掲示板に使えそうなの出来ました。
時間確認は4年に1度のイベントとなります。
ご参加頂ければ、有難くおもいます。
簡単な、キャプチャーに続ぎ、scriptの紹介を致します。
最後まで、お楽しみ頂ければ、幸せにおもいます。
構成
・エラー処理
・時間
・受信
・デコードとハッシュ代入
・URL変換
・ファイル書き込み
・html書き出し
・Fileからの書き出し
大体そのようになっています。
では、キャプチャー
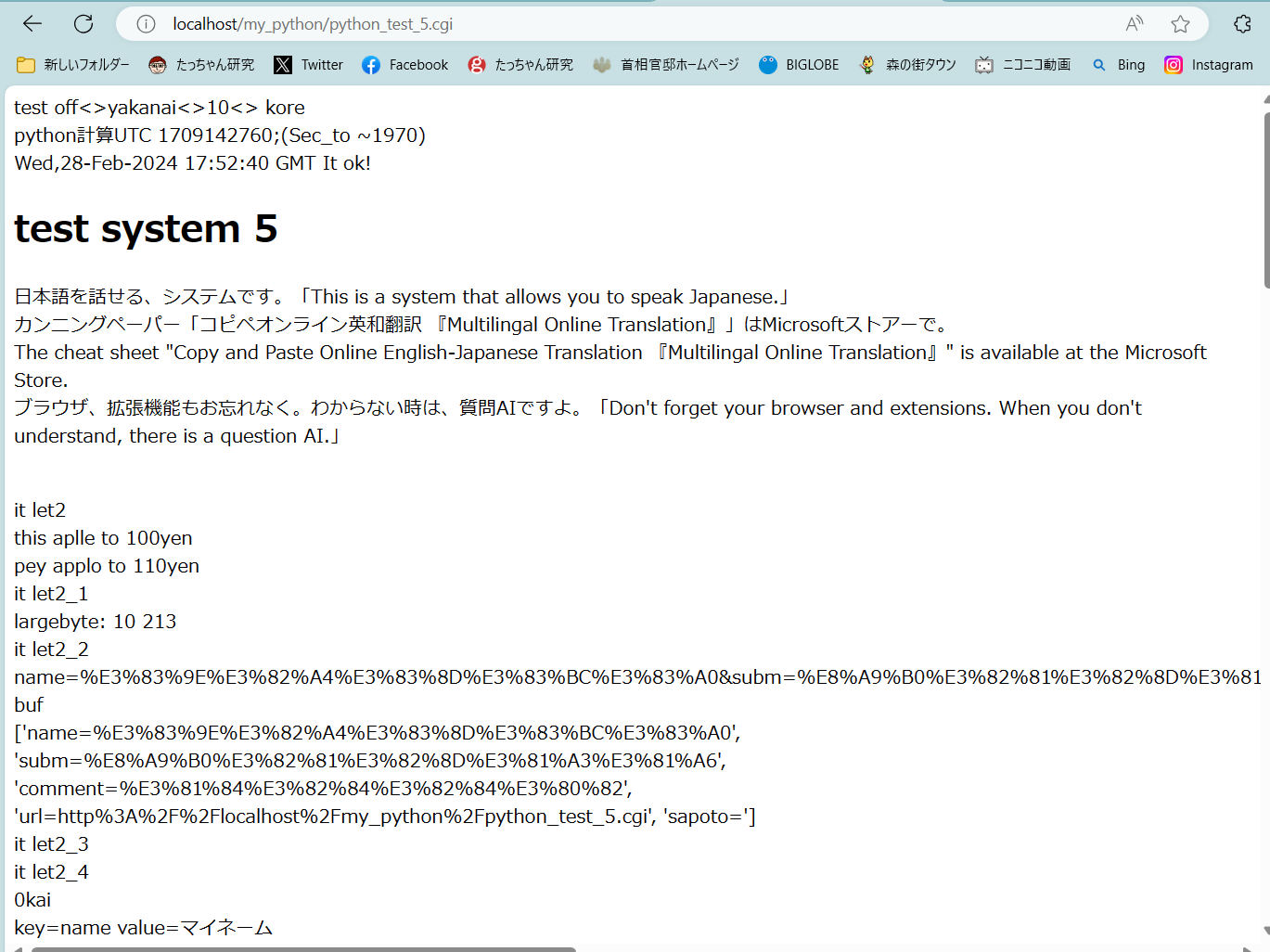
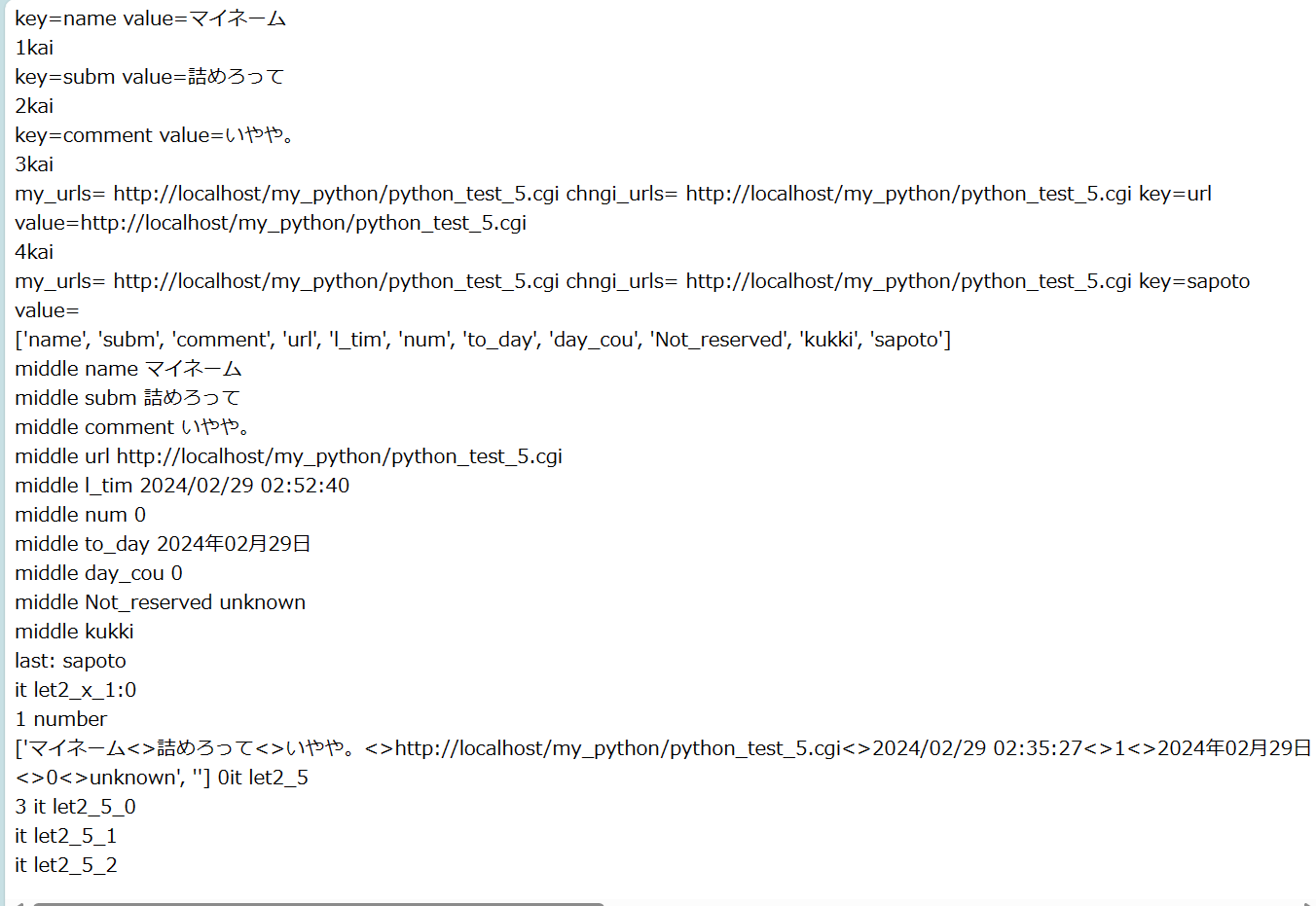



スクリプト
#!C:/Python/python -X utf8
# coding=utf-8
## note 2024/02/28
##################################################################################
## #!C:/Python3/python_3_12_0_embed_amd64/python -X utf8 adores un matcing.
## ok #!C:/Python/python ok no -X utf8 It to python.exe adoress.
## fail python_test_5.cgi adoress C:\xampp\htdocs\my_python\
## cooding tattyan Qiita tattyan3 No.ling 2024/02/28 to
##################################################################################
script_adoress = "http://localhost/my_python/python_test_5.cgi"
memore_line = 10
point_err = bool(1)
point_return = bool(0)
settig_msgA = 'NO Settig.'
settig_msgB = 'NO Settig.'
error_detail = 'No Error.'
def my_error(error_detail):
if point_err:
print ("Content-type:text/html\n\n")
print ('<!DOCTYPE html><html lang=\"ja\"><head><meta charset=\"UTF-8\"><title>omikuji Error</title></head><body>')
print ('<h1>エラー発生(An error has occurred.)</h1>')
if point_err:
print('type on; ')
else:
print('type off; ')
if point_return:
print('return on;')
else:
print('return off;')
print ('<h2>detail :'+error_detail+'</h2><div style=\"background-color: #000066;color: #cccccc;font-size: 12px;margin: 3px;padding: 3px;\">'+settig_msgA+'</div><div style=\"background-color: #006600;color: #cccccc;font-size: 12px;margin: 3px;padding: 3px;\">'+settig_msgB+'</div><br>')
if point_return:
return
print ('</body></html>\n')
exit()
# my_error('オープン前エラー Occurrence before opening <b>test.</b>')
import os
kukki_yaki_in = ['off<>yakanai<>10<>']
kukki_yaki = 0
result_c = bool(0)
if os.path.exists('cukki_yaku.txt'):
with open('cukki_yaku.txt', 'r') as f:
kukki_yaki_in = f.readlines()
else:
with open('cukki_yaku.txt', 'w') as f:
for item in kukki_yaki_in:
f.write(f"{item}\n")
print ('Content-type:text/html'+'\n'+'\n')
print ('<!DOCTYPE html><html lang=\"ja\"><head><meta charset=\"UTF-8\"><title>pyton_v5</title></head><BODY BGCOLOR=\"#ffffff\">\n')
point_err = bool(0) #error ヘッダー off
point_return = bool(1) #error リターン on
if kukki_yaki_in:
print ('test '+kukki_yaki_in[0]+' kore\n')
# result_c = bool(re.search(r'yakanai', kukki_yaki_in[0]))
# if result_c:
kukki_yaki = 0
# else:
# kukki_yaki = 1
import datetime
now = datetime.datetime.now()
#my_date = now.strftime("%Y/%m/%d %H:%M:%S")
my_year = int(now.strftime("%Y"))-1970
my_month = int(now.strftime("%m"))-1
my_day = int(now.strftime("%d"))-1
my_hour =int(now.strftime("%H"))
my_minute = int(now.strftime("%M"))
my_second = int(now.strftime("%S"))
def_moon_days = [0, 31, 59, 90, 120, 151, 181, 212, 243, 273, 304, 334]
def_moon_days4 = [0, 31, 60, 91, 121, 152, 182, 213, 244, 274, 305, 335]
if my_year%4 == 0:
my_moon_days = def_moon_days4[my_month]
else:
my_moon_days = def_moon_days[my_month]
epoch_tokyo = 9
my_year2 = int(my_year/4)
epoch_0 = my_year*365*24*60*60 + (my_moon_days + my_day+my_year2)*24*60*60 + (my_hour - epoch_tokyo)*60*60 + my_minute*60 + my_second
print('<br>python計算UTC '+str(epoch_0)+';(Sec_to ~1970)<br>\n')
from datetime import datetime, timezone, timedelta
gmt = datetime.now(timezone.utc)
cookie = f"{gmt + timedelta(days=30):%a,%d-%b-%Y %H:%M:%S} GMT"
cookie = f"{gmt + timedelta(days=0):%a,%d-%b-%Y %H:%M:%S} GMT"+" It ok!"
print(cookie)
print('<br>\n')
# print ('Content-type:text/html'+'\n'+'\n')
print ('<h1>test system 5</h1>'+'\n')
print ('<p>日本語を話せる、システムです。「This is a system that allows you to speak Japanese.」<br>\n')
print ('カンニングペーパー「コピペオンライン英和翻訳 『Multilingal Online Translation』」はMicrosoftストアーで。<br>\n')
print ('The cheat sheet \"Copy and Paste Online English-Japanese Translation 『Multilingal Online Translation』\" is available at the Microsoft Store.<br>\n')
print ('ブラウザ、拡張機能もお忘れなく。わからない時は、質問AIですよ。「Don\'t forget your browser and extensions. When you don\'t understand, there is a question AI.」</p><br>\n')
# import re
import datetime
now = datetime.datetime.now()
formatted_date = now.strftime("%Y/%m/%d %H:%M:%S")
it_day = now.strftime("%Y年%m月%d日")
it_time = now.strftime("%H時%M分%S秒")
# mydisp = re.sub(r'\x','%', 'abcIt let1def<br>\n')
# print (mydisp)
#decode()
#def decode():
my_hash = {}
#my_hkey_list0 = list(my_hash.keys())
my_hash['name'] = ''
my_hash['subm'] = ''
my_hash['comment'] = ''
my_hash['url'] = ''
my_url = ''
my_hash['l_tim'] = formatted_date
my_hash['num'] = '0'
my_hash['to_day'] = it_day
my_hash['day_cou'] = '0'
my_hash['Not_reserved'] = 'unknown'
my_hash['kukki'] = ''
come = ''
my_hash['sapoto'] = ''
data_file_name = 'file.txt'
in_d = {}
in_d['apple'] = '100'
in_d['banana'] = '150'
in_d['cherry'] = '200'
print ('it let2<br>\n')
print ('this aplle to '+in_d['apple']+'yen<br>\n')
in_d['apple'] = '110'
print ('pey applo to '+in_d['apple']+'yen<br>\n')
file_path_xlsx = r"C:\Users\UserName\Documents\Example.xlsx"
#人気者やなぁ
import cgi
text = []
# f = open('python_test2.txt', 'r')
#自分開いていると読み込めないcgiは、サーバーが実行する
# for line in f:
# text.append(line)
# print(line)
# f.close()
#print(<a href=\"http://127.0.0.1/my_python/python_test3.html\" target=\"~_blank\">pythonのソースファイル</a><br>\n')
#print('Content-Type: text/plain\n\n')
#print(text)
#print("")
#print('<br><a href=\"http\">なにか</a><br>\n')
#return
# import os 移動
import re
import sys
req_met = os.environ.get('REQUEST_METHOD')
print ('it let2_1<br>\n')
if req_met == 'POST' :
for query in sys.stdin:
os.environ.get('CONTENT_LENGTH')
pass
else :
query = os.environ.get('QUERY_STRING')
if len(query) > 0 and req_met != 'POST':
tmp_q_m = '<br><b>not post.</b>:'+str(len(query))+'<br>query:'+query
print (tmp_q_m+'<br>\n')
if len(query) > 10 :
language = len(query)
print (f'largebyte: 10 {language}<br>\n') #test message after get out;F(x)Qestit??
print ('it let2_2<br>\n')
print (query+' buf <br>\n')
buf_arrey = query.split("&")
print (buf_arrey)
print ('<br>\n')
print ('it let2_3<br>\n')
separator = '<br>'
#tmp_arrey = separator.join(buf_arrey)
#print (tmp_arrey)
#print ('<br>\n')
key_myh = list(my_hash.keys())
import urllib.parse
key0=''
value0=''
n_n = 0
print ('it let2_4<br>\n')
if "" not in buf_arrey :
for my_buf in buf_arrey :
print (f'{n_n}kai<br>\n')
mytem_buf = my_buf
mytem_buf += '='
key_val_arry = mytem_buf.split("=")
key0 = key_val_arry[0]
value0 =key_val_arry[1]
# if "%" in key0 :
# key0 = re.sub(r'%([0-9a-fA-F][0-9a-fA-F])', lambda x: chr(int(x.group(1), 16)), key0)
key0 = urllib.parse.unquote(key0)
key0 = re.sub(r'\+', ' ', key0)
key0 = re.sub(r'&', '&', key0)
key0 = re.sub(r'<', '<', key0)
key0 = re.sub(r'>', '>', key0)
key0 = re.sub(r'\r\n', '<br>', key0)
key0 = re.sub(r'\r|\n', '<br>', key0)
my_key = key0
# value0 = re.sub(r'%([0-9a-fA-F][0-9a-fA-F])', lambda x: chr(int(x.group(1), 16)), value0)
value0 = urllib.parse.unquote(value0)
value0 = re.sub(r'\+', ' ', value0)
value0 = re.sub(r'&', '&', value0)
value0 = re.sub(r'<', '<', value0)
value0 = re.sub(r'>', '>', value0)
value0 = re.sub(r'\r\n', '<br>', value0)
value0 = re.sub(r'\r|\n', '<br>', value0)
my_val = value0
if my_key == 'comment':
value0 = re.sub(r'<br>', '\n', value0)
come = value0
key_c=0
for key_myh_s in key_myh:
if key0 == key_myh_s:
key_c=1
if key_c==0:
if "" is not my_val:
my_val = ''
# my_error('bad item.')
#I can't get around to it, so I'll try putting it out.
my_hash[my_key] = my_val
if my_hash['url']:
print("my_urls=",my_hash['url'])
my_url = re.sub(r'(https?://\S+|\.|!"|!\n+)',"<a href=\"\\1\">\\1</a>", my_hash['url'])
print("chngi_urls=",my_hash['url'])
n_n += 1
print (f'key={my_key} value={my_val}<br>\n')
# cookieの書き込み設定
if my_hash['kukki'] == 'on' or my_hash['kukki'] == 'off':
if my_hash['kukki'] == 'on':
kukki_yaki_in[0] = 'on<>yaku<>10<>'
else:
kukki_yaki_in[0] = 'off<>yakanai<>10<>'
with open('cukki_yaku.txt', 'w') as f:
for item in kukki_yaki_in:
f.write(f"{item}\n")
key_list0 = list(my_hash.keys())
print(key_list0)
print ('<br>\n')
for i, val0 in enumerate(key_list0):
if i == len(key_list0) - 1:
print('last: '+val0+' '+my_hash[val0]+'<br>\n')
else:
print('middle '+val0+' '+my_hash[val0]+'<br>\n')
print ('it let2_x_1:'+my_hash['num']+'<br>\n')
if my_hash['num'] == '' :
my_hash['num'] = '0'
number = int(my_hash['num']) + 1
my_hash['num'] = str(number)
my_list = my_hash['name']+'<>'+my_hash['subm']+'<>'+my_hash['comment']+'<>'+my_hash['url']+'<>'+my_hash['l_tim']+'<>'+my_hash['num']+'<>'+my_hash['to_day']+'<>'+my_hash['day_cou']+'<>'+my_hash['Not_reserved']
my_list_arrey = []
if os.path.exists(data_file_name):
#fileがあれば読み込む
with open(data_file_name, 'r') as f:
tmp_list_in = f.readlines()
#f = open(data_file_name, 'r')
#for line in f:
# tmp_list_in.append(line)
# print(line)
#f.close()
if tmp_list_in:
result1 = bool(re.search(r'&wl_1;', tmp_list_in[0]))
if result1:
arrey_arrey = tmp_list_in[0].split("&wl_1;")
tmp_list_in[0] = arrey_arrey[0]
result0 = bool(re.search(r'&wl_0;', tmp_list_in[0]))
if result0:
my_list_arrey = tmp_list_in[0].split("&wl_0;")
my_bool1=bool(1)
n=0
for tmp_i in my_list_arrey:
tmp_i = re.sub(r'&', '&', tmp_i)
my_list_arrey[n] = tmp_i
if my_bool1:
tmp_li0_sp_arr= my_list_arrey[0].split("<>")
tmp_nm = tmp_li0_sp_arr[5]
print(tmp_nm+' number <br>')
if not tmp_nm.isnumeric():
tmp_nm ='0'
number = int(tmp_nm)
number += 1
# number = '{0.0}'.format(tmp_li0_sp_arr[5]) + 1.0
my_hash['num'] = str(number)
my_bool1=bool(0)
n += 1
#else:
#わたしの書式のファイルでないとき
#エラー関数を呼び出し終わる。書き換えるわけにいかんだろう。
else:
#空のファイルの時または、消えた時
my_hash['num'] = '100'
my_list_arrey=[my_list]
new_my_list_arrey= []
my_list = my_hash['name']+'<>'+my_hash['subm']+'<>'+my_hash['comment']+'<>'+my_hash['url']+'<>'+my_hash['l_tim']+'<>'+my_hash['num']+'<>'+my_hash['to_day']+'<>'+my_hash['day_cou']+'<>'+my_hash['Not_reserved']
wit_flg = 0
print (my_list_arrey,'0it let2_5<br>\n')#空の要素1[0]=""が無いとか。
#name,subm,come,url,
if my_hash['comment'] != "":
wit_flg = 1
if len(my_list_arrey) == 0:
my_list_arrey.append(my_list)
else:
if my_list_arrey[0] == my_list:
wit_flg = 0
else:
new_my_list_arrey.append(my_list)
for my_my_lis in my_list_arrey:
new_my_list_arrey.append(my_my_lis)
my_list_arrey = my_list_arrey[:0]
for my_my_li in new_my_list_arrey:
my_list_arrey.append(my_my_li)
print (len(my_list_arrey),'it let2_5_0<br>\n')
my_listem = ''
if my_hash['comment'] == "":
wit_flg = 0
if len(my_list_arrey) > 0 and my_list_arrey[0]:
my_listem = my_list_arrey[0]
else:
my_listem = my_list
l_dat = my_listem.split("<>")
my_hash['name'] = l_dat[0]
my_hash['url'] = l_dat[3]
print ('it let2_5_1<br>\n')
if len(my_list_arrey) > memore_line:
my_list_arrey = my_list_arrey[:memore_line]
print ('it let2_5_2<br>\n')
my_error('0'+my_hash['sapoto'])
print(my_hash['subm'],'!=',my_hash['sapoto'],'<br>\n')
# my_error('1?'+str(wit_flg))
if my_hash['subm'] != "":
print('何か入ってる')
else:
print('何もない')
print('<br>')
if my_hash['subm'] != "" and my_hash['subm'] != my_hash['sapoto']:
wit_flg = 1
else:
wit_flg = 0
if my_hash['sapoto'] == my_hash['subm']:
wit_flg = 0
my_error('1 str '+str(wit_flg))
if wit_flg ==1:
# my_list_arrey=[my_list,my_list] #わざわざ2個にして、テストしていた要らんわ。
n=0
for tmp_i in my_list_arrey:
tmp_i = re.sub(r'&', '&', tmp_i)
my_list_arrey[n] = tmp_i
n += 1
with open(data_file_name, 'w') as f:
for item in my_list_arrey:
f.write('%s&wl_0;' % item)
#区切りマークとしてwl_0を書いている
f.write("&wl_1;")
#区切りマークとしてwl_1を書いている
#for joint &wl_1;'arrey1["<><br><>"&wl_0"<>&(amp;)lt;&(amp;)gt;<>"&wl_0"<><><>"] &wl_1 arrey2 ..' \n (1 line)inarrey(\n=><br>)
for item in my_list_arrey:
f.write('%s&wl_0;' % item)
f.write("&wl_1;")
#ファイルの書き込みすべて終わるとクローズ
f.write("\n")
#書き込み終わり1個のを2回 test書き込み1回で良いのをわざわさ2変数行けますよって...
print ('it let2_6<br>\n')
# chng"%s\n; =>"%s&wl;"ここの \n 細工して最後に入れれは 配列 in 配列 だわ&wl_n_m;とか この場合\n='<br>'に変えられているが。
print('<br><br>\n')
print("現在の日付と時刻: ", now)
print('<br>'+formatted_date+' Japanise style. きょうは、'+it_day+'で時計は'+it_time+'<br>\n')
# def validate_buf(query):
# pattern = r"\x"
# if len(query) != len(re.findall(pattern, query)):
# print('buf is \\x include.<br>\n')
print ('it let2_7<br>\n')
#form()
#
#def form():
print ('it let3<br>\n')
my_url_script = os.environ.get('SCRIPT_NAME')
# my_url_script is bad item.
print ('これをComment欄に貼り付けでご利用してください。\"%E6%97%A5%E6%9C%AC%E8%AA%9E%E9%9D%9E%E5%AF%BE%E5%BF%9C\"<br>\n')
#print ('<form action=\"'+script_adoress+'\" method=\"GET\">\n')
print ('<form action=\"'+script_adoress+'\" method=\"POST\">\n')
print ('<table border=0 cellspacing=1>\n')
#in_d['name'] = ''
print ('<tr><td><b>name</b></td><td><input type=text name=name size=28 value=\"'+my_hash['name']+'\" maxlength=\"12\" class=f></td></tr>\n')
#in_d['subm'] = ''
print ('<tr><td><b>submit</b></td><td><input type=text name=subm size=100 value=\"'+my_hash['subm']+'\" maxlength=\"100\"class=f></td></tr>'+'\n')
#in_d['comment'] = ''
print ('<tr><td colspan=2><b>comment</b><br><textarea cols=70 rows=7 name=comment wrap=\"soft\" class=f>'+come+'</textarea></td></tr>'+'\n')
#in_d['url'] = ''
print ('<tr><td><b>url</b></td><td><input type=text size=52 name=url value=\"'+my_hash['url']+'\" class=f><br>'+my_url+'</td></tr>'+'\n')
my_hash['sapoto'] = my_hash['subm']
print ('<tr><td><input type="hidden" name="sapoto" value="'+my_hash['sapoto']+'"><input type=submit value=\"submit\"></td><td><input type=reset value=\"reset\"></td></tr>\n')
# <input type="hidden" name="sapoto" value="'+my_hash['sapoto']+'">
print ('</form></table><br>\n')
#come = ''
print ('name='+my_hash['name']+'<br>subm:'+my_hash['subm']+'<br>'+my_hash['comment']+'<br><font color="#ff00ff"><b>It OK?</b></font><br>\n')
print (my_list_arrey)
print ('<br>\n')
loop0 = 0
for my_line in my_list_arrey:
in_name=''
in_subm=''
in_come=''
in_url=''
in_time=''
myli_arr = my_line.split("<>")
tmp_bod_line=len(myli_arr)
if tmp_bod_line < 9:
print(my_line)
s_tmp_bod_line = str(tmp_bod_line)
print (' it smoll line.'+s_tmp_bod_line+'<br>\n')
else:
in_name = myli_arr[0]
in_subm = myli_arr[1]
in_come = myli_arr[2]
in_come = re.sub(r'````?`?`?`?`?`?`?', '```', in_come)
in_valle_arrey = in_come.split('```')
new_in_valle = []
n = 0
for out_v in in_valle_arrey:
if n % 2 == 0:
out_v = re.sub(r'&','&',out_v)
out_v = re.sub(r'>','>',out_v)
out_v = re.sub(r'<','<',out_v)
new_in_valle.append(out_v)
n += 1
separator = '```'
in_come = separator.join(new_in_valle)
in_url = myli_arr[3]
in_time = myli_arr[4]
in_nomber = myli_arr[5]
#numberは書き込まれていてfor内では変わることがない。入っている値をだす。
in_to_d = myli_arr[6]
in_da_co= myli_arr[7]
#in_unno = myli_arr[8]
if wit_flg == 1 and loop0 == 0:
print('<br>name:'+in_name+' Title:<font color=\"#0000ff\"><b>'+in_subm+' </b></font>:is '+in_time+'<br><b>Coment</b> '+in_nomber+'<br>'+in_come+'<br><font color=\"#ff0000\"><b>End</b></font><br>\n')
elif loop0 != 0 or my_hash['sapoto'] == "":
print('<br>name:'+in_name+' Title:<font color=\"#0000ff\"><b>'+in_subm+' </b></font>:is '+in_time+'<br><b>Coment</b> '+in_nomber+'<br>'+in_come+'<br><font color=\"#ff0000\"><b>End</b></font><br>\n')
loop0 += 1
myli_arr = myli_arr[:0]
#return
#
key_list = list(in_d.keys())
print(key_list)
print ('<br>\n')
for i, val in enumerate(key_list):
if i == len(key_list) - 1:
print('last: '+val+' '+in_d[val]+'<br>\n')
else:
print('middle '+val+' '+in_d[val]+'<br>\n')
print ('<br><a href="python_html.html">index</a><br>\n')
my_error('all オーライ.all end!!')
print ('</body></html>\n')
exit()
ありがとう。