山田です。
スパコンポエムAdC2020、十二日目となりました。
皆さん昨日のロボ太先生の記事 はお読みになられましたか?
ロボ太先生の数々の記事から、スパコンというものを動かす大変さが伝われば幸いです…(血涙
ところでBlue Gene/Lってそんな割り切った構成だったんですね…あらゆるところでビット化け例外受け取って対処するとかちょっとめまいがするんですけど…すごいなLLNL…
奇しくもBlue Gene/Lはマイナビで記事になっている ので、そちらも合わせてどうぞ。
それでは、今日もゆるゆると、これは話しておかねばなるまいってスパコンについて、ポエムっていきましょう。
Day12 DGX Superpod

(出典: https://www.nvidia.com/ja-jp/data-center/dgx-superpod/)
上記画像はNVIDIA A100にてレンダリングされ(たような気がし)ました。
はい、というわけで、NVIDIAが2020年、V100の次のプロダクトとして、満を持して世に送り出したHPC用プロセッサ、名実ともに世界最強を更新したA100によって構築された、DGX superpodです(オタク早口
Nov/2020のTop500では#170 につけておりますが、Nov/2020のGreen500では#1となっています。それも前人未到の25GFlops/Wを突破して!! さらにJune/2020の首位MN-3(これもさらに性能を伸ばしてきた) を僅差で押さえての一位!! これはもう化け物ですよ、いやほんとに。NVIDIAのGPU表現するのに化け物以外の形容詞使ってないな…
DGX Superpodのスペック
スペックは以下のような感じ。
| | Spec |
|----|----|----|
|CPU| AMD EPYC-7742 * 2 |
|GPU| 8 * NVIDIA A100 80GB |
|Memory| 2TB |
|InteConnect| 8 * Mellanox HDR 200Gbps Infiniband, 2 * 200Gbps Ethernet |
|PeakPerformance| 2,812.8 TFlops |
(出典: DGX-A100 datasheet, NVIDIA DGX Superpod A100 )
DGX Superpodは、DGX-A100という、NVIDIAが開発した自前のリファレンスサーバーアーキテクチャに基づいて作られています。MicrosoftのSurfaceみたいなものですね(?
DGX Superpodは、140個のDGX-A100から構成されています。ネットワークトポロジーとかは[NVIDIA DGX Superpod A100](NVIDIA DGX Superpod A100) に詳しいので、そちらをご参照のこと…
このスパコンがですね、ほんとに強いんですよ。NVIDIAは時代の最先端を使ってるなって思わされますね。
まずCPUはROME世代のEPYC を採用。俗にいうEPYC2ですね。まぁEPYC2にはいろいろ言いたいことはありますが、この採用は2020年時点では当然というかベストチョイスでしょう。なぜならIntelのサーバーCPUはまだPCIe Gen4をサポートしていないから!!!
いやーホスト-デバイス間が細くて困るのでNVLinkとかを実装しているNVIDIAからすれば、Gen4のサポートがない時点で選ばないわけですね。加えて言うなら、Interconnectの帯域もEDRどまりになってしまうので、それはない。あと、PCIeのレーン数もかなり多く、なんと128レーンを擁しています。
GPUは言わずもがななんでまぁこれは後に譲るとして、NVIDIAに買収されたMellanoxのHDR Infinibandが8つ接続されています。これは、各A100が一枚をそれぞれハンドルしています。信じられますか!? GPUが直接200Gbpsでデータ吐けるんですよ!? GPUDirect極まったな。
そんな構造だからか、ピーク性能の2,812.8 TFlopsに対して、実効性能は2,356 TFlopsとなっており、実効効率は83.7%となっています。これは驚異的に高い値です。Piz Daintの記事 でも触れましたが、DGX-1を採用したP100世代のシステムが67.4%, PizDaintが78%, Summitでさえ74%だったのに、10%の性能向上を成し遂げてきたDGX Superpodは真に偉大といって差し支えないかと。
この高効率の理由は、ハードウェア的にA100がHDRをハンドルしているのも大きいと思うんですが、たぶん、NVIDIAのxxxxxがxxxxxして、xxxxxをxxxxxでxxxxxになったっていうのがあるんじゃないかと思うんですよね。そうすると、xxxxxとxxxxxが減らせるわけで……そうか、だからRPeakの計算にxxxxxがxxxxxなのか…あ、前回とは違ってこれは結構推測入ってます。
(注釈: 大人の事情でまずそうなところはすべてxxxxxと置き換えました。なお文字数は実際に記載されていた単語とは対応していません)
という性能でありながら、実測の消費電力としては89.94 kWです。これはかなりすごい数字で、何故かというとDGX-A100のカタログでの最大消費電力が6kWなんですね。Green500のレギュレーション的に、DGX SuperPODの計測メソッドはLevel2なので、最低1/8の電力を計測する必要があります。とすると、これを8倍すると、720kW。カタログ値をそのままとすると840kWになるところ、15%ほど低い計算になります。しかもここにさらにネットワーク等のサブシステム電力を入れる必要があるわけで、実質、計算ノードの消費電力はカタログから2割ほど落ちている計算になります。
かなりxxxxxをxxxxxをしたんだろうなと思うところですが、xxxxxでxxxxxだという話はxxxxxから伺っているので、xxxxxを頑張ったんだろうな…としみじみと感じ入りますね。
(注釈: 大人の事情でまずそうなところはすべてxxxxxと置き換えました。なお文字数は実際に記載されていた単語とは対応していません)
さて、それではDGX-A100の心臓部、NVIDIA A100の中を見ていきましょう。
NVIDIA A100

(出典: NVIDIA A100)
2020年にTSMCの7nmプロセスを使って製造された、NVIDIAのHPC用GPUです。
世界最強と呼ぶにふさわしい性能です。まさしく「規模を問わず、前例のない加速」です。
(このタイトル気に入った)
アーキテクチャとしてはAmpereアーキテクチャを採用しており、Voltaアーキテクチャを改良したものになっています。
毎回毎回、Whitepaper を公開していただいてるのはありがたい限り…分析が捗る…日本語版 もあるよ…
V100とA100を比較すると
| Spec | V100(SXM2) | A100(80GB) | A100(40GB) |
|---|---|---|---|
| fp64 | 7.8 TFlops | 9.7 TFlops | 9.7 TFlops |
| fp32 | 15.7 TFlops | 19.5 TFlops | 19.5 TFlops |
| fp16 | 31.4 TFlops | 78 TFlops | 78 TFlops |
| bp16 | N/A | 39 TFlops | 39 TFlops |
| Peak FP64 TensorCore | N/A | 19.5 TFlops | 19.5 TFlops |
| Peak TF32 TensorCore | N/A | 156 TFlops | 156 TFlops |
| Peak FP16 TensorCore | 125TFlops | 312 TFlops | 312 TFlops |
| Peak BF16 TesnorCore | N/A | 312 TFlops | 312 TFlops |
| Peak INT8 TensorCore | N/A | 624 TOPS | 624 TOPS |
| Peak INT4 TensorCore | N/A | 1248 TOPS | 1248 TOPS |
| HBM2/HBM2 | 16 or 32 GB | 40 GB | 80 GB |
| bandwidth | 900 GB/s | 1555 GB/s | < 2000 GB/s |
| Dev I/F | NVLink2.0 or PCIe x16 | NVLink3.0 or PCIe x16 | NVLink3.0 or PCIe x16 |
のようになっています。
V100からA100へは、CUDA Coreの性能自体は3割ぐらいの強化にとどまっています。
が、一方で、TensorCoreの強化が目覚ましいですね。あとメモリ帯域。HBM2eを採用したA100(80GB) では、なんと2TB超を達成しているため、つまるところ、B/Fが0.1にまで戻ってきた…!なんてこった!!
さて、Voltaアーキテクチャからのアップデートは以下の通り
- SM構造の改善
- 第三世代TensorCore
- L1キャッシュの容量増加
- 非同期メモリコピー
- L2キャッシュコントロール命令の追加
- Multi Instance GPU(MIG) の実装
- 第三世代NVLink
- ...
といった感じです。
SM構造の改善
毎度おなじみのSMの中身見るコーナー。
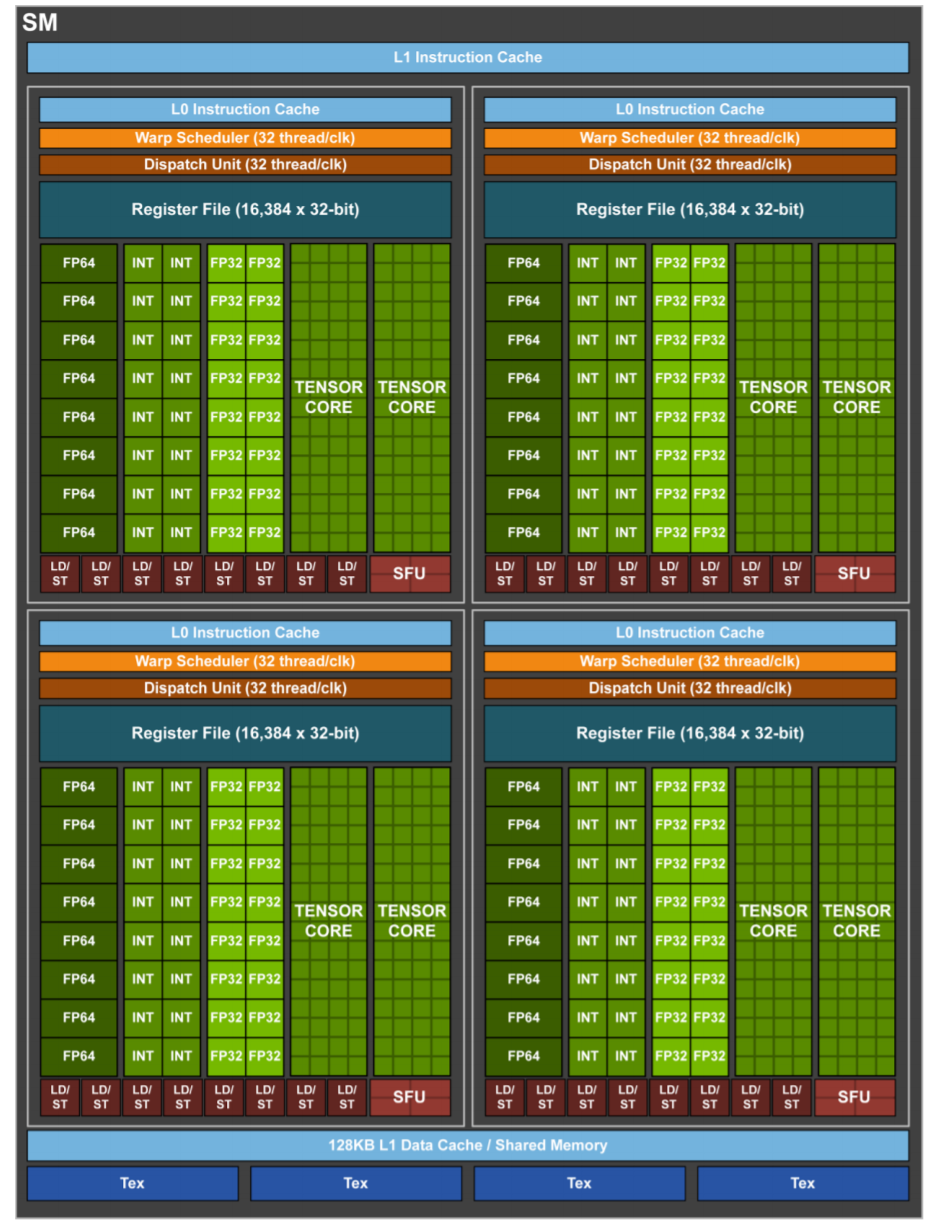
まずはVoltaアーキテクチャのSMから。
(引用元: Volta architecture Whitepaper)
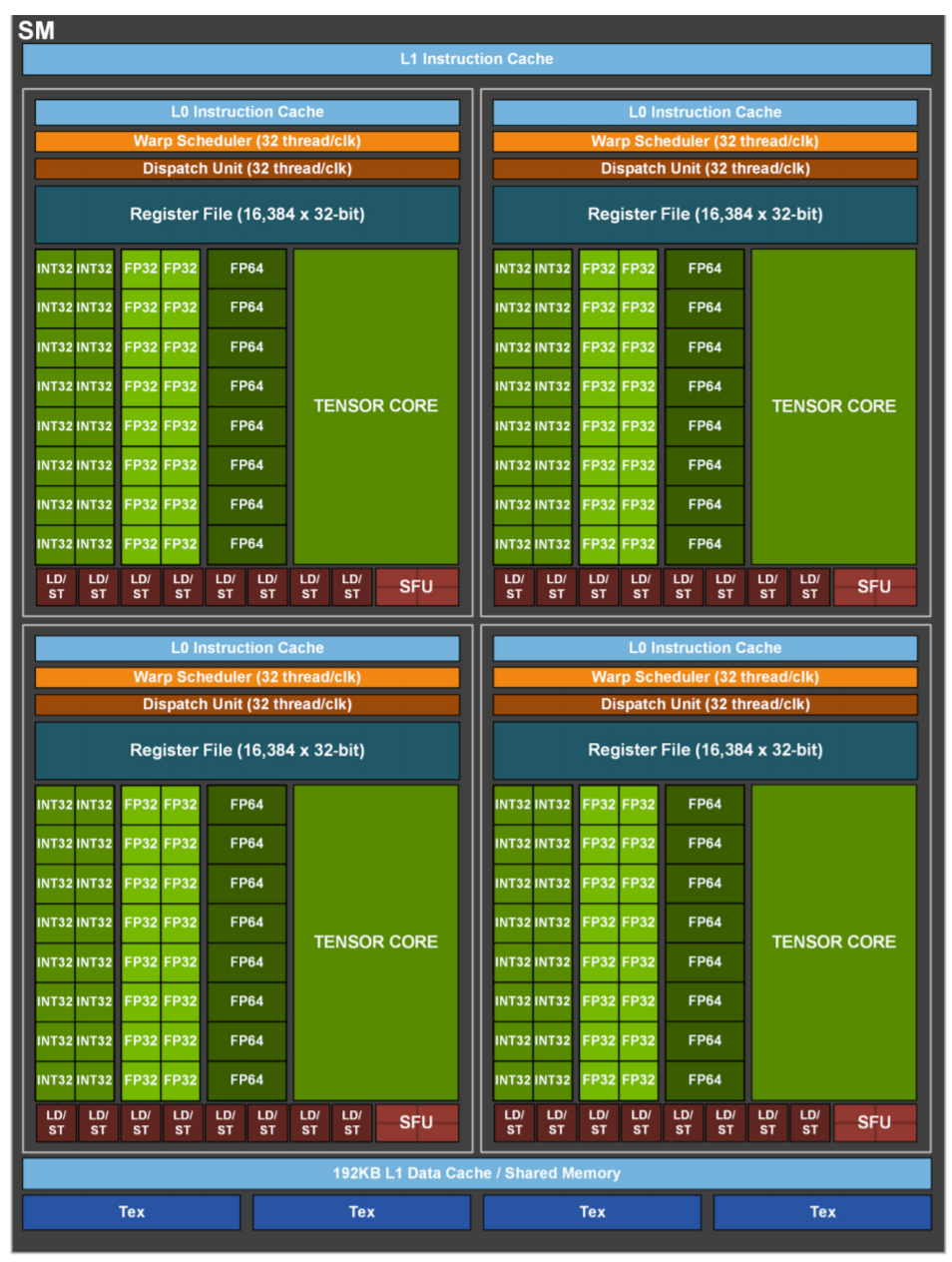
続いて、AmpereアーキテクチャのSM。
(出典: Ampere architecture whitepaper)
ブロックダイアグラムから見えるSMの構造自体は、TensorCoreの数が変わったことぐらいでしょうか。SMあたり8個あったTensorCoreが、SMあたり4個に減っています。
第三世代TensorCore
TensorCoreですが、第三世代に到り、なんと倍精度演算をサポートしました。
まぁこれに関しては、Top500に両足突っ込んでいる身からすると、ちょっといろいろ思うところはありますが、それでも「いかなる手段を使ってでも顧客に最速のものを提供する」という観点から考えれば、回路にするのは当然なことだと思います。
また、TensorCoreの数を減らす代わりに、中身の構造を見直すことで、SMあたりのスループットを2倍にしました。つまりTensorCoreの効率はVoltaアーキテクチャ比で4倍になっています。どういうことなの?
どういうことかというと、第二世代TensorCoreはで演算単位が4x4x4でしたが、第三世代TensorCoreでは演算単位が8x4x8になっています。1クロックあたりの演算量が4倍になっているわけですね。これは結構すごい。主にデータ供給的な意味で。これを支えるのが、後述するデータ供給パスの効率化だったりするわけですが。
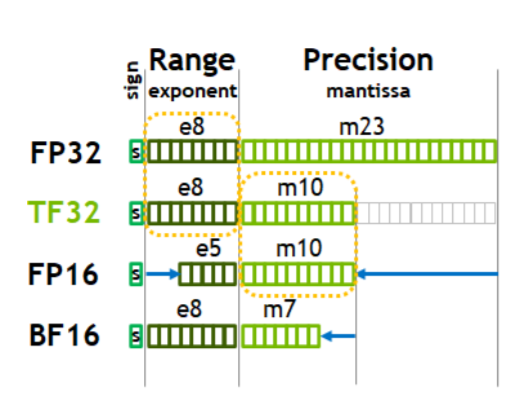
あと特徴的なのは、FP32の代わりにTF32というフォーマットを使用することで、精度を落とすことなく、演算性能を圧倒的に強化したことでしょうか。
TF32はFP32の仮数部だけを落としたようなビット表現をしています。あるいは言い換えるならFP16の指数部を拡張したような。平たく言うとFP32とFP16の中間のビット表現です。
(出典: Ampere architecture whitepaper)
プログラムレイヤでは、入力はFP32, 出力もFP32になるということで、基本的にはユーザーはTF32の存在を意識することなく、高速な計算結果を得ることができるというものです。
L1キャッシュの容量増加
Voltaアーキテクチャから、L1キャッシュとShared Memoryが統合されましたが、Ampereアーキテクチャに到り、そのキャッシュが128KBから192KBに増加しました。1.5倍!
正直、SRAM増えるの面積にクリティカルヒットするので良く増やせるな…と驚きを隠せない…
非同期メモリコピー
これがすごいんですよね。
みんな大好きDMA。
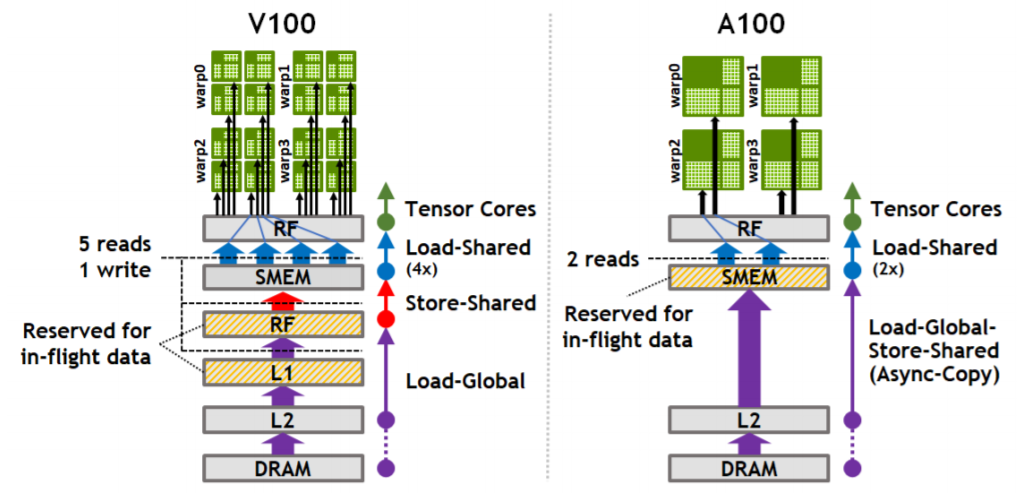
どういうことかというと、Shared Memoryにデータを置こうと思った時、Voltaアーキテクチャまでだと、CUDA Coreを経由して置くしかなかったわけなんですよね。左図のように、CUDA Coreのロード命令でL1までいって、一度レジスタに載せた後Shared memoryに置くしかなかった。そのため、もう一度CUDA Core / TensorCoreで使おうとしたときはレジスタに載せ直す必要がありました。
一方、Ampereアーキテクチャでは、グローバルメモリからShared Memoryに対してDMAをかけられるようになったので、余計なパスを通る必要がなくなりました。レジスタも節約できるし、なんなら転送中に裏で別の処理を行うこともできる。やっぱりみんなDMAが大好きなんだなって…
L2キャッシュコントロール命令の追加
多層キャッシュにおける最適化の厄介なところというのは、「キャッシュの気持ちになる」ということで、つまりどういうことかというと、「このデータはこの処理のタイミングでこのレベルのキャッシュにいてくれるか?」(追い出されてないか?) ということです。それって結構厄介で、残っててほしいデータを遺すためには、そういう触り方をするように頑張らないといけないわけです。だからみんな明示的にコントロールできるDMAが大好きなわけですが。キャッシュをaddressableにしよう? それスクラッチパッドっていうんだわ。
Ampereアーキテクチャでは、GPU全体をまたぐL2キャッシュというのが巨大にどんと(40MBほど) あるわけですが、このキャッシュを(できるだけ) 残しておく命令が追加されました。
Multi Instance GPU(MIG) の追加
これはみんな欲しかったヤツ。
実はですね、NVIDIAのGPUはその昔から1つのGPUを別プロセスから同時に使用して複数のタスクを実行する取り組みっていうのは結構やられていたんですよ。その昔はMulti Process Service(MPS) と呼ばれていましたけれども。Pascalアーキテクチャではソフトウェア制御だったんですが、Voltaアーキテクチャではハードウェア支援が入り、そしてAmpereでは完全にもろもろわけて、MIGという機能に進化したわけですね。
例えば、1つのA100の上で3つのGPUインスタンスを立ち上げた時はこんな感じの模式図になります。
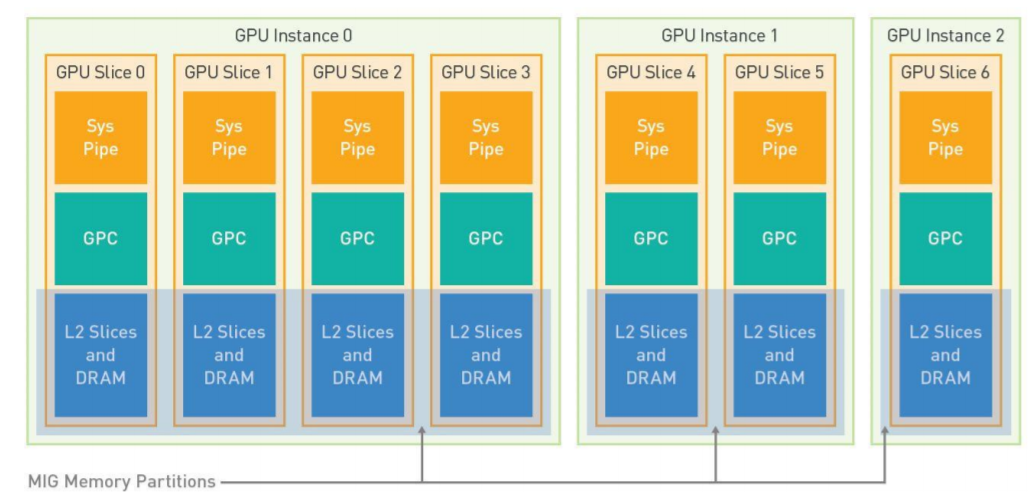
GPU Sliceというのは、ハードウェア的には1つのGPCに対応しており、そのため、A100で使えるMIGのインスタンスの数は7が最大になっています。この時HBMの割り当てとかはどうなるんでしょうね? GPCがHBMのPHYをどういう風にハンドルしてるのかわからないので何ともですが…L2でいい感じにインターリーブして吸収してくれんのかしら?
こういう機能ですが、結局、fp64で20TFlops、TF32で156TFlopの単一性能というのは、実は持て余してしまうことが多いというのが現実なのかという気はします。まぁだからと言って性能を相対的に落としていいかというとそんなことはなく、大きなものでなければできないこともあるので、大きなものを小さく分けて使えるようにするというアプローチが今のところ最善なんじゃないかと思いますね(誰に向けたアピールなんだ
- 第三世代NVLink
Summitでは300GB/sだから偉大って言ったな。
こっちは600GB/sだ(ド ン
毎回毎回倍にしていくのも相当すごいと思いますよマジで。
DGX-2からNVSwitchという機構で、デュアルCPU間のデバイスでもまたいで高速に接続できるようになっているようですが、NVSwitchの資料が全然ないのでここについてはあんまり書くのは止めておきます。
まとめ
- DGX SuperPODについて述べました。
- NVIDIA A100の強力さについて述べました。
- 26.195 GFlops/Wは超強力だと思います。