1. 概要

大規模言語モデル(LLM)のファインチューニングを行う方法としてLow-Rank Adaptation(LoRA)が知られており、モデルのすべての重みを更新するのではなく、小さな行列を使って学習に必要なメモリや計算量を削減できるため、Parameter-Efficient Fine-Tuning(PEFT)の代表手法としてよく用いられる。
この研究では、QLoRAと呼ばれる新しいファインチューニングを提案しており、従来の16ビットのファインチューニングと同等性能を維持しながら、メモリ使用量を大幅に削減することで、650億パラメータのモデルを48GBのGPU1つでファインチューニングすることに成功している。
*Oral Paper
2. 新規性
従来のファインチューニング手法では、モデルの膨大な重みを全て更新する必要があったが、QLoRAでは重みを量子化して圧縮し、LoRAを用いて小さな行列を用いてファインチューニングを行う。新規性として特に以下が挙げられる。
- 4 bit Normal Float(NF4): 正規分布に従う重み表現に最適化された新しいデータフォーマットを提案している。
- 二重量子化(Doubled Quantization): 量子化定数を量子化することで、さらにメモリ使用量を削減した。
- ページ分割最適化(Paged Optimizers): メモリ使用量の一時的な急増に対処する手法を提案している。
3. 実現方法
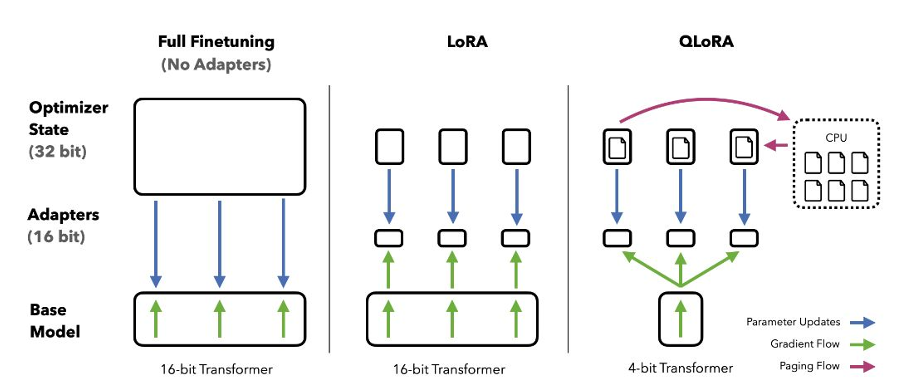
- 事前に学習済みの言語モデルの重みを4ビットに量子化し圧縮する。
- 量子化された重みは固定し、ファインチューニングはLoRAを用いて実行する。
- LoRA を更新することで、モデルの性能を向上させる。
4. 結果
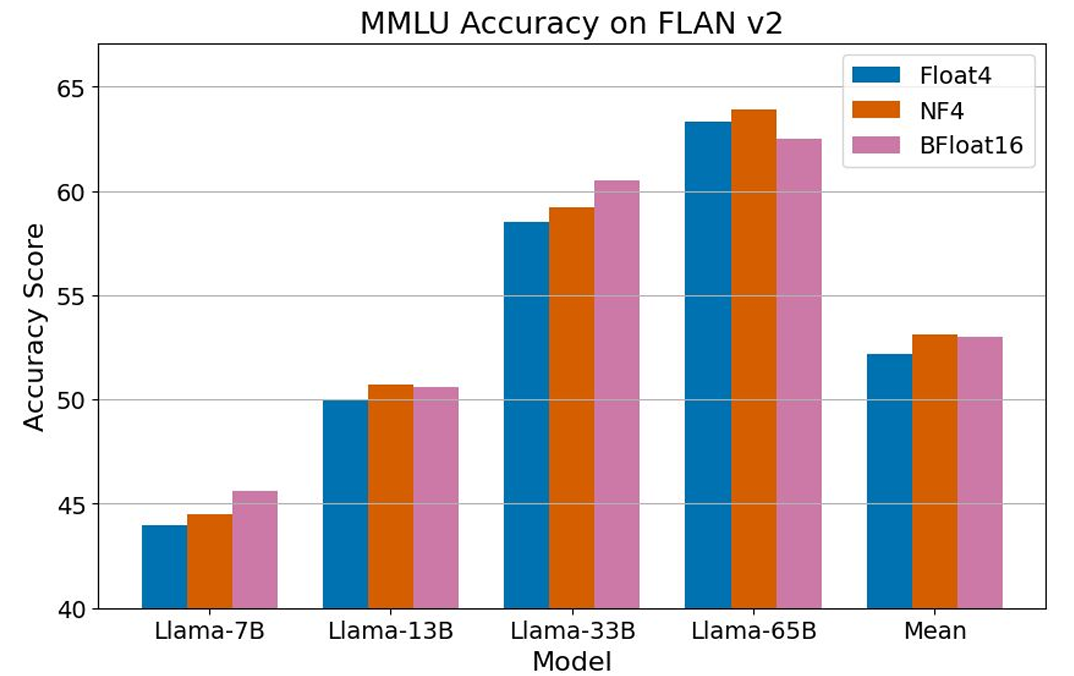
提案手法のQLoRAを用いて、LLaMaやT5など様々な規模の言語モデルに対して、1000を超えるモデルでファインチューニングを実施して性能評価を行っている。その結果、従来手法ではファインチューニングが困難だった大規模モデル(330億パラメータ~650億パラメータ)に対して、大幅にメモリ使用量を削減することでファインチューニングを可能にした。
また、少量の高品質なデータセットを用いた提案手法によるファインチューニングでは、SOTAモデルと同等以上の性能を実現している。
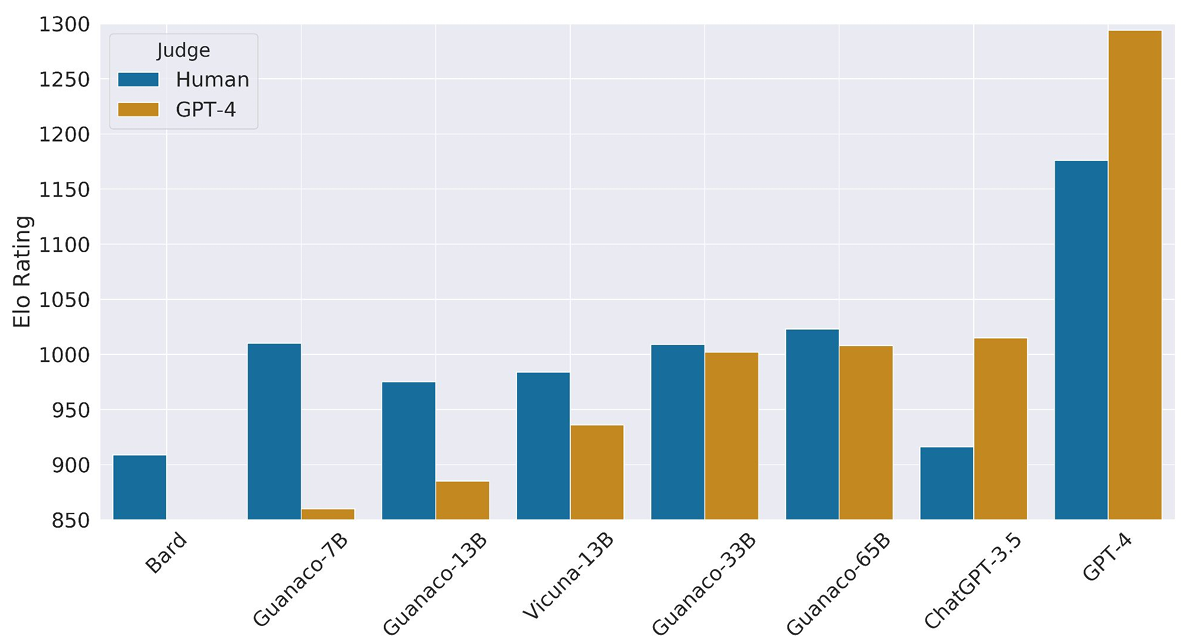
さらに、QLoRAを用いて24時間でGPU1つだけでファインチューニングされた4ビットチャットボット(Guanaco)について評価をしたところ、人間による評価とGPT-4による評価の結果が類似しており、GPT-4による性能評価は人間による評価の代替え手段として有効としている。また、現行のチャットボットのベンチマークは必ずしも信頼できない可能性を示唆している。GuanacoがChatGPTに比べて劣っている点についても分析がなされている。
Paper URL: https://openreview.net/forum?id=OUIFPHEgJU
last updates: Apr. 24 2024