テコテックAdventCalendar2017の9日目の記事です。
さて、先日の記事でkotlinを簡単に実行できるようになったので、少し実用的なものとしてCrawlerを作ってみたいと思います。
機能としては、指定されたURLのHTML内の画像一覧を表示するだけのものにします。
今回は、Javaライブラリ「crawler4j」のkotlin版「kotlin-crawler」を使います。
1. build.gradleの修正
まずは、kotlin-crawlerのREADMEを参考にして、前回作成したbuild.gradleを編集します。
repositoriesとdependenciesの部分を修正しました。
build.gradle
buildscript {
ext.kotlin_version = '1.2.0'
repositories {
mavenCentral()
}
dependencies {
classpath "org.jetbrains.kotlin:kotlin-gradle-plugin:$kotlin_version"
}
}
apply plugin: 'kotlin'
apply plugin: 'application'
repositories {
jcenter()
mavenCentral()
maven { url "https://jitpack.io" }
}
dependencies {
compile "org.jetbrains.kotlin:kotlin-stdlib:$kotlin_version"
compile 'com.github.brianmadden:krawler:0.4.3'
}
sourceSets {
main.java.srcDirs += './'
}
defaultTasks 'run'
run {
if (project.hasProperty('main')) {
main(project.main.replace(".kt", "Kt").capitalize())
}
}
3. プログラムの作成
今回はkotlin-crawlerのサンプルプログラムを弊社HPから画像ファイルのリストを取得するように修正してみます。
※あまりアクセスしすぎると対象サーバに負荷をかけてしまうので実行する際には注意してください!
main.kt
import io.thelandscape.krawler.crawler.KrawlConfig
fun main(args: Array<String>)
{
// totalPagesにCrawlするページ数を設定する
// あまり多すぎるとサーバに負荷をかけてしまうのでほどほどに・・・
val config: KrawlConfig = KrawlConfig(totalPages = 100)
val k = SimpleExample(config)
// アクセスを許可するホストの一覧
val allowedHosts = listOf("tecotec.co.jp")
k.whitelist.addAll(allowedHosts)
// Crawl先を指定して実行
k.start(listOf("http://tecotec.co.jp/"))
}
SimpleExample.kt
import io.thelandscape.krawler.crawler.KrawlConfig
import io.thelandscape.krawler.crawler.Krawler
import io.thelandscape.krawler.http.KrawlDocument
import io.thelandscape.krawler.http.KrawlUrl
import java.time.LocalTime
import java.util.concurrent.ConcurrentSkipListSet
import java.util.concurrent.atomic.AtomicInteger
class SimpleExample(config: KrawlConfig = KrawlConfig()) : Krawler(config)
{
// 抽出から除外するURLの正規表現
private val EXCLUDE_FILTERS: Regex = Regex(".*(\\.(css|js|bmp|gif|jpe?g|png|tiff?|mid|mp2|mp3|mp4|wav|avi|" +
"mov|mpeg|ram|m4v|pdf|rm|smil|wmv|swf|wma|zip|rar|gz|tar|ico))$", RegexOption.IGNORE_CASE)
// ドキュメントから抽出する拡張子の正規表現
private val EXTRACT_FILTERS: Regex = Regex(".*(\\.(bmp|gif|jpe?g|png|tiff?))$", RegexOption.IGNORE_CASE)
val whitelist: MutableSet<String> = ConcurrentSkipListSet()
// Crawlする対象URLかどうかを判定するメソッド
// この中の条件を変えて対象URLを絞り込む
override fun shouldVisit(url: KrawlUrl): Boolean {
val getParams: String = url.canonicalForm.split("?").first()
return (!EXCLUDE_FILTERS.matches(getParams) && url.host in whitelist)
}
private val counter: AtomicInteger = AtomicInteger(0)
// 抽出対象を処理するメソッド
// この中で抽出対象のドキュメントについて操作を行う
override fun visit(url: KrawlUrl, doc: KrawlDocument) {
println("${counter.incrementAndGet()}. Crawling ${url.canonicalForm}")
doc.otherOutgoingLinks.forEach {
if (EXTRACT_FILTERS.matches(it)) {
println(it)
}
}
}
override fun onContentFetchError(url: KrawlUrl, reason: String) {
println("Tried to crawl ${url.canonicalForm} but failed to read the content.")
}
private var startTimestamp: Long = 0
private var endTimestamp: Long = 0
override fun onCrawlStart() {
startTimestamp = LocalTime.now().toNanoOfDay()
}
override fun onCrawlEnd() {
endTimestamp = LocalTime.now().toNanoOfDay()
println("Crawled $counter pages in ${(endTimestamp - startTimestamp) / 1000000000.0} seconds.")
}
}
4. 実行
前回と同様に[ツール]→[ビルド]を選択するか、Ctrl+Bでビルドを実行します。
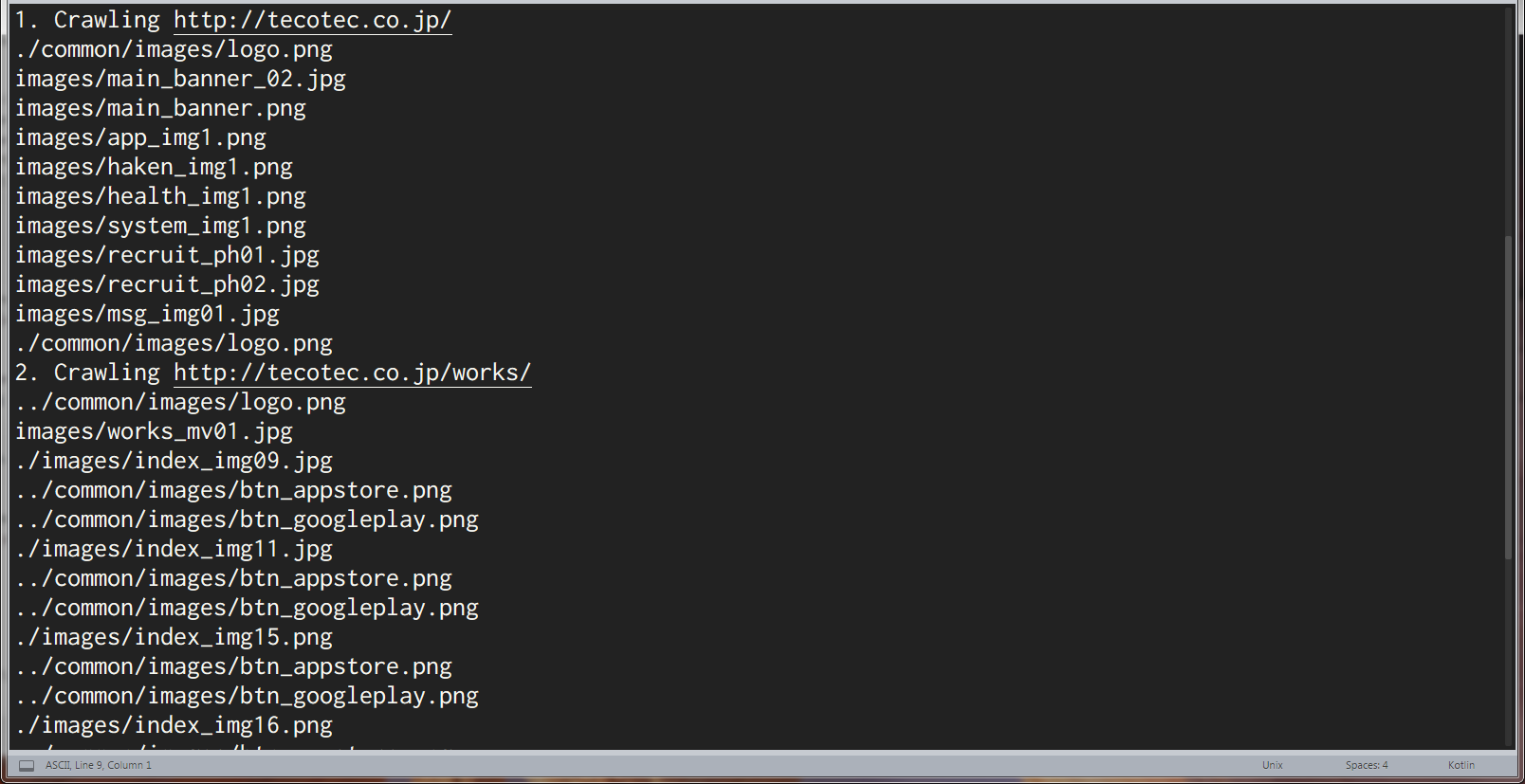
これでkotlinと快適なcrawlingライフを送れるようになりました!
みなさんもどんどんkotlinとたわむれましょう!