はじめに
この記事は、「COBOL ハッカソン 2020 ~IT温故知新 世代を超えた開発コンテスト~」の活動内容について記載したものです。
COBOL ハッカソン 2020
テーマとしては「クラウド連携やってみた!」ということで、COBOLとなんらかのクラウド連携をしてみるというものです。COBOLコンソーシアムが主催となっていますが、アマゾンウェブサービスジャパンが協力しているということで、何かはAWS上で動くものを作るということになっています。
今回、我々のチームが実施した内容は以下の記事に分割して記載していきます。
関連記事
(1) コンセプト <=当記事
(2) 要素技術
(3) 実行結果/まとめ
以下のYoutube動画も合わせてご参照下さい。
Youtube:COBOLレコードのElasticsearchへの取り込み
コンセプト
参考: DXレポート ~ITシステム「2025年の崖」克服とDXの本格的な展開~
経産省が出している上のレポートはあちらこちらで参照されており、「2025年の崖」克服のためのDXの重要性が謳われています。この手の話は言葉を変えつつも以前からずっと続いてきているテーマとも言えます(ホスト集中 => クラサバへ、Web連携、SOA、SoE-SoR などなど...)。いずれも、新しい仕組みにシフトするにしても、スクラップ&ビルドで一切合切を作り直すということではなく、既存の仕組みを活かしながら適材適所で考えるということは共通しているかもしれません。
今回はCOBOLを中心としたハッカソンということですが、テーマとしては"クラウド連携"というのが挙げられており、既存資産の代表ともいえるCOBOLと、比較的新しい世界の"クラウド"環境をそれぞれうまく活用することについて検討しました。
さて、両者の間には文化の違いや技術的な隔たりが多々あると思いますが、ここでは、取り扱うデータ形式の違い、ということに着目してみました。
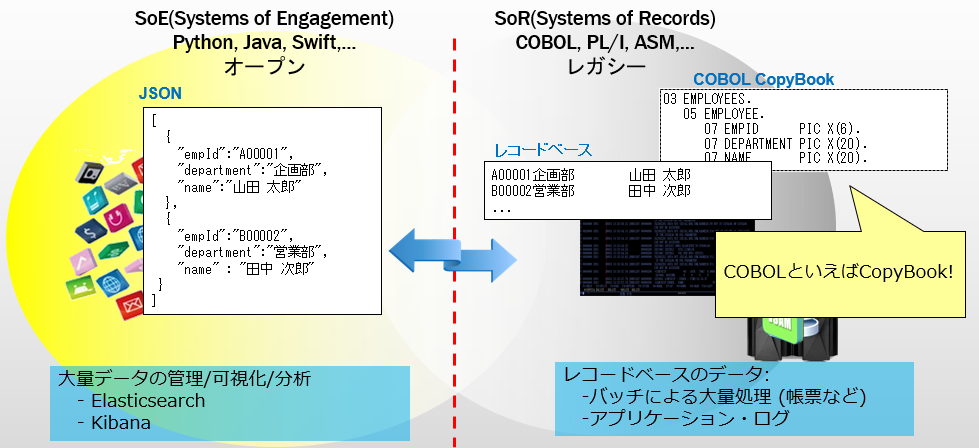
COBOL上ではレコードベースのデータで扱われます。これは特定のオフセットに特定の長さのデータが入るということがあらかじめ決められていて、そのフォーマットに従ってデータが保持されます。データ構造はCopybook(コピー句)によってあらわされます。従って、データそのものだけだとどの部分にどのデータが入っているかは分からず、Copybookの構造と照らし合わせることではじめて意味のあるデータを取り出すことができるということになります。
昨今のサービスで使われるデータ形式はJSONで扱われることが多いと思います。これはデータ自体に項目名や構造を保持しているために疎な連携がしやすく可読性にも優れます。一方でデータサイズが大きくなりがちなので余計な負荷がかかることにもつながります。
COBOLはデータサイズを意識する言語ですので、サイズが可変のJSONのようなデータを直接扱うことは苦手です。そこで、COBOLで扱われているレコードベースのデータをJSONベースのデータにして管理するようなパスが作れれば、既存の仕組みを活用する新しい道が開けるのではないかと考えます。
今回は大量データの管理や可視化、分析などによく利用されるElasticsearchにデータを取り込んで見ることにしました。
テーマ: COBOLアプリから出力されるレコードベースのデータを、Elasticsearchに取り込んでKibanaで簡単に可視化/分析できるようにしてみよう!
方針
基本的には以下の前提/方針で進めることにします。
- 既存のCOBOL資産を有効活用する
- なるべく既存アプリに手を入れなくて済むような仕組みとする
- 要員のスキルセットの境界を明確にする
- COBOLを扱う要員は、従来のCOBOLの作法の範疇で考えればよいようにする(COBOLアプリ側でJSONは意識させない)
- アプリケーションが特定のミドルウェアに直接的に依存しないようにする
- DBとのコネクションなどは保持しない
つまり、できるだけ疎結合になるような方向性で考えたいと思います。
参考
当ハッカソンの前提条件と審査のポイントは以下の通り
前提条件
- 一部でもよいのでCOBOLが使われており、実際にコンピュータ上で稼働すること
- 成果物のうち「何か」がAWS上で稼働していること(ハッカソンのテーマについてはAWSの利用に関するものでなくてもOK)
審査のポイント
- COBOLの特徴を生かした使い方・COBOLをうまく使っている!
- コンセプトの着眼点!(共感度・納得度・面白さ)
- COBOL利用の将来性への貢献度!(有益な手法であること/その情報があるとうれしい人が多そう)
- コンセプトの実現性!(構想だけでなく動く事を検証している)
次は、具体的な仕組み作りに必要な要素技術を個別に見ていきます。