はじめに
こちらは TECOTEC Advent Calendar 2019 の18日目の記事です。
色々迷ったんですが今年も機械学習系で行こうと思います。
といってもすごいありきたりなやつなんですが、最近界隈でよく名前を聞く機会が増えてきたkaggleに登録してみたので、今回はcodexaのこちらを参考に決定木モデルを使ってkaggeleのチュートリアルと言われているタイタニックの生存予想をやってスコア判定するまで書こうかと思います。
kaggleとは?
kaggele
Kaggleは企業や研究者がデータを投稿し、世界中の統計家やデータ分析家がその最適モデルを競い合う、予測モデリング及び分析手法関連プラットフォーム及びその運営会社である。 モデル作成にクラウドソーシング手法が採用される理由としては、いかなる予測モデリング課題には無数の戦略が適用可能であり、どの分析手法が最も効果的であるか事前に把握することは不可能であることに拠る。 2017年3月8日、GoogleはKaggle社を買収すると発表した。(wikipediaより)
使用環境
Google Colab
Pyton3
今回も使用環境はGoogle Colabを使います。
環境構築不要でブラウザ上でpythonの実行環境ができてしまう。GPUも無料で使える便利!!
https://colab.research.google.com/notebook
まずはkaggleのサイトから予報に使うデータセットを取得します。(kaggleへのユーザー登録が必要です。)
kaggleタイタニック課題ページ
>Download Allからデータを取得
ダウンロードしたZIPを解凍するとtrain.csvとtest.csvができるのでこれを使います。
train.csvが訓練データ、test.csvがテストデータです。
これで準備は整ったので課題の攻略をしていこうと思います。
STEP1 課題の定義
まず何を求めなくてはいけないのかを定義していきます。
今回の場合は乗客データからどれだけの人が事故後生存できたのかを予測することです。
STEP2 データ取得
まずはColabにデータをアップロードしていきます。
from google.colab import files
uploaded = files.upload()
uploaded2 = files.upload()
上記で取得してきたtest.csvとtrain.csvをアップロード。
import pandas as pd
import io
test = pd.read_csv(io.StringIO(uploaded['test.csv'].decode('utf-8')), header=0)
test.head()
train = pd.read_csv(io.StringIO(uploaded2['train.csv'].decode('utf-8')), header=0)
train.head()
それぞれ出力してデータの中身を確認してみます。
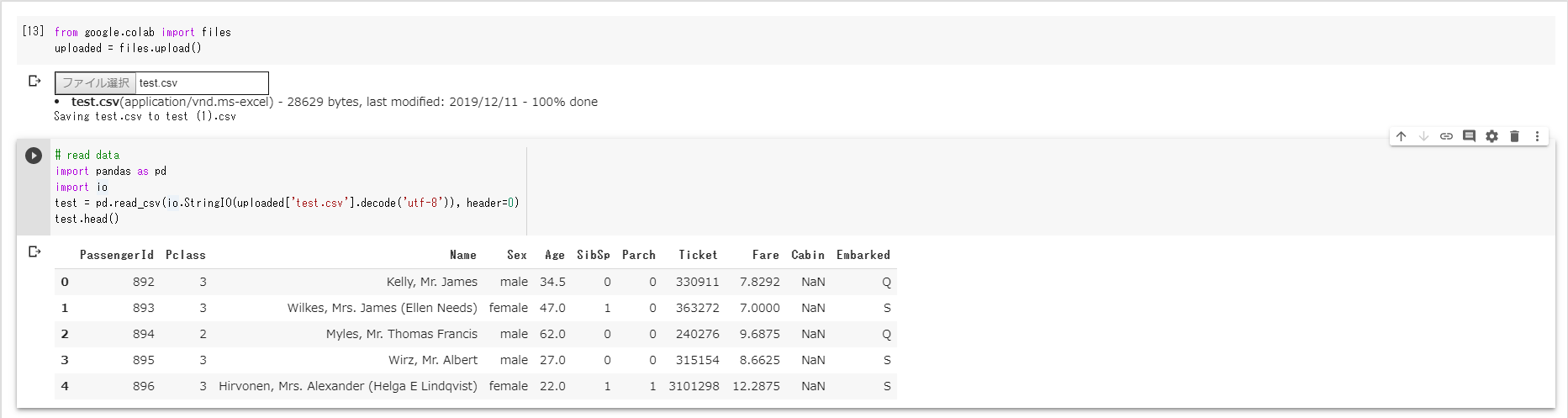
test.csvの中身。
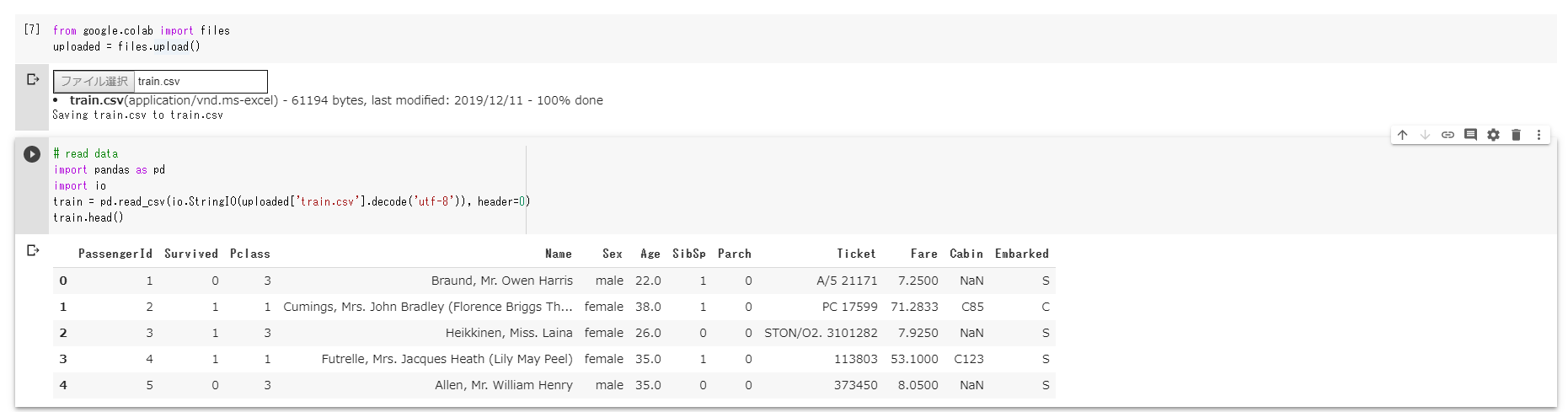
train.csvの中身。
| カラム | 意味 |
|---|---|
| Passenger_Id | 乗客のユニークID |
| Pclass | チケット等級 |
| Name | 乗客の名前 |
| Sex | 性別(male=男性、female=女性) |
| Age | 年齢 |
| SibSp | 同乗している兄弟/配偶者の数 |
| Parch | 同乗している親/子供の数 |
| Ticket | チケット番号 |
| Fare | 料金 |
| Cabin | 客室番号 |
| Embarked | 乗船した港(C = Cherbourg(シェルブール), Q = Queenstown(クィーンズタウン), S = Southampton(サウサンプトン)) |
| 補足 | |
| Pclass 乗客の社会的地位を表しています。1:上級 2:中級 3:下級 | |
| Age 1歳未満の場合は小数です。またxxx.5のような場合は実年齢ではなく推定年齢です。 |
STEP3 統計情報の確認
まずtrain と test の統計情報とサイズの確認です。
test_shape = test.shape
train_shape = train.shape
print(test_shape)
print(train_shape)
(418, 11)
(891, 12)
testが418人の乗客と11個のカラム
trainは891人の乗客と12個のカラム
が存在するのが分かります。
testとtrainのカラム数が異なるのはtrainの方には
今回求めるターゲットとなるSurvivedのカラムが含まれているからです。
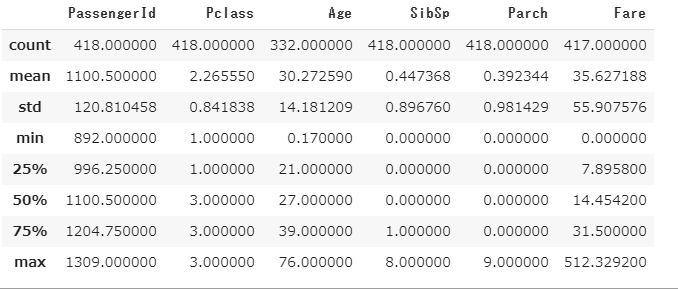
次に基本統計量を確認します。
test.describe()
train.describe()
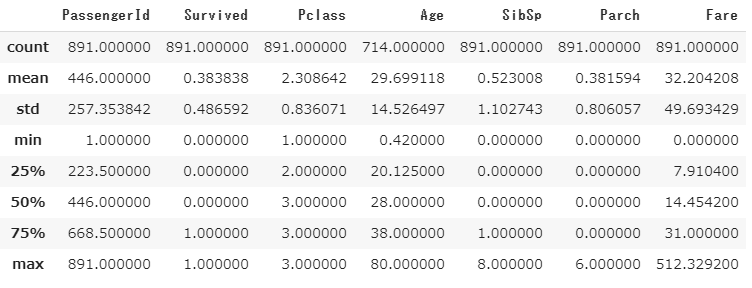
PassengerIdを始めとするほとんどの項目は418、891と人数と合っているのに対しAgeやFareなどに欠損が生じています。
ひとまず失われたデータを確認します。
def loss_table(df):
null_val = df.isnull().sum()
percent = 100 * df.isnull().sum()/len(df)
loss_table = pd.concat([null_val, percent], axis=1)
loss_table_ren_columns = loss_table.rename(
columns = {0 : '欠損数', 1 : '%'})
return loss_table_ren_columns
loss_table(train)
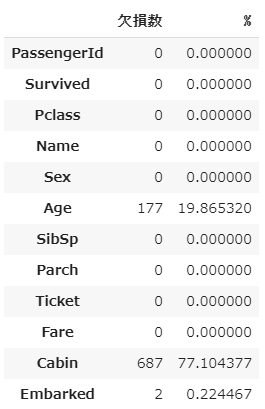
loss_table(test)
STEP4 欠損データの穴埋め
このままでは計算できないので事前処理として欠損データに代入して穴埋めをしていきます。
まずtrainから
train["Age"] = train["Age"].fillna(train["Age"].median())
train["Embarked"] = train["Embarked"].fillna("S")
loss_table(train)
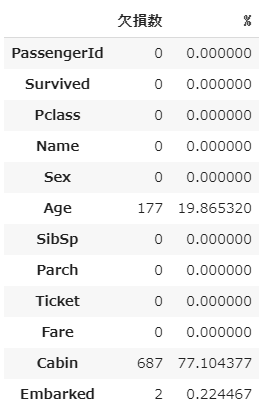
loss_table(test)
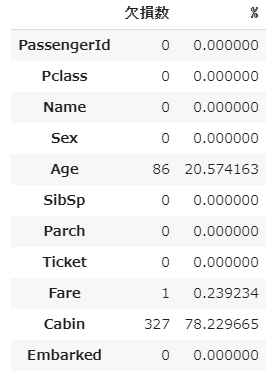
Ageは全データの中央値を代入しました。
Embarkedは最も多いSを入れます。
STEP5 文字データの置き換え
次に文字データを数値に置き換えていきます。
まずはtrainから。
train["Sex"][train["Sex"] == "male"] = 0
train["Sex"][train["Sex"] == "female"] = 1
train["Embarked"][train["Embarked"] == "S" ] = 0
train["Embarked"][train["Embarked"] == "C" ] = 1
train["Embarked"][train["Embarked"] == "Q"] = 2
train.head(10)
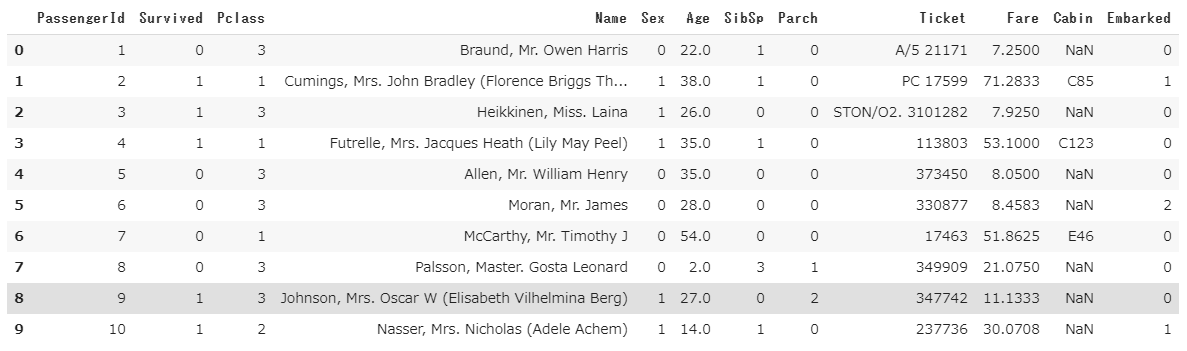
headで確認すると数値に置き換わっているのが分かります。
次にtestも置き換えていきます。
test["Age"] = test["Age"].fillna(test["Age"].median())
test["Sex"][test["Sex"] == "male"] = 0
test["Sex"][test["Sex"] == "female"] = 1
test["Embarked"][test["Embarked"] == "S"] = 0
test["Embarked"][test["Embarked"] == "C"] = 1
test["Embarked"][test["Embarked"] == "Q"] = 2
test.Fare[152] = test.Fare.median()
test.head(10)
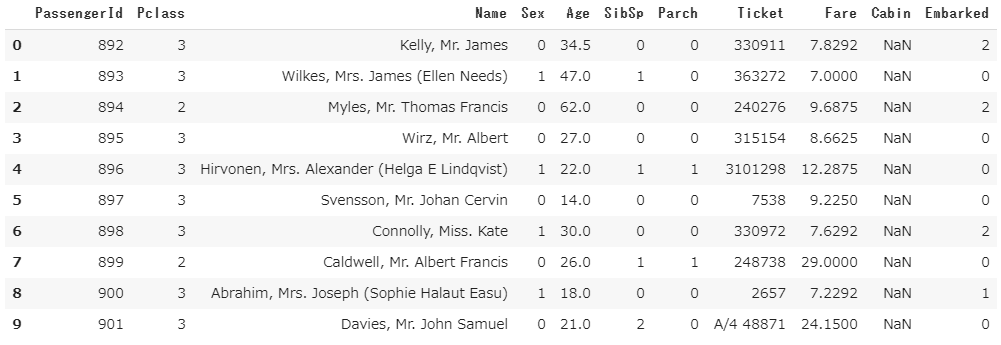
こちらも置き換わっているのが確認できました。
ではいよいよ決定木モデルを使って予測していきます
from sklearn import tree
# 「train」の目的変数と説明変数の値を取得
target = train["Survived"].values
features_one = train[["Pclass", "Sex", "Age", "Fare"]].values
# 決定木の作成
tree_model = tree.DecisionTreeClassifier()
tree_model = tree_model .fit(features_one, target)
# 「test」の説明変数の値を取得
test_features = test[["Pclass", "Sex", "Age", "Fare"]].values
# 「test」の説明変数を使って「tree_model 」のモデルで予測
my_prediction = tree_model.predict(test_features)
# 予測データのサイズを確認
my_prediction.shape
scikit-learnのDecisionTreeClassifier()で決定木モデルを作成しfeatures_oneと同じ項目を
test_featuresにいれて予測を立てるといった感じです。
でできたmy_predictionのサイズが↓
(418,)
予測の対象となるtest.csvのデータは418件だったので完全なデータができたことになります。
[0 0 1 1 1 0 0 0 1 0 0 0 1 1 1 1 0 1 1 0 0 1 1 1 1 0 1 1 1 0 0 0 1 0 1 0 0
0 0 1 0 1 0 1 1 0 0 0 1 1 1 0 1 1 1 0 0 0 1 1 0 0 0 1 1 0 1 0 0 1 1 0 1 0
1 0 0 1 0 1 1 0 0 0 1 0 1 1 1 1 1 1 1 0 0 0 1 1 1 0 1 0 0 0 1 0 0 0 1 0 0
0 1 1 1 0 1 1 0 1 1 0 1 0 0 1 0 1 0 0 1 0 0 1 0 0 1 0 0 0 0 0 0 0 0 1 1 0
1 0 1 0 0 1 0 0 1 1 0 1 1 1 1 1 0 1 1 0 0 0 0 1 0 1 0 1 1 0 1 1 0 0 1 0 1
0 1 0 0 0 0 0 1 0 1 0 1 0 0 0 0 1 0 1 0 0 0 0 1 0 1 1 0 0 0 0 1 0 1 0 1 0
1 1 1 0 0 1 0 0 0 1 0 0 1 0 0 1 1 1 1 1 1 0 0 0 1 0 1 0 1 0 0 0 0 0 0 0 1
0 0 0 1 1 0 0 0 0 0 0 0 0 1 0 1 1 0 0 0 0 0 1 1 0 1 0 0 0 1 0 1 0 1 0 0 0
1 0 0 0 0 0 0 0 1 1 0 1 1 0 0 1 0 0 1 1 0 0 0 0 0 0 0 1 1 0 1 0 0 0 1 0 1
1 0 0 0 0 0 1 0 0 0 1 0 1 0 0 0 1 1 0 0 0 1 0 1 0 0 1 0 1 1 1 1 0 0 0 1 0
0 1 0 0 1 1 0 0 0 1 0 0 0 1 0 1 0 0 0 0 0 1 1 0 0 1 0 1 0 0 1 0 1 1 0 0 0
0 1 1 1 1 0 0 1 0 0 0]
中身はこんな感じでtrain.csvのSurvivedは0:死亡、1:生存だったのでちゃんとした予測データができたことになります。
次にKaggleに投稿するためのデータを出力します。
import numpy as np
from google.colab import files
# PassengerIdを取得
PassengerId = np.array(test["PassengerId"]).astype(int)
# my_prediction(予測データ)とPassengerIdをデータフレームへ落とし込む
my_solution = pd.DataFrame(my_prediction, PassengerId, columns = ["Survived"])
# first_change.csvとして書き出し
my_solution.to_csv("first_change.csv", index_label = ["PassengerId"])
files.download('first_change.csv')
PassengerIdと予測した0 or 1のデータをセットにしてCsvに書き出した後、Google Colabからダウンロードするためにはfrom google.colab import filesのライブラリを呼び出してfiles.downloadでローカルにダウンロードする必要があります。
いよいよ投稿です。KaggleのtitanicページからSubmit Predictionsをクリックします。
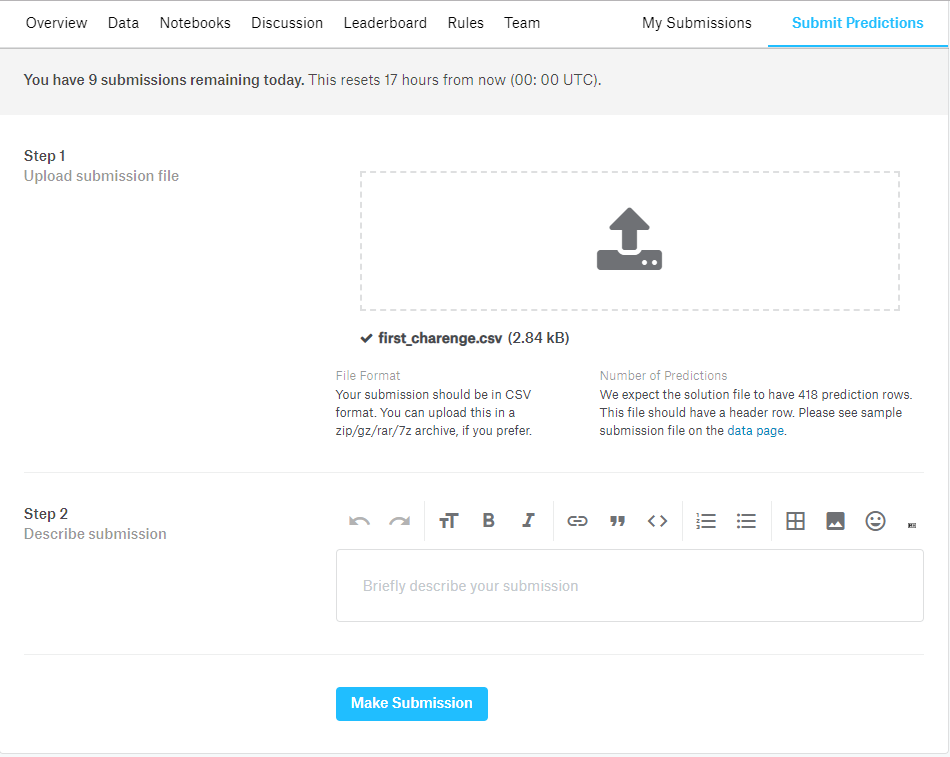
Submit Predictionsページにてから予測結果をドラック&ドロップして
ファイルアップロード。
Make Submissionをクリック
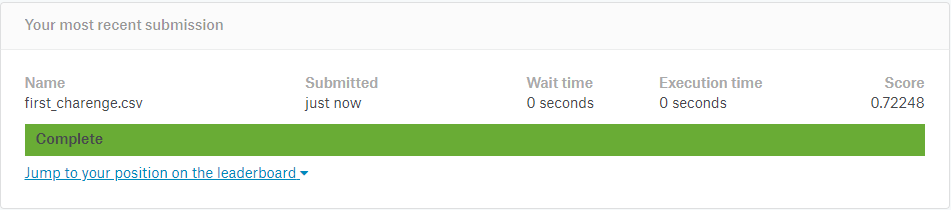
アップロード完了!
Score 0.72248が評価(正誤率)
めっちょ長くなってしまいましたがどうでしょう?
Kaggleにはtitanic以外にも様々な企業や団体から課題がアップされており世界中のkagglerが日夜スコアを競っています(titanicなんかは投稿が多すぎて載らなくなるのでスコアランキングが2か月で消されるようになったほど。。。)日本でもリクルートやメルカリといった企業が賞金を出してコンペを行っていたりします。
興味があればkaggleに挑戦して世界のkagglerと競ってみてください。