※2016/5/12追記 公式Tensorflowのレポジトリにマージされたので、この記事は完全にDeprecatedになります。
-> TensorflowでOSXのGPUが対応されたよ
まぁあまりインストールの仕方は変わらないのですが。
※非公式なので何が起きても責任負えません。
自分のMacbook Pro(Retina, 15-inch, Mid 2014)がIntel Iris Proの他にNVIDIA GeForce GT 750Mも積んでいたことを思い出したので、「Cudaで3.0やん。TensorflowのGPUいけるやん」と思い、やり方探してたら海外ですでにやってる人いたので、参考にした時の手順を残します。
ただしver0.6.0に戻ります
bazelとか使うのでpip,Virtualenv,dockerのインストールした人は、まず普通にソースからのインストールした方がよいかも。
※最近のApple製品のほとんどはグラフィックボードがIntelかAMDなので事前に確認してください。
スペック確認は左上の"About This Mac"から"System Report"で見れます。
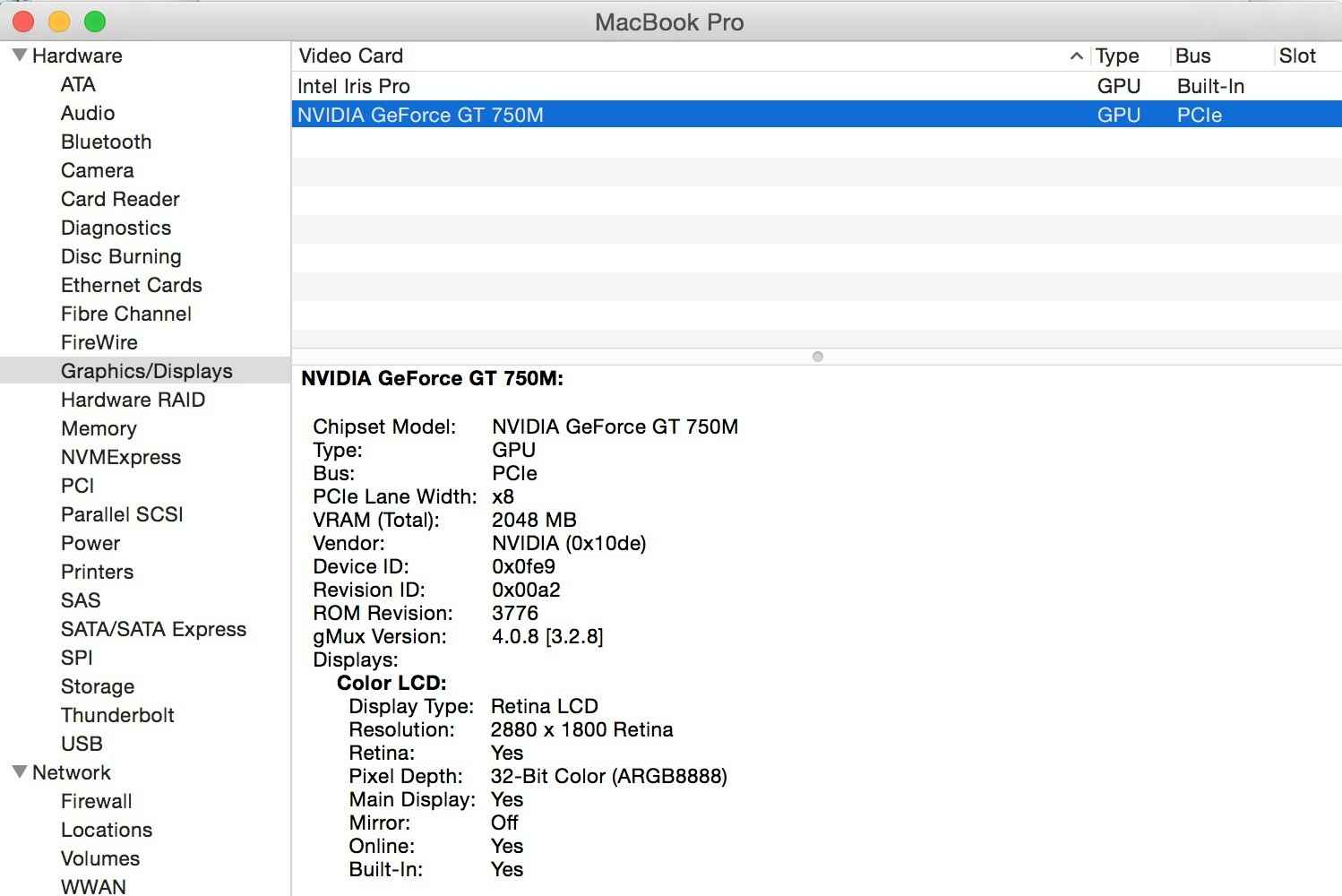
多分いける種類
| 型番 | GPU |
|---|---|
| iMac (21-inch, Late 2012) | NVIDIA GeForce GT 640M |
| iMac (21-inch, Late 2012) | NVIDIA GeForce GT 650M |
| iMac (27-inch, Late 2012) | NVIDIA GeForce GTX 660MX |
| iMac (27-inch, Late 2012) | NVIDIA GeForce GTX 675MX |
| iMac (27-inch, Late 2012) | NVIDIA GeForce GT 680M |
| iMac (21.5-inch, Late 2013) | NVIDIA Geforce GT 750M |
| iMac (27-inch, Late 2013) | NVIDIA Geforce GT 755M |
| iMac (27-inch, Late 2013) | NVIDIA Geforce GTX 775M |
| iMac (27-inch, Late 2013) | NVIDIA Geforce GTX 780M |
| MacBook Pro (15-inch, Mid 2012) MacBook Pro (Mid 2012) MacBook Pro (15-inch, Early 2013) |
NVIDIA GeForce GT 650M |
| MacBook Pro (15-inch, Late 2013) MacBook Pro (15-inch, Mid 2014) |
NVIDIA GeForce GT 750M |
セットアップ
参考元:
Fabrizio Milo @ How to compile tensorflow with CUDA support on OSX
まずはCudaインストール。 私はbrewでしました。
$ brew upgrade
$ brew install coreutils
$ brew cask install cuda
一応バージョン確認 (7.5.20のはず)
$ brew cask info cuda
NVIDIAからライブラリーのlibCudnnをダウンロードする。(要登録)
https://developer.nvidia.com/cudnn.
自分がダウンロードしたバージョンはこれ: cudnn-7.0-osx-x64-v4.0-prod.tgz
ダウンロードしたものの中身をそれぞれ/usr/local/cuda/のlib, includeの対応する場所に移す。
.bash_profileにパスを追記
$ vim ~/.bash_profile
export DYLD_LIBRARY_PATH=/usr/local/cuda/lib:$DYLD_LIBRARY_PATH
TensorflowのレポジトリでOSXでもGPU使えるようにするPull Request#644をもってくる
$ cd tensorflow
$ git fetch origin pull/664/head:cuda_osx
$ git checkout cuda_osx
Tensorflow再インストール
$ TF_UNOFFICIAL_SETTING=1 ./configure
WARNING: You are configuring unofficial settings in TensorFlow. Because some external libraries are not backward compatible, these setting
s are largely untested and unsupported.
Please specify the location of python. [Default is /usr/local/bin/python]:
Do you wish to build TensorFlow with GPU support? [y/N] Y
GPU support will be enabled for TensorFlow
Please specify the Cuda SDK version you want to use. [Default is 7.0]: 7.5
Please specify the location where CUDA 7.5 toolkit is installed. Refer to README.md for more details. [Default is /usr/local/cuda]:
Please specify the Cudnn version you want to use. [Default is 6.5]: 4
Please specify the location where cuDNN 4 library is installed. Refer to README.md for more details. [Default is /usr/local/cuda]:
Please specify a list of comma-separated Cuda compute capabilities you want to build with.
You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus.
Please note that each additional compute capability significantly increases your build time and binary size.
[Default is: "3.5,5.2"]: 3.0
Setting up Cuda include
Setting up Cuda lib
Setting up Cuda bin
Setting up Cuda nvvm
Configuration finished
$ bazel build -c opt --config=cuda //tensorflow/cc:tutorials_example_trainer
$ bazel build -c opt --config=cuda //tensorflow/tools/pip_package:build_pip_package
$ bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
$ pip install /tmp/tensorflow_pkg/tensorflow-自分のtmpにある-whl
import tensorflow as tf
# Creates a graph.
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
# Creates a session with log_device_placement set to True.
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
# Runs the op.
print sess.run(c)
エラーでReason: image not foundと言われたらCudaのライブラリーが見つけられないかららしいので、パスを確認
$ export DYLD_LIBRARY_PATH=/usr/local/cuda/lib:$DYLD_LIBRARY_PATH
これでいけるはず。
試しに"ひらながMAIST"のCNNで処理速度を計測してみよう。
。。。
あれ。

っていうオチまで考えて画像用意してたのに、ちゃんと早くなりました。
CPUだとだいたい52分
i 19900, training accuracy 1 cross_entropy 0.205204
test accuracy 0.943847
elapsed_time:3312.28295398[sec]
i 19900, training accuracy 1 cross_entropy 0.0745807
test accuracy 0.945042
elapsed_time:1274.27083302[sec]
GPUだと21分くらい。
他にいろいろアプリケーションが動いていたりすると実行の際に出てくるログのFree memory:部分でGPUメモリがかなり少なかったりします。
あまりにも少ないとメモリ不足でエラーになるという。 ノートパソコンなので致し方ないですね。
アプリ落としたり再起動するなりで回復するので、まぁその辺は適当に。