機械学習でオブジェクト検出を行う場合、人物や猫など一般的な物体を検出したいのであれば、Amazon Rekognition や Google Cloud Vision API などのサービスを利用することで、既存の学習済みモデルを使用してすぐに検出を始めることができる。一方で、そういった既存のモデルでは検出できない特殊な物体を検出したい場合などは、最初に人力で教師データを用意しなければならない。この作業を少しでもラクにするためにさまざまなツールが存在しているが、今回は Microsoft が開発している VoTT (Visual Object Tagging Tool) を使用して画像のアノテーション(タグ付け)を行ってみた。
VoTT のインストール
VoTT にはインストール不要の Web 版 (https://vott.z5.web.core.windows.net) も用意されているが、こちらはデータの入出力が Azure Blob Storage または Bing Image Search となっており、PC のローカルに保存されている画像を使用できないため、今回はインストール版を使用する。
インストール版は https://github.com/Microsoft/VoTT/releases からダウンロード可能。今回は v2.1.0 の macOS 版 (vott-2.1.0-darwin.dmg) を選択した。
プロジェクトの作成
VoTT を起動すると以下のような画面が表示されるので、[New Project] を選択する。

[Display Name] に任意のプロジェクト名を入力する。続いて、データの入出力に関する設定を行う。まずは、入力画像の場所を指定するために [Source Connection] の右側にある [Add Connection] をクリックする。
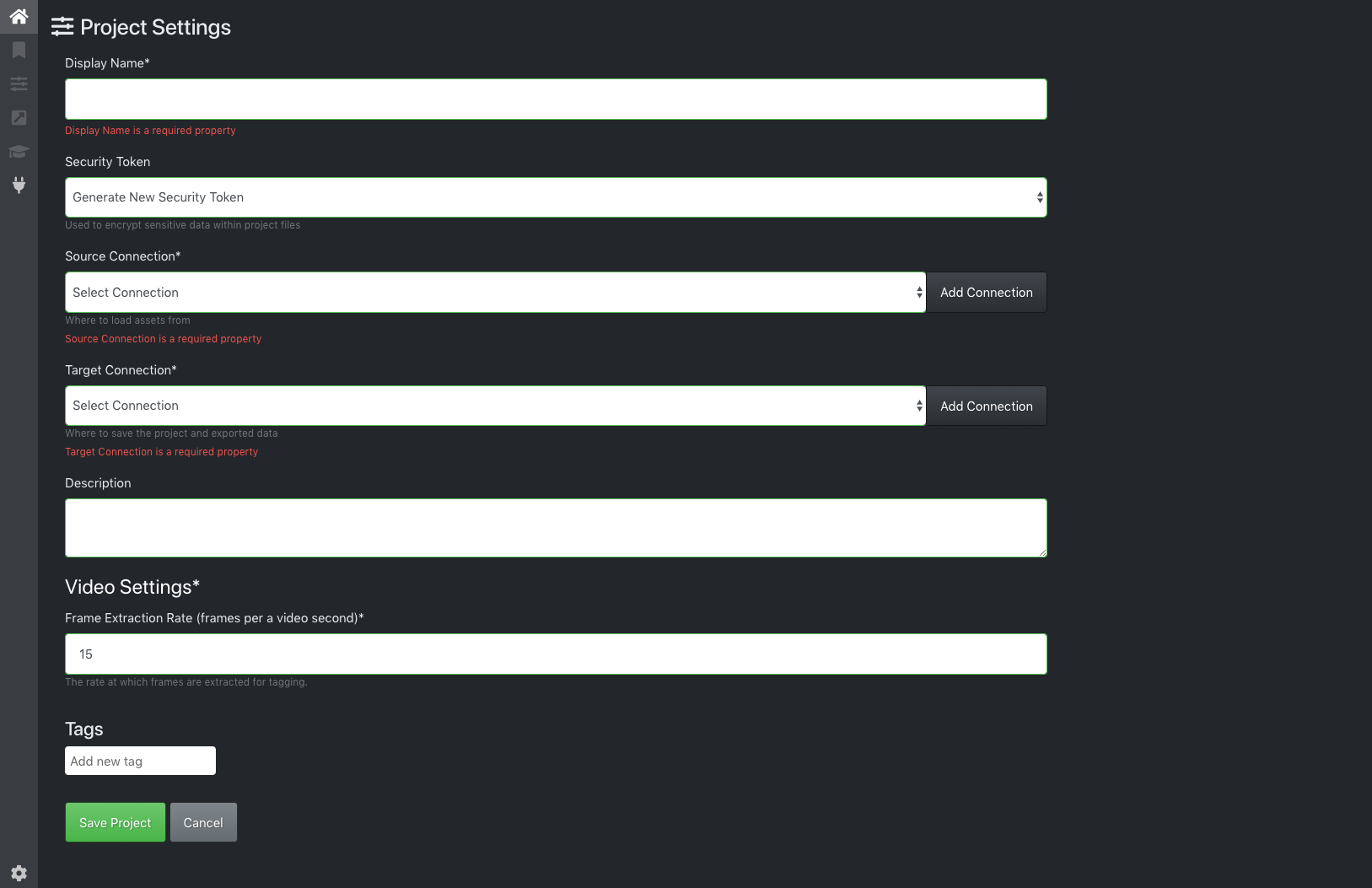
[Display Name] に任意の名前を入力し、[Provier] で Local File System を選択し、[Folder Path] で入力画像が格納されているフォルダを指定する。なお、サブフォルダに格納されている画像は認識されないようなので注意。設定を終えたら [Save Connection] をクリックする。

同様に [Target Connection] でデータの出力先を指定する。アノテーションの情報は画像ごとに JSON 形式のファイルとして出力される。設定を終えたら [Save Project] をクリックする。
アノテーション(タグ付け)
プロジェクトを作成するとアノテーション(タグ付け)を行う画面が表示される。
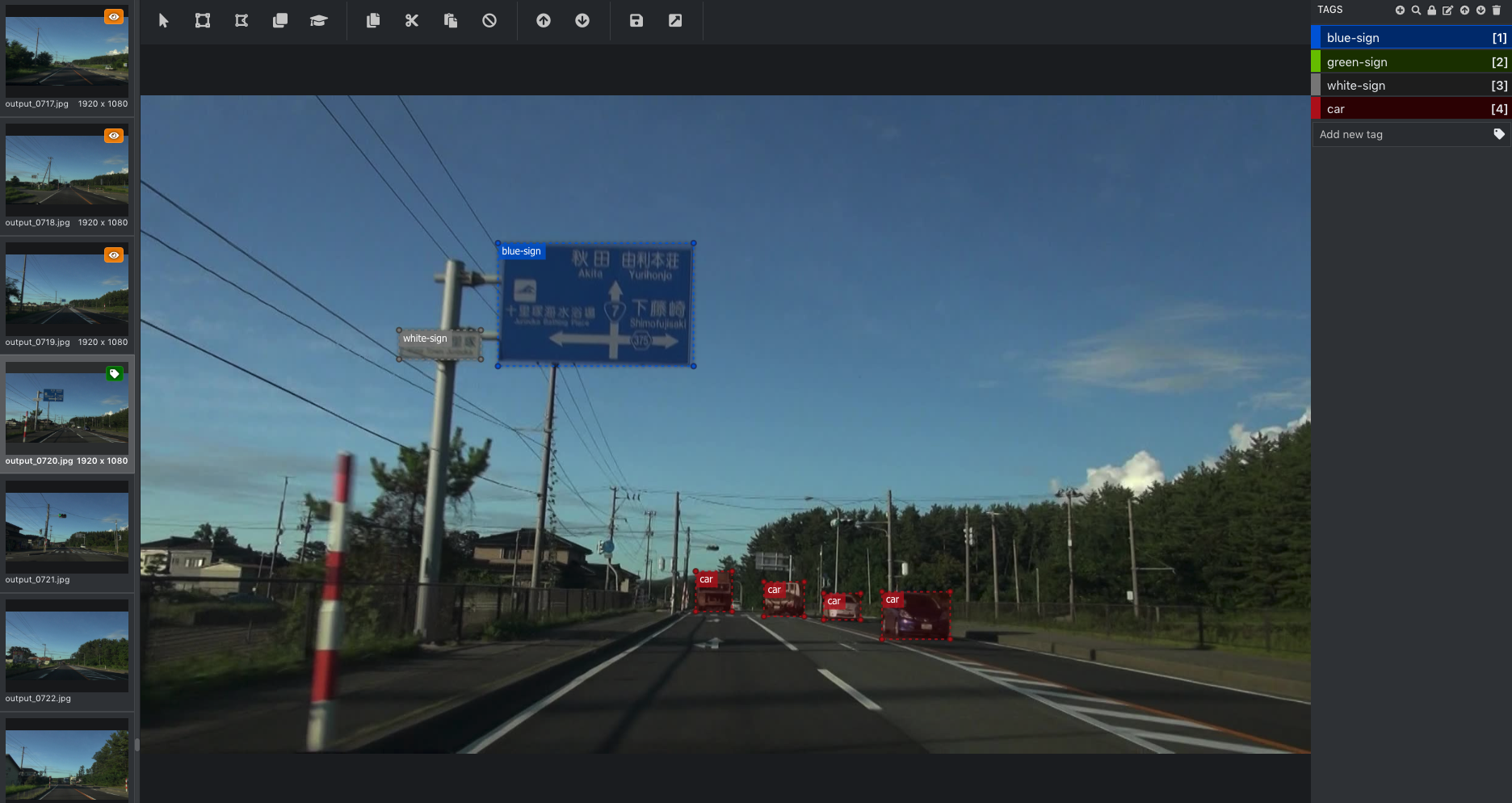
まずは画面右上の [TAGS] の右側にある + マークをクリックしてタグを作成する。次に、画像上をドラッグして範囲を指定したあと、画面右側のタグをクリックすると(またはタグ名の右側に表示されている数字のキーを押すと)、選択した領域に対してタグ付けが行われる。1 つの領域に複数のタグを設定することもできる(どういった状況で使用するのかは不明)。
タグを選択してから [TAGS] の右側にある 鍵(🔒)マークをクリックすると、そのタグ名の右側に 鍵(🔒)マークが表示され、それ以降は画像上をドラッグして範囲を指定するだけで自動的にそのタグが付与されるようになる。また、タグ名をクリックしてから 鉛筆 ボタンをクリックすると、タグ名を編集できる。タグ名の左側にある色の付いた四角い部分をクリックしてから 鉛筆 ボタンをクリックすると、タグの色を変更できる(これが分かりにくい)。なお、タグの色は VoTT における表示にのみ影響し、アノテーションの結果には特に影響しないので、作業中に分かりやすい色を選べばよい。
基本的な作業の流れとしては、キーボードの ↓ キーを押して画像を次々と表示させながら、画像上をドラッグして範囲を指定し、適切なタグを設定するという作業を延々と繰り返すことになる。これは退屈な作業だが、モデルの検出精度を決定付ける重要な作業なので、根気よく続けるしかない(ちなみに Amazon SageMaker Ground Truth を使用すると、この面倒な作業を外部のパブリックチームに委託することもできる)。
出力データの形式
アノテーションを行うと、プロジェクトのデータ出力先に指定したフォルダに次々に JSON ファイルが生成される。これらのファイルは画像ごとに出力され、いずれも以下のような形式となっている。
{
"asset": {
"format": "jpg",
"id": "3d22a9b3f18397dc624a04b4f7b86d66",
"name": "output_0720.jpg",
"path": "file:/Volumes/Video/screenshots/20130826/20130826161633/output_0720.jpg",
"size": { "width": 1920, "height": 1080 },
"state": 2,
"type": 1
},
"regions": [
{
"id": "UIepmXSfA",
"type": "RECTANGLE",
"tags": ["blue-sign"],
"boundingBox": {
"height": 202.00306748466252,
"width": 321.04037267080747,
"left": 586.3250517598342,
"top": 241.0433282208588
},
"points": [
{ "x": 586.3250517598342, "y": 241.0433282208588 },
{ "x": 907.3654244306418, "y": 241.0433282208588 },
{ "x": 907.3654244306418, "y": 443.04639570552143 },
{ "x": 586.3250517598342, "y": 443.04639570552143 }
]
}
],
"version": "2.1.0"
}
regions[].boundingBox に選択した領域の幅と高さ、左上からの距離が記録されており、その領域に対応するタグ名が regions[].tags に記録されていることが分かる。これらのアノテーションの情報を使用して実際にトレーニングを行う場合は、必要に応じてこれをさらに別の形式に変換する。