この記事でやること
何かものを認識させたい。JetsonNanoならある。そんな方に向けて
colabを用いて、YOLOv4-tinyのオリジナルモデルを作る方法をご紹介します。
今回は、データの作成までを書いていきます。
以下をつぎはぎした記事になってます
https://qiita.com/nnn112358/items/746357a341ccf9ff6324
http://takesan.hatenablog.com/entry/2018/08/16/013452
https://pjreddie.com/darknet/yolo/
前提知識
- DeepLearning特にCNNに関する基礎知識
- Linuxに関する基礎知識
- python
ここら辺は抑えている必要があります。
pythonはそこまでですが、linuxはcolabでの操作に必須ですのでわかっておいてください。また途中でネットの設定をいじるのですが、そこで何をいじっているのかぐらいはわかっておいた方がいいので、CNNは勉強しておくべし。
YOLOv3-tiny

YOLOはYou Only Look Onceの略だそうな。要は、画像からダイレクトにobjectの位置までを表示してくれるCNNの一種。今回はこれをDarknetというフレームの上で動作させます。このDarknetはCで書かれているので高速だとか何とか。筆者は高校の時、YOLOを知らず、自分でこの仕組みを作って自慢していたのは秘密。
YOLO-tinyはJetsonNanoでも15fps程度で動いてくれるので、ロボットに搭載する時にはお勧め。
colab
神様、仏様、Google様
https://colab.research.google.com/
colabはGoogleが提供する無料の機械学習プラットフォーム。あんな子やこんな子といったGPUを無料で使わせてもらえる。ただ、90min以上放置すると機嫌を損ねて学習データを消してしまうので注意。
学習用データを作る
今回学習させるのはJetsonNano一クラスです。
最初に教育用データを作るためにアノテーションという作業をしていきます。これにはいろいろな方法があり、これが最適解ではないことを理解しておいてください。
yoloが読める形式
まず最初に目標からお話しします。
最終的に得たいファイルはこんな構造です
|-data--------
|-train.txt
|-test.txt
|-obj.names
|-obj.data
|-output---------
|-0.jpg
|-0.txt
|-1.jpg
....
|-923.jpg
|-923.txt
...
output以下について **X.jpgとX.txtは対応していて、X.txtでjpgの中のobjectの位置を示しています。**X.txtは以下のような形式でなくてはならず
0 0.2345 0.373 0.1234 0.298
順に
- class番号
- objectのX中心(比率)
- objectのY中心(比率)
- objectのX方向の大きさ(比率)
- objectのY方向の大きさ(比率)
を表しています。
また複数classの場合
0 0.2345 0.373 0.1234 0.298
3 0.5345 0.673 0.2134 0.148
といった感じになります。
次にtrain.txtとtest.txtはさっきの学習用データの場所をリストしたもので
data/output/0.jpg
data/output/1.jpg
data/output/2.jpg
data/output/3.jpg
data/output/4.jpg
...
data/output/426.jpg
...
となり、test.txtも全く同じ形式となります
補足として、名前の通りtrain.txtは学習のためのデータ、test.txtは評価用のデータを示しています。大体全データの15%ぐらいをtestに割り振るといいでしょう。
最後にobj.dataとobj.namesについて
classname1
classname2
classname3
ここにはクラスの名前を書きます。今回はJetsonを認識させるので
Jetson
となります。
obj.dataには各種ファイルの場所を書きます。
classes = 1
train = data/train.txt
valid = data/test.txt
names = data/obj.names
backup = backup/
基本的にはこれで大丈夫です。
注意してほしいのは必ずUTF-8、LFで作成してください。
イイですか?必ずUTF-8、LFですよ?大事なことなので2回言いました。

メモ帳の下の方がこうなるように作成してください。
ちゃんとやらないとcolab上でYOLOがうまく動作しません
余談
筆者はここで躓きました。
インチヤード法は滅ぼすべきとよく言われていますが、コンピュータの世界ではSHIJIがこれに当たります。わかったら、友達にささやきましょう。
データの作成
では実際に画像のアノテーションを行っていきます。
今回はVOTTというアノテーションツールを使いました。
https://github.com/Microsoft/VoTT/releases
このサイトに
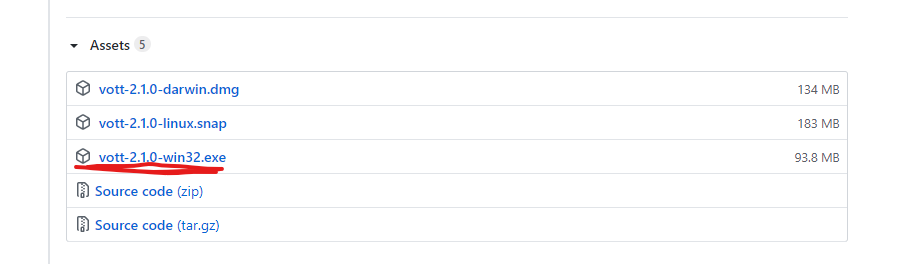
のようなところがあるのでDL&installします。
VOTTの使い方は以下のサイトが参考になります。
https://qiita.com/clerk67/items/8e7207284037dcf1f9ec
上手くアノテーションができたらこんな感じのファイルが生成されているはずです。
これをVScodeで開くと
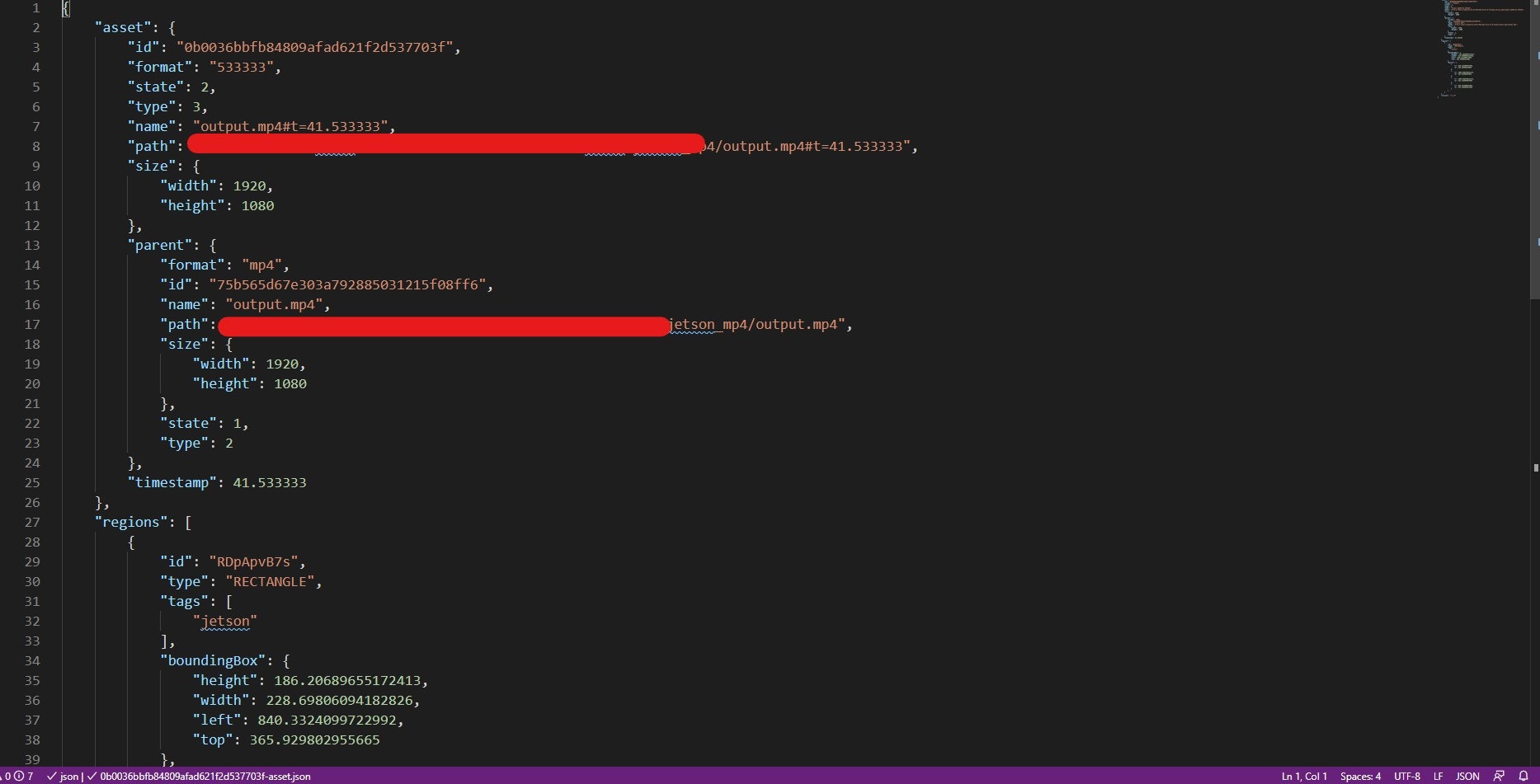
筆者は動画をアノテーションしたので、txtの中身だけではなく画像を動画から抽出しなくてはなりません。
それを含めたpythonコードを書いておきます
import glob
import json
import cv2
file_list = glob.glob("jetson_mp4/*.json")#jsonファイルのファイル名リストを取得
cap = cv2.VideoCapture("jetson_mp4/output.mp4")#動画ファイルの読み込み
name_num = 0
for i in file_list:
print(name_num,i)
name_num = name_num + 1
filename = str(name_num)
json_txt = open(i)
json_load = json.load(json_txt)
width = json_load['asset']['size']['width']
height = json_load['asset']['size']['height']
top_x = json_load['regions'][0]['points'][0]['x']
top_y = json_load['regions'][0]['points'][0]['y']
box_width = json_load['regions'][0]['boundingBox']['width']
box_height = json_load['regions'][0]['boundingBox']['height']
timestamp = json_load['asset']['timestamp']
frame = int(timestamp * 29.97)#ココの数値は動画ファイルのFPSに設定
cap.set(cv2.CAP_PROP_POS_FRAMES,frame)
cv2.imwrite('output/' + filename + '.jpg',cap.read()[1])
cen_x = (top_x + (box_width / 2))/width
cen_y = (top_y + (box_height / 2))/height
ratio_width = box_width / width
ratio_height = box_height / height
txt_con = '0 ' + str(cen_x) + ' ' + str(cen_y) + ' '
txt_con = txt_con + str(ratio_width) + ' ' + str(ratio_height)
with open('output/' + filename + '.txt',mode='w') as f:
f.write(txt_con)
あくまでも参考程度でお願いします
このprocess.pyを
のように配置して実行
上手く動作すればoutputの中に
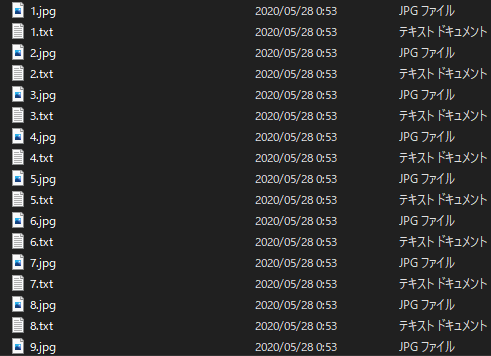
といった感じでtxtとjpgが交互に続いたようになっているはずなので確認してください
次にtrain.txtとtest.txtを生成するためのpythonコードを置いときます。
import glob, os
current_dir = os.path.dirname(os.path.abspath(__file__))
current_dir = current_dir + "/output/"
# Percentage of images to be used for the test set
percentage_test = 15;
file_train = open('train.txt', 'w')
file_test = open('test.txt', 'w')
counter = 1
index_test = round(100 / percentage_test)
for pathAndFilename in glob.iglob(os.path.join(current_dir, "*.jpg")):
title, ext = os.path.splitext(os.path.basename(pathAndFilename))
if counter == index_test:
counter = 1
file_test.write(current_dir + title + '.jpg' + "\n")
else:
file_train.write(current_dir + title + '.jpg' + "\n")
counter = counter + 1
これをprocess.pyと同じ場所に配置、実行はしないでください
実行するのはcolab上で行います
最後に
次回はcolabのセットアップと学習を行っていきます。
https://qiita.com/tayutayufk/items/4dba4087e6f06fec338b