深層学習 Day4
本記事はラビット☆チャレンジのレポートとして記載し、今回は以下の内容について記述する。
Section1:TensorFlowの実装演習
Section2: 強化学習
動画の要約
Section1:TensorFlowの実装演習
- TensorFlowとは
- google が作っている機械学習用ライブラリ。シェアは世界で1番多い。
- 実務では NumPy 等を使って DNN をスクラッチで実装することは少なく、TensorFlowやKeras等が利用される
- TensorFlowの使い方
- constant
- 値、変数の型等を指定するために用いる
- TensorFlow ではテンソルというものを利用する
- 定義後、Session.run() しないと実際に評価されない
- printでは出ないのでデバックなどの際には注意する
- placeholder
- 箱のようなものを用意するイメージ
- 後から値を自在に変えることができる
- Session.run() しないと実際に評価されない
- variables
- オペレータを定義し、そのオペレータで変数の値を更新する
- global_variables_initializerメソッドで初期化できる
- TensorFlow実装
実装結果および考察については別途記載する。
- 線形回帰
- 非線形回帰
- mnist 1層
- mnist 3層
- mnist CNN
- 論文からの実装
- AlexNet や Yolo など、論文はネットで入手することができる
- 「モデル名 archive」等で検索可能
- githubでソースが公開されていることもある
- メジャーなモデルは Keras のアプリケーションとして実装が提供されていたりする
- 例題確認
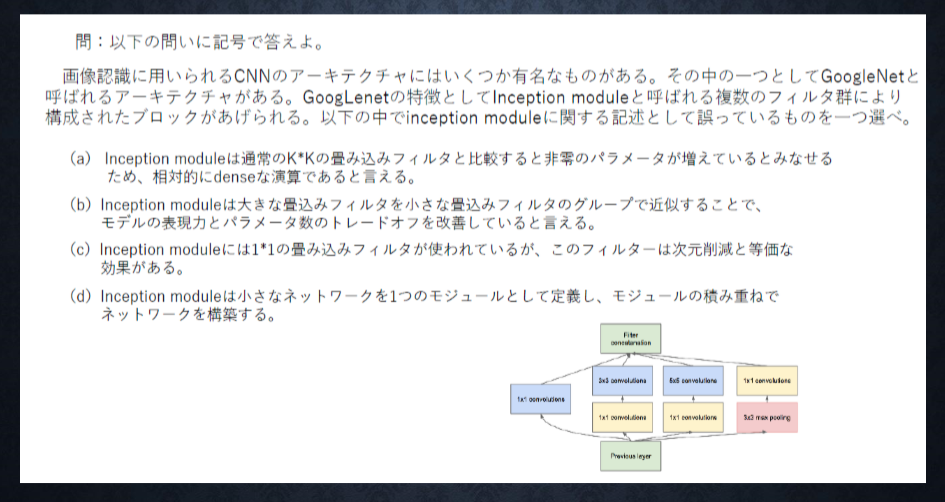
<答え>
a
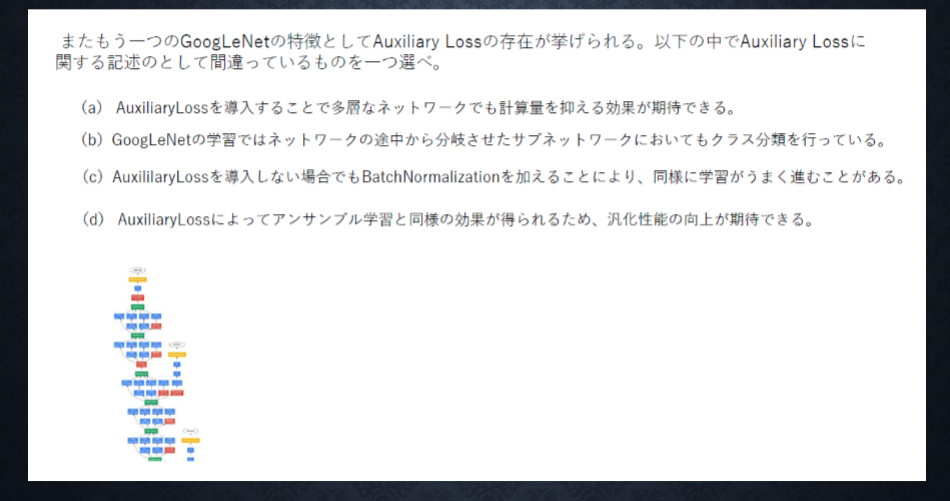
<答え>
a
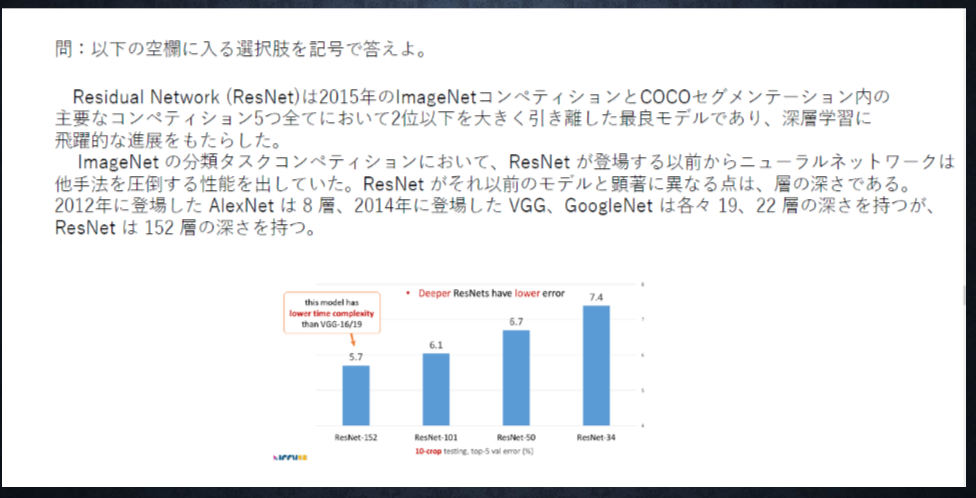


<答え>
あ:a
い:a
う:a
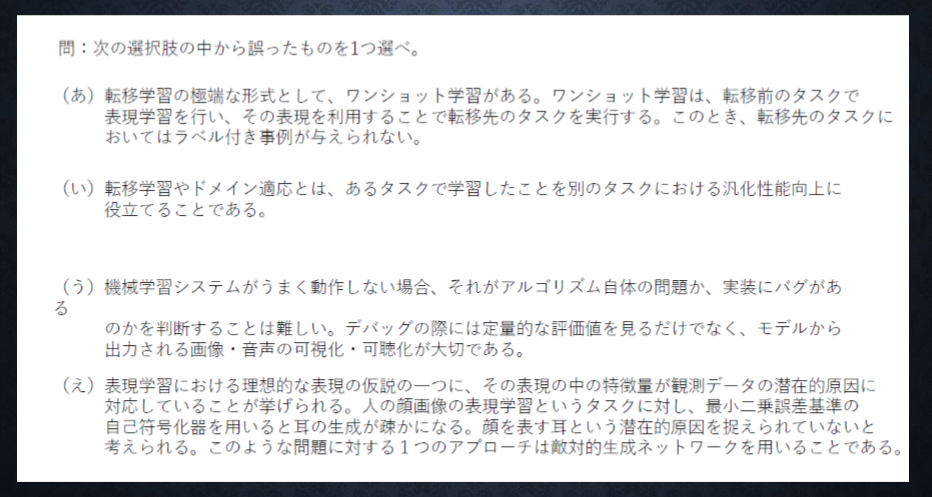
<答え>
あ
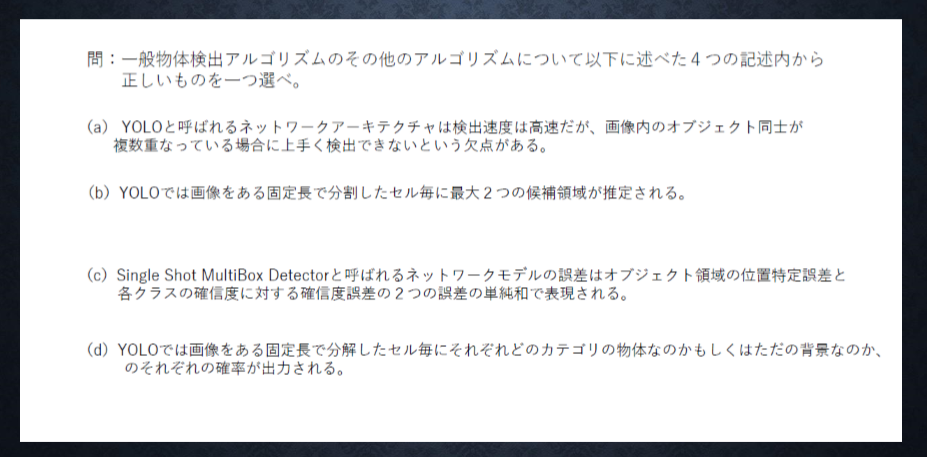
<答え>
a
- 確認テスト
VGG、GoogLeNet、Resnetの特徴を簡潔に述べよ。
- VGG:ネットワークがシンプル。パラメータ数が多い。
- GoogLeNet::Inception moduleを使用した1x1畳み込みによる次元削減。様々なサイズのフィルターによるスパースな演算。
- Resnet:Identity moduleにより勾配消失問題を解決し、深い層でも学習が可能。
- Kerasとは
- TensorFlow のラッパー
- シンプルなモデルであれば簡単に記述ができる
- 複雑な構造には対応出来ないため、その部分はTensorFlowを用いる
- Keras実装演習
実装結果および考察については別途記載する。
- 線形回帰
- 単純パーセプトロン
- 分類(irisデータ)
- 分類(mnist)
- RNN
Section2:強化学習
- 強化学習とは
- 機械学習の一分野。教師あり学習や教師なし学習とは別に分類される。
- 長期的に報酬を最大化できるように環境のなかで行動を選択できるエージェントを作ることを目標
- 行動の結果として与えられる利益(報酬)をもとに行動の原理を改善していく仕組み
- 強化学習の応用例
<マーケティングの例>
- 環境:会社の販売促進部
- エージェント:プロフィールと購入履歴に基づいて、キャンペーンメールを送る顧客を決める
- 行動:メール送信・非送信
- 報酬:負の報酬と正の報酬の和
- 負の報酬:キャンペーンのコスト
- 正の報酬:キャンペーンで生み出される売上
<確認テスト>
強化学習に応用できそうな事例を考え、環境・エージェント・行動・報酬を具体的に述べよ。
- 環境:株のトレーディング
- エージェント:過去の株価やその他の指標に基づいて、特定の銘柄の株の売買を決める
- 行動:株の買売
- 報酬:負の報酬と正の報酬の和
- 負の報酬:トレードによる損失
- 正の報酬:トレードによる利益
- 探索と利用のトレードオフ
-
過去のデータで、ベストとされる行動のみを常に取り続ければ他にもっとベストな行動を見つけることはできない
- 探索が足りない状態
-
未知の行動のみを常に取り続ければ、過去の経験が活かせない
- 利用が足りない状態
- 強化学習イメージ
- エージェントが方策を実施して行動を行った結果、環境は状態$S$となる
- エージェントは環境を観測し、状態$S$における報酬を得る
- エージェントは方策をもとに行動を行う
- 方策は方策関数$ \Pi (s,a)$で表される
- 報酬の価値は行動価値関数 $Q(s,a)$ により表される
- 強化学習の差分
- 強化学習と教師あり・なし学習との違い
- 教師あり・なし学習 → パターンを見つける
- 強化学習 → 優れた方策を見つける
- 強化学習の歴史
- 計算速度の進展により大規模な状態をもつ場合の、強化学習を可能としつつある
- 関数近似法と、Q学習を組み合わせる手法の登場
- Q学習:行動価値関数を行動毎に更新し学習を進める方法
- 関数近似法:価値関数や方策関数を関数近似する手法
- 行動価値関数
- 状態価値関数と行動価値関数の2種類がある
- 状態価値関数:ある状態の価値に注目する場合
- 行動価値関数:状態と価値を組み合わせた価値に注目する場合
- 方策関数
- ある状態でどのような行動を採るのかの確率を与える関数
- 方策勾配法について
- 方策反復法:方策をモデル化して最適化する手法
\theta^{t+1} = \theta^{t} + \epsilon \nabla J(\theta)
$J$は方策の良さを表すが、これを定義しなければならない
- $J$の定義方法
- 平均報酬
- 割引報酬和
- 上記の定義に対応して、行動価値関数:$Q(s,a)$の定義を行い、方策勾配定理が成り立つ
\nabla _ \theta J(\theta) = E _{\pi_\theta}[(\nabla _ \theta \log \pi _\theta(a|s)Q^{\pi}(s,a))]
- DCGAN
- Deep Convolutional Generative Adversarial Networks
- CNN のディープなネットワークを利用して敵対的生成を利用してモデルを訓練する
- 潜在空間でベクトルをもとめ、それをもとに画像を生成
- 例:(笑顔の女の人の顔) - (女の人の顔) + (男の人の顔) → 笑顔の男性の顔
- kaggle
- データ分析のコンペティション
- 企業等がコンペを開いて賞金を出している
- Kernel で、世界のデータサイエンティストの実装を見ることが可能
- 優勝者は複数のモデルをアンサンブルして構築することが多い
- 初心者用のコンペもあるので、だれでも参加可能
TensorFlow実装
線形回帰
TensorFlowを用いて線形回帰を行った
# データを生成
n = 100
x = np.random.rand(n)
d = 3 * x + 2
# ノイズを加える
noise = 0.3
d = d + noise * np.random.randn(n)
# 入力値
xt = tf.placeholder(tf.float32, shape=[None,1])
dt = tf.placeholder(tf.float32, shape=[None,1])
# 最適化の対象の変数を初期化
W = tf.Variable(tf.zeros([1]))
b = tf.Variable(tf.zeros([1]))
y = W * xt + b
# 誤差関数 平均2乗誤差
loss = tf.reduce_mean(tf.square(y - dt))
optimizer = tf.train.GradientDescentOptimizer(0.1)
train = optimizer.minimize(loss)
# 初期化
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# 作成したデータをトレーニングデータとして準備
x_train = x.reshape(-1,1)
d_train = d.reshape(-1,1)
# トレーニング
for i in range(iters_num):
sess.run(train, feed_dict={xt:x_train,dt:d_train})
if (i+1) % plot_interval == 0:
loss_val = sess.run(loss, feed_dict={xt:x_train,dt:d_train})
W_val = sess.run(W)
b_val = sess.run(b)
print('Generation: ' + str(i+1) + '. 誤差 = ' + str(loss_val))
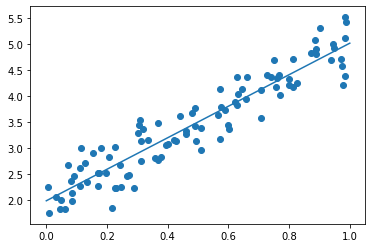
誤差 = 0.10555928
noiseを0.3→0.03に変更
dの傾きを3→30に変更
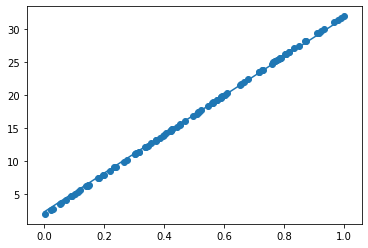
<考察>
- TensorFlowの基本であるplaceholder、Variable、Sessionの使い方が理解できた
- ノイズは傾きに対する割合が大きいほど影響が大きく、割合が小さければ影響が少ないことを再確認した
- TensorFlowでも線形回帰は可能であるがsk-learnを用いた方がシンプルなコードで実装できることがわかった
非線形回帰
iters_num = 10000
plot_interval = 100
# データを生成
n=100
x = np.random.rand(n).astype(np.float32) * 4 - 2
d = - 0.4 * x ** 3 + 1.6 * x ** 2 - 2.8 * x + 1
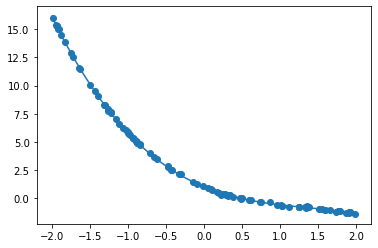
iters_num = 10000
AdamOptimizer(0.001)
誤差 = 0.0028053217
$𝑦=30𝑥^2+0.5𝑥+0.2$において非線形回帰を実装する。
その際に収束するためにiters_numやlearning_rateを調整する。
iters_num = 20000
plot_interval = 1000
# データを生成
n=100
x = np.random.rand(n).astype(np.float32) * 4 - 2
d = 30. * x ** 2 + 0.5 * x + 0.2
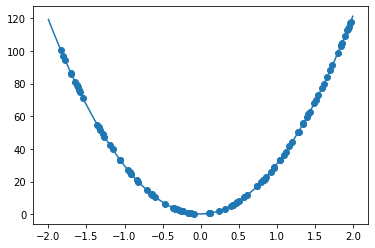
iters_num = 20000
AdamOptimizer(0.01)
誤差 = 1.8617819e-11
<考察>
- 非線形回帰でも問題なくモデルの作成が行うことができた
- learning late を10倍にすると、変更前に比べて早い段階で収束した
- learning lateが重要なパラメータの一つであることを再認識した
mnist(1層)
iters_num = 100
batch_size = 100
plot_interval = 1
x = tf.placeholder(tf.float32, [None, 784])
d = tf.placeholder(tf.float32, [None, 10])
W = tf.Variable(tf.random_normal([784, 10], stddev=0.01))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
accuracies = []
for i in range(iters_num):
x_batch, d_batch = mnist.train.next_batch(batch_size)
sess.run(train, feed_dict={x: x_batch, d: d_batch})
if (i+1) % plot_interval == 0:
print(sess.run(correct, feed_dict={x: mnist.test.images, d: mnist.test.labels}))
accuracy_val = sess.run(accuracy, feed_dict={x: mnist.test.images, d: mnist.test.labels})
accuracies.append(accuracy_val)
print('Generation: ' + str(i+1) + '. 正解率 = ' + str(accuracy_val))
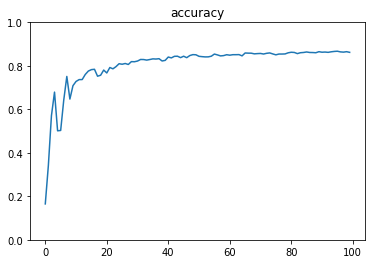
正解率 = 0.8621
mnist(3層)
iters_num = 3000
batch_size = 100
plot_interval = 100
hidden_layer_size_1 = 600
hidden_layer_size_2 = 300
dropout_rate = 0.5
x = tf.placeholder(tf.float32, [None, 784])
d = tf.placeholder(tf.float32, [None, 10])
W1 = tf.Variable(tf.random_normal([784, hidden_layer_size_1], stddev=0.01))
W2 = tf.Variable(tf.random_normal([hidden_layer_size_1, hidden_layer_size_2], stddev=0.01))
W3 = tf.Variable(tf.random_normal([hidden_layer_size_2, 10], stddev=0.01))
b1 = tf.Variable(tf.zeros([hidden_layer_size_1]))
b2 = tf.Variable(tf.zeros([hidden_layer_size_2]))
b3 = tf.Variable(tf.zeros([10]))
z1 = tf.sigmoid(tf.matmul(x, W1) + b1)
z2 = tf.sigmoid(tf.matmul(z1, W2) + b2)
keep_prob = tf.placeholder(tf.float32)
drop = tf.nn.dropout(z2, keep_prob)
y = tf.nn.softmax(tf.matmul(drop, W3) + b3)
optimizer = tf.train.AdamOptimizer(1e-4)
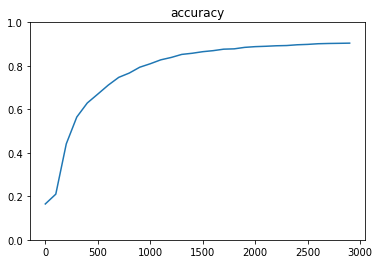
Generation: 3000. 正解率 = 0.9044
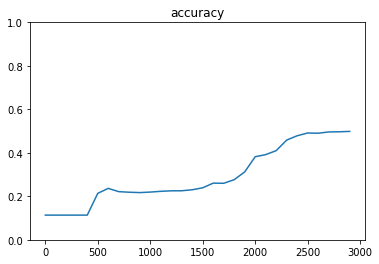
hidden_layer_size_1 = 60
hidden_layer_size_2 = 30
Generation: 3000. 正解率 = 0.4985
学習速度は速い
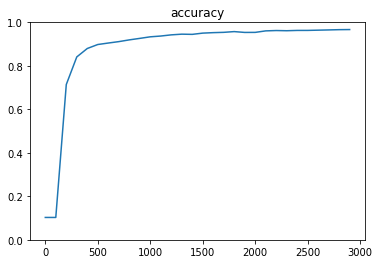
hidden_layer_size_1 = 600
hidden_layer_size_2 = 300
optimizer = tf.train.RMSPropOptimizer(0.001)
Generation: 3000. 正解率 = 0.9669
<考察>
- 1層に比べると3層のほうが精度が高かった
- 隠れ層の数を減らすと精度が下がるが、学習速度は速かった
- 実務上は精度と速度の優先を考えて構築する必要がある
- RMSPropは収束するまでの速度が速かった
mnist(CNN)
iters_num = 300
batch_size = 100
plot_interval = 10
dropout_rate = 0.5
# placeholder
x = tf.placeholder(tf.float32, shape=[None, 784])
d = tf.placeholder(tf.float32, shape=[None, 10])
# 画像を784の一次元から28x28の二次元に変換する
# 画像を28x28にreshape
x_image = tf.reshape(x, [-1,28,28,1])
# 第一層のweightsとbiasのvariable
W_conv1 = tf.Variable(tf.truncated_normal([5, 5, 1, 32], stddev=0.1))
b_conv1 = tf.Variable(tf.constant(0.1, shape=[32]))
# 第一層のconvolutionalとpool
# strides[0] = strides[3] = 1固定
h_conv1 = tf.nn.relu(tf.nn.conv2d(x_image, W_conv1, strides=[1, 1, 1, 1], padding='SAME') + b_conv1)
# プーリングサイズ n*n にしたい場合 ksize=[1, n, n, 1]
h_pool1 = tf.nn.max_pool(h_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 第二層
W_conv2 = tf.Variable(tf.truncated_normal([5, 5, 32, 64], stddev=0.1))
b_conv2 = tf.Variable(tf.constant(0.1, shape=[64]))
h_conv2 = tf.nn.relu(tf.nn.conv2d(h_pool1, W_conv2, strides=[1, 1, 1, 1], padding='SAME') + b_conv2)
h_pool2 = tf.nn.max_pool(h_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 第一層と第二層でreduceされてできた特徴に対してrelu
W_fc1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1024], stddev=0.1))
b_fc1 = tf.Variable(tf.constant(0.1, shape=[1024]))
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# Dropout
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 出来上がったものに対してSoftmax
W_fc2 = tf.Variable(tf.truncated_normal([1024, 10], stddev=0.1))
b_fc2 = tf.Variable(tf.constant(0.1, shape=[10]))
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
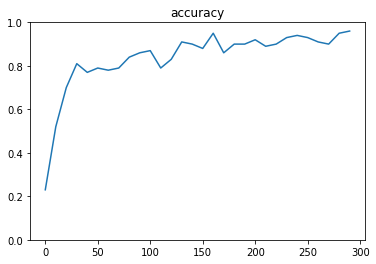
dropout_rate = 0.5
Generation: 300. 正解率 = 0.96
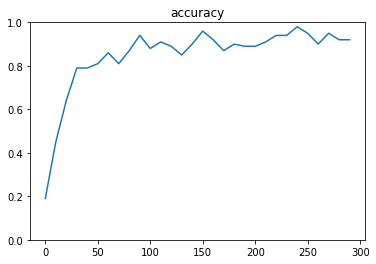
dropout_rate = 0
Generation: 300. 正解率 = 0.92
<考察>
- TensorFlowでのCNNの実装方法を理解した
- ドロップアウトの有無で結果を比較したが、今回のケースではドロップアウトを行った方がよい結果となった
- 今回はvalidation を行ってないため大きな差異はなかったが、実務上は汎化性能をあげる目的でドロップアウトを用いられる
Keras実装
線形回帰
iters_num = 1000
plot_interval = 10
x = np.linspace(-1, 1, 200)
np.random.shuffle(x)
d = 0.5 * x + 2 + np.random.normal(0, 0.05, (200,))
from keras.models import Sequential
from keras.layers import Dense
# モデルを作成
model = Sequential()
model.add(Dense(input_dim=1, output_dim=1))
# モデルを表示
model.summary()
# モデルのコンパイル
model.compile(loss='mse', optimizer='sgd')
# train
for i in range(iters_num):
loss = model.train_on_batch(x, d)
if (i+1) % plot_interval == 0:
print('Generation: ' + str(i+1) + '. 誤差 = ' + str(loss))
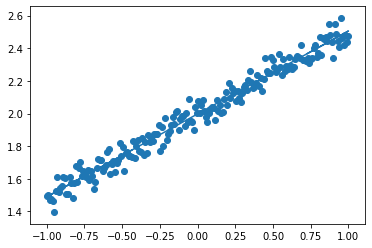
Generation: 1000. 誤差 = 0.0024898422
<考察>
- Tensorflowに比べてKerasの方がコードがシンプルで分かりやすく感じた
単純パーセプトロン
# 乱数を固定値で初期化
np.random.seed(0)
# シグモイドの単純パーセプトロン作成
model = Sequential()
model.add(Dense(input_dim=2, units=1))
model.add(Activation('sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy', optimizer=SGD(lr=0.1))
# トレーニング用入力 X と正解データ T
X = np.array( [[0,0], [0,1], [1,0], [1,1]] )
T = np.array( [[0], [1], [1], [1]] )
# トレーニング
model.fit(X, T, epochs=30, batch_size=1)
# トレーニングの入力を流用して実際に分類
Y = model.predict_classes(X, batch_size=1)
<結果>
True, True,True,True
- np.random.seed(0)をnp.random.seed(1)に変更
- False,True,True,True
- エポック数を100に変更
- True, True,True,True
- AND回路、 XOR回路に変更
- ANDは学習可能であるが、XORは線形分離不可能のためこのモデルでは学習できない
- OR回路にしてバッチサイズを10に変更
- False,True,True,True
- エポック数を300に変更
- True, True,True,True
<考察>
- OR回路でもエポック数やバッチサイズの変更で学習結果が異なることを理解した
- XOR回路は単純パーセプトロンでは分離できないことを理解した
- XOR回路を学習するためには2層のパーセプトロンが必要になる
- Kerasの実装ではエポック数やバッチサイズの変更が容易であることを実感した
分類(iris)
iris = datasets.load_iris()
x = iris.data
d = iris.target
from sklearn.model_selection import train_test_split
x_train, x_test, d_train, d_test = train_test_split(x, d, test_size=0.2)
from keras.models import Sequential
from keras.layers import Dense, Activation
# from keras.optimizers import SGD
# モデルの設定
model = Sequential()
model.add(Dense(12, input_dim=4))
model.add(Activation('relu'))
# model.add(Activation('sigmoid'))
model.add(Dense(3, input_dim=12))
model.add(Activation('softmax'))
model.summary()
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history = model.fit(x_train, d_train, batch_size=5, epochs=20, verbose=1, validation_data=(x_test, d_test))
loss = model.evaluate(x_test, d_test, verbose=0)
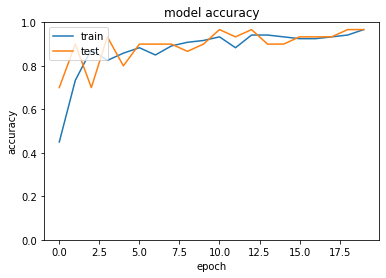
val_acc: 0.9667
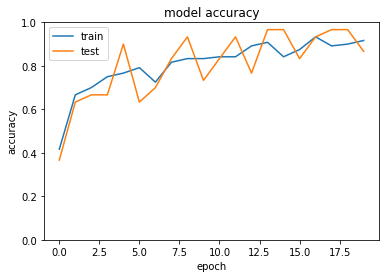
中間層の活性関数をReLU→sigmoidに変更
optimizerをSGD(lr=0.1)に変更
val_acc: 0.8667
<考察>
- 活性化関数をReLUからsigmoidに変更すると、精度が低くなった
- trainとtestとの精度の差がReLUの方が少なかった
- 今回は単純なモデルだったので差が少ないが複雑なモデルだと勾配消失が起こるためReLUの方が精度が高くなると推測される
- 学習率を変更すると、収束までの回数が少なかった
分類(mnist)
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
# モデル作成
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax'))
model.summary()
# バッチサイズ、エポック数
batch_size = 128
epochs = 5
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.01, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False),
metrics=['accuracy'])
history = model.fit(x_train, d_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, d_test))
loss = model.evaluate(x_test, d_test, verbose=0)
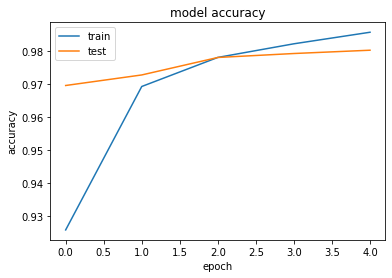
Test loss: 0.06423825728407828
Test accuracy: 0.9802
- load_mnistのone_hot_labelをFalseに変更しよう (error)
- errorになった
- 誤差関数をsparse_categorical_crossentropyに変更しよう
- 問題なく稼働した
- Adamの引数の値を変更しよう
- 学習率を0.001→0.01に変更して実行
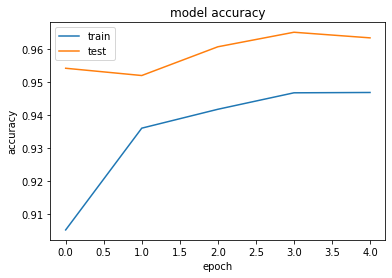
Test loss: 0.141413943686321
Test accuracy: 0.9634
<考察>
- one_hot_labelの場合はcategorical_crossentropyで評価、one_hot_labelではないカテゴリ変数の場合はsparse_categorical_crossentropyを用いることを理解した
- 学習率が0.01よりも0.001の方が精度が高かった
- 学習する回数も多いため、学習率が少ないほうが良い結果になったものと推測する
RNN
model = Sequential()
model.add(SimpleRNN(units=16,
return_sequences=True,
input_shape=[8, 2],
go_backwards=False,
activation='relu',
# dropout=0.5,
# recurrent_dropout=0.3,
# unroll = True,
))
# 出力層
model.add(Dense(1, activation='sigmoid', input_shape=(-1,2)))
model.summary()
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.1), metrics=['accuracy'])
# model.compile(loss='mse', optimizer='adam', metrics=['accuracy'])
history = model.fit(x_bin, d_bin.reshape(-1, 8, 1), epochs=5, batch_size=2)
<結果>
Test loss: 0.0002635647432751196
Test accuracy: 1.0
- RNNの出力ノード数を128に変更
- Test loss: 0.00023303030571066784
- Test accuracy: 1.0
- RNNの活性化関数を sigmoid に変更
- Test loss: 0.1437570298864956
- Test accuracy: 0.9069906990818292
- RNNの活性化関数を tanh に変更
- Test loss: 0.00018681757391885155
- Test accuracy: 1.0
- 最適化方法をadamに変更
- Test loss: 6.516284079761758e-08
- Test accuracy: 1.0
- RNNの入力 Dropout を0.5に設定
- Test loss: 0.1306398273816835
- Test accuracy: 0.8415341533855363
- RNNの再帰 Dropout を0.3に設定
- Test loss: 0.01195037082694184
- Test accuracy: 0.9828232822984275
- RNNのunrollをTrueに設定
- Test loss: 3.3513248808932866e-08
- Test accuracy: 1.0
<考察>
- 出力ノード数を増やすと時間がかかるが精度が向上することが理解できた
- 活性化関数をsigmoidに変更すると学習が進まなくなった。勾配消失と思われる
- 活性化関数をtanhに変更した場合は精度の向上が見られた
- 最適化の方法をAdamに変更すると精度が向上した
- RNNの入力 Dropout を0.5に設定すると、今回のケースでは学習が進まなかった
- RNNの再帰 Dropout を0.3に設定すると、学習は進むが精度が低くなった
- RNNのunrollをTrueに設定すると、学習の速度が向上した
- 複雑なモデルになると精度が高くなるパラメータに傾向があるように感じた
- 活性化関数はReLU、最適化の方法はAdam等