1.背景
君たちは以下の画像をみて、流れが分かるのだろうか....?
残念ながら私は全く意味が分からない。
これから私は調べて〇〇でした!今後の活躍に期待したいですね!というくそブログみたいな内容を描くので、基礎の基礎は理解できてるけど、基礎が理解できてないM1になっても未だにひよっこな人は目を通してくれると嬉しく感じる。
引用:https://www.frontiersin.org/journals/nutrition/articles/10.3389/fnut.2023.1247075/full

2.深層学習について
まず第一に深層学習についてどやりながらしゃべれるのか?という質問に対し、私はNOと答えるのでまず第一に深層学習について知ることが重要だと考えた。
下記の動画を閲覧してまとめる。
ぶっちゃけこの動画より下記のURLのサイトの方が分かりやすいまでもある
2.1 ニューラルネットワークとは
非常に分かりやすい画像があったので、下記の画像を引用する。

これを見ていただければ大まかなニューラルネットワークの仕組みや起源を知った気になるだろう。私はなっている。
より一般的なニューラルネットワークの仕組みとしては下記の通りとなっている。
引用:https://www.tel.co.jp/museum/magazine/communication/160229_report01_02/03.html

2.2 隠れ層について
入力層や出力層に関してはある程度の処理の想像はできるだろう。しかし、隠れ層に関してはよくわからない部分である。
下記は上の動画のスクリーンショットである。
白の9という数字の隣に様々なカラーリングで描かれている9があるだろう。 この9の一つ一つの色とその列にある丸いものに注目してほしい。 これはピンクの一部分が一つ目、黄色の部分が二つ目、三つ目.....とその丸に代入されているものと考えてほしい。 かなり端折って書いたので是非とも丁寧で分かりやすい動画の閲覧を推奨したい。(4:00~7:45)

2.3 ニューラルネットワークの重み付けに関して
概要としては下記URLのみで完成されていると思う。

上記のURLにて重み付けの手法の具体例が書いてあり、一部を引用する
例の重み付けはニューラルネットワークの訓練では一般的なバリエーションであり,訓練データの異なる例に異なる重要性が与えらるというものである.簡単に言うと,これは各例の損失にその例に関連付けられた重みを掛け,NetTrainで実行される最適化プロセスでそれに高いもしくは低い重要性を与えることで達成できる.は?意味が分からん。 ということで、計算手法はこんなもんなんだな~とURLを参考にしながら学んでもらうとしてこの文章の意味を分かりやすく伝えるだけ伝えたいと考える。
-
例の重み付け
調べたところ分かりませんでした!のが結論である。これに関しては翻訳ミスなのではないかと思われる。
ChatGPTに聞いたところ「サンプルの重み付け」「クラスの重み付け」が正しいのではないかということである。確かにこの訳だと意味が通る。 -
損失(Loss)
損失(Loss)は、ニューラルネットワークが訓練データに対してどれくらい予測を誤ったかを測る指標である。URL内容に書いてある手法に関してはこれのことが該当するのではないかと考えられる。
実際にモデルの予測結果と実際のラベルとの誤差が大きければ大きいほど損失は大きくなり、誤差が小さければ損失も小さくなる。損失は、モデルの性能を評価し、訓練の最適化アルゴリズム(例えば勾配降下法)で使用される。
より具体的に例の重み付けと損失の関係を見るとするならば、
各例に対する損失に、その例に関連付けられた重みを掛けることで、異なる例が最適化に与える影響を調整する。重みが大きい例はより強い影響を与え、重みが小さい例は影響が少なくなる。
勾配降下法について出てきたが今回は割愛する
https://www.ibm.com/jp-ja/topics/gradient-descent -
NetTrain
NetTrainは、ニューラルネットワークを訓練する方法を指す。これは、損失関数を最小化するように、ネットワークのパラメータ(重みやバイアス)を調整するステップである。
具体的な訓練の流れは次のようになる
1.初期化
ネットワークのパラメータ(重み)がランダムに初期化される。
2.フォワードパス
入力データをネットワークに通し、出力を計算する。
3.損失の計算
出力と正解ラベルの差異から損失を計算する。
4.バックプロパゲーション
損失を最小化するために、勾配降下法などのアルゴリズムを用いて、パラメータの勾配を計算し、重みを更する。
以上を繰り返す
2.4 畳み込み層について
基礎的な内容だと下記URL
少し実践的な内容を交えると下記URLが参考になる。
以上は簡単な読み物となっているので是非とも目を通していただきたい。
こちらは具体的な内容となっているが読むのが億劫だと感じる人もいそうなため、読むのを控えても構わない気もするが面白い内容となっているので共有させていただく。
しかし、私がパッと見たいものが何点かあるためそこをまとめていこうと思う。
様々な読み物を通して深さ32というものがはっきり理解できなかった。深さ32の畳み込み層は32枚の画像があるっていうイメージを持ってしまうほどである。
そこでChatGPTに聞いてみたところ
「深さ32」というのは、畳み込み層がデータを処理した結果、32種類の異なる情報(特徴)を持っている、ということです。これは「画像が32個ある」という意味ではなく、1枚の画像を分析して、32種類の特徴を取り出しているというイメージです。特徴とは、例えば形やパターンなど、画像から抽出されるさまざまな情報のことです。 ですので、「32」という数字は、色ではなく、ネットワークが画像から抽出する情報の種類や数を示していると考えてください。
という何とも機械の分際でえらそうな回答を得た。
こちらには書いてないが チャンネル数が32という形でも言うそうだ。
また、一層につき深さ32、また次の深さを変えることはできないのか???
私は畳み込み層の学習モデルは上記に数枚添付している画像のようなものを想像していたのに...と思った
ここでchatgptに 「これは層を変えるごとに逐一深さを変えなければならないのか」 と聞いてみたところ
そうです、各層のチャンネル数(深さ)は逐一設計者が決める必要があります。ネットワークの設計段階で、どの層にどのくらいのチャンネル数を使うかは、タスクに応じて試行錯誤する部分です。例えば、画像分類のタスクであれば、初めの層では簡単な特徴(エッジや色)を捉えるために少ないチャンネル数(例えば32)を使い、後の層に進むにつれてより複雑なパターン(形状やオブジェクト)を捉えるために**チャンネル数を増やす(64や128など)**のが一般的な戦略です。
このように、どの層でどれだけのチャンネル数を使うかは、モデルの目的や計算リソースに応じて調整します。
以上のように回答を得られた。
2.5 活性化関数について
こちらもURLのみでまとめる
3.画像解説
3.1 一枚目について
一枚目のフロー図はVGG16 ネットワークを書いた図式である。
VGGの解説を行っているともう終わらない気もするので、参考になるURLを下記に貼る。
https://qiita.com/ttomomasa/items/b673a1e0b42a2a14a9d2
以上の画像を見て私が分からない単語についてまとめる。
-
conv3-32
conv3: これは「3×3の畳み込みフィルタ (convolution)」を意味している。畳み込みフィルタは画像の特定の特徴(エッジやテクスチャなど)を抽出する役割を果たし、3×3というのはフィルタのサイズである。この場合、3ピクセル×3ピクセルの領域を1つのフィルタがカバーしています。
**32**: 32という数字は、畳み込み層のフィルタ(カーネル)の数を示しています。つまり、32個の異なるフィルタを用いて、32個の特徴マップが生成されることを意味します。 まとめると、「conv3-32」は「3×3のサイズの畳み込みフィルタを32個持つ畳み込み層」を指しています。

-
Max-Pool

最小値=黒/最大値=白
右画像は大きさ[2 x 2]のカーネルで,ストライド幅=2画素の例である。
最大プーリング層(Max-Pool)では,入力の特徴マップ上の各チャンネルkにおいて(左),チャンネルごとに独立に,カーネル窓のスライディングウィンドウによって,各位置(x,y)の局所カーネル内の最大値を抽出する。
出力のチャンネルkの画像の位置(i,j)に対応する,カーネル(= 図1の黄,緑,赤,青の範囲)の中において,それぞれ最大値(ピンク)のみを出力する。
つまり一言でいうと[2×2]の画像を取り出して白の近い色を取り出す層である
https://cvml-expertguide.net/terms/dl/layers/pooling-layer/max-pooling/
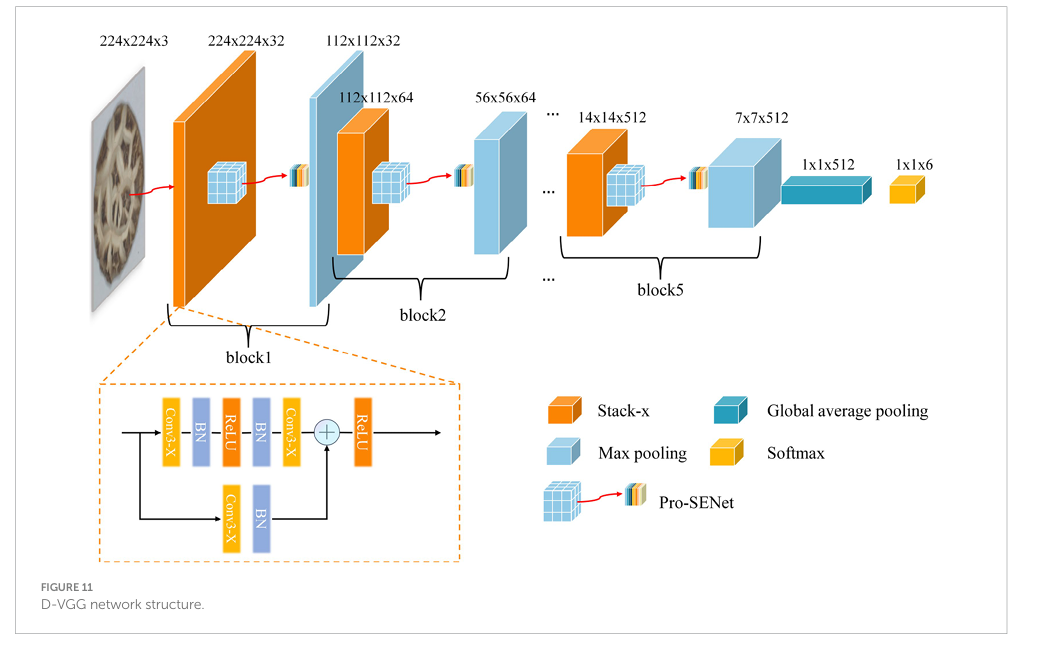
3.2.二枚目について
-
BN(Batch Normalization)
Batch Normalizationは、ニューラルネットワークの各層に入力されるデータの分布を標準化(正規化)する技術である。ネットワークが訓練中に学習する際、入力の分布が変化すると、学習が不安定になったり遅くなったりすることがある。この問題を解決するために、各ミニバッチの出力を平均0、分散1に調整するのがBatch Normalizationである。
これにより、学習がより速く進行しやすくなり、過学習(オーバーフィッティング)を防ぐ効果も期待できる。 -
ReLU(Rectified Linear Unit)
ReLUは、ニューラルネットワークで使われる活性化関数の一種である。活性化関数は、各層の出力を次の層に送る前に、その値を変換するための関数である。
ReLUは、次のように非常にシンプルな変換を行います:ReLU(x)=max(0,x)
つまり、入力が0以上の場合はそのままの値を出力し、0未満の場合は0を出力するという関数である。
ReLUは計算が高速で、勾配消失問題(深い層で勾配が消えてしまい学習が進まない問題)が他の活性化関数(シグモイドやタンズH)に比べて少ないため、非常に人気のある活性化関数である。 - まとめると:
BN(Batch Normalization) は、ネットワークの訓練を安定させ、学習速度を上げるために使われる正規化手法。
ReLU(Rectified Linear Unit) は、非線形な変換を行い、勾配消失問題を軽減するための活性化関数である。
論文URL
原文
https://www.frontiersin.org/journals/nutrition/articles/10.3389/fnut.2023.1247075/full
訳
https://qiita.com/tarura/private/9ab6be1fa3bd45d2f310