1. 概要
NVIDIA が提供するプロファイリングツール Nsight を使って、Jetson Nano で動作するアプリの性能ボトルネックを見つける方法をまとめます。
今回私が Nsight を使おうと思ったきっかけは、前回記事 でもネチネチと作業したように、
TensorFlow Lite GPU Delegate (OpenGLESバックエンド) を使ったアプリを少しでも速くしたかったからです。
ですので、下記のような Posenet による姿勢推測処理負荷の高いアプリを観測対象とします。
なお、観測対象アプリのソースコードは下記にあります:
https://github.com/terryky/tflite_gles_app/tree/master/gl2posenet

2. Nsight について
2.1 Nsight 3兄弟
公式ページ にある通り、2019/12月時点において、Nsight は、3種類のツールから構成されます。

1) Nsight Systems
・性能解析のとっかかりとして、システム全体を俯瞰して大まかな性能ボトルネックを見つけるためのツール。
・ボトルネックがCPU処理なのか、OpenGLES や CUDA などGPUオフロード先の処理なのかの判定を行う。
2) Nsight Graphics
・Nsight Systems による観測の結果、ボトルネックがOpenGLESやVulkanによる描画処理だと分かった際に、描画に焦点をあててさらに深く観測するためのツール。
・OpenGLES や Vulkan など、バイナリライブラリとして隠蔽されているAPIの内部の処理負荷を観測できる。
3) Nsight Compute
・Nsight Systems による観測の結果、ボトルネックがCUDA処理だと分かった際に、CUDAをさらに深く観測するためのツール。
2.2 Jetson Nanoでの Nsight
Jetson Nano 上のアプリを Nsight で観測するには、ホストPCからJetson Nano へssh接続した状態で観測を行います。このとき、Jetson Nano側のアプリは、プロファイル情報取得するため sudo 等で root 権限を付与した状態で実行する必要があります。私はここでハマったのですが、ホストPCからJetsonNanoへssh接続する際、通常ユーザアカウントではなく、root アカウントで接続しないとうまくプロファイルが取得できませんでした。(root アカウントによる ssh 接続は何か気持ち悪いですが仕方なく。。)
なお、Jetson Nano で使用可能な Nsight は JetPack として提供されています。JetPack 4.3 には、Nsight 3兄弟のうち Nsight Systems と Nsight Graphics だけが含まれているようです。Nsight Compute は見つけられませんでしたが、今回観測対象のアプリは CUDA を使っていないため、問題ありませんでした。

3. Nsight のインストール
公式手順 に従って JetPack をインストールすることで、Nsight が使えるようになります。
以下、簡単にインストールの流れを説明します。
3.1 SDK Manager のダウンロード
NVIDIA のWebページ から NVIDIA SDK Manager をダウンロードします。
(ダウンロードには、NVIDIA Developer Program への参加が必要です)

Developer Program にログインした状態で上記画像の赤枠ボタンをクリックすると、sdkmanager_1.0.0-5517_amd64.deb がダウンロードできるので、ホストPC (Ubuntu) の適当な場所へ保存します。
3.2 SDK Manager の実行
ホストPC上で、SDK Manager を起動します。
$ cd ~/download
$ sudo apt install ./sdkmanager_1.0.0-5517_amd64.deb
$ sdkmanager
SDK Manager を起動するとログインを促されますので、SDK Manager をダウンロードした時と同じアカウントでログインします。
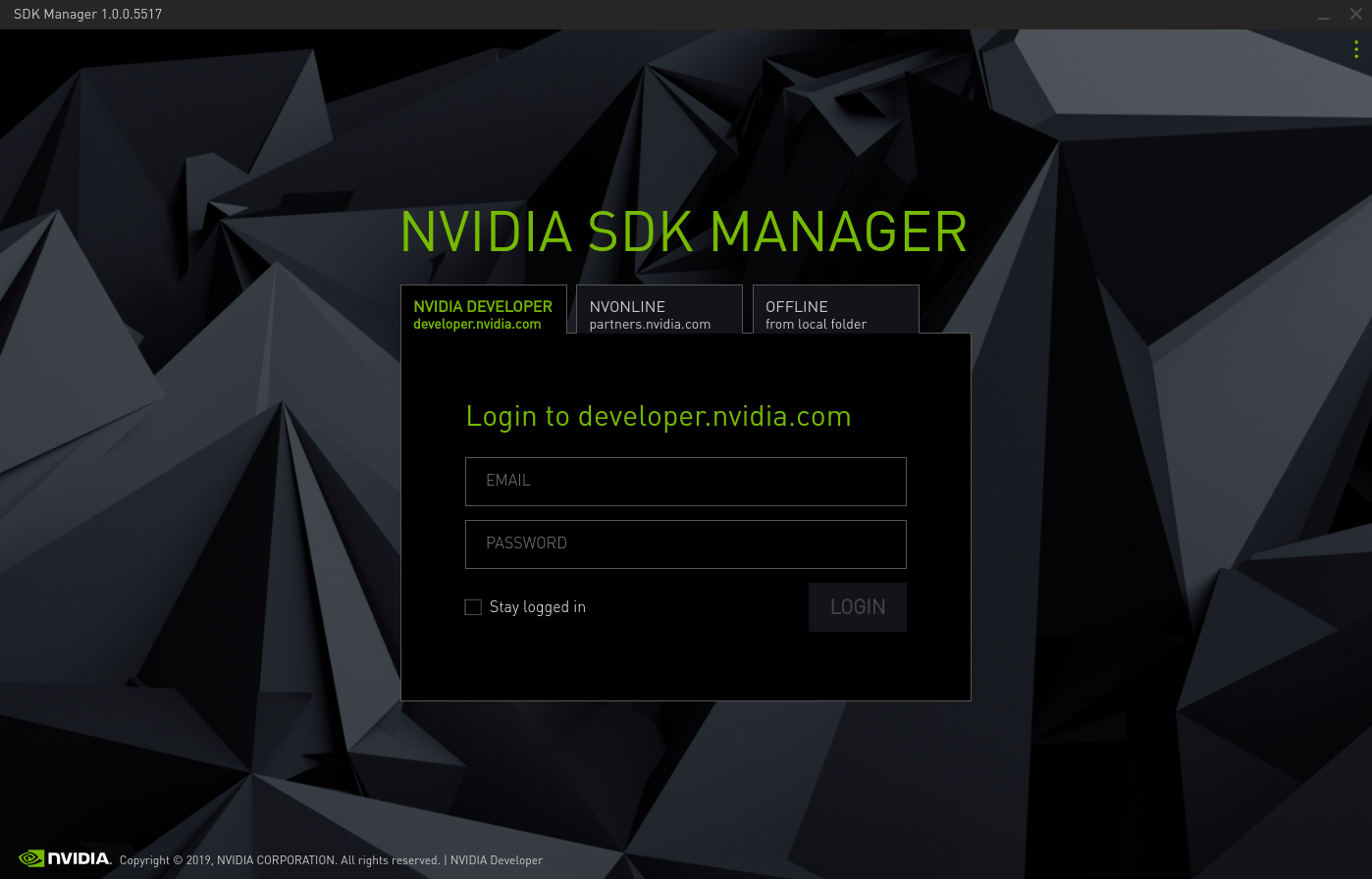
ログイン後、ターゲットとなるデバイスの選択画面となります。
今回はホストPC側に Nsight をインストールしたいだけなので、Target Hardware のチェックを外します。
(Jetson Nano 側はSDカードに最新版イメージが書き込み済みの前提)

次に、インストールするソフトモジュールの確認画面となります。
ホストPC側に、NVIDIA Nsight Graphics/Systems がインストール対象となっていることが確認できます。
「I accept ...」にチェックをいれて、continue します。

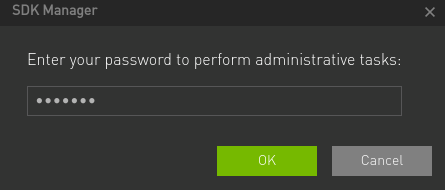
sudo するためのパスワードを入力すると、あとは自動でインストールが完了します。
4. Nsight Systems の実行
まずは大まかにボトルネックをつかまえるために、Nsight Systems によるプロファイルを行います。
4.1 前準備
前述の通り、ホストPCからJetson Nano へ root アカウントで ssh 接続できる環境を準備します。
例えば下記のように。(正式な手順はわかっていません。すみません)
(参考記事)https://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q10190946705
(参考記事)https://qiita.com/____easy/items/60d8b5d5ca03a3ce250d
4.2 Nsight Systems 起動
これ以降、全ての作業はホストPC側から行います。
まず下記コマンドで起動します。
$ nsight-sys
ターゲット選択画面になるので、スパナみたいなアイコンをクリック
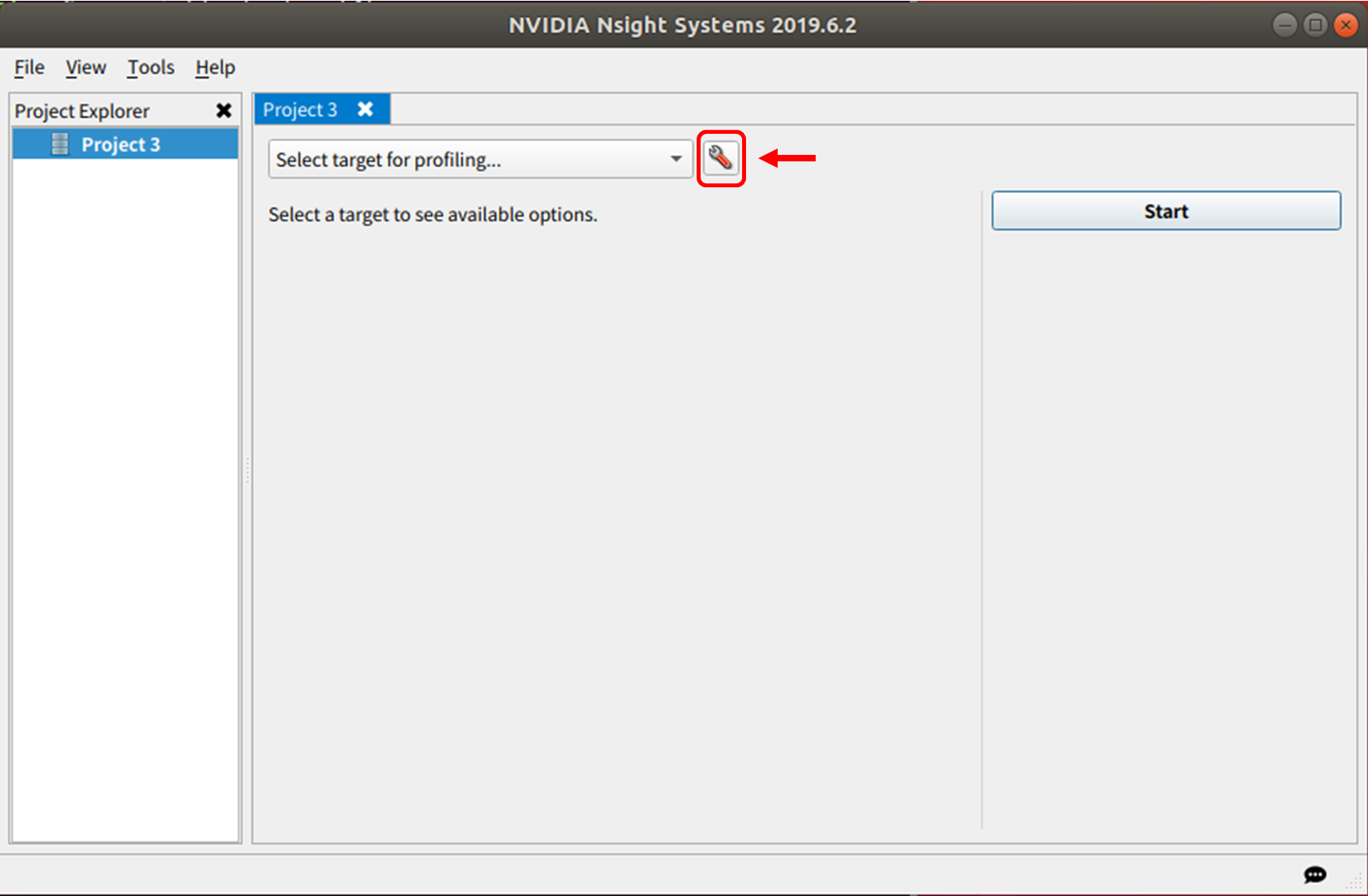
Create a new connection をクリック
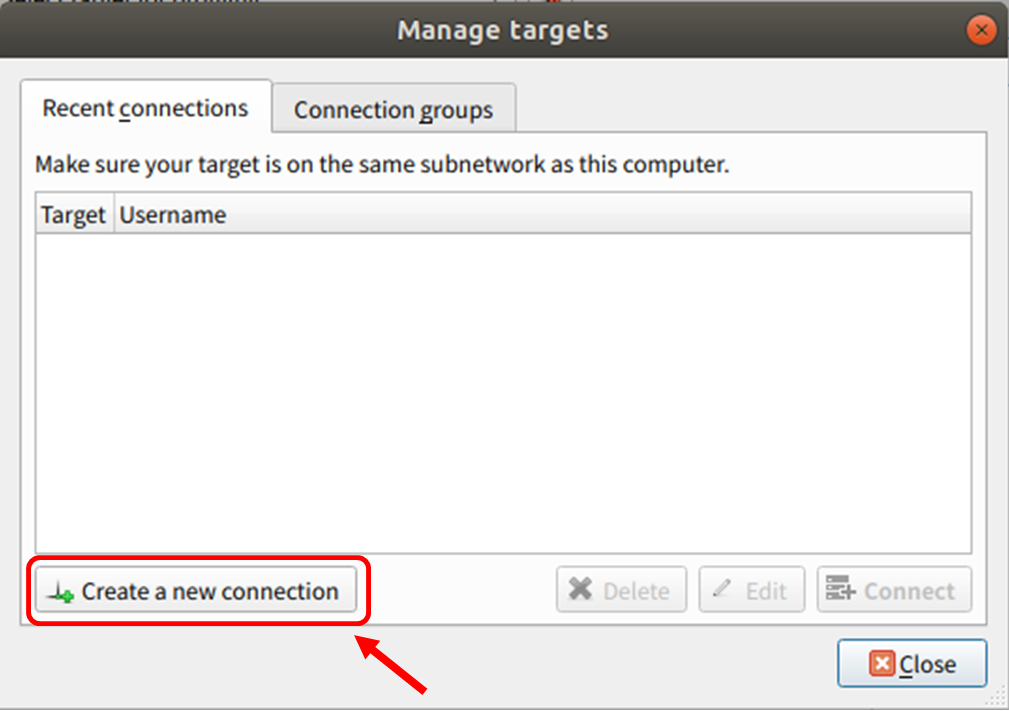
ssh 接続するために、Jetson Nano の IP とアカウントを設定。
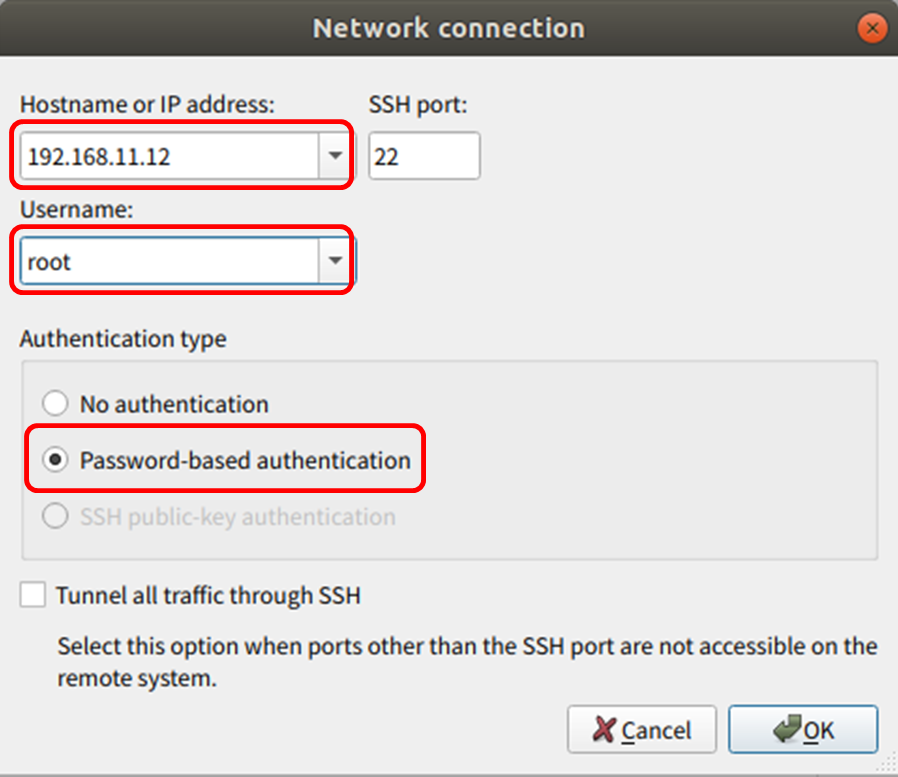
connect
Jetson Nano へssh接続するパスワード入力
観測対象アプリを指定する画面になるので、下記設定後、Start。
・観測対象アプリのパスを指定
・XWindow を開くアプリなので、DISPLAY変数の値を :1 に指定 (不要かも)
・Launch as root にチェック
・Collect OpenGL trace にチェック
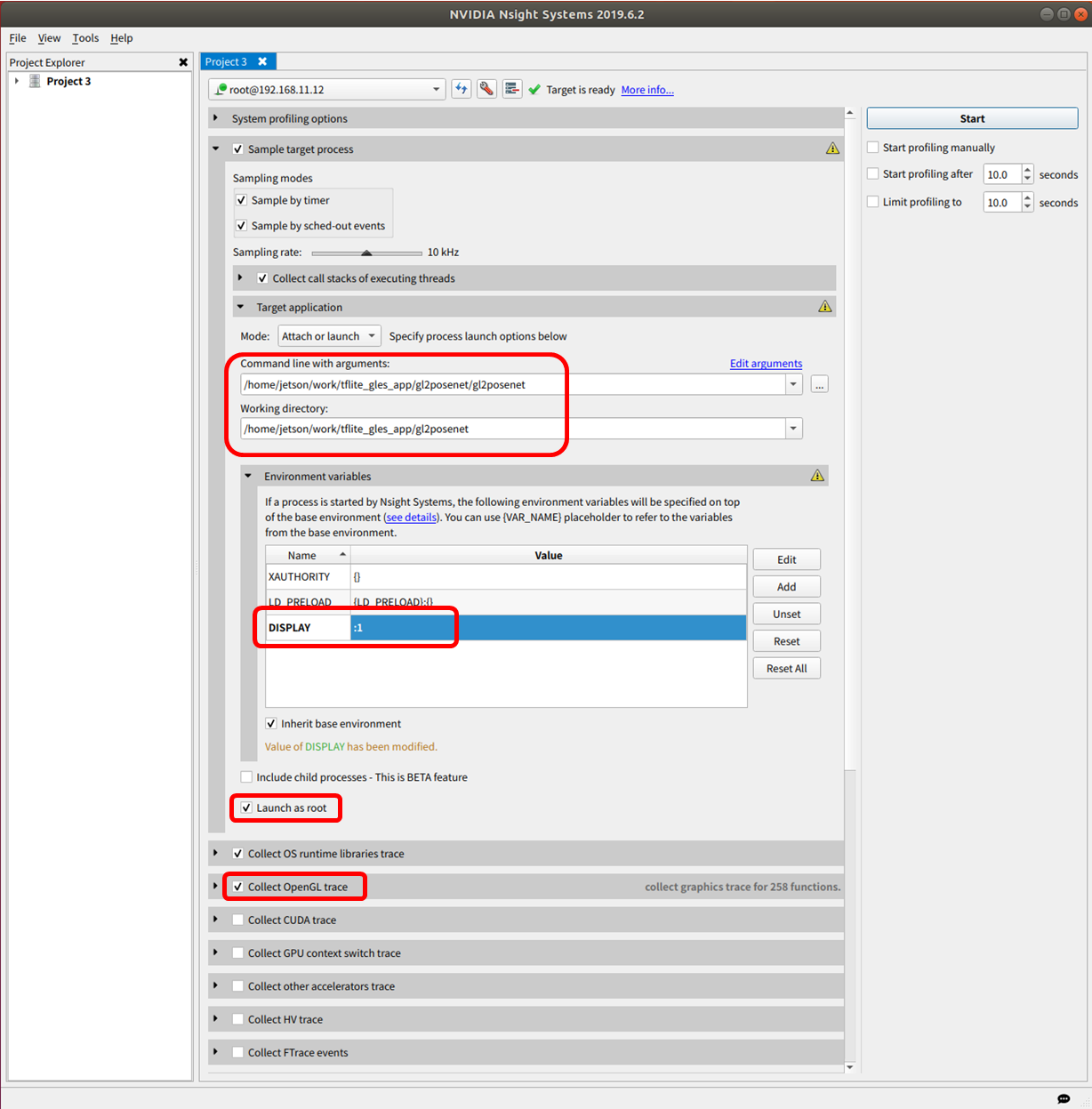
Jetson Nano 側で観測対象アプリが立ち上がり、プロファイルデータの取得が始まります。
観測対象アプリが定常状態となり有効なデータが取得できたと思われるタイミングで Stop させます。
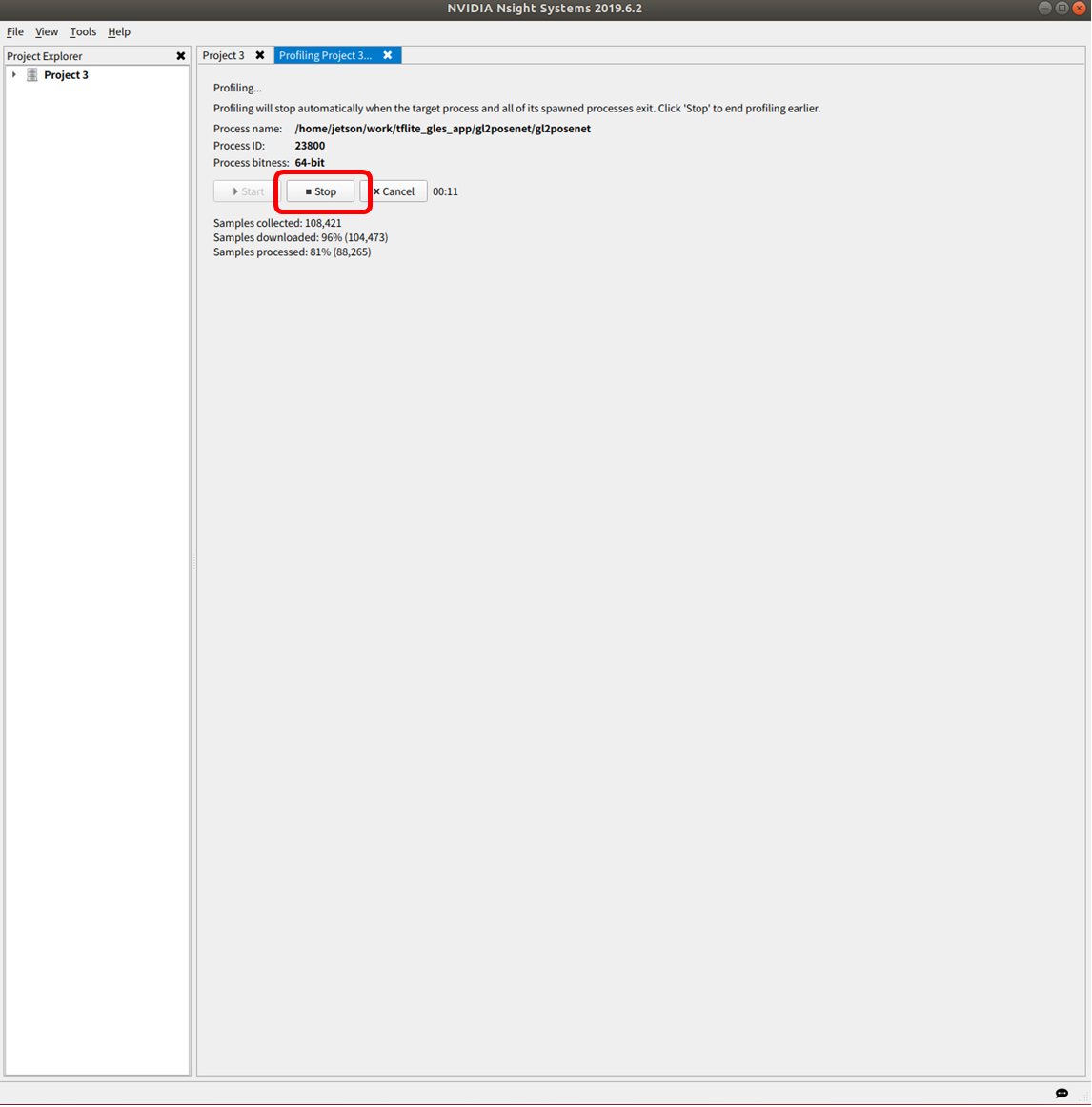
4.3 Nsight Systems で観測
プロファイル結果が表示されるので、下記のようにしてボトルネックを探します。
・右上の Timeline View で、Ctrl+マウスホイールで適当なスケールに拡大
・1フレーム分の時間と思われる範囲をマウス左ドラッグで選択
・右クリック→ Filter by Selection
・画面真ん中あたり、Top-Down View を選択
・画面右下に、時間占有率の高い関数が表示される
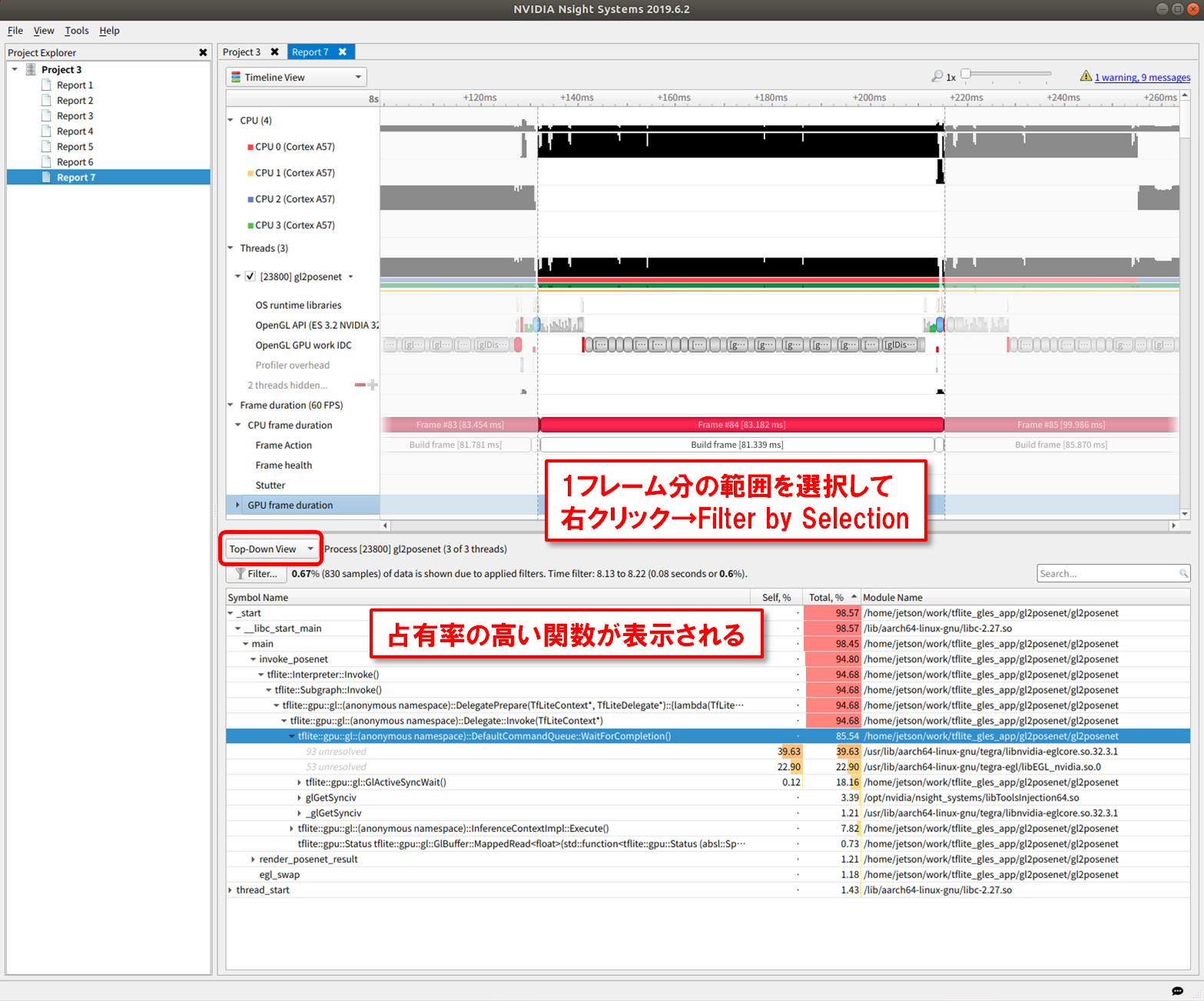
上の例の場合、1フレームあたり 81[ms]くらい時間がかかり、そのうち 85% が、WaitForCompletion() 関数が消費していることがわかります。つまり、TFLite GPUDelegate において、OpenGLES Compute shaderのGPU処理完了を待っている時間が大半であることを示しています。
4.4 GPU Delegate 有無での比較
比較のため、GPU Delegate を使わないときのプロファイルも取得してみます。
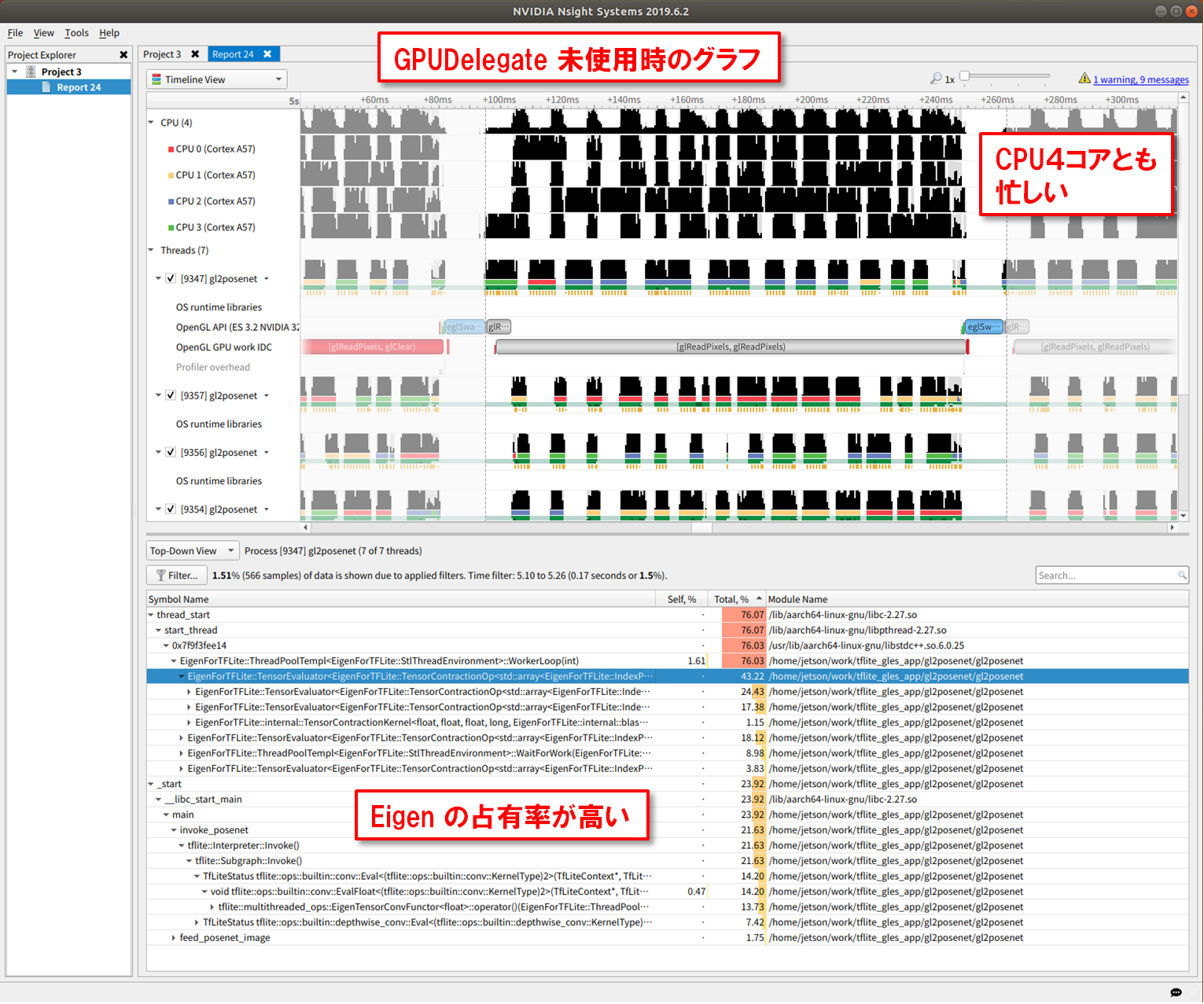
両者のプロファイル結果を比較することで、下記のようなことが確認できます。
| 比較項目 | GPU Delegateあり | GPU Delegateなし |
|---|---|---|
| 処理時間 | 81 [ms] | 165 [ms] |
| CPUコア | 1コアだけ忙しい | 4コアとも忙しい |
| 占有率高い関数 | OpenGLES | Eigen |
今回の目的は GPU Delegate 時のボトルネック解析なので、次は Nsight Graphics を使って、GPU Delegate時の OpenGLES の内部動作をさらに詳しく見ていきます。
5. Nsight Graphics を使った性能プロファイル
Nsight Graphics によるプロファイリング作業も、全てホストPC側から行います。
下記コマンドで起動します。
$ nv-nsight-gfx-for-l4t
Quick Launch の Continue をクリック
・Jetson NanoへのSSH接続情報を設定
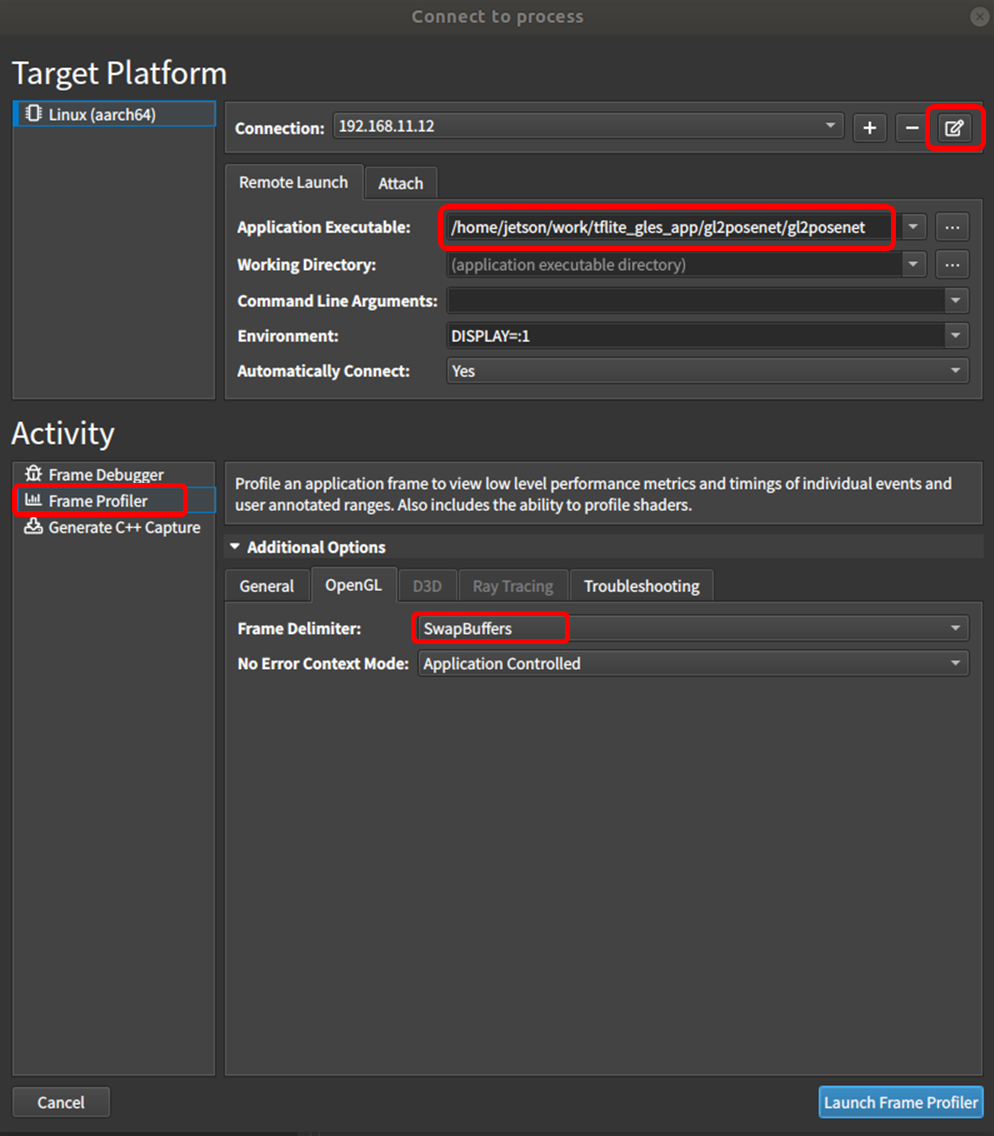
・観測対象アプリを設定
・Frame Profiler を選択
・Frame Delimiter は SwapBuffers を選択。(描画しないアプリなら glFinish() 等を選択)
Jetson Nano への接続に成功すると、Jetson Nano側で観測対象アプリが起動され、プロファイル待機状態となります。適当なタイミングで Cpature for Live Analysis を押すと、その直後の1フレームのプロファイリング情報が取得されます。
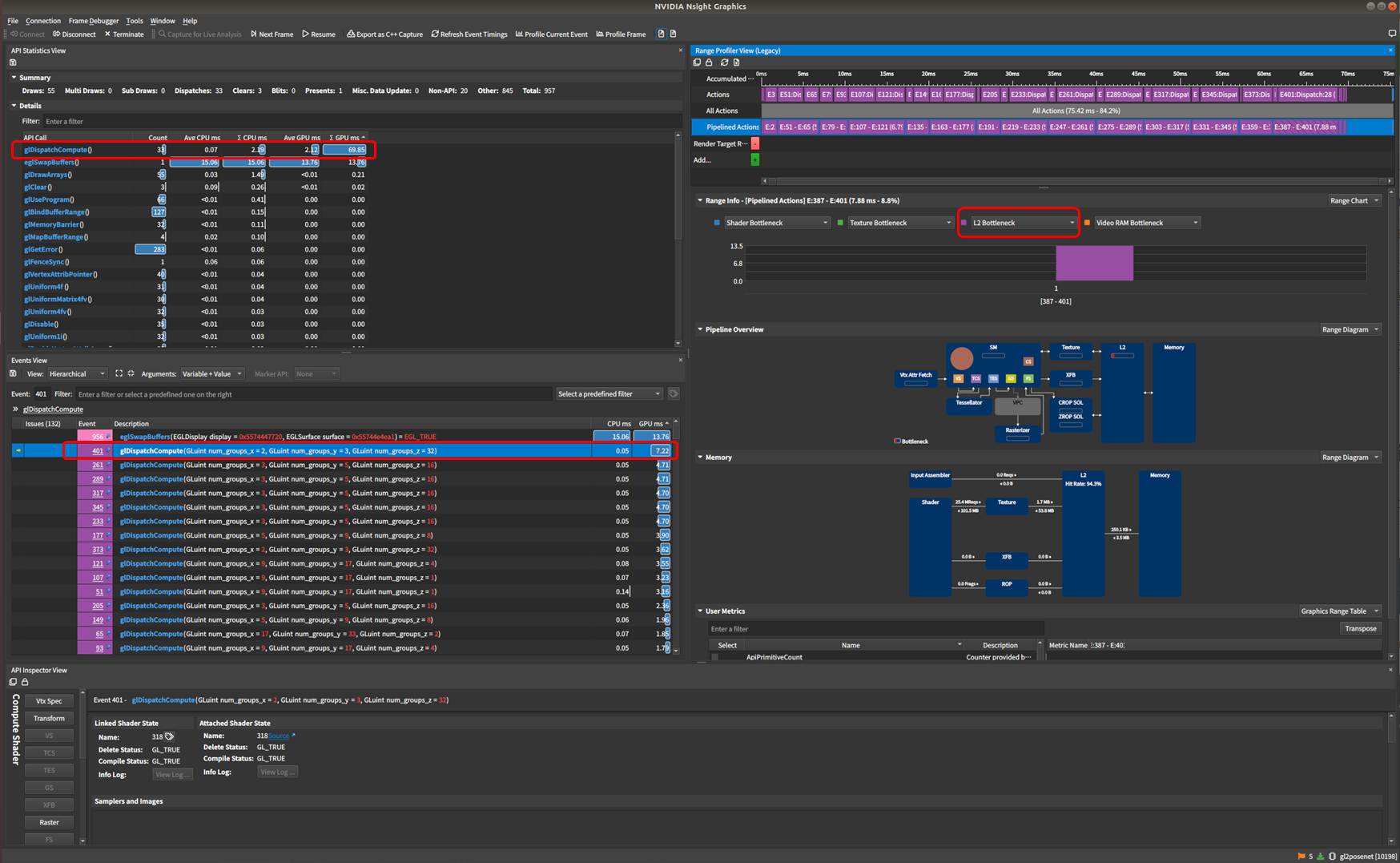
下図が取得したプロファイル結果です。
・glDispatchCompute() による GPU 稼働時間が 69.85[ms] とダントツであることがわかります。
・1フレームあたり glDispatchCompute() は複数回よびだされますが、最も時間のかかるものは 7.22 [ms]
・GPUパイプラインにおけるボトルネックを表示させると、L2 Bottleneck がダントツ
以上のことから、性能改善を実現するには、L2$ の負荷が下がるように、ComputeShaderに手を入れていく必要があることがわかります。(これが難しいのですが。。。)
6. 最後に
Jetson Nano 上で、Nsight を使ってアプリの性能プロファイリングする方法を説明しました。
公式ページ にはもっと詳しい情報がありますのでご参考になさってください。
Nsight Systems を使えば、GPUを使っていないアプリでも、どの関数実行に時間がかかっているのかを簡単に取得できるので、とても汎用性の高いツールだと思います。
Nsight Graphics では、バイナリで隠蔽されている OpenGLES 内部を詳しく観測 してボトルネックを見つけることができるので、こちらも有用なツールです。
強力なGPUハードを提供するだけでなく、その性能を引き出すための良いソフトツール群が揃っているのがNVIDIAの強みですね。