1. 概要
大規模言語モデル(LLM)では、パラメータ数が膨大となりファインチューニングと学習・推論のデプロイの際にメモリ使用量と計算コストが大きな課題となっている。パラメータ効率の良いファインチューニング手法はPEFT(Parameter-Efficient Fine-tuning)として種々の手法が提案されており、ファインチューニング時にオプティマイザーが消費するメモリを削減することを目指しているが、学習済みのLLMの重み自体が非常に大きく、以前としてメモリ使用量削減は大きな課題となっている。
この研究では、大規模言語モデルの効率的なファインチューニング方法とモデルの軽量化手法として、PEQA(Parameter-Efficient Quantization-aware Adaptation)を提案している。PEFTとモデル軽量化の量子化手法を組み合わせた手法となっている。
2. 新規性
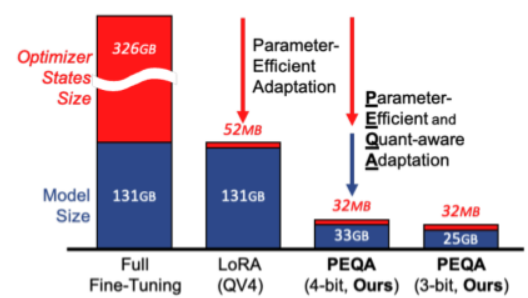
LLaMA-65Bの学習に使用されるDRAMの比較
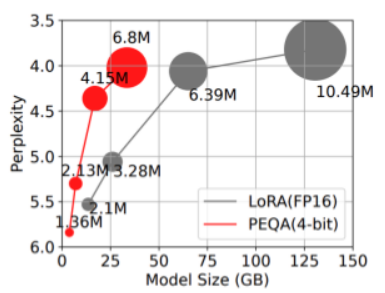
WikiText2データセットを用いたLLaMAの学習時のモデルサイズ比較
(Perplexityが小さいほど言語モデルの予測性能が高い)
- 量子化スケールのみ更新:PEQAは学習済みのLLMの膨大な重み自体を更新するのではなく、量子化スケールと呼ばれるパラメータ値のみを更新することで、メモリ使用量を削減している。
- デプロイ段階での高速推論:PEQAでファインチューニングされたLLMは、量子化構造が維持されているためデプロイ段階での高速推論にも有効となっている。
3. 実現方法
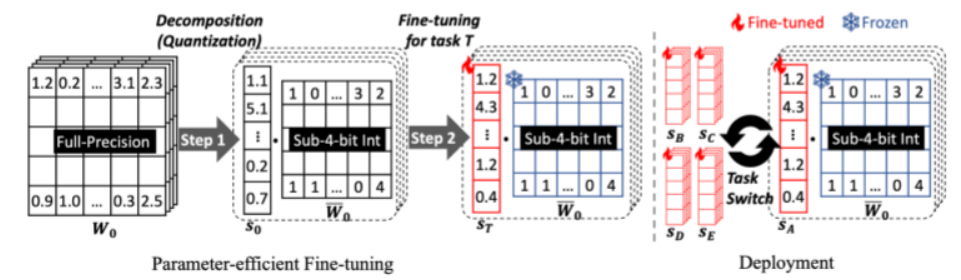
- 事前にLLMを学習させておく。
- LLMの重みを少ないビット数で表現するように変換する(量子化)。
- PEQAを用いて、量子化スケールのみ更新し、特定のタスクに対してLLMをファインチューニングしていく。
ここで、ファインチューニングの仮定でLLMの重みを更新するアルゴリズムが使用する情報として、オプティマイザーの状態情報を利用する(従来のPEFTと共通)。
4. 結果
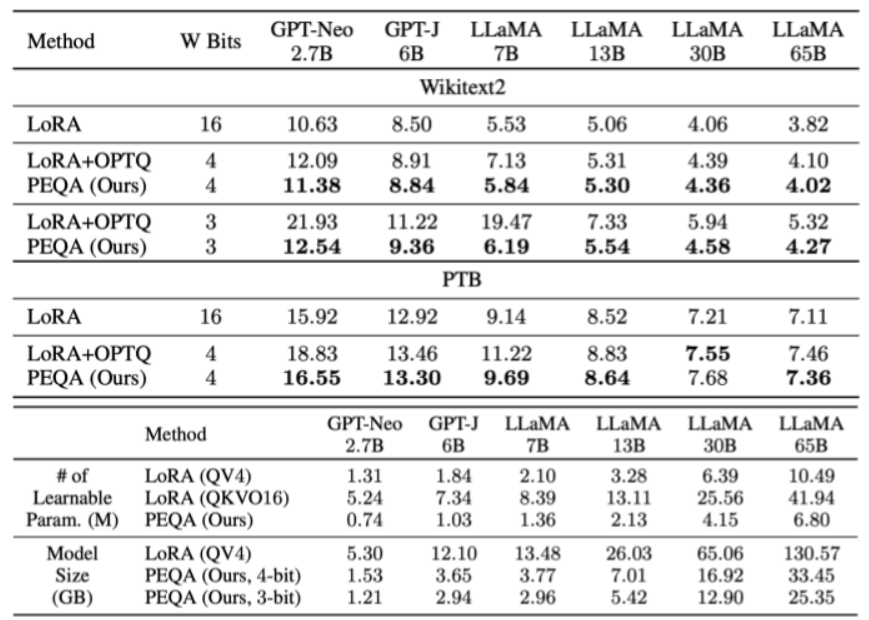
Wikitext2とPennTreeBankデータセットを用いて、LLMのモデルサイズが大きくなった際のスケーラビリティとタスク依存性の高いファインチューニングの精度比較を見ると、PEQAは、最大650億パラメータを持つLLMに対しても有効性を示している。また、4ビット以下の精度に量子化されたLLMであっても、PEQAを用いることで、元の精度での性能を維持・向上させることに成功している。
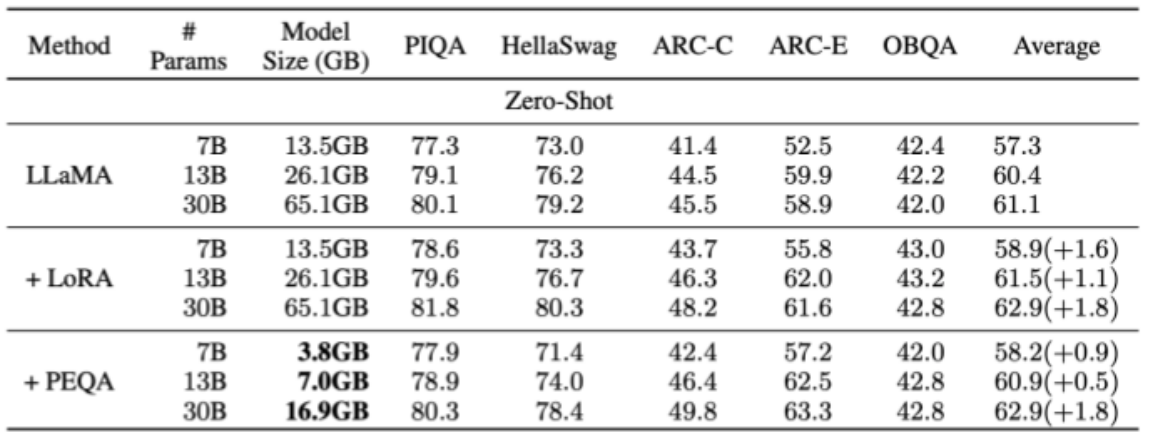
提案手法では、従来のLoRAなどのPEFT手法と比べても、LLMのメモリ使用量を削減しつつ、性能を維持できている点が評価されている。
Paper URL: https://openreview.net/forum?id=2jUKhUrBxP
last updates: May. 7 2024