はじめに
COBOLハッカソン2020関連記事その2です。ここでは当活動で利用した要素技術について個別に記載します。
関連記事
(1) コンセプト
(2) 要素技術 <=当記事
(3) 実行結果/まとめ
全体像
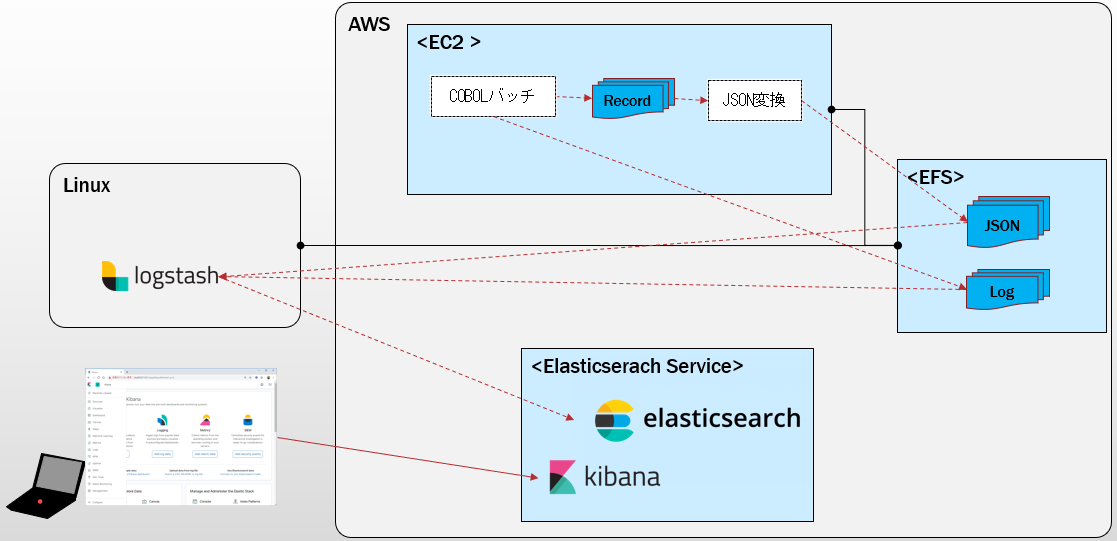
COBOLから出力されたレコードベースのファイルをElasticsearchに取り込んでKibanaで確認する、ということを実現するのに利用した仕組みです。
Logstashを使ってElasticsearchにデータの取り込みを行っていますが、最初はここもAWS上のEC2で実装しようと思いましたが、無料の範囲でやろうとするとマシンスペックが貧弱でしんどそうだったので、この部分だけローカルPC上のLinux(VirturalBox)を使いました。
EFSでオンプレとEC2のファイル共有みたいなことも試せたのでこれはこれで有用かと思います。
- EC2: Amazon Linux上にopensourceCOBOL環境を構築したもの。COBOL実行環境として利用。
- PC上のLinux: Elasticsearchにデータを取り込むLogstash稼働サーバーとして利用。
- EFS: Elasticsearchに取り込む情報を格納するファイルサーバー。上の2環境からそれぞれNFSマウントして接続し、両環境間でファイルを共有するために利用。
- Elasticsearch Service: データの取り込み先(データストア)、および、分析/可視化の基盤として利用。
要素技術確認
ここでは、上の仕組みを実現する際に利用した個々の要素技術について個別に見ていきます。(EC2環境構築部分は、ハッカソンのハンズオンで出来合いのイメージから作成しただけなので、詳細は割愛します)
COBOLアプリからのファイル出力
参考: OpenCOBOL 1.1 Programmer’s Guide
今回のハッカソンでは、AWS上のEC2(Amazon Linux)上に、opensource COBOL環境を用意して、そこでCOBOLアプリを動かすハンズオンがあったので、COBOLの実行環境としてはこれをそのまま使います。
opensource COBOLでファイルIOを行うと、Linux上のファイルの読み書きができます。COBOLの作法に従ってファイルI/Oが普通にできます。(ここでは、LINE SEQUENTIALファイルを扱いますが、Relative File, Indexed Fileも扱えるようです。)
ソース
COBOLで単純なファイル入出力のアプリの動作を試してみます。
まずはデータ構造として、以下のような構造のレコードを扱う想定をします。
03 Brand Pic x(3).
03 Location.
05 Location-Number Pic 9(4).
05 Location-Type Pic XX.
05 Location-Name Pic X(35).
03 Address-A.
05 Address-1 Pic X(40).
05 Address-2 Pic X(40).
05 Address-3 Pic X(35).
03 Postcode Pic 9(10).
03 State Pic XXX.
03 Location-Active Pic X.
これをファイルから読み取ったデータをそのまま別のファイルに書き出すような単純なサンプルを用意します。以下の記事をそのまま参考にさせて頂きました。
1人COBOL再研修〜データ入出力編〜
IDENTIFICATION DIVISION.
PROGRAM-ID. fileio01.
*
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
FILE-CONTROL.
SELECT IN-FILE ASSIGN TO IN-FILE-NAME
ORGANIZATION IS LINE SEQUENTIAL.
SELECT OUT-FILE ASSIGN TO OUT-FILE-NAME.
*
DATA DIVISION.
************************************
FILE SECTION.
FD IN-FILE LABEL RECORD STANDARD
BLOCK CONTAINS 0 RECORDS.
01 IN-REC.
COPY "location.cpy".
FD OUT-FILE LABEL RECORD OMITTED.
01 OUT-REC.
COPY "location.cpy".
************************************
WORKING-STORAGE SECTION.
01 IN-DATA.
COPY "location.cpy".
* 03 IN-STR PIC X(10).
01 FLG-EOF PIC X(01).
*
01 IN-FILE-NAME PIC X(255).
01 OUT-FILE-NAME PIC X(255).
*
PROCEDURE DIVISION.
***********************************
* Main Logic
PGM-MAIN SECTION.
PGM-MAIN-S.
ACCEPT IN-FILE-NAME FROM ENVIRONMENT "INFILENAME".
DISPLAY "IN-FILE: " IN-FILE-NAME.
ACCEPT OUT-FILE-NAME FROM ENVIRONMENT "OUTFILENAME".
DISPLAY "OUT-FILE: " OUT-FILE-NAME.
PERFORM FILE-OPEN.
PERFORM FILE-READ.
PERFORM FILE-WRITE-READ
UNTIL FLG-EOF = '1'.
PERFORM FILE-CLOSE.
PGM-MAIN-E.
STOP RUN.
*********************************
* File Open
FILE-OPEN SECTION.
FILE-OPEN-S.
OPEN INPUT IN-FILE
OUTPUT OUT-FILE.
MOVE SPACE TO FLG-EOF.
FILE-OPEN-E.
EXIT.
* File Read
FILE-READ SECTION.
FILE-READ-S.
READ IN-FILE INTO IN-DATA
AT END
MOVE '1' TO FLG-EOF
END-READ.
FILE-READ-E.
EXIT.
* File Write and Read
FILE-WRITE-READ SECTION.
FILE-WRITE-READ-S.
WRITE OUT-REC FROM IN-DATA AFTER 1.
PERFORM FILE-READ.
FILE-WRITE-READ-E.
EXIT.
* File Close
FILE-CLOSE SECTION.
FILE-CLOSE-S.
CLOSE IN-FILE
OUT-FILE.
FILE-CLOSE-E.
EXIT.
入力ファイル、出力ファイルは環境変数で指定するようにしています。
コンパイル
cobcコマンドでコンパイル。
[ec2-user@ip-10-0-0-181 cobol]$ cobc fileio01.cob
実行
テスト用のデータをinfile01.txtに用意しておき、結果をoutfile01.txtに出力させるようにします。
[ec2-user@ip-10-0-0-181 cobol]$ export INFILENAME=infile01.txt
[ec2-user@ip-10-0-0-181 cobol]$ export OUTFILENAME=outfile01.txt
[ec2-user@ip-10-0-0-181 cobol]$ cobcrun fileio01
IN-FILE: infile01.txt
OUT-FILE: outfile01.txt
outfile01.txtにinfile01.txtと同じ内容のデータが出力されればOKです。
これでCOBOLからのファイル出力が確認できました。
EFS(Elastic File System)
AWS上では様々なストレージサービスがあるようですが、ここでは、EFS(Elastic File System)というNFSサーバーを使ってみます。一応無料もあるみたいだし。
参考: Amazon EFS の料金
ファイルシステム作成
AWSコンソールのサービスからEFSを選択して、ファイルシステムの作成をクリックします。
上で利用しているCOBOL実行環境用EC2と同じVPCを選択します。
各種ファイルシステムの設定を行います。
この辺はデフォルトのまま
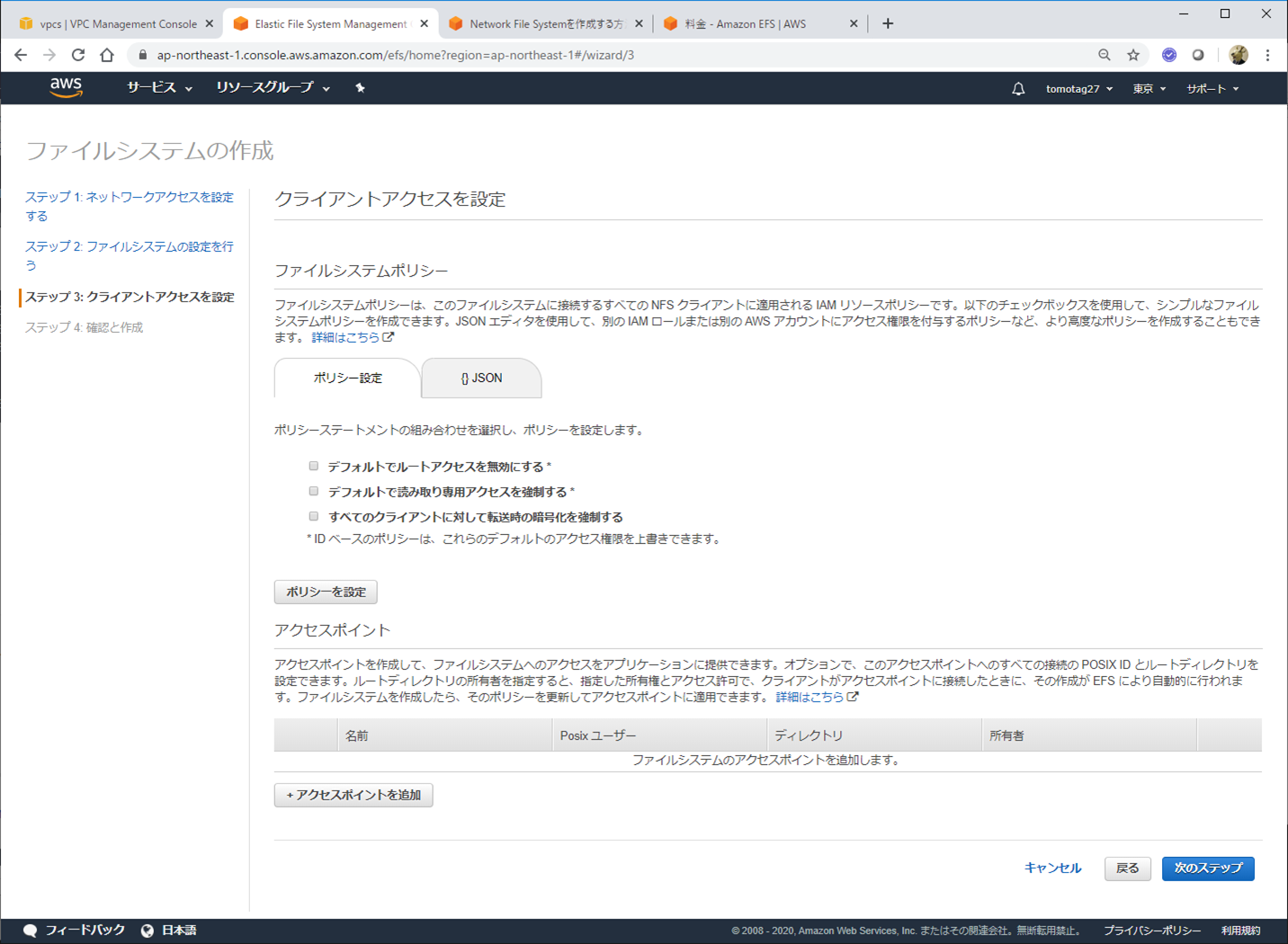
確認して作成!
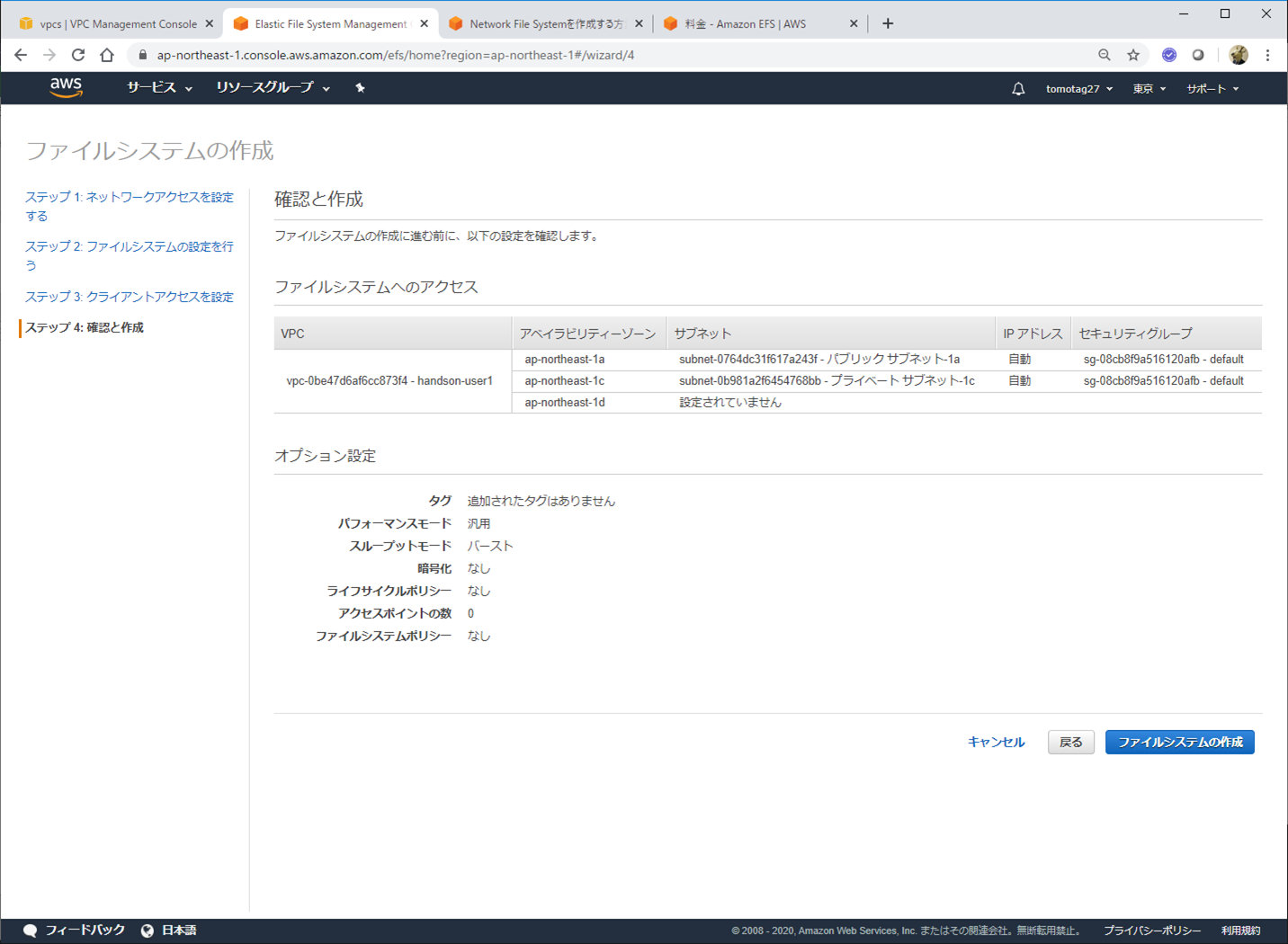
できました。
ご丁寧にマウント手順のリンクも載っていて、クリックすると以下のようなガイドがでます。
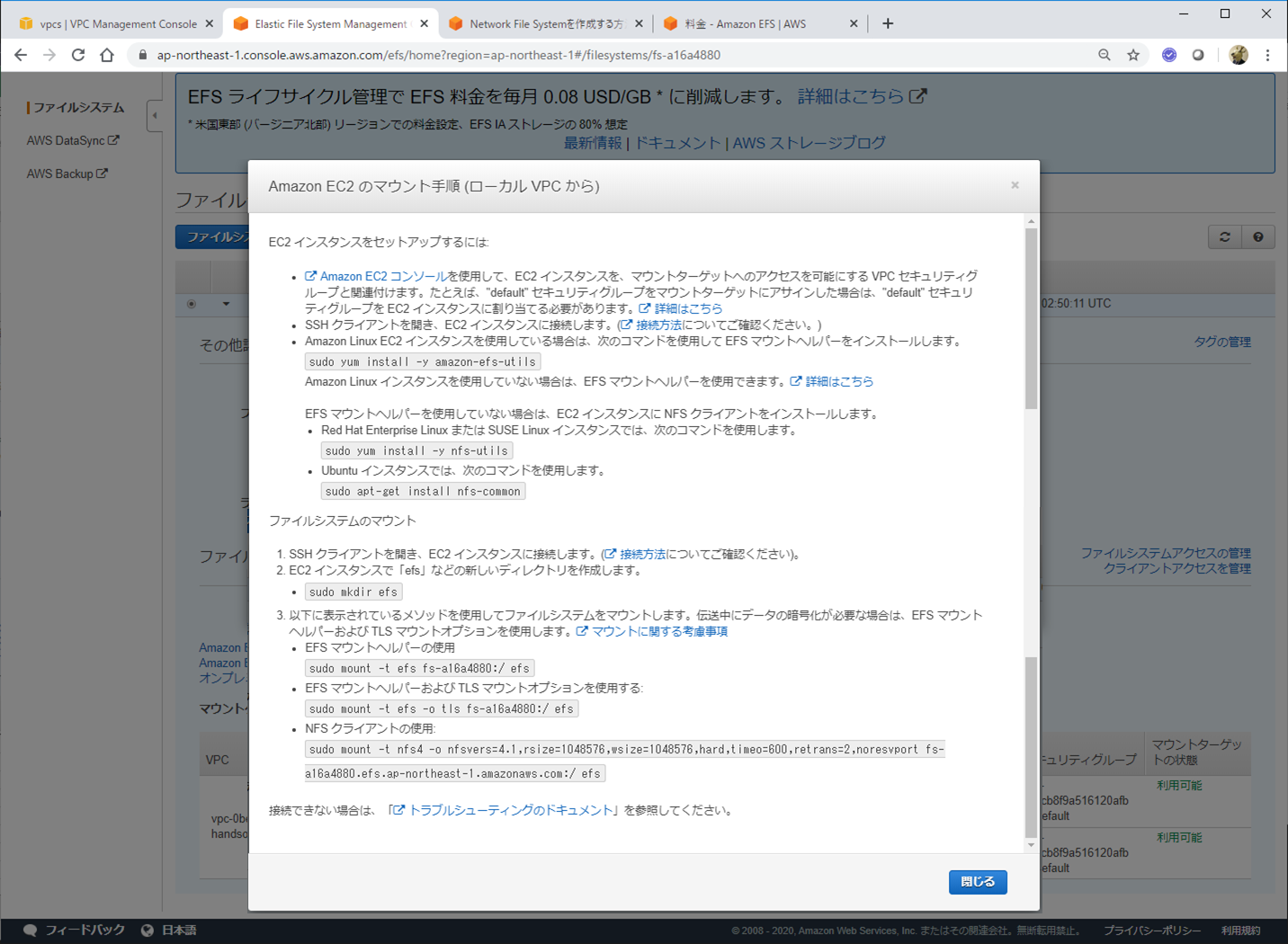
ただ、セキュリティ設定とかデフォルトのままだと、マウントがうまくいきませんでした。
参考: [EFS]マウント時にConnection timed outが出て少しハマる
そのため、上の記事を参考に、EC2の管理画面から、NFS用のセキュリティグループを追加します。
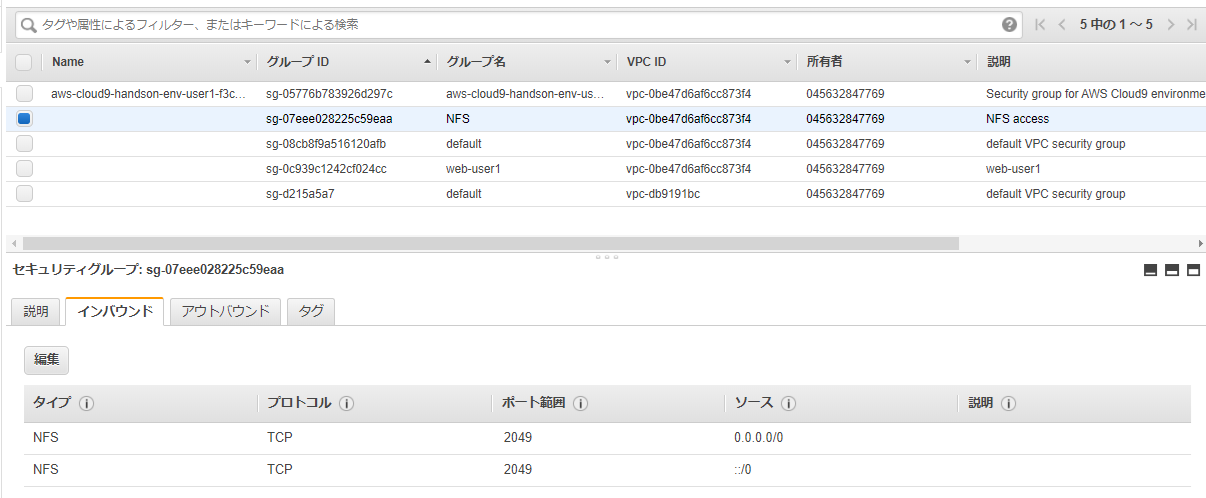
NFS V4は2049番ポートが使われるので、それを許容するようなセキュリティグループを作成します。
EFSの管理画面に戻って、ファイルシステムアクセスの管理から、上で作成したNFS用のセキュリティグループを追加
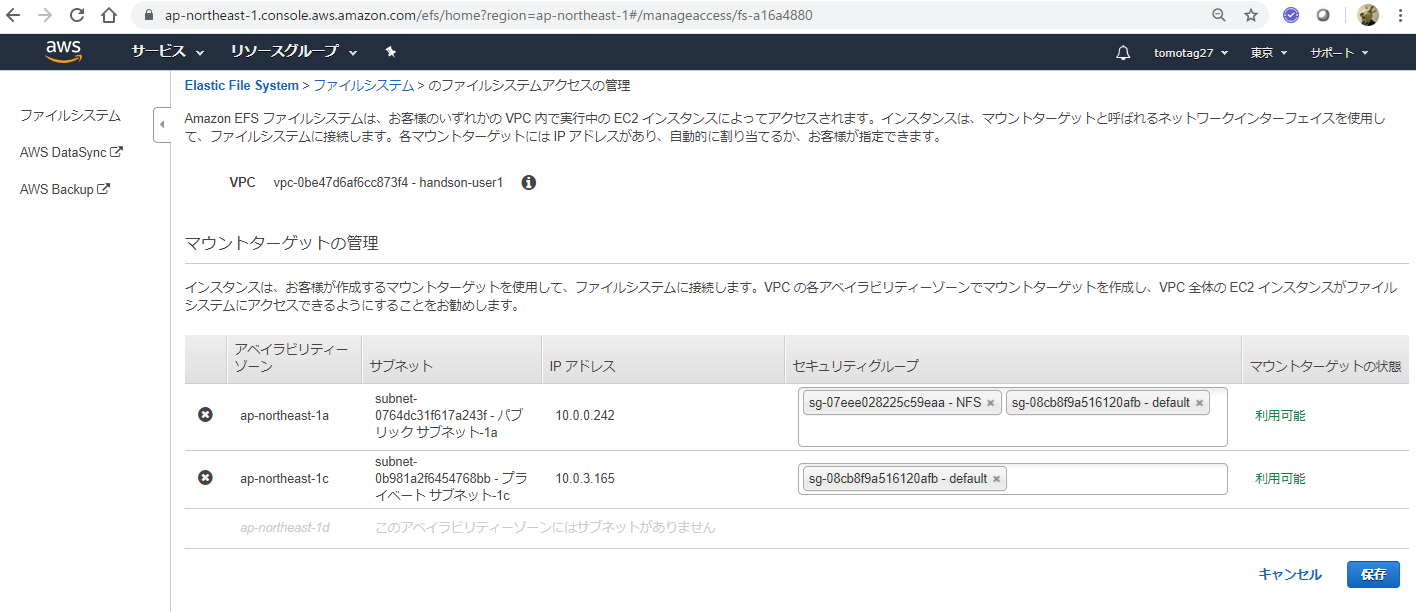
これで、後述のマウント処理ができるようになりました。
EC2からのマウント
以下のコマンドでマウントします。mountコマンドで指定しているのは、EFS作成時にアサインされたファイルシステムIDです。
[ec2-user@ip-10-0-0-181 ~]$ mkdir efs
[ec2-user@ip-10-0-0-181 ~]$ sudo mount -t efs fs-a16a4880:/ efs
[ec2-user@ip-10-0-0-181 ~]$ df -m
Filesystem 1M-blocks Used Available Use% Mounted on
devtmpfs 475 0 475 0% /dev
tmpfs 492 0 492 0% /dev/shm
tmpfs 492 1 492 1% /run
tmpfs 492 0 492 0% /sys/fs/cgroup
/dev/xvda1 8180 2629 5552 33% /
tmpfs 99 0 99 0% /run/user/1000
fs-a16a4880.efs.ap-northeast-1.amazonaws.com:/ 8796093022207 0 8796093022207 0% /home/ec2-user/efs
マウントできました!
PC上のLinuxからマウント
参考: SSH ポートフォワーディングを使って EFS を Mac からマウントしてみた
AWS上ではなく、PC上のLinuxからマウントしてみます。EFSのサーバーは外部からアクセスさせるためには、公開IPをアサインしたりする必要があるのですが、今回はテスト用なので、上でマウントが確認できたEC2を踏み台にして、SSHポートフォワードを経由してマウントしてみます。
PC上のLinux側からポートフォワード
$ ssh -i /root/.ssh/handson-key-user1.pem -f -N -L 2049:fs-a16a4880.efs.ap-northeast-1.amazonaws.com:2049 ec2-user@xx.xx.xx.xx
pemファイル: EC2へのssh接続用の秘密鍵
fs-a16a4880.xxx.com: EFSサーバーのDNS名
ec2-user@xx.xx.xx.xx: EC2へのssh接続時のユーザーとIPアドレス
これで、ローカルの2049ポートへのリクエストがEFSサーバーにフォワードされるはずなので、次に、以下のコマンドでマウントします。
$ mkdir /efs
$ mount -t nfs4 -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport localhost:/ /efs
$ df -m | grep efs
localhost:/ 8796093022207 0 8796093022207 0% /efs
マウントできました!
PC上のLinuxからここにファイルを作って、EC2上から参照できました。
これでファイル共有ができていることが確認できました!
Elasticsearch Service
参考: Amazon Elasticsearch Service開発者ガイド
ElasticsearchをAWS上で提供してくれるサービスです。Elasticsearchの管理やデータの分析/可視化のためのUIを提供してくれるKibanaも、このサービスに含まれて提供されるようです。
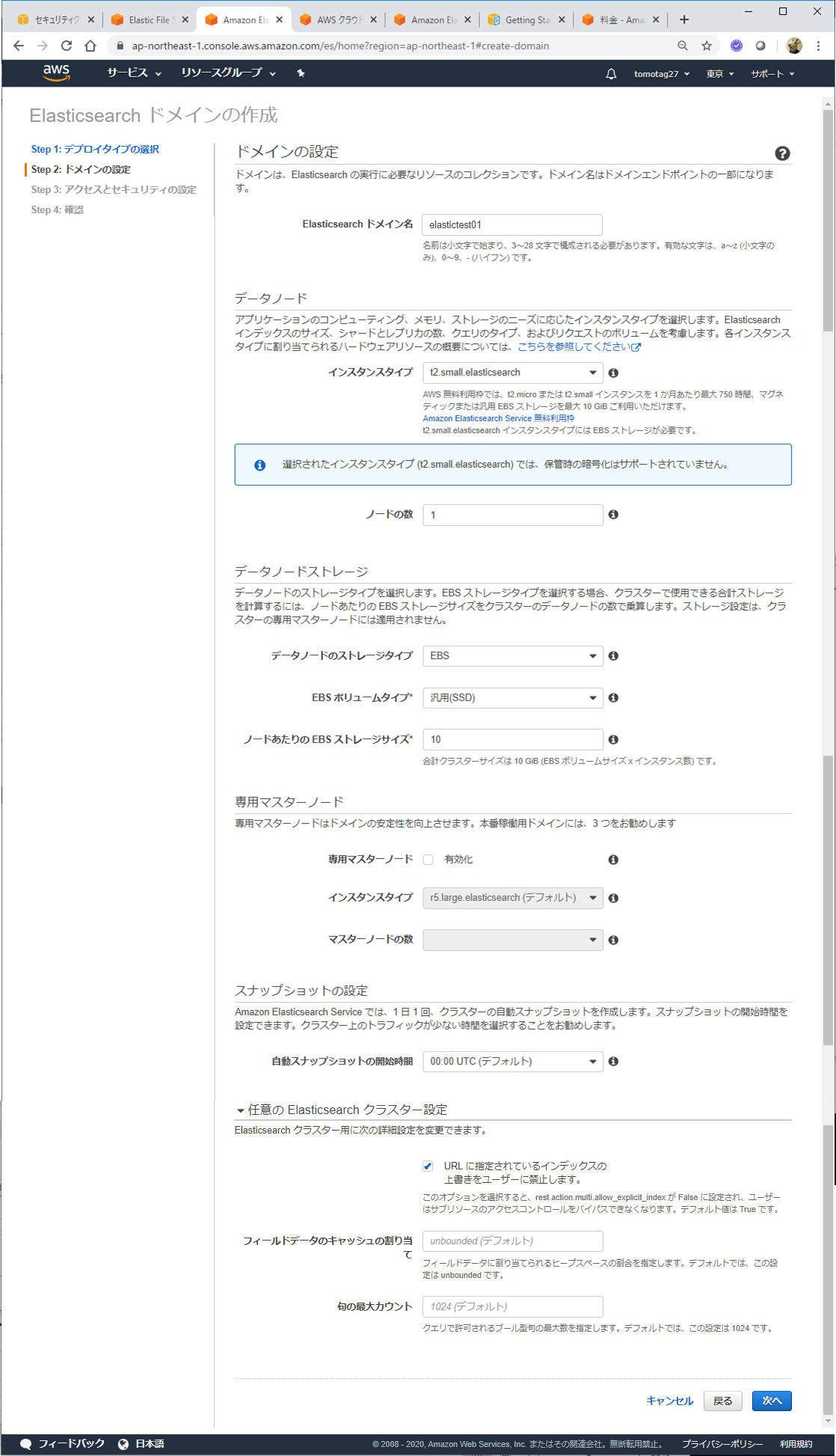
インスタンス作成
AWSコンソールのサービスからElasticsearch Serviceを選択し、新しいドメインの作成をクリック
開発およびテストをチェック
各種設定を行います。t2.small.elasticsearchは無料枠で使えるようです。
ネットワークやセキュリティの設定などを行います。ここではパブリックアクセスを選択します。
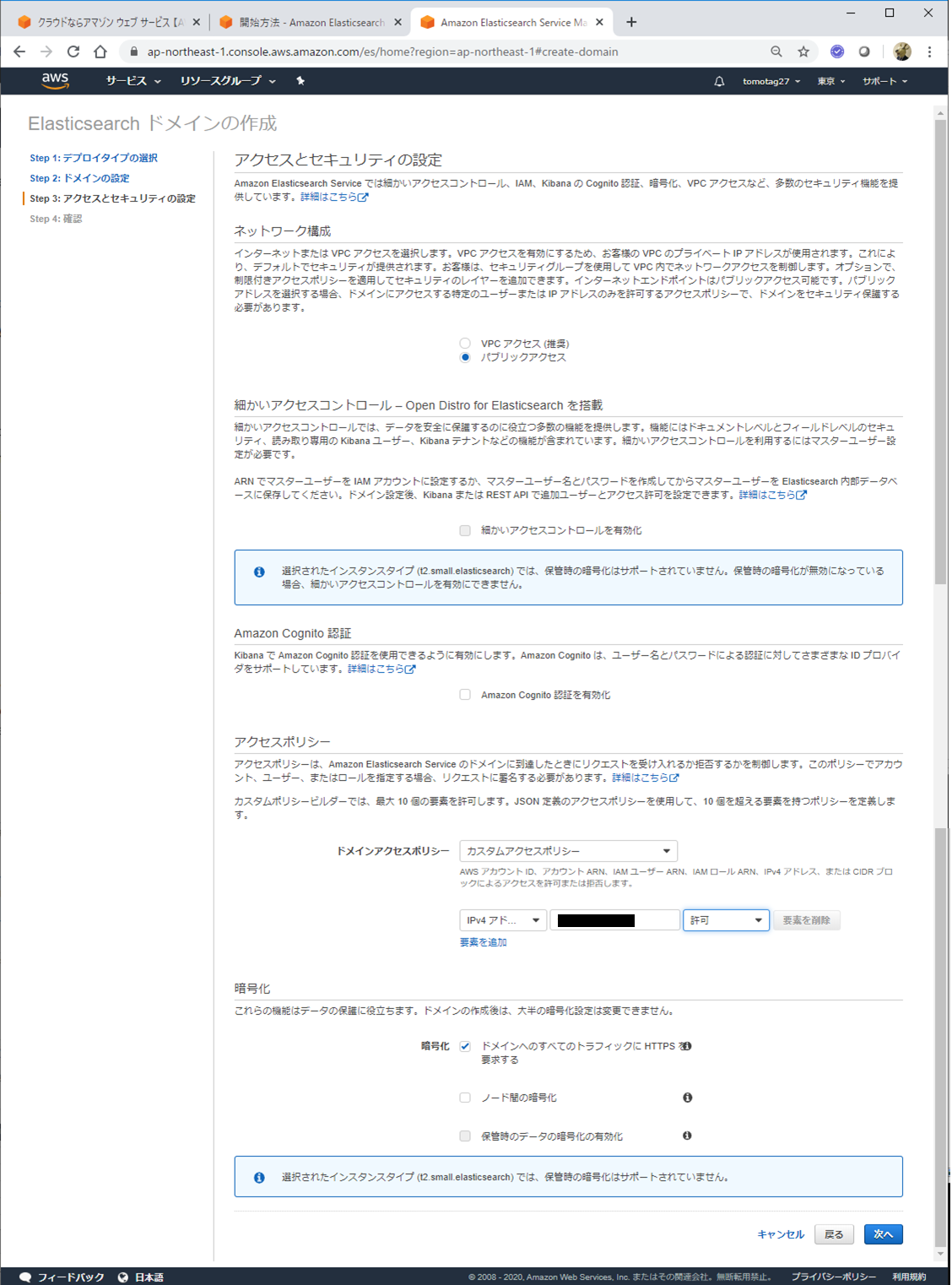
アクセスポリシーでは、特定のIPアドレスからのリクエストを許可するよう設定しています。自PCからアクセスする想定なので、自PCのIPアドレスを黒塗りの所に指定しています。
ちなみにGlobal IPは、以下のサイトなどで確認できます。
https://www.cman.jp/network/support/go_access.cgi
最後に内容確認すると、Elasticsearchのドメインが作成されます。これには若干時間がかかって、10~15分くらい待たされました。
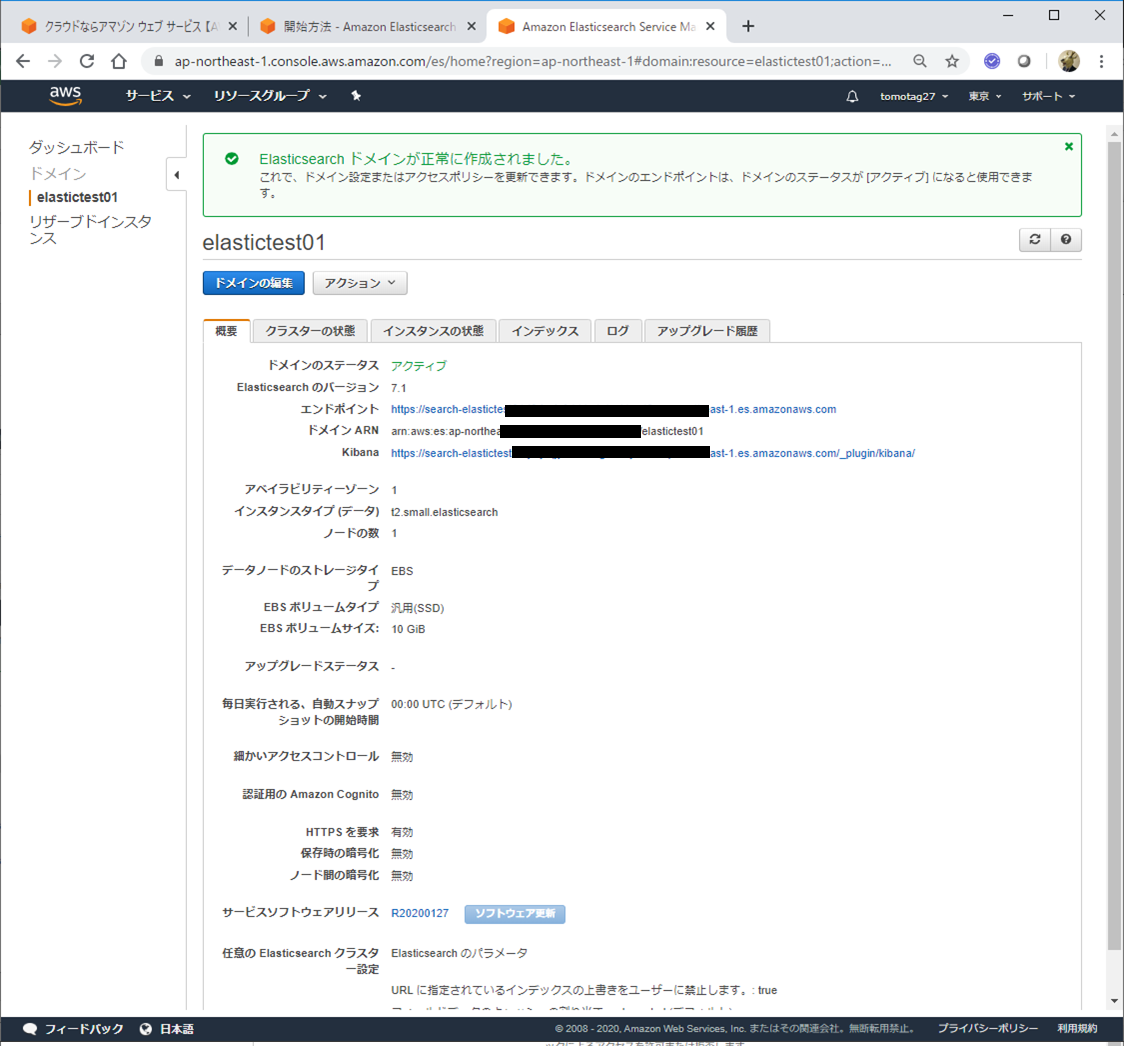
黒塗りされている所がElasticsearch, Kibanaのアクセスポイントです。
Kibanaのリンクをクリックすると、Kibanaのコンソールにアクセスできました!
レコードベースのデータの取り込み(1)
COBOLとElasticsearch周辺の環境が出来てきたので、あとはこの間をつなぐ部分です。
Elasticsearchにデータを取り込むための仕組みとしては、Logstashやらfluentdやらembulkやら色々ありそうですが、いずれもさすがにCOBOLのCopybookを元にフォーマットするようなものは無さそうです。
色々調べていると、以下のようなCopybookを元にJSONに変換するユーティリティーがありました。
https://sourceforge.net/projects/coboltojson/
JSON変換できれば取り込みもだいぶ楽なので、とりあえずはこれを利用してみることにします。
また、データ転送には、Elasticsearchとセットで使われることも多いLogstashを使うことにします。
Copybookを元にしたレコードからJSONへの変換
上のcoboltojsonユーティリティーでは、Javaで実装されたコンバーターが提供されています。レコードファイルと、そのフォーマットを示すCopybookを入力として指定すると、JSON形式のファイルを生成してくれます。使いやすいようにCobol2Json.shというスクリプトも提供してくれています。
01 message.
03 Brand Pic x(3).
03 Location.
05 Location-Number Pic 9(4).
05 Location-Type Pic XX.
05 Location-Name Pic X(35).
03 Address-A.
05 Address-1 Pic X(40).
05 Address-2 Pic X(40).
05 Address-3 Pic X(35).
03 Postcode Pic 9(10).
03 State Pic XXX.
03 Location-Active Pic X.
後々加工しやすいように、01レベルに「message」という固定の名前を付けるようにしておきます。
入力となるレコードはこんな感じ
TAR5015STBankstown Bankstown Unit 2, 39-41 Allingham Street Condell Park 2200 NSWA
TAR5019STPenrith Penrith 58 Leland Street Penrith 2750 NSWA
TAR5033STBlacktown Marayong Dock 2, 11 Melissa Place Marayong 2148 NSWA
TAR5035STRockdale Building B, Portside DC 2-8 Mc Pherson Street Botany 2019 NSWA
TAR5037STMiranda Westfield Shoppingtown Cnr. Urunga Pde & The Kingsway Miranda 2228 NSWA
TAR5052STEastwood Marayong Offsite Reserve 11 Melissa Place Marayong 2148 NSWA
TAR5055STLeichhardt Marketown Marion Street Leichhardt 2040 NSWA
TAR5060STSt Marys St. Mary's Charles Hackett Drive St Mary's 2760 NSWA
TAR5070STBass Hill Bass Hill Plaza 753 Hume Highway Bass Hill 2197 NSWA
TAR5074STCampbelltown Campbelltown Mall 303 Queen Street Campbelltown 2560 NSWA
TAR5078STWarringah Mall Frenchs Forest Units 2-3, 14 Aquatic Drive Frenchs Forest 2086 NSWA
TAR5081STAshfield Ashfield Mall Knox Street Ashfield 2131 NSWA
TAR5085STRoselands Condell park Unit 2, 39-41 Allingham Street Condell Park 2200 NSWA
実行してみます。
[ec2-user@ip-10-0-0-181 cobol]$ /home/ec2-user/c2j/lib/Cobol2Json.sh -cobol location.cpy -fileOrganisation Text -input infile01.txt -output outfile01.json
作成されたoutfile01.jsonファイルを確認してみます。
{
"message" : [ {
"Brand" : "TAR",
"Location" : {
"Location-Number" : 5015,
"Location-Type" : "ST",
"Location-Name" : "Bankstown"
},
"Address-A" : {
"Address-1" : "Bankstown",
"Address-2" : "Unit 2, 39-41 Allingham Street",
"Address-3" : "Condell Park"
},
"Postcode" : 2200,
"State" : "NSW",
"Location-Active" : "A"
}, {
"Brand" : "TAR",
"Location" : {
"Location-Number" : 5019,
"Location-Type" : "ST",
"Location-Name" : "Penrith"
},
"Address-A" : {
"Address-1" : "Penrith",
"Address-2" : "58 Leland Street",
"Address-3" : "Penrith"
},
"Postcode" : 2750,
"State" : "NSW",
"Location-Active" : "A"
...
01レベルで指定した"message"という項目に、配列で各レコードのデータが設定される構造になっています。
このように、Copybookの構造に従ってJSON形式に変換されることが確認できました!
※上の例でははLinuxファイルで日本語無しのテキスト(UTF-8≒ASCII)しか扱っていませんが、このユーティリティはなかなか優秀なようで、文字コードの明示指定も可能です。後述の記事のシナリオではSJISベースの日本語を含んだデータでも試しています。コード変換にはJavaのコンバーターが使われているようなので、ホストから転送してきたデータを直接ハンドリングする、というような応用もききそうです(IBM Javaを利用すれば、EBCDICのコンバーターも提供されます)。
LogstashからElasticsearchへの出力
参考: Logstash tutorial: A quick start guide
LogstashからAWS上のElasticsearch Serviceへデータを送信する際は専用のプラグインが必要のようです。(通常、Elasticsearchにデータを出力する際は、標準のelasticsearch output pluginを使えばよいのですが、それではAWS上のサービスには接続できずにハマりました。)
AWS上のElasticsearch用のプラグインをLogstashに追加します。
$ /usr/share/logstash/bin/logstash-plugin install logstash-output-amazon_es
Validating logstash-output-amazon_es
Found logstash-output-amazon_es (6.4.1), but was for platform x86_64-linux
Installing logstash-output-amazon_es
Installation successful
次に、Elasticsearchアクセス用のユーザーを作成します。
AWSコンソールのサービスから、IAMを選択します。左側のメニューからユーザーを選択し、ユーザーを追加をクリックします。
ユーザー名を指定して、プログラムによるアクセスをチェックします。
既存のポリシーを直接アタッチを選択して、AmazonESFullAccessにチェックします。
タグの追加はなにもせずそのまま。
確認してユーザーの作成をクリック
すると、以下のようにユーザーが作成されて、アクセスキーIDとシークレットアクセスキーがアサインされます。
Logstash側に戻って、Logstashの構成ファイルを以下のように作成します。
input {
stdin{}
}
output {
amazon_es {
hosts => ["search-elastictest01-xxxx.ap-northeast-1.es.amazonaws.com"]
region => "ap-northeast-1"
aws_access_key_id => 'Axxxxxxxxxxxxxxxx4'
aws_secret_access_key => 'fxxxxxxxxxxxxxxxxxxxl'
index => "test-%{+YYYY.MM.dd}"
}
}
テスト用なので、stdinのデータをそのままelasticsearchに入れるような設定にしています。
aws_access_key_id, aws_secret_access_keyは上でユーザーを作成した際にアサインされたものを指定します。
Logstash起動してstdinから入力したデータがElasticsearchに取り込まれるはずなので、Kibanaで確認します。
test-xxxというindexを作成するようにしているので、Kibana上でtest-*というindex pattern作成してDiscoverで見てみるとデータが投入されていることが確認できました!
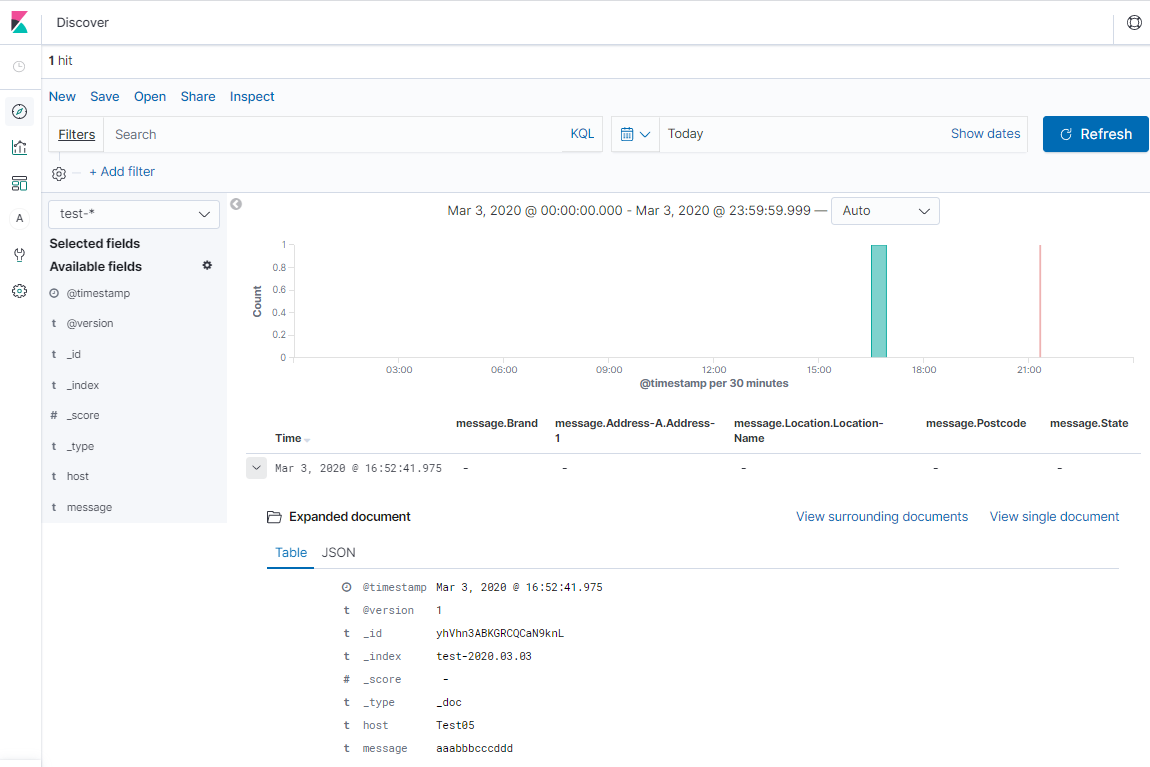
LogstashによるJSONファイルのElasticsearchへの取り込み
レコードファイルから変換されたJSONファイルをLogstash経由でElasticsearchに取り込んで見ます。
構成ファイルは
input {
file{
path => "/efs/outfile*.json"
mode => "read"
file_completed_action => "log"
file_completed_log_path => "/efs/file_completed.txt"
sincedb_path => "/efs/temp.sincedb"
}
}
filter {
json {
source => "message"
}
split { }
}
output {
amazon_es {
hosts => ["search-elastictest01-xxxx.ap-northeast-1.es.amazonaws.com"]
region => "ap-northeast-1"
aws_access_key_id => 'Axxxxxxxxxxxxxx4'
aws_secret_access_key => 'fxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxl'
index => "cob-location-%{+YYYY.MM.dd}"
}
}
/efs/outfile*jsonというファイルを取り込んでElasticsearchに取り込む想定です。
/efsにこのネーミングルールにそったJSONを含むファイルを配置して、Elasticsearchに取り込まれればOKです!
レコードベースのデータの取り込み(2)
上の例では、業務データとして扱われているレコードを想定していました。そういうレコードの場合データ構造は複雑になりがちですし、アプリやデータの種類によって構造も異なります。そのため、上の例のようにCopybookから構造をマッピングさせる必要があります。
一方、アプリケーションの稼働状況などを出力するような、いわゆるアプリケーション・ログについては、フォーマットも単純である程度固定になると思います。そういうものは、Copybookとマッピングさせて構造を判断させなくても、正規表現などを用いて手動で構造を記述してしまった方が早いです。
例えば、以下のような構造のアプリ・ログを出力することを想定します。
01 APL-LOG.
03 AL-YEAR PIC 9(4).
03 FILLER PIC X(1) VALUE "/".
03 AL-MONTH PIC 9(2).
03 FILLER PIC X(1) VALUE "/".
03 AL-DAY PIC 9(2).
03 FILLER PIC X(1) VALUE "-".
03 Al-HOURS PIC 9(2).
03 FILLER PIC X(1) VALUE ":".
03 AL-MINUTES PIC 9(2).
03 FILLER PIC X(1) VALUE ":".
03 AL-SECONDS PIC 9(2).
03 FILLER PIC X(1) VALUE ".".
03 AL-10MSEC PIC 9(2).
03 FILLER PIC X(1) VALUE " ".
03 AL-BATID PIC X(8) VALUE "BATCH001".
03 FILLER PIC X(1) VALUE " ".
03 AL-MSGID PIC X(8).
03 FILLER PIC X(2) VALUE ": ".
03 AL-MSGTXT PIC X(100).
この構造を元に出力されるメッセージ例としては以下のイメージになります。
2020/03/03-19:27:25.76 BATCH001 MSGID001: Begin Program
2020/03/03-19:27:25.76 BATCH001 MSGID003: Read 1 record from file.
2020/03/03-19:27:32.00 BATCH001 MSGID004: Write 1 record to file.
2020/03/03-19:27:32.00 BATCH001 MSGID003: Read 1 record from file.
2020/03/03-19:27:38.20 BATCH001 MSGID004: Write 1 record to file.
...
2020/03/03-19:28:47.46 BATCH001 MSGID002: End Program
Logstashでは、メッセージのフォーマットを正規表現で表してフィールドにマッピングすることができますので、上の構造をハンドリングするための正規表現を作成します。
DATETIME [0-9]{4,4}\/[0-9]{2,2}\/[0-9]{2,2}-[0-9]{2,2}:[0-9]{2,2}:[0-9]{2,2}\.[0-9]{2,2}
BATCHID .{8,8}
MSGID .{8,8}
PATTERN01 %{DATETIME:date_time} %{BATCHID:batch_id} %{MSGID:msg_id}: %{GREEDYDATA:msg_txt}
上のPATTERN01というのがアプリ・ログの全体を表すことになります。
アプリ・ログのファイルを読み取って、上の正規表現を元に解釈し、Elasticsearchに取り込む、という一連のPipelineを設定すると、構成ファイルはこんな感じになります。
input {
file{
path => "/efs/cob*.log"
start_position => "beginning"
sincedb_path => "/efs/log_temp.sincedb"
}
}
filter {
grok {
patterns_dir => ["/etc/logstash/config_cobol/patterns.d"]
match => {"message" => "%{PATTERN01}"}
}
if ![batch_id] {
drop{}
}
date {
match => [ "date_time", "yyyy/MM/dd-HH:mm:ss.SS" ]
target => "@timestamp"
}
}
output {
amazon_es {
hosts => ["search-elastictest01-xxxxx.ap-northeast-1.es.amazonaws.com"]
region => "ap-northeast-1"
aws_access_key_id => 'Axxxxxxxxxx4'
aws_secret_access_key => 'fxxxxxxxxxxxl'
index => "cob-log-%{+YYYY.MM.dd}"
}
}
これでアプリ・ログがElasticsearchに取り込めるようになります。
Logstash稼働させて、設定に従ったファイルにアプリ・ログを出力して、Elasticsearchに取り込まれたことを確認できればOKです。
その他
Timezone
アプリ・ログのためにCOBOLアプリ中で稼働時のタイムスタンプを取得する場合、取得された時刻は稼働環境のTimizoneに依存してしまいます。EC2のTimezoneを日本時間にしておきたいので、以下のコマンドでTimezoneをAsia/Tokyoに変更しておきました。
[ec2-user@ip-10-0-0-181 ~]$ sudo ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime
[ec2-user@ip-10-0-0-181 ~]$ date
Tue Mar 3 19:20:12 JST 2020
これで時刻がJSTで返されるようになりました。
(Logstash稼働環境もJSTにしておく)
SJISロケール
EC2環境にSJISのロケールが無かったので、追加してみました。
[ec2-user@ip-10-0-0-181 cobol]$ locale -a | grep ja
ja_JP
ja_JP.eucjp
ja_JP.ujis
ja_JP.utf8
japanese
japanese.euc
[ec2-user@ip-10-0-0-181 cobol]$ sudo localedef -f SHIFT_JIS -i ja_JP ja_JP.sjis
character map `SHIFT_JIS' is not ASCII compatible, locale not ISO C compliant
[ec2-user@ip-10-0-0-181 cobol]$ locale -a | grep ja
ja_JP
ja_JP.eucjp
ja_JP.sjis
ja_JP.ujis
ja_JP.utf8
japanese
japanese.euc
変更
[ec2-user@ip-10-0-0-181 scenario01]$ export LANG=ja_JP.sjis
[ec2-user@ip-10-0-0-181 scenario01]$ locale
LANG=ja_JP.sjis
LC_CTYPE="ja_JP.sjis"
LC_NUMERIC="ja_JP.sjis"
LC_TIME="ja_JP.sjis"
LC_COLLATE="ja_JP.sjis"
LC_MONETARY="ja_JP.sjis"
LC_MESSAGES="ja_JP.sjis"
LC_PAPER="ja_JP.sjis"
LC_NAME="ja_JP.sjis"
LC_ADDRESS="ja_JP.sjis"
LC_TELEPHONE="ja_JP.sjis"
LC_MEASUREMENT="ja_JP.sjis"
LC_IDENTIFICATION="ja_JP.sjis"
LC_ALL=
課金
AWSはアカウント作成後12か月は無料枠があって、多くのサービスを無料で利用できます。
参考: [AWS 無料利用枠](https://aws.amazon.com/jp/free/?all-free-tier.sort-by=item.additionalFields.SortRank&all-free-tier.sort-order=asc
基本、この枠内で実施しているつもりだったのですが、2月分として$2.72課金された旨のメールが飛んできてしまいました。
なんで???
AWSコンソールからサービス-billingで課金の状況など詳細が確認できるので、そこから請求書の詳細見てみると...
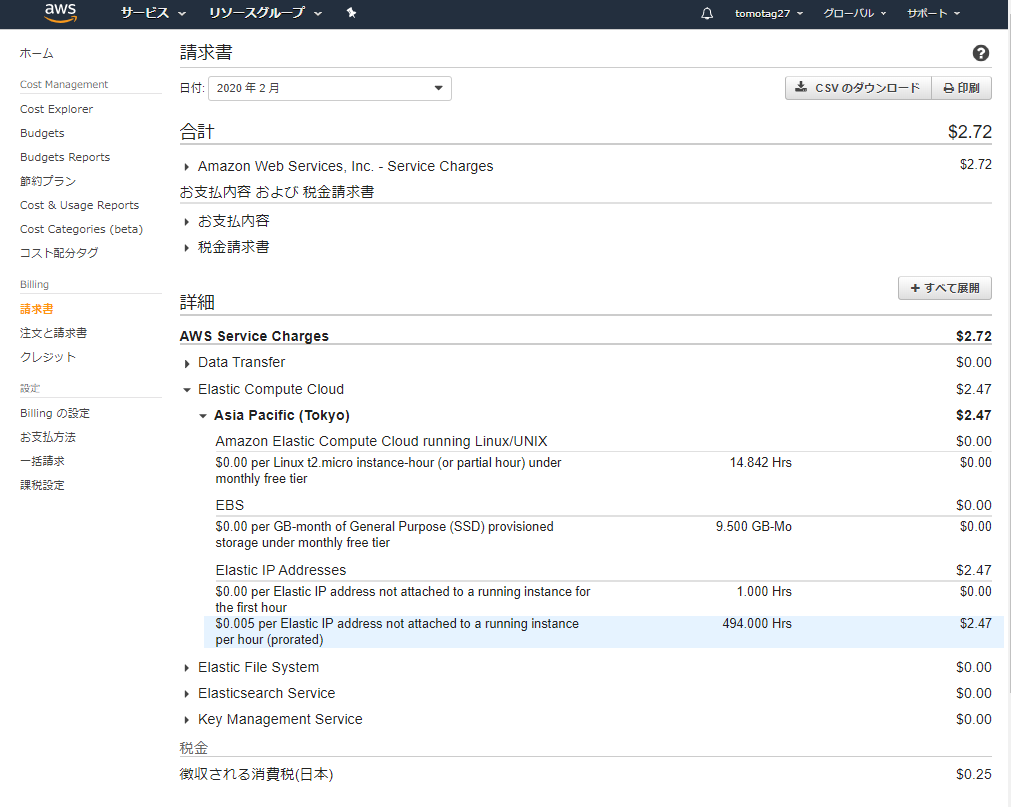
コレが原因でした。
$0.005 per Elastic IP address not attached to a running instance per hour (prorated)
稼働中のインスタンスにアサインされていないElastic IP(外部公開用のIP)は、課金対象になるようです。
EC2にElastic IP割り当てていて、そのEC2を停止させていると課金されていくってことですね。無料枠があればむしろEC2上げっぱなしにしていた方が課金されないという...
うーん分かりにくい。
調べてみるとAWSでは昔からの"あるある"のようですね。
https://www.mogumagu.com/wp/wordpress/archives/1762
不要なElastic IPは早々に開放しましょう。
次は、ここで示した要素技術を組み合わせて具体的なシナリオを流してみます。
前の記事へ<=](https://qiita.com/teamcimkcs2020/private/cb3e8a020e414f7acad3) [=>次の記事へ