想定読者
Pytorch初学者です。
Pytorchのニューラルネットワーク(CNN)のチュートリアル1.3.1について理解したので解説します。
- CNNの仕組みはふんわり掴めている
- Pythonはなんとなく触ったことがある
- 初めてPytorchを勉強しようとしたものの公式チュートリアルよく分からない
という方向けの記事です。そのため、割と丁寧に書いています。必要なところだけサク読みしてください。
また、今回はあくまで公式チュートリアルの理解に焦点を当てており、チュートリアルに出てこない引数等については説明しません。
この記事が解説するのはPytorch Tutorial 1.3.1です。
このチュートリアルでやること
このチュートリアルでは、「2次元の画像をニューラルネットワークに入れて目的関数まで出し(順伝播:forward propagation)、その後各パラメータ値を更新する(誤差逆伝播法:backpropagation)ところまでを、Pytorchではどのようにやるのか」ということを説明しています。
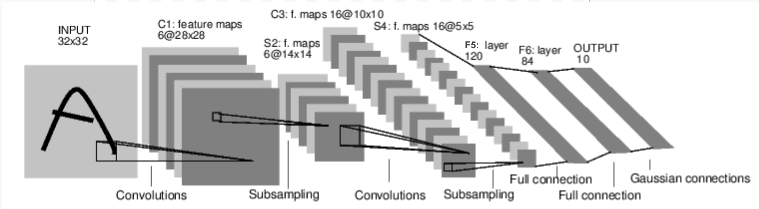
画像引用元:[Pytorch Tutorial 1.3.1]
(https://pytorch.org/tutorials/beginner/blitz/neural_networks_tutorial.html#backprop
)
もう少しだけ詳しく概観すると、上の通り、画像の畳み込み→プーリング→畳み込み→プーリング→一次元配列に変換→全結合のネットワークで出力層(10のノード)まで持っていく、というイメージです(この後それぞれ解説してます)。
その後、上の画像には書かれていませんが、この出力結果と予め持っている答えを照らし合わせて目的関数(今回は平均二乗誤差)の値を出して、パラメータの値を更新します。
(ちなみにこのモデルは、手書き文字のようなシンプルな物体認識に最適だとして1998年にCNNが最初に取り上げられた際に、Object Recognition with Gradient-Based Learningという論文で紹介された5層のLeNetです。)
さて、もっと細かいことはコードを書きながら見ていきましょう。
モデルを作る
import torch
import torch.nn as nn
import torch.nn.functional as F
まずは、torchをimportです。nnはパラメータを持つ層、Fはパラメータを持たない層がそれぞれ入っているモジュールです。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 3x3 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
さて、ここではネットワークが定義されています。
Pytorchではnn.Moduleを継承するクラス(ここではNET)を作成し、ネットワークはこのクラスの中に定義します。
上にあげたコードを分割しながら、3つのメソッドについてそれぞれ説明していきます。
パラメータを持つ層の入った__init__
def __init__(self):
super(Net, self).__init__()
1つ目はパラメータを持つ層での処理の仕方についてです。基本的にパラメータを持つ層はコンストラクタ__init__の中に入れられます。
まずはsuper(Net, self).__init__()で親クラスのコンストラクタを継承しています。子クラスでコンストラクタを生成すると上書きされてしまうので、親クラスのコンストラクタを引き継ぎつつ今回追加が必要な部分をこれから書き足すようなイメージですね。ちなみにsuper(Net, self).__init__()はsuper().__init__()のように省略して書いてOKです。
畳み込み層
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
conv2Dは2次元の畳み込みをする際に使われるクラスです。つまりここでは、画像の縦横が圧縮されるようなイメージです。引数はそれぞれ(入力する画像の奥行き(インチャンネル),出力する画像の奥行き(アウトチャンネル),フィルタのサイズ)です。
チャンネル(奥行き,深さ)って何?
画像には縦横以外にも奥行き(深さと訳されたりしてます)があり、この奥行きをチャンネルといいます。奥行きは画像の場合は色に対応しており、RGBだとチャンネル数は3、モノクロだと1です。これにフィルタを畳み込みますが、このフィルタは必ず入力層と同じチャンネル数を持つものとして自動的に設定されます。例えば入力のチャンネル数が3だったら、フィルタのチャンネル数も自動的に3です。
たとえば、
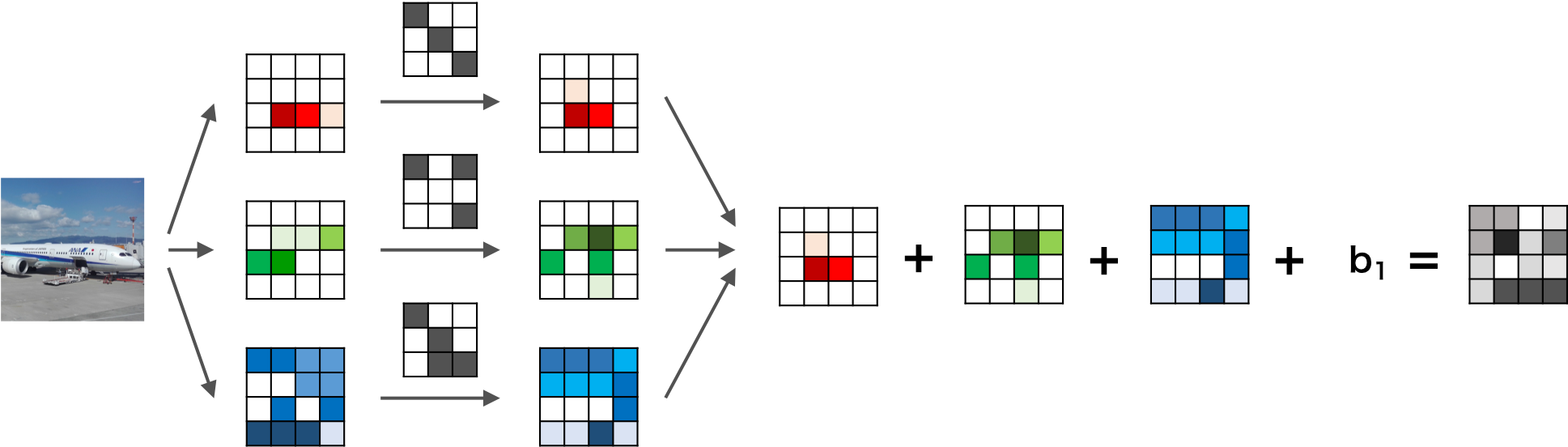
画像引用元:https://axa.biopapyrus.jp/deep-learning/cnn.html
このように、入力画像のチャンネル数が3だった場合はフィルタのチャンネル数も3になります。つまり、R,G,Bにフィルタの各チャンネルが畳み込まれ、その和として1つの特徴量マップができます。
そして、フィルタを何枚用意するかによって、出力の数が変わります。
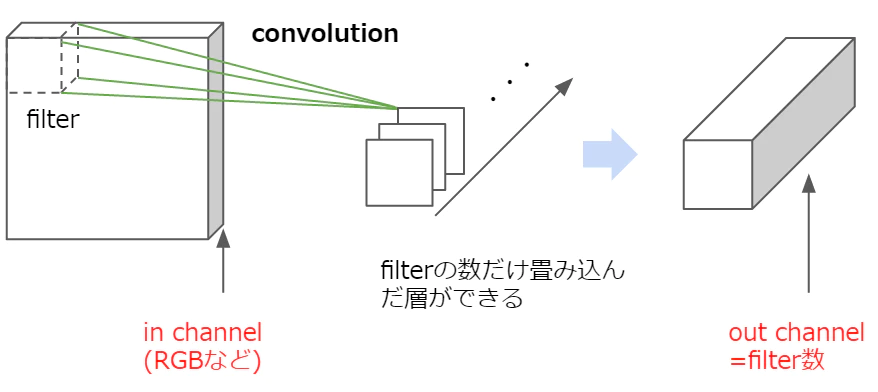
画像引用元:https://qiita.com/icoxfog417/items/5aa1b3f87bb294f84bac
最初のconv1の引数を見てみると、入力データは1チャンネル=モノクロ、出力は6チャンネル、フィルタのサイズは3×3です。つまり、入力データと同じ奥行き1のフィルターを6つ用意して畳み込んだことによって6つの特徴マップが出力されたということです。
次のconv2は入力データは6チャンネル、出力は16チャンネルなので、奥行き6の16個のフィルターが畳み込まれたということです。出力の際の画像のチャンネル数は必ずフィルタの数になります。
全結合層
次に、nn.Linearは入力データに線形変換を適用するクラスで、引数は(インプットされたユニット数、アウトプットするユニット数)です。全ユニット(ノードとも言います)が結合されている全結合のネットワークです。
self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
さて、ここでいきなり1666(=576)という数字が出てきていますが、これはその前までの3次元のデータを1次元にしたものです。
この全結合層に来る前の畳み込み層で画像データは16チャンネルになっていました。なので1つのデータは(チャンネル数,縦,横)=(16,縦,横)の3次元データです。このデータを全結合層に持ってくるためには、3次元のデータを1次元にする必要があります。今回のモデルでは縦・横が6の画像がここで入ってくると設定されており、1666=576が全結合層の最初の入力層のノード数になっているわけです。
なので、もしこのモデルに入れる画像データが、全結合層の前に縦横66になっていない場合は、例えばこの層の前に66に変更する層が必要になってきます。
順伝播を記述するforward
次にforwardというメソッドについてです。ここでは、引数としてデータ(x)を受け取り、出力層の値を出すまでのネットワークを記述しています。
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
ここでは、
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d -> view -> linear -> relu -> linear -> relu -> linear
という順伝播の流れが記載されています。パラメータを持つ層についてはすでに説明をしたので、それ以外の層について説明をしていきます。
F.relu関数は畳み込まれたデータに対して非線形処理を行う活性化関数の1つである、ランプ関数です。ReLU(x)=max(x,0)であり、データが0より大きければその値を出力し、0より小さければ0を出力します。
max_pool2d関数は二次元の最大値プーリングを行います。ここでは22の窓を使っています。図にすると以下のようなイメージです。
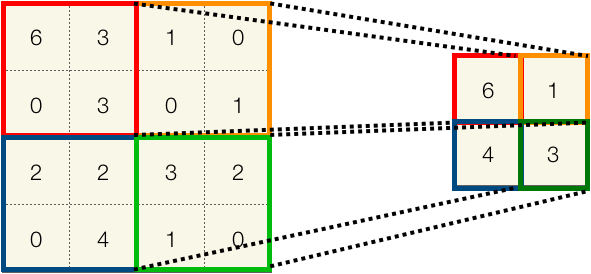
左上から順に窓の中の最大値を出力しています。プーリングはストライドの設定などなく、枠線がかぶらないように演算されていきます。今回は22なので、ここで縦横のサイズが2分の1に圧縮されていますね。
view関数については少し詳しく説明します。
viewは,入力データと同じ数字の羅列を、形状が異なる新しいテンソルにして返す関数です。これは全結合層の前に画像データを1次元データに変換するときに使います。
例えば、
>>>x = torch.randn(2,2)
>>>x
tensor([[-0.2834, -0.3660],
[-0.1678, -0.3034]])
>>>x.view(4)
tensor([-0.2834, -0.3660, -0.1678, -0.3034])
と言ったようにデータの形を変えることができます。
今回は引数の最初に-1があります。これは、その他(今回であれば2つ目)の引数に合わせて1つ目の次元のサイズを適切に調整してくれるものです。
例えば、
>>>x = torch.randn(4,3)
>>>x
tensor([[-1.2163, 1.6905, 0.1850],
[-0.2123, 0.5995, 0.7282],
[-0.5564, -0.1090, -0.8454],
[-0.5643, 1.2565, -0.5475]])
>>>x.view(-1,6)
tensor([[-1.2163, 1.6905, 0.1850, -0.2123, 0.5995, 0.7282],
[-0.5564, -0.1090, -0.8454, -0.5643, 1.2565, -0.5475]])
こんな感じです。「43をx6に変更して」、というと自動的に最適な2*6に変更してくれるということです。
今回のx = x.view(-1, self.num_flat_features(x))について考えましょう。
もとの画像データが(16,6,6)なら x.view(576)で良さそうなのですが、実はもともとの入力テンソルは(サンプル数,チャネル数,縦,横)という4つの次元のテンソルです。
これまでは入力データを1つの画像と考えていたのでサンプル数について触れていませんでしたが、機械学習では基本的にミニバッチで複数の画像を処理したあとにパラメータを更新するため(Pytorchの'torch.nn'はミニバッチを利用する前提で作られています)、入力データにはサンプル数という情報も含まれているわけです。
そこで、ここではアウトプットの形状を(サンプル数、チャンネル数×縦×横)として、各サンプルごとの特徴量が一次元配列となるようにすることで、サンプルごとの特徴量を全結合層の開始ノードとしたいわけです。
x = x.view(-1, self.num_flat_features(x))とは、今回はx = x.view(-1, 576)です。このself.num_flat_features(x)は1サンプルあたりの特徴量の数を計算するメソッドとして作られているため、このメソッドで計算した結果をここに代入しているだけです。(self.num_flat_features(x)についてはこのあと触れます。)
このforwardメソッドで順伝播のモデルを作ることによって、backward関数も定義されたことになります。backward関数は順伝播で来た道を逆に戻り、目的関数についての勾配を求めていくだけなので、順伝播のネットワークが組まれれば、この計算式についても自動的に作られるということです。
特徴量の数を数えているnum_flat_features(x)
ここでは、サンプル数以外の特徴量を一次元化するために、チャンネル数×縦×横をしているだけです。
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
入力データの最初のサンプル数以外の次元を掛けているだけです。
[1:]は(0,16,6,・・・)の16以降(=インデックス[1]以降)を抽出する、ということです。
num_features *= s = num_features = num_features * s です。
つまりここでは、(サンプル数,16,6,6)なので→(16,6,6)とした後に、1画像あたりの1666をして特徴量の数を出しているわけです。
さてこれでモデルの設計図は完成です。
インスタンス化しましょう。
>>>net = Net()
>>>print(net)
Net(
(conv1): Conv2d(1, 6, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=576, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
機械学習の処理では自分が定義したクラス(ここではNet()クラス)をインスタンス化したオブジェクトを使って学習を行っていきます。
画像サイズの整理
念の為、このモデルはどの画像サイズを想定したものなのか、ここまでの画像サイズの変化について整理しましょう。
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d -> view -> linear -> relu -> linear -> relu -> linear
今回「LeNetの入力データは3232が想定されていますよ」とpytorchの公式チュートリアルにも書いてあるんですが、今回のパラメータだと30が最適だと思います。
30×30のデータを入れる→畳込みのフィルタサイズが(33,1ストライド)なので2828→プーリング(22)で1414→畳み込み(33,1ストライド)なので1212→プーリング(22)→66で全結合層へ投入、ですね。
もとの論文では、最初の畳み込み層は55のフィルタサイズを使っているので、その場合3232が最適ですね。
(pytorchの'nn.MaxPool2d'プーリングは小数点以下は切り捨てられるので、一応今回のパラメータでも3232を入れることは可能ではあります)
パラメータを確認
さて、ここでパラメータを確認しておきましょう。
学習されるパラメータはnet.parameter()で求めることができます。
>>>params = list(net.parameters())
>>>print(len(params))
>>>print(params[0].size()) # conv1's .weight
>>>print(params[1].size())
10
torch.Size([6, 1, 3, 3])
torch.Size([6])
今回パラメータは10個です。
最初の畳み込み層には[6, 1, 3, 3]と[6]のパラメータがあります。
畳み込み層でいうパラメータとはフィルタの値のことです。
このフィルタの値がパラメータであり、学習によって更新されていくものなので、6(出力チャネル数)×1(入力チャネル数)×3(縦)×3(横)+6(バイアス)です。
次の畳み込み層は、同じ理屈で[16,6,3,3]と[16]です。
ここまでわかればあとの全結合層の6つは分かりますね。
[120,576],[120],[84,120],[84],[10,84],[10]です。
データを入力
それでは試しに先程のモデルに画像データを入力したこととして適当な数字を入れてみます。
>>>input = torch.randn(1, 1, 32, 32)
>>>out = net(input)
>>>print(out)
tensor([[-0.0843, 0.0283, 0.0677, 0.0639, -0.0076, -0.0293, 0.1049, 0.2183,
-0.1275, -0.1151]], grad_fn=<AddmmBackward>)
しっかり10個出力されていますね。
ちなみにinputの際の4次元データの最初は1バッチあたりの画像の数です。
損失の計算
目的関数は(出力値、ターゲット(答え))のペアを入力として受け取り、出力結果が出したかった答えからどれだけ離れているのか計算します。
nnパッケージには損失関数がいくつかありますが、今回は出力結果とターゲット間の平均二乗誤差を計算するnn.MSELossを利用します。
>>>output = net(input)
>>>target = torch.randn(10) # a dummy target, for example
>>>target = target.view(1, -1) # make it the same shape as output
>>>criterion = nn.MSELoss()
>>>loss = criterion(output, target)
>>>print(loss)
tensor(0.6110, grad_fn=<MseLossBackward>)
outputにモデルからの出力結果をいれ、targetにも今回は適当な数字を入れてモデルの出力結果と形を合わせています(モデルからの出力結果にはバッチ数も入っているので(1,10)です)。
損失関数はインスタンス化して使います。
パラメータの更新
pytorchのoptimというモジュールには様々なパラメータの更新手法があり、簡単に誤差逆伝播法を行ないパラメータを更新していくことができます。
import torch.optim as optim
# create your optimizer
optimizer = optim.SGD(net.parameters(), lr=0.01)
# in your training loop:
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # Does the update
optim.SGD(net.parameters(), lr=0.01)は、確率的勾配降下法を使って、指定のパラメータ値(net.parameters())を学習率0.01で更新せよ、という意味です。
optimizer.zero_grad()
これは,目的関数の勾配を0にせよ、ということです。これは今までTransflowのようなdefine-and-runのフレームワークに馴染みがある人には、必要性が「?」かもしれませんが、Pytorchやchainerでは事前に逆伝播の計算処理について規定する必要がなく、勾配処理に必要になる計算履歴が全て記憶されていることによって柔軟にパラメータの更新ができるわけですが、逆に言えば、いつこの勾配の計算処理が終わるのか、ということについては規定されていません。そのため、必要な箇所でこれを0にしないと、その前の入力データから計算された勾配に対して,新しいデータの勾配が累積されていってしまうために、正しい勾配の計算ができなくなりす。
つまりこの勾配を初期化する処理は、誤差逆伝播するたび(=バッチを作成するたび)に行う必要があります。
以上で、モデル作成→順伝播→損失関数を計算→誤差逆伝播でパラメータ更新までをPytorchで行う流れについて説明しました。
次は実際のデータを使ってモデルを動かしてみようというチュートリアルが待っているので、ぜひトライしてみてください。
おわりに
今回私が理解するにあたって色々なURLを参考にさせてもらったのでご紹介です。
どれもオススメです。
画像引用元
- Convolutional Neural Networkを実装する
https://qiita.com/icoxfog417/items/5aa1b3f87bb294f84bac - 畳み込みニューラルネットワーク(Convolutional neural network)
https://axa.biopapyrus.jp/deep-learning/cnn.html - Object Recognition with Gradient-Based Learning
http://yann.lecun.com/exdb/publis/pdf/lecun-99.pdf
続いて参考URLです
- 畳み込みニューラルネットワーク_CNN(Vol.16)
https://products.sint.co.jp/aisia/blog/vol1-16#toc-3 - 畳み込みニューラルネットワークの最新研究動向 (〜2017)
https://qiita.com/yu4u/items/7e93c454c9410c4b5427#fn3 - メディカルAI専門コース オンライン講義資料
https://japan-medical-ai.github.io/medical-ai-course-materials/index.html - Convolutional Neural Networks (CNNs / ConvNets)
http://cs231n.github.io/convolutional-networks/ - Why do we need to call zero_grad() in PyTorch?
https://discuss.pytorch.org/t/why-do-we-need-to-set-the-gradients-manually-to-zero-in-pytorch/4903