Deep Learning系のライブラリを試すのが流行っていますが、Exampleを動かすのはいいとしても、いざ実際のケースで使おうとするとうまくいかないことがよくあります。
なんとか動かしてみたけれど精度が出ない、データの加工の仕方が悪いのか、モデルのパラメーターが悪いのか、原因がぜんぜんわからん・・・という事態を乗り越えるには、やはり仕組みに対する理解が必要になってきます。
そんなわけで、本編では画像の用意という一番最初のスタートラインから、Chainerで実装したCNNを学習させるところまで、行うべき手順とその理由を解説していきたいと思います。
前段として理論編を書いていますが、ここではライブラリなどで設定しているパラメーターが、理論編の側とどのようにマッチするのかについても見ていきたいと思います。
なお、今回紹介するノウハウは下記リポジトリにまとめています。画像認識を行う際に役立てばと思います。
データの準備
データについては数万件などたくさん用意しないといけないと思われがちですが、最近の画像認識では学習済みのモデルを利用するのが一般的です。

CS231n Lecture11 Training ConvNets in practice, p26
学習済みのモデルは「学習させたタスク」しかできないのでは?(例えば猫の検知とか)と思うかもしれませんが、モデルの下層に行くほど画像の基礎的な特徴を抽出する能力が備わっています。
そのため、下層のレイヤはそのままに、上の方のレイヤだけ学習をさせることで(あるいは付け足すことで)、少ないデータでも識別性能を出すことができます。これをFine Tuning(またはTransfer Learning)と呼びます。
どれくらいのレイヤをそのままにすべきかは、自分の目的とするタスクが元の「学習させたタスク」とどれくらい近いかに依存します。
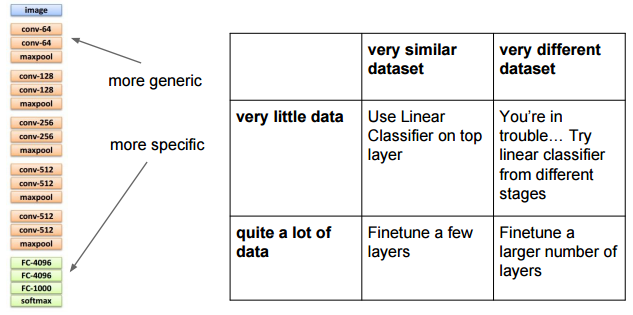
CS231n Lecture11 Training ConvNets in practice、p33
学習済みのモデルが使えるライブラリで有名なのは、Caffeになります。Caffeを用いたFine Tuningの手法については公式に記載があります。
Fine-tuning CaffeNet for Style Recognition on “Flickr Style” Data
ChainerではCaffeのモデルを読み込むことができるので、同様にFine Tuningが可能です。
Chainerでファインチューニングするときの個人的ベストプラクティス
学習する際に、せっかくとってきた学習済みモデルの値を変更したくないときは、volatitleのフラグを使って学習済みの下層部分への誤差伝搬を止めることができます。
TensorFlowについては以下にチュートリアルがあります。
Caffeのモデルを持ってきたい場合は、一応以下のようなツールがあります。
このように、先人たちの功績によって集めるべきデータの数はだんだんと少なくなってきています。今回も、学習済みのモデルを格納しておいたので利用してみてください(初めてgit lfsを使った)。
ただ、その分自分がベースとして使うモデルがどういうものなのかについての理解がより求められるようになってきている、ともいえます。
その点については次項で解説するため、ここでは画像データセットとして有名なImageNetからの画像データの取得について簡単に解説しておきます。
ImageNet
WordNetという語の概念構造をベースに、画像に対しタグ付けを行っているデータセットです。登録されている語(つまりラベル)の数は10万ほどで、各語に対し1000程度の画像を収集することを目指し活動が行われています。ILSVRC(ImageNet Large Scale Visual Recognition Challenge)で使用されているデータセットとしても有名です。
さて、このデータセットは研究者なら申請して許可が下りれば全部ダウンロードできます。そうでない場合、各ラベルに対する画像のURLは取得できるため、そこから自力で落とすことになります。なお、これ以外に画像特徴量のデータやオブジェクトの境界といったデータも取得可能です。

Downloadから、画像のURLを取得できます。ただし、リンク切れになっているものも多々あります。
リンク切れを回避しながら、なおかつ並列処理でダウンロードしたい、というのが人情なので作っておきました。
mlimages/mlimages/scripts/gather_command.py
これにてとりあえずダウンロードをして画像は準備できた、とします。
モデルの理解
集めた画像は、目的とするタスク、そして利用する学習済みモデルに合わせて加工する必要があります。そこで、ここでは実際のモデルのコードを追うことで理解を深めていきたいと思います。
説明に利用するのは、ChainerのAlexNetのコードです。これは画像認識におけるニューラルネットの活躍の端緒となった記念碑的なモデルです。なお、Chainer以外のライブラリ(Caffeなど)でもネットワークの定義はほぼ変わらないので、ここで説明する内容はChainer以外でも通ずると考えていただいて差し支えありません。
chainer/examples/imagenet/alex.py
非常に短いコードなので、以下に定義部分を抜粋して掲載します。
class Alex(chainer.Chain):
"""Single-GPU AlexNet without partition toward the channel axis."""
insize = 227
def __init__(self):
super(Alex, self).__init__(
conv1=L.Convolution2D(3, 96, 11, stride=4),
conv2=L.Convolution2D(96, 256, 5, pad=2),
conv3=L.Convolution2D(256, 384, 3, pad=1),
conv4=L.Convolution2D(384, 384, 3, pad=1),
conv5=L.Convolution2D(384, 256, 3, pad=1),
fc6=L.Linear(9216, 4096),
fc7=L.Linear(4096, 4096),
fc8=L.Linear(4096, 1000),
)
self.train = True
def clear(self):
self.loss = None
self.accuracy = None
def __call__(self, x, t):
self.clear()
h = F.max_pooling_2d(F.relu(
F.local_response_normalization(self.conv1(x))), 3, stride=2)
h = F.max_pooling_2d(F.relu(
F.local_response_normalization(self.conv2(h))), 3, stride=2)
h = F.relu(self.conv3(h))
h = F.relu(self.conv4(h))
h = F.max_pooling_2d(F.relu(self.conv5(h)), 3, stride=2)
h = F.dropout(F.relu(self.fc6(h)), train=self.train)
h = F.dropout(F.relu(self.fc7(h)), train=self.train)
h = self.fc8(h)
self.loss = F.softmax_cross_entropy(h, t)
self.accuracy = F.accuracy(h, t)
return self.loss
さて、自分でカスタマイズして使いたいと思った場合、最も重要なのが入力部分と出力部分になります。
入力部分については、画像のサイズ、グレースケールにしておくべきか否かといった点にかかわりますし、出力部分はFine Tuningを実装するにあたって継ぎ足しをしたり識別するクラス数を変えたりする際に重要になります。
まずは入力について。ポイントとなるのは以下の点です。
- 画像サイズ:
insize = 227 - 入力を受け取る一層目:
conv1=L.Convolution2D(3, 96, 11, stride=4)
重要なのは一層目の定義のほうです。Convolution2DのAPIによると、設定値は以下のように解釈できます。
- in_channel: 3
- out_channel: 96
- ksize: 11
- stride: 4
これらの項目値が何を表しているのか?ですが、ここで理論編の畳み込みに利用するフィルタの定義を引用します。
- フィルタの数(K): 使用するフィルタの数。大体は2の階乗の値がとられる(32, 64, 128 ...)
- フィルタの大きさ(F): 使用するフィルタの大きさ
- フィルタの移動幅(S): フィルタを移動させる幅
- パディング(P): 画像の端の領域をどれくらい埋めるか
まず、フィルタとは畳み込みに使う窓的なものです。以下のようなイメージで、この大きさなどで元の画像がどれくらい圧縮されるかが決まります。
では、フィルタの大きさによってどのように圧縮後のサイズが決まるのか、は下図を見るとわかりやすいです。
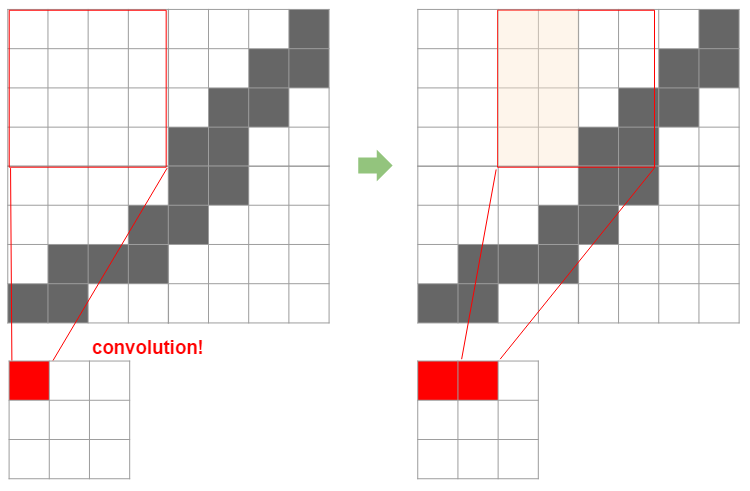
ここでは8x8の画像に対し4x4のフィルタを、2つずつスライドさせながら適用しています。この場合、最終的に8x8の画像は3x3に圧縮されます。ここで、元サイズを$N$、フィルタのサイズを$F$、スライド幅を$S$と圧縮後の画像幅は以下の式で求められます。
$$
(N - F) / S + 1
$$
この式に当てはめると、$(8 - 4)/2 + 1 = 3$で、きちんと3になることがわかります。パディング$P$で画像の周りに余白(実際は輝度0=黒にすることが多く、そういう意味では余黒)をとる際は、以下のようになります。
$$
(N + P \times 2 - F) / S + 1
$$
これは、下図を見るとわかりやすいです、余白サイズ×2が元のサイズに加わるということです。
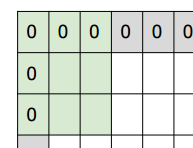
割り算が入っていることからもわかる通り、適用するフィルタの幅・スライド幅などはきちんと割り切れるように調整する必要があります。これが、他のモデルを利用する場合の第一の制約になります。
ここまでをまとめておきます。最初に挙げたポイントのうち以下3点を使うことで、フィルタ適用後の層の幅が計算できることがわかりました。
- フィルタの大きさ(F): 使用するフィルタの大きさ
- フィルタの移動幅(S): フィルタを移動させる幅
- パディング(P): 画像の端の領域をどれくらい埋めるか
フィルタ適用後の層の幅 = $(N + P \times 2 - F) / S + 1$
入力画像は、既存のモデルで使用されているフィルタに適合する(上記の式の結果がきちんと整数になる)必要がある
さて、残った最後の「フィルタの数(K)」は何にかかわるかというと、画像の「深さ(チャンネル数)」に関わります。
チャンネル数は画像における深さ要素のことで、画像的にはカラー(RGB)に対応します。そのため、一層目のチャンネル数は3のことが多いです。逆に、既存のネットワークを流用する場合でここが1になっていれば、それはグレースケールを表しているため前処理でグレースケールに変換する必要があります。
ここで、畳み込んだ後深さはどうなるのかを考えてみます。フィルタの深さは入力画像の深さに合わせるため(そうしないと計算できない)、畳み込んだ後は深さは常に「1」になります。
ここで、フィルタをもっと増やすとどうなるでしょうか。そうすると、深さが1の畳み込み層がフィルタの数だけ増えることになります(下図)。
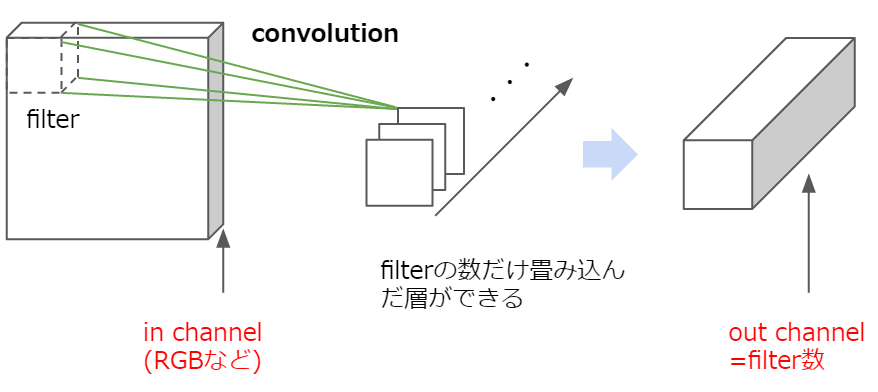
通常、CNNではこのように複数のフィルタを利用して畳み込みを行っています。つまり、「フィルタの数(K)」はそのまま畳み込んだ後の「深さ(チャンネル数)」になるということです。これは当然次の層の入力の深さと同じになります(コード中、conv1のout_channelとconv_2のin_channelは同じ値になっていると思います)。
ここまででフィルタに関するすべての要素を見てきたので、改めて第一層の定義を見直してみます。
- in_channel: 3 -> 最初の画像の深さ。RGB=3
- out_channel: 96 -> 畳み込んだ後の層の深さ = フィルタの数(K)
- ksize: 11 -> フィルタのサイズ(F)
- stride: 4 -> フィルタのスライド幅(S)
Convolution2Dにはpadのパラメーターもあり、これは当然パディング(P)に該当します。これでパラメータの理解はできました。そして、ここからAlexNetでは以下の制約があることがわかります。
- 入力画像のサイズは、11を引いた後4で割り切れる数である必要がある(設定されているサイズ227はこれを満たす)。※厳密には、以後の層の定義も満たす必要がある
- 入力画像は、RGBカラーで表されている必要がある
よって、画像のサイズは実は固定ではなく、条件を満たせば他のサイズでも使用可能です。ただ、事前に学習させた内容が適用されるかわからないのと、出力部分に影響が出ます。AlexNetでは6層目から線形関数になっており、ここからがいわば畳み込んだ結果を使って分類を行っている部分になります。Fine Tuningを行うならここを差し替えたりSVMにつなげたりということになると思いますが、それに際しては以下の定義を理解することが必要です。
Chainerの6層目の定義はfc6=L.Linear(9216, 4096)となっており、ここから入力の数が9216で出力の数が4096ということは明白ですが、入力の「9216」はどういう意味か分かるでしょうか。
畳み込み層からの出力は当然「幅×高さ×深さ」になるため、直前のconv5で「幅×高さ×深さ=9216」になっていることが推察されます。深さはconv5のout_channelが256であることから明らかなため、9216を256で割ると36、よって幅×高さ=36なので幅は6になっていることがわかります。この「6」は当然入力画像の幅が定義通り227だった時の場合なので、入力する画像のサイズを変えるならもう一層いれてサイズを調整するなどしないといけないことがわかります。
サイズの調整は当然畳み込んでもいいですが、重みを使わずサイズの調整、つまり幅の圧縮を行うプーリングを使うという手もあります(プーリングについての詳細は理論編のこちら参照)。
このプーリング層はAlexNetでも使われていて、実はconv5の段階では13だった幅がfc6では6になっているのはこのプーリングのためです。下図にfc6に至るまでの計算の過程を書いているので、興味がある方は追ってみてください。計算順序は、conv1>pool1>conv2>pool2>conv3>conv4>conv5>pool5>fc6になります(※conv3>conv4、conv4>conv5間にはプーリングはありません)。
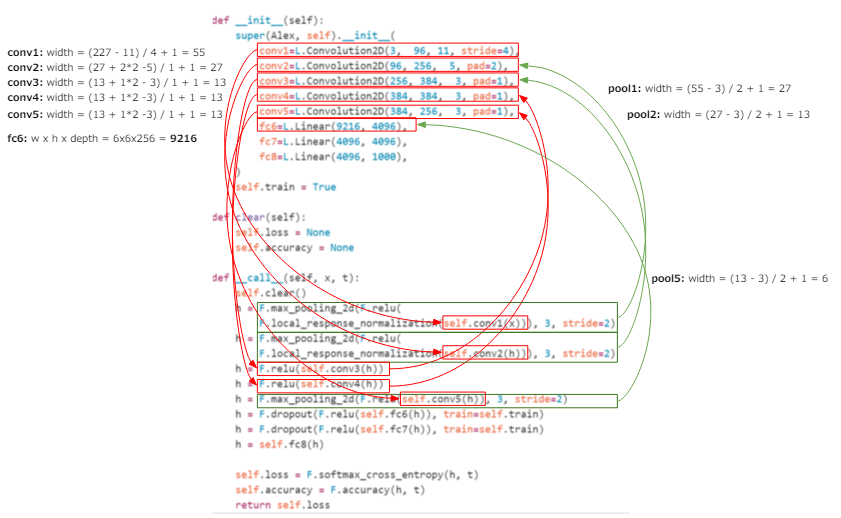
よって、大き目の画像を使うならこのプーリングでもう少し圧縮するようにすればいいということです(逆に小さいならプーリングしない)。前述のとおり、このプーリングは重みを使わないため、学習済みモデルから持ってきた重みは関係しません。よって、学習済みのモデルを使うなら学習して重みをもっている畳み込み層でなく、プーリングで調整するほうが良いでしょう。
最後に、学習済みモデルをカスタマイズする際のポイントについてまとめておきます。なお、これは理論的には、の話で実際使う上ではうまくいったりいかなかったりというのがあるとおもいます。私のほうでも、わかり次第またまとめていきたいと思います。
- 層の定義から、サイズ・カラーに関する制約がわかる
- 特定の層にFine Tuning用の学習機をつけたい場合、その入力数は入力した画像のサイズと各層のフィルタ定義を順に計算していくことで導出できる
- 最近はちょっと複雑なフィルタのかけ方をしたり層がものすごい深くなっていたりするので、勉強のため以外で計算するのはあまりお勧めできない。一番上の層は分類するクラス数に一致するはずなので、素直に一番上につけることを推奨。
- 入力画像のサイズを変更したい場合は、学習済みの重みをもつ畳み込み層は温存しプーリングで調整を行う
- 最近はPoolingをかませないのが主流となっているが、学習済みモデルを流用するために入れるのはありだと思う。
※「最近は」の情報は、Stanfordの講座参照(Lecture 7 p89)。 AlphaGoについてもちょっとのっている。CNNの理解は最先端のAIの仕組みの理解にもつながっているのだ。
データの前処理
ここまででモデルの理解ができ、どんなデータを用意すればいいかもわかりました。
ただ、実際学習させるときに必要なのは「画像」ではなく、それを数値的に表現した「行列」になります。この変換の過程にミスがあるとせっかくの学習済みモデルも役に立ちません。特に重要な点は、以下点になります。
- 行列変換
- 直感的には幅(W)x高さ(H)x深さ(K)
- 行列的に考えると、行列の行は高さ、列は幅に該当するので、行列的にはH x W x Kになる
- 学習する際は、慣例?としてさらにこれをK x H x Wに変換する
- 実際の処理は、chainer/examples/imagenet/train_imagenet.pyの
read_imageを参照。 - 深さの調整
- モデルはRGBを想定しているが輝度しかない、という場合は輝度の値を複製して調整する。輝度しかないのは、次元が2であることで判別可能(colorがないので2次元の行列での表現になるため)。
- 世の中にはRGBAという形式があるため、この場合Aを落とす
- 実際の処理は、Caffe/io.pyの
load_imageを参照。 - 画像データの正規化
- 全データセットから計算した平均を差し引くことで正規化する。なお、当然画像のサイズがすべてそろっていないといけないので注意。
- 平均の計算処理はchainer/examples/imagenet/compute_mean.pyを参照
- スケーリング
- RGBカラー、また輝度は0-255の値をとるので、これを0-1の値に変換するため255で割る
- 実際の処理は、chainer/examples/imagenet/train_imagenet.pyの
read_imageを参照。
今回作成したツールでは、画像を読み込んで深さの調整をしたうえで行列変換をしてくれるクラス(LabeledImage)を実装しました。
to_arrayとfrom_array行列化とそこからの復元が可能です。画像のリサイズ用のメソッドも積んでいるので、サイズ調整等の加工したうえで行列にできるようにしています。実装の参考にしていただければと思います。
平均化については実装はほぼ同様ですが、実際の画像として保存するようにしました。これはnumpyを使わない場合でも利用できるようにするほか、データの傾向を見られるという利点もあります。
以下はImageNetの猫系の画像から作成した平均画像ですが、何の特徴も見えないことがわかると思います。

これは良くはない傾向です。なぜなら、すべての画像に共通する何らかの特徴があれば、その部分だけ色などが変わっているはずだからです(人の顔なら、目や口の位置など)。もちろん画像の枚数が多ければこうした全体的に黒っぽいものになるのは当然ですが、あるクラスのみで作ってみるなど傾向をとらえるには使えると思います。
教師データの準備
さて、画像を用意しただけでは学習はできません。その画像に対し、それがどのクラスに分類されるのかといった教師データを作成してやる必要があります。これは、「画像のパス」「教師ラベル」をペアにして記載したフォーマットが用いられることが多いです(以下の感じ)。
tabby\51879196_5a4404873a.jpg 10
tortoiseshell\1802271715_d1b3acb8f4.jpg 13
tom\1433889998_6a42ce2633.jpg 12
これは当然人力でやっていると日が暮れるので、自動的作成したいです。画像をクラスごとにフォルダに収めている場合、フォルダ構造がそのまま教師データとなるので、これを利用して教師データを作成することができます。
今回作成したツールでも、簡単なスクリプトを作ってラベル付けを行いました(mlimages/mlimages/scripts/label_command.py)。
なお、スクレイピングなどで自動的に画像を集めていた場合、たまに開けなかったり教師データとして不適なものがあったりします。学習している際にこうした画像に当たり例外が飛んで数時間かけた学習が止まると泣きたくなるので、ここでそうした要素を排除しておくとよいです。
学習に際しては正規化のために平均画像を計算する必要があり(前述)、その際に本番同様の行列への変換や演算を行うので、そこでチェックをかけてもよいです。今回は平均画像計算の際に別途「平均計算に使用した(できた)画像」をファイルとして出力し、それを学習データとして使っています。
あと、データをテスト用と訓練用などに分ける、ちゃんとシャッフルしておく、といった点は通常の機械学習と変わりません。これは単純にファイルの分割や乱数を利用した処理で行えるので、そう手間ではないと思います。
モデルの学習
教師データの準備ができたら後は学習させるだけです。ここでの最大の考慮点は、パフォーマンスと監視です(運用管理みたいですが・・・)。
パフォーマンス
パフォーマンスについては、以下点が重要になります。
- GPU
- 並列処理
GPU。これは実際やって痛感したのですが、何はともあれGPUマシンを用意しましょう(AWSでも可)。CPUだと数日待っても精度が上がる確信が得られないのに比べ、GPUなら数時間でわかるか計算が終わります。
モデルの構成、学習率といったハイパーパラメーター、またバッチサイズなど、学習に際しては調整すべきパラメーターが多々あります。この検証・確認のサイクルをどれだけ速く回せるかが肝となるので、ハードで解決できるところはハードで解決してしまったほうが良いです。
並列処理は、これに比べソフト面での工夫となります。画像の学習に際しては、教師データには画像へのパスしか書いていません。そのため学習時に画像を読み込む必要がありますが、これを上から順に・・・とかやっているとただでさえ遅い学習がさらに遅くなるので、ミニバッチ(一度に学習させるデータのまとまり)内の画像は並列で読み込むといった工夫が必要になってきます。Pythonではmultiprocessing、3からはasyncioが利用できるので、これらのモジュールを利用して並列化できるところは並列化します。
監視
学習中は、きちんと学習が行われているかどうかを見ておく必要があります。
一定量の学習(1batch/epochなど)ごとに、誤差と精度を記録しておきます。また、途中でモデルを保存しておくことも重要です。単にコンソールに出力しているだけだと接続が切れたり万一落雷とかで飛んだ時に何も残らないので、ログファイルやらモデルファイルやら、とにかくディスクに残る形で記録をすることをお勧めします。
具体的な学習用スクリプトの実装としては、Chainerのexampleが参考になります。
chainer/examples/imagenet/train_imagenet.py
Pythonは3からasync/awaitが書きやすくなったので、Python3にするならmultiprocessingのところはもう少し書きやすくなると思います。今回作ったツールについてはPython3を使いました(ただ、ロギングはまだない・・・)。
mlimages/mlimages/training.py/generate_batches
これで一通りのポイントは解説し終えました。最後に、データの収集・教師データの作成・それを利用した学習、をまとめたスクリプトを参考に載せておきます。モデルには例の通りAlexNetを利用しています。
mlimages/examples/chainer_alex.py
実際に学習をさせる際の参考となれば幸いです。なお、このスクリプトはCPUでは2日たっても全然精度が上がりませんでしたが、GPUで計算させたところ2、3時間で50~60%の精度(accuracy)になりました。実際のモデルではExampleのように、見る間に精度が上がっていくことはありませんし、またその保証もありません。モデルに対する正当な評価をベースにブラッシュアップしていくには、やはり速度の貢献は大きい・・・ということを痛感した次第です。