MNIST
import文
import torch
# 基本モジュール
import torchvision
# 画像関連
import torchvision.transforms as transforms
import torchvision.datasets as datasets
# 画像用データセット諸々
import numpy as np
import torch.nn as nn
# ネットワーク構築用
# torch.nn パッケージ全体は、単一のサンプルではなくサンプルのミニバッチの入力をサポートするだけ
import torch.nn.functional as F
# ネットワーク用の様々な関数
import torch.optim as optim
import matplotlib.pyplot as plt
# グラフプロット用
データのダウンロード
# データの成形
Transform = transforms.Compose(
[
transforms.ToTensor(),
# tensor変換
transforms.Normalize((0.5,), (0.5,))
# 正規化
]
)
-
torchvision.transforms.Compose- 引数で渡されたlistを先頭から順に実行していく
[trasforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))]- Tensor化 → 正規化
- このTransformフィルタによって、MNISTの各ピクセルの値の数値の範囲を
0〜1から-1〜1の範囲の分布になるように変換する
-
transforms.ToTensor()- Tensor変換
-
transforms.Normalize()- 正規化
- 引数は(訓練データの平均, 分散)
- 入力画像を平均0, 分散1に標準化する
訓練用データセット定義
trainset = datasets.MNIST(
root = '/Users/tefu/Git/MNIST',
# 格納ディレクトリ
download = True,
# Webから取得する
train = True,
transform = Transform
)
-
trainset- ニューラルネットワークの訓練用データ
-
root- 格納ディレクトリをパス指定
-
download- Webから取得する
- 取得済みの場合、
downloadは無視される
-
train = True- 訓練データを指定
-
Falseのときテストデータ -
/Users/tefu/Git/MNIST/processed/training.ptからデータを生成する
-
transform- Transformフィルタにかける
trainloader = torch.utils.data.DataLoader(
trainset,
batch_size = 100,
# バッチサイズを指定
shuffle = True,
num_workers = 2
# 並行処理の数
)
-
PyTorchでは、
Dataloaderという形でデータを取り扱う -
Dataloaderには、バッチサイズごとにデータとラベルがまとめられている -
データは
torch.tensorというテンソルの形で扱うが、Dataloaderにおけるデータの形は(batch, channel, dimension)という順番になっている -
torch.utils.data- データセット読み込み関連の関数
-
torch.utils.data.DataLoader()- 第一引数にデータセットを取る
- 先ほど定義した
trainsetを置く
-
trainset- MNISTのデータを扱うためのクラスインスタンス
-
ミニバッチ法
- N個の訓練データからランダムにn個を取り出す
- n個の学習を行う
- 再度ランダムにn個取り出し、取り出したデータの総計がN個になるまで繰り返す
-
batch_size = n- 一度に取り出すデータの数を指定
-
nはデータセットの全データ数を割り切れる値
-
shuffle = True- データの参照の仕方をランダムにする
-
num_workers- 並行処理を行う数を指定
- デフォルトはメイン一つのみ
testset
testset = datasets.MNIST(
root = '/Users/tefu/Git/MNIST',
download = True,
train = False,
transform = Transform
)
testloader = torch.utils.data.DataLoader(
testset,
batch_size = 100,
shuffle = False,
num_workers = 2
)
-
testset- ニューラルネットワークの性能テスト用データ
プロット用データ記録リスト
history = {
'train_loss' : [],
'test_loss' : [],
'test_acc' : [],
}
ニューラルネットワーク構築
class Net(nn.Module) :
def __init__(self) :
# ネットワーク層の定義
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
# 畳み込み層
self.pool = nn.MaxPool2d(2, 2)
# プーリング層
self.dropout1 = nn.Dropout2d()
# ドロップアウト
self.fc1 = nn.Linear(12 * 12 * 64, 128)
# 全結合のネットワーク
self.dropout2 = nn.Dropout2d()
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# 順伝播の計算
x = F.relu(self.conv1(x))
# self.conv1(x)のニューロンの出力をReLUによって変換
x = self.pool(F.relu(self.conv2(x)))
x = self.dropout1(x)
x = x.view(-1, 12 * 12 * 64)
# 1次元データに変えて全結合層へ
x = F.relu(self.fc1(x))
x = self.dropout2(x)
x = self.fc2(x)
return x
net = Net()
# Networkの使用を宣言
-
class Net(nn.Module)-
torch.nn.Moduleクラスを継承して、オリジナルのネットワークを構築
-
ネットワーク層
-
def __init__(self)- ネットワーク層の定義
-
__init__→ 初期化メソッド
-
nn.Conv2d()- 畳み込み層
- 引数は
(入力する画像の奥行き, 出力する画像の奥行き, フィルタのサイズ(タプル)(但し正方形の場合は整数に省略可能)) - 画像には縦横以外にも奥行きがあり、この奥行きをチャンネルという
- 画像の場合奥行きは色に対応しており、RGBだとチャンネル数は3、モノクロだと1となる
- フィルタは必ず入力層と同じチャンネル数を持つものとして自動的に設定される
-
conv2の入力データは32チャンネル(conv1の出力結果を利用しているためconv1の出力チャンネル=conv2の入力チャンネルとなる)、出力は64チャンネルである → 奥行き32の64個のフィルターが畳み込まれた
-
MaxPool2d()- プーリング層
- 特徴を強調する
- 引数は
(pool_size, strides) -
MaxPool2d(2, 2)-
pool_sizeダウンスケールする係数を決める値。2つの整数のタプル(垂直, 水平)で表すが、垂直=水平の時整数に省略可能 -
pool_size(2, 2)→ 画像をそれぞれの次元で半分にする -
stridesフィルタを適用する位置の間隔 →(2, 2)
-
-
Dropout- 学習時に一部のニューロンをわざと非活性化させることによって、過学習を防ぐ手法
-
nn.Linear()- 全ユニット(ノード)が結合されている全結合のネットワーク
- 入力データに線形変換を適用するクラス
- 引数は(入力サイズ、出力サイズ)
-
12 * 12 * 64→ その前までの3次元のデータを1次元にしたもの
順伝播
-
def forward(self, x)- 順伝播の計算
-
F.relu(self.conv1(x))-
ReLU入力が負のときは0、正のときはそのまま入力を出力するユニット
-
-
view- 1つ目の引数に-1を入れることで、2つ目の引数で指定した値にサイズ数を自動的に調整する関数
- Tensorの要素数が指定したサイズ数に合わない(割り切れない)場合、エラーになる
- サイズ数の指定も可能
-
net = Net()-
Net()クラスのインスタンスとなるnetを生成 - 定義した初期化関数
__init__()が実行される -
netがパラメータやNetworkの構造を保持している
-
GPUの利用
CUDA
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net.to(device)
# netをcuda上で動かす
損失関数の定義
criterion = nn.CrossEntropyLoss()
# 交差エントロピー損失関数
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0025)
# パラメータの更新
nn.CrossEntropyLoss()-
optimizer- 最適化のインスタンスを指定
-
SGD- パラメータの更新手法
- 引数は
(params, lr)-
params更新したいパラメータ - 微分可能でなければならない
- 今回は作成したNetworkのmodelのパラメータを入力
-
lr学習率(learning rate) -
float型を渡す -
momentum各パラメーターグループのサイクルにおける運動量 -
weight_decay重み減衰
-
- 確率的勾配降下法
- 損失関数
criterionを微分し、勾配を求める - この勾配にマイナスを欠けた方向に
net.parameters()(重み)を移動させることでcriterionを小さくする - 微分変数の移動を制御する値が
lr
- 損失関数
学習を行う
for epoch in range(100) :
# エポック数を指定
running_loss = 0.0
# 損失関数の累積値を0に初期化
for i, (inputs, labels) in enumerate(trainloader, 0) :
# ミニバッチ毎に学習をループさせる
inputs = inputs.to(device)
labels = labels.to(device)
# 入力データをGPUへ送る
optimizer.zero_grad()
# パラメータの勾配を0に初期化
outputs = net(inputs)
loss = criterion(outputs, labels)
# outputsとlabelsの損失関数を求める
# 出力と訓練データの正解との誤差を求める
loss.backward()
# lossの勾配を計算
optimizer.step()
# 計算した勾配を用いて`net.parameters()`を移動
# 重みの更新
running_loss += loss.item()
# 損失関数の累積を計算
if i % 1000 == 999 :
# 1000バッチごとに損失関数の平均値を表示
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
# 損失関数の累積値を0に初期化
history['train_loss'].append(loss.cpu().item())
print('Finished Training')
学習結果の確認
correct = 0
total = 0
test_loss = 0
with torch.no_grad():
for (images, labels) in testloader:
images = images.to(device)
labels = labels.to(device)
# GPUに送る
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
# 確率が最大のラベルを取得
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 正解ならば正解数をカウントする
history['test_loss'].append(test_loss / total)
history['test_acc'].append(float(correct / total))
print('Accuracy: %.2f %%' % (100 * float(correct/total)))
-
torch.no_grad()- パラメータの保存をしない → メモリ溢れを防ぐ
Out
99.17%
データ数の確認
print(len(history['train_loss']))
print(len(history['test_loss']))
print(len(history['test_acc']))
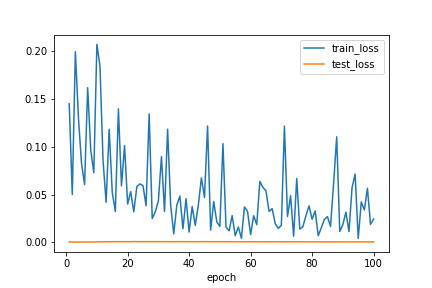
グラフにプロット
# 結果の出力と描画
plt.figure()
plt.plot(range(1, 101), history['train_loss'], label='train_loss')
# x, yのsizeを揃える
plt.plot(range(1, 501), history['test_loss'], label='test_loss')
plt.xlabel('epoch')
plt.legend()
plt.savefig('loss.png')
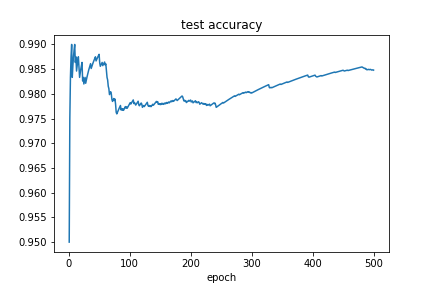
plt.figure()
plt.plot(range(1, 501), history['test_acc'])
plt.title('test accuracy')
plt.xlabel('epoch')
plt.savefig('test_acc.png')