どうも、山田です。
スーパーコンピュータポエムAdC、六日目となりました。
そろそろネタがなくなってきましたよ。そもそも20余システムも特徴的なシステムないって(暴言
Day 6 Prometeus
名前と天板、めっちゃかっこいいな…

というわけで、本日はポーランドに設置されたスーパーコンピュータ、Prometeusシステムについての記事です。
Prometeusとは?
Prometeusは、ポーランドはAGH科学技術大学の計算機センター、Cyfronetに設置されています。
ランクはNov/2020で#324。理論ピーク性能は2.3PFlopsのマシンです。
にあります。
ちなみにポーランド語なので何書いてあるんだかマジでわかんない。
Prometeusのスペック
先ほどのプレスリリースと
Top500のサイト、そしてAGH科学技術大学のサイト から読み解いていくことにします。
Top500のサイトによれば、HPEのApollo 8000という製品を使用したシステムで、使っているCPUはXeon E5-2680v3, GPUはNVIDIA K40のようです。
ノード間インターコネクトはInfiniband FDR。EDRの一つ前の世代であり、56Gbpsの転送速度を持ちます。
Prometeusシステムが今の形になったのはNov/2015なので、5年前のシステムとしてみると妥当な構成ですね。
……が、これどうもcyfronetのプレスリリースを見ると、たぶんですがK40はHPLには使っていなさそうですね。
Prometeusは以下のパーティションに分かれていると記載があるので
• classic computing servers with high-performance Intel Xeon Haswell and Intel Xeon Gold processors,
• a set of servers with NVIDIA K40 XL graphics processors,
• an acceleration partition with NVIDIA K80 GPGPU cards and Intel Xeon Phi and Nallatech FPGA accelerators,
• a partition dedicated to computing related to artificial intelligence, equipped with GPGPU NVIDIA Tesla V100 graphics
(引用元:http://www.cyfronet.krakow.pl/aktualnosci/18006,3,komunikat,prometheus_na_326__miejscu_listy_top500_-_najszybszych_superkomputerow_swiata.html)
正確にはGoogle翻訳が英語に翻訳したものだけど。
Google翻訳のおかげで何となく読めている……
たぶんHaswell世代のXeonを使ったシステムによる計測だと思われます。つまりE5-2680v3ですね。
使っているノード数、CPU数とかは
The hardware consists of 2,200 servers of the HP Apollo 8000 platform. Scientists and researchers have at their disposal over 53 thousand cores of Intel Xeon processors.
との記載があることから、2200ノード、E5-2680v3は12コアなので、デュアルソケットにすると計算が合います。また、理論ピーク性能についても、E5-2680v3の理論ピーク性能を480GFlopsとすると、4400 * 480 = 2.1PFlopsと、大まかに合う計算です。(一割どっか行ってるのが気になるけど…もしかしたら144枚のK40がピーク性能に追加されているのかもしれん…
なので、Prometeusシステム自体は、これXeonオンリーなCPUクラスタなんですよ!!(な、なんだってー!?
えーどうしようかな…K40の話しようと思ってたんだけど…今更Haswellの話するのもなんだかな…
まぁいいか…K40の話しよ!!
はい!!使われてないけどK40の話します!!!(それでいいのか?
NVIDIA K40
はい。NVIDIA K40です。
NVIDIAのHPC用の製品、Teslaの三四代目ですね。(12/08修正 似鳥先生ありがとう) ところで、最近Teslaって言われてないのご存じですか?
メジャーなマイクロアーキテクチャの更新としては、G80, Fermiの次、HPC用の強力な改良を持ち込んできたKeplerアーキテクチャです。
最近のCUDAでサポートが終了してしまった Fermiアーキテクチャですが、これはとてもいいアーキテクチャでした。というかFermiって2009年に情報公開とかなのか…うーむ…十年一昔…
Fermiアーキテクチャは性能的にはとても良いアーキテクチャだったのですが、歩留まり向上と発熱量に苦しんだアーキテクチャだったように記憶しています。GF100系は丸々64CUDA Core(2 SM)をDisableにした状態で出荷されていましたし、それでもなお爆熱といわれていました。つらいですなマジで。なお、しばらくした後に歩留まりが向上したのかフルスペック版のGF11xが出て、もっぱらそれを利用していました。大学時代にGTX580を何枚破壊したことか…
全然関係ないんですけど、GPU買うならELSAさんがいいですよ。高いけど三年保証! 計算してて壊しちゃっても快く直してくれていや本当に申し訳ございませんでした。反省してます。
KeplerアーキテクチャはFermiアーキテクチャの反省を踏まえ、大きなジャンプアップを遂げた良いアーキテクチャでした。マイクロアーキの変更が大きすぎてみた当初はビビりましたが。
Keperアーキテクチャのwhitepaperはこちらにあります。ちなみに日本語版もあるよ。
Fermi->Kepler
FermiアーキテクチャのGF1xxはTSMCの40nmプロセスで製造されたGPUでした。一方、KeplerアーキテクチャのGK11x系はTSMCの28nmプロセスで製造されていました。(過去形
GF110のダイサイズは520mm^2で、512個のCUDA Coreを実装していました。GK110ではどうなったかというと、561mm^2のダイに対して、2880個のCUDA Coreを実装しています。プロセスルールが進んでいるとはいえ、面積が約8%増加してコアが5倍には普通ならないですねえ…
一般的にトランジスタだけで考えると、(40 * 40) / (28 * 28)倍は詰めるようになるので、2倍は詰め込めるとして、マイクロアーキテクチャの改善がないと、さらに倍にはならないわけです。
そのため、NVIDIAはマイクロアーキテクチャのドラスティックな変更を加えてきたわけですね。
何したかというと、コントロールロジックを大幅に削減しました。
端的に言うと、「命令ってデータが来てたら一定時間で終わるわけで、並び替えにそんな労力割く必要なくない?」ということで、コンパイル時に命令の依存性とかレイテンシとかをバイナリに埋め込んでおくことで簡素化し、ハードウェア側は実行できる命令を常に実行する、という仕組みにしたわけですね。(語弊がある説明だったら申し訳ない……)
これのため?かどうかはわかりませんが、これのためのような気がしないでもないのが、SMの構造の大幅な変更です。
SMX
SMというのは、今日のAmpereアーキテクチャでもなお引き継がれている、CUDAのカーネル実行単位であり、CUDA Coreをひとまとまりにしたもの、いわゆるCPUにおけるコアです。
FermiアーキテクチャのSMは
 ([Fermi whitepaper](https://www.nvidia.com/content/PDF/fermi_white_papers/P.Glaskowsky_NVIDIA's_Fermi-The_First_Complete_GPU_Architecture.pdf)より)
([Fermi whitepaper](https://www.nvidia.com/content/PDF/fermi_white_papers/P.Glaskowsky_NVIDIA's_Fermi-The_First_Complete_GPU_Architecture.pdf)より)
となっており、32個のCUDA Coreが1まとまりになっていました。NVIDIAのGPUでの命令発行単位はWarpと呼ばれる32個CUDA Coreのまとまりになっており、Fermiアーキテクチャでは命令発行単位とコア数が1:1対応していたわけですね。
一方KeplerアーキテクチャのSMは
 ([Kepler whitepaper](https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-product-literature/NVIDIA-Kepler-GK110-GK210-Architecture-Whitepaper.pdf)より)
([Kepler whitepaper](https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-product-literature/NVIDIA-Kepler-GK110-GK210-Architecture-Whitepaper.pdf)より)
となっており、一目で巨大になったのがわかると思います。パッキングされているCUDA Coreの数は192となっており、なんと6倍。名前も変わってSMXとなりました。
これだけではなく、SMあたりのレジスタもFermiアーキテクチャと比較して倍になっています。
NVIDIAのGPUの構造はとても面白くて、レジスタはSMに大量にあり、それをスレッドでシェアするようになっています。プログラマがプログラムを書くと、カーネルの1スレッドあたりのレジスタ数というのが決定されて、その数によってインフライトになる(同時にSM内に同居できる) スレッドブロックの数が決定されます。このインフライトになる数というのが重要なんですね。これは今日のAmpereアーキテクチャでも同様です。
Warp shuffle
↑の話は後でまた触れるとして、Keplerアーキテクチャで導入された新フィーチャーで面白かったのは、Warp内シャッフル命令です。
これは割とこの時期にCUDAのコード書いてた人はたぶんみんな好きだと思うのですがw データ並列のコードを書いていると、今演算している並列単位の中でデータの順番を入れ替えたいケースっていうのが発生します。SIMD書いてても発生しますよねえ。ぐるっと回したいなとか…
そういうケースでは、FermiアーキテクチャのときはShared Memoryに書くしか方法がありませんでした。ただ、Shared memoryに書くのはそれなりにコストが高いんですよね。できれば回避したい…という声を汲んでくれてできたのがWarp内Shuffle命令です。
Warpは先ほど説明した通りの32CUDA Coreの単位ですが、別スレッドが持っているレジスタにアクセスできるというものです。図にすると以下のようになります。
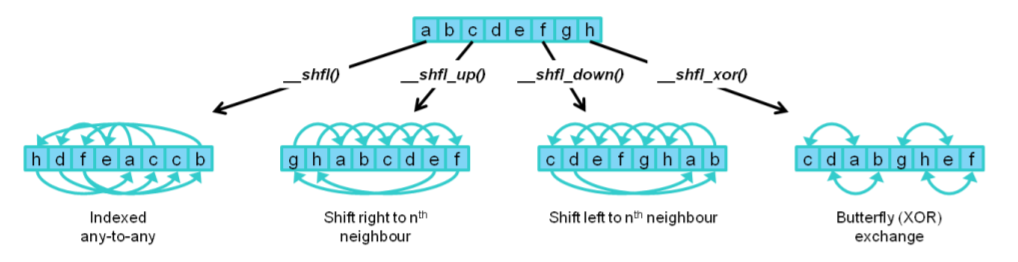 ([Kepler whitepaper](https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-product-literature/NVIDIA-Kepler-GK110-GK210-Architecture-Whitepaper.pdf)より)
([Kepler whitepaper](https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-product-literature/NVIDIA-Kepler-GK110-GK210-Architecture-Whitepaper.pdf)より)
これが地味に良くてねえ…
SIMDに慣れ親しんだ方(いるのか?) には、1024bit SIMDの任意permuteができるとかレジスタ内左右ローテートができると思ってもらえれば(どういう説明だよ
Read Only Cache
Fermiアーキテクチャのころからついていたはついていたんですが、当時はTexture Cacheと呼ばれていて、本来はグラフィックス用のキャッシュを使うというシロモノだったんですが(まぁそもそもGPGPUってそういうもんだよな…) コンピュート用にもサポートしてくれました。
しかもFermiアーキテクチャのころのように、APIを使ってTextureキャッシュに置くことなく、リードオンリーなデータに対して、const __restrict修飾をするだけでコンパイラがキャッシュに載せてくれるので、とても便利でした。SMXに対して48KBとそこそこ大きい空間があったので、これは割と重宝しましたね。
Dynamic Parallelism
Keplerでめっちゃ革新的!!とテンションがあがったものの、実際これどこで使うんだべか…という気持ちに若干なってしまったやつ。使いどころがないわけじゃないんですけどね…
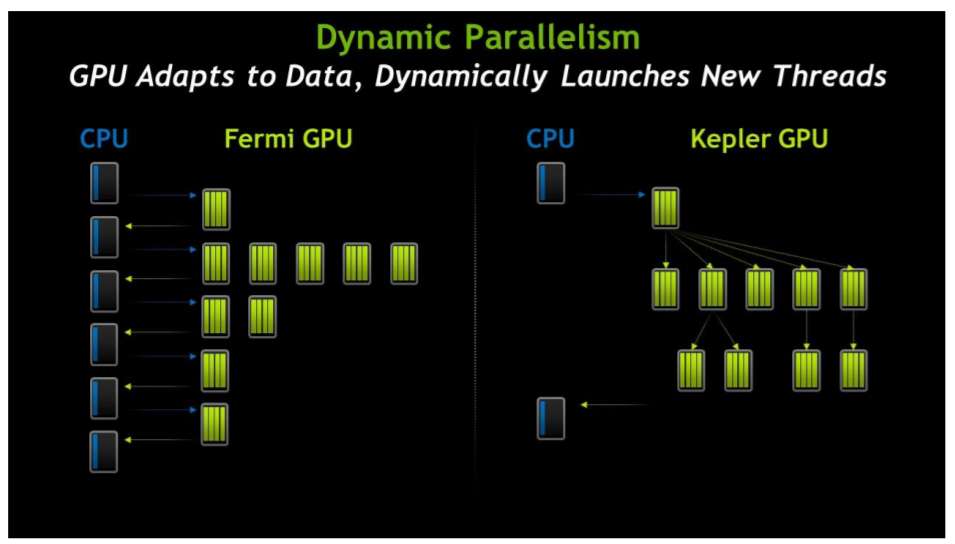
普通にGPUをキックすると、スレッドやスレッドブロック間で、負荷のインバランスが発生します。通常はGPUは実際のコア数に対して多いスレッド数を割り当てることで、スレッドのストールやインバランスを吸収するような思想で作られているわけですが、必ずしもそういう隠蔽がうまく動作するとは限りませんし、そもそも並列性が低いプログラムはGPUには乗せられないのか?という問題があります。
フクザツなコントロールフローのある一部分に割と大きな並列性があるけど、並列になる部分ではデータが割と飛び飛びなところにあるので、GPUに乗せるにはシリアライズしないといけなくて、シリアライズコストも馬鹿にならないからGPUに乗せてもあんまりメリットがない…みたいな経験、皆さん一度はしたことありますよね(???
Dynamic parallelismではそれをうまく解決できる、というのが触れ込みで、何をするかというと、GPUのカーネル内でさらにカーネルを起動することができます。
これをやると、少ないスレッドでコントロールフローを実行し、並列性が大きくなったところでGPUの巨大なスレッドを一気に立ち上げる、ということができるようになります。フローがGPU側にあるということはデータもGPU側にあるので、データコピーもシリアライズのコストも必要ない!素晴らしい!
Keplerアーキテクチャは実際どうだったか?
つらつらとFermiアーキテクチャからの変更点を書いてきましたが、実際Keplerアーキテクチャはどうだったのか、というと、割とテクいアーキテクチャになったな、という感じでした。
Fermiアーキテクチャのころというのは、割と素直に128スレッドぐらいを起動して1SMにあてるようにしたら平和に性能が出るような感じのものだったのですが、Keplerアーキテクチャだとそういうわけにはいかないんですよね。そもそも192CUDA Coreあるので、128スレッドとかだと全然足りない。あと、Warp schedulerもFermiアーキテクチャだと1:32だったのが、Keplerアーキテクチャだと4:192になっているので、スレッドの割り付け自体をちゃんと考えないといけなくて、少し悩ましい構造になっていました。実はSMあたりのレジスタ数もかなり減ってる(32:65536 -> 192:65536) し。
なので、雑に、「これ並列性あるから乗せてみよ」と乗せてCPU比で速い、よし次!ぐらいの温度感でいるのが平和な感じのアーキテクチャでした。これを詰めようと思うと、レジスタが足りねえ…稼働率が上がらねえ…というループに飲み込まれていくような…
ただ、堅実に良い方向での改良は加えられていた良いアーキテクチャでした。ここで得られたものをもとに、Maxwellを経てPascalに到り、NVIDIAはこんにちの地位を盤石のものとしたのです…(?
まとめ
- ポーランドのスーパーコンピュータ Prometeusについて述べました。
- 大誤算でPrometeusはCPUクラスタでした。
- Prometeusにはあんま関係なかったのですが、NVIDIA K40の話をしました。関係なくてほんとすいません。ほとんど自己満足です。
- 12/7は@higucheese さんで、Oakforest-PACSのお話です。めっちゃ楽しみ!!!
……もしかしてみんなXeonPhi好きなんじゃないか?(錯乱