URL:https://www.frontiersin.org/journals/nutrition/articles/10.3389/fnut.2023.1247075/full
背景
私は、現在大学院で椎茸の良品不良品を判別する研究をしている。
でも研究してわっわっかんね~~~~~!!!!!!!!!!!!!!!!!!!!!
意味わからん。てか、データ収集地が大学から高速で三時間。ということで椎茸×機械学習の研究を第一に調べてどんどんコアに絞っていこうかと考えている。
でも大まかな概要を見たところこれは判別に成功してね....?っていうところである。
論文内容
1.概要
椎茸の分類や加工は、人の手に頼りがちであり、良質な椎茸を収穫するには長時間労働で収穫する必要がある。
この論文では、簡単に言うとキノコの品質と等級付けのために使用するYOLOシリアルアルゴリズムの最新バージョンであるYOLOX深層学習手法を改善するために、新しい手法が提案されている。
具体的な手法としてはシイタケの品質分類のために提案・改良されたYOLOXモデルの構築と最適化のプロセスをデータセットの拡張・チャンネルプルーニング・知識蒸留とプロセスを分け段階的に行っていき、モデルの最適化を行った。
実験的な結果によると、本論文で提案した改良YOLOX法は椎茸の表面組織を効果的に検査することができ、mAPとFSPはそれぞれ99.96%と57.3856であり、他の既存のアルゴリズム(Faster R-CNN、YOLOv3、YOLOv4、SSD 300)よりも優れた性能を発揮することでモデルサイズは半分以上削減することができた。
この改良されたYOLOX法は、生産プロセスにおいてシイタケの品質を迅速かつ正確に分類するのに効果的である。
2.導入
シイタケは長い歴史を持つ優れた食用キノコであり、最初に飼いならされ、栽培されたキノコの一つである。栄養(栄養素)と活性物質(物質)が豊富で、コレステロールや血圧を下げる(血圧低下)などの薬用および食事用(食材)の用途があり、近年、椎茸の需要は大幅に増加しています。
椎茸の特徴として、土壌環境や生育中の光や温度の影響により、椎茸の傘の表面は通常ひび割れ、さまざまな色や模様の特徴的な質感を形成する。
一般的に、この質感は白褐色でデイジーの形に似ており、このようなサンプルは乾燥花きのことして知られています。対照的に、傘の表面にひび割れのないキノコは乾燥厚きのこや乾燥薄きのこと呼ばれる。その中で、外観と質感に応じて、さまざまな種類の乾燥椎茸 (以下DSM) は、プレミアム、1 級、2 級の 3 つの等級に分類され、等級が高いほど品質が優れている。椎茸の品質は、取得プロセス中にその等級を識別するための重要な要素である。したがって、椎茸を品質に応じて正確に分類し、迅速な等級分けを実現するために、効率的で正確な自動等級分け方法の開発が緊急に必要とされている。
近年、ディープラーニングは様々な分野で研究ブームを巻き起こしている。農業分野では、マシンビジョンと組み合わせたディープラーニングが、木材カテゴリーの認識、果物と野菜の分類、植物の害虫と病気の識別、作物の収穫量推定、雑草検出など、植物の認識と検出に広く使用されている。特にディープラーニングは、農産物の品質等級付けに関連するタスクにもすぐに採用される。
以下にディープランニングでの実装事例を記入する:
Zhang et al.:
Zhang et alは、転移学習による改良された AlexNet モデルに基づくピーナッツ ポッドの等級認識方法を提案した。モデルをトレーニングするために、5 等級のピーナッツ ポッドの収集画像 500 枚の初期データセットが 3,500 枚の画像に拡張され、最終的な平均認識精度は 95.43% であった。
Ren et al.:
Ren et al. は、畳み込みニューラルネットワーク(CNN)と転移学習に基づく唐辛子の品質検出方法を提案した。この方法は、唐辛子の外観特徴に基づいてグレーディングを実行し、98.14%の予測精度を達成した。
Lu et al.:
Luら et al.は、マルチスケール特徴融合を備えた改良型ResNet50ネットワークに基づく焙煎タバコのグレーディング方法を提案した。この方法は、7段階の合計6,068枚のタバコ画像でテストされ、最終的なグレーディング精度は80.14%であった。
Chen et al.
Chen et al.は、ディープラーニングと生理学的指標に基づいたピーカンナッツのインテリジェントなグレーディング方法を提案し、4等級のピーカンナッツの画像4,395枚のデータセットを6,213枚に増やし、テストセットでの最終的なグレーディング精度は92.2%であった。
今回の研究で行うDSM 等級分けの研究では、当初、等級の識別は主に手作業による選別、計量、および篩穴に基づく機械的等級分け(笠の大きさに合わせたふるいに基づく機械的分類方法)に依存していた。
第一に手作業による選別では、熟練した作業員による等級の推定が含まれるが、この方法は効率が低く、等級分けは個人の主観的な評価に左右されるため、選別誤差が高くなり、等級分けの精度が低下するという問題がある。
また、軽量では、DSM 等級を重量で選別します。この方法は効率が向上しましたが、等級を区別するためにきのこの笠の特性を考慮していないため、制限がある。
そして、篩穴に基づく機械的等級分けでは、異なる篩穴サイズを使用して DSM を等級分けする。この方法は高速ですが、DSMの笠を考慮されていない。さらに、一部の DSM の形状は、対応する等級の篩穴の固定サイズと一致しない場合があり、等級分けの精度が低下する。
以上の手法の他に近年農産物におけるマシンビジョンとディープラーニング技術の発展により、国内外の学者の中には、DSM 画像の特徴を分析することで異なる等級を識別できるようになったという実績もある。
実績として以下のようなものがある。
Chen et al.:
Chen et al.は、DSMの笠の表面から適切なテクスチャ領域を抽出し、グレースケールヒストグラム統計、グレースケール共起行列、ガウスマルコフランダムフィールドモデル、フラクタル次元モデルを使用して特徴抽出を行い、k近傍法分類器を設計して画像の特徴を分類し、正しい分類率は93.57%であった。
Shi et al.:
Shi et al.(21)は、笠の開口部のテクスチャ特性に基づいてDSMを分類する方法を設計し、品質係数の計算式を確立し、最終的な分類精度は94.18%に達した。
Ketwogsa et al:
Ketwongsa et alは、改良された AlexNet CNNに基づいて、有毒シイタケと食用シイタケを分類するためのディープラーニング モデルを提案し、提案されたモデルの精度はそれぞれ 98.50% と 95.50% に達した。さらに、武漢 Cooper スマート マッシュルーム選別ラインなど、いくつかのインテリジェント マッシュルーム選別ラインが現場での応用で報告されている。
キノコの種の検出と品質の等級付けではいくつかの成果が得られていますが、まだいくつかの制限があります。
まず、従来のマシンビジョン方式は等級分けのプロセスが遅く、実際の現場環境の要件に適合していない。次に、既存の研究のほとんどは、さまざまな種類のキノコの分類に焦点を当てており、同じ種類のキノコの異なる等級に関する研究は少ない。これにより、高速実装、アルゴリズムの最適化、モデルの一般化、パフォーマンスの信頼性など、実際のアプリケーションで多くの課題が発生する。
この研究では、マシンビジョンとディープラーニングに基づいて、さまざまなDSMグレードをオンラインでリアルタイムに識別するための完全な画像処理方法とグレーディングスキームを提案する。
この方法により、さまざまな種類とグレードのDSMを正確かつ効率的に識別できる。
この研究の主な貢献は次のとおりである。
1.改良された Otsu の閾値二値化 (OOA-Otsu) アルゴリズムは、最大輪郭を抽出し、最大輪郭外部マトリックスを切り取ることによって DSM 画像を分割するように設計されています。次に、関心領域 (ROI) を拡張して完全な DSM 画像を取得する。さまざまなグレードの 1,355 個のオリジナル DSM を含む画像データセットが作成された。
2.D-VGG ネットワークは、VGG16 ネットワークを基本フレームワークとして使用して構築された。このネットワークは、最適化された畳み込み層、完全接続層の代わりにグローバル平均プーリング層の採用、残差モジュールとバッチ正規化の追加、および改良されたチャネル アテンション ネットワークによる融合を通じて、さまざまなグレードの DSM を効果的に識別できり。DSM データセットで達成された精度率は 96.21% で、他の同様のディープラーニング手法よりも優れている。
3.データクレンジング
この研究では、プレミアムドライフラワーマッシュルーム(DFM-P)、グレード1ドライフラワーマッシュルーム(DFM-1)、グレード2ドライフラワーマッシュルーム(DFM-2)、プレミアムドライシックマッシュルーム(PDM-TH)、グレード1ドライシックマッシュルーム(DTHM1)、プレミアムドライシンマッシュルーム(PDM-Th)の6種類のDSMに対して画像取得と前処理を実施した。
取得した初期画像は、DSMグレード認識モデルをトレーニングするための最終データセットを作成するために強化されている。全体的な方法のフローチャートを図1に示す。画像取得と前処理の手順については、次のセクションで詳しく説明する。

3.1.画像取得
異なる等級の DSM サンプルのサンプル画像が図 2 に示す。ここで、A1、A2 は DFM-P、B1、B2 は DFM-1、C1、C2 は DFM-2、D1、D2 は PDM-TH、E1、E2 は DTHM-1、F1、F2 は PDM-Th である。

図 2 から、異なる種の DSM は異なるテクスチャ特性を持ち、同じ種でも異なる等級の間にはいくつかの違いがあることがわかる。注目すべきは、一部の DSM 種は等級間で比較的わずかなテクスチャの違いを示し、正確に区別することが困難であったことである。たとえば、PDM-TH と DTHM-1 は、その後の DSM 等級の選別にいくつかの課題と困難をもたらした。
画像取得システムを図 3 に示す。

今回は、DSM等級認識タスク用に、リング光源を備えた画像取得暗室が設計した。
実験撮影環境は、60 cm×60 cm×60 cmの暗室の下で、外部光源の干渉を防ぐために、黒い光吸収布を敷いたプロ仕様のカメラを使用し、光源とカメラはブラケットに固定した。また、対象物を照らすために、Hikvision Technologyの産業用高均一リング光源を使用し、カメラモデルは、焦点距離12mmのMVL-HF1224M-10MP Hikvision光学産業用レンズを搭載したHikvision MV-CE100-30GC 10メガピクセル産業用カメラを使用した。
DSMの色と質感の詳細を強調するために、ホワイトバランスカードを背景として使用し、撮影距離を45 cmに設定した。
Hikvision Robotics Machine Vision が提供する公式 MVS ソフトウェアを使用して、露出時間を 1.818/100 秒に調整し、ソフトウェアに付属するガンマ補正アプリケーションを使用して画像の元の色を復元し、自動ホワイトバランスをオンにし、画像取得装置の前ではオープン モードを採用し、DSM 原材料の配置と取り外しを容易にした。
取得した画像は、ネットワーク接続を介してコンピューターに転送される。実験では合計 1,500 枚の DSM 画像が収集され、ぼやけや不完全な撮影背景などの取得上の問題のある画像は手動で選別を行う。
その結果、スクリーニング後に 1,355 枚の DSM 画像が得られた。
これには、184 枚の DFM-P、223 枚の DFM-1、212 枚の DFM-2、249 枚の PDM-TH、222 枚の DTHM-1、および 265 枚の PDM-Th 画像が含まれ、各画像のサイズは 3,840×2,748 ピクセルである。その後、画像はさらに前処理される。
3.2画像処理
現場の組み立てラインに広がるさまざまなレベルの DSM を継続的に識別する必要があるため、撮影フィールドは単一のキノコよりもはるかに大きくなければならない。
そうすれば、画像取得プラットフォームのすべてのパラメーターを変更する必要がなくなり、現在の認識モデルとデータセットを後続の現場部分検出に直接適用できる。
元の DSM 画像のサイズは 3,840×2,748 ピクセルで比較的大きく、DSM ターゲットが占める領域は小さいため、画像の大部分は無関係な背景ピクセルで構成されていた。モデルのトレーニングと収束速度を向上させるには、最初にキャプチャした画像をさらに前処理して、DSM が占める領域を正確に特定し、モデルが DSM のテクスチャ機能を識別して効率的かつ正確に評価できるようにする必要がある。
画像の前処理手順は以下のとおりである:
(1) 画像をグレースケールに変換します。
(2) 改良 Otsu のしきい値 2 値化 (OOA-Otsu) を適用します。
(3) DSM アウトライン抽出
(4) ROIの切り取り
3.2.1 DSM 画像の Otsu 閾値二値化の改善
画像は最初に単純なしきい値処理を使用して処理され、その結果、直接しきい値を使用して画像が 2 値化される。さまざまな DSM 画像のグレースケール分布を分析することにより、155、165、175、および 185 の 4 つのしきい値が選択され、画像が処理された。
図 4 は、4 つの異なるしきい値を使用して 6 つの DSM グレード画像を処理した結果を示している。

このうち、A1 ~ F1 は、異なるグレードの元の DSM 画像をあらわす。
A1 は DFM-P に対応し、B1 は DFM-1 に対応し、C1 は DFM-2 に対応し、D1 は PDM-TH に対応し、E1 は DTHM-1 に対応し、F1 は PDM-Th に対応します。
A2~A5 は、それぞれ 155、165、175、185 の 4 つのしきい値を使用して処理された DFM-P 画像の結果であり、B2~B5、C2~C5、D2~D5、E2~E5、F2~F5 についても同様である。異なるしきい値を使用して異なる DSM グレードの画像を 2 値化すると、異なる効果が得られることがわかる。
図 4A1 の DFM-P 画像では、グローバルしきい値が 155 (図 4A2) と 165 (図 4A3) の場合、最大外側輪郭が壊れているように見えるが、他のグレードの DSM の輪郭は正確に識別できる。図 4D1 の PDM-TH 画像では、グローバルしきい値が 185 の場合 (図 4D5)、しきい値を使用して 2 値化するとエッジが大きくなるが、DFM-P 輪郭の場合は同じしきい値で良好な結果が得られる (図 4A5)。
一方、他の DSM グレードでは、4 つのしきい値で異なる結果が出ている。したがって、異なる DSM グレードの画像のバッチ処理に固定しきい値を決定することは困難である。異なる DSM グレードのデータセット画像で得られた結果を表 1 に示す。
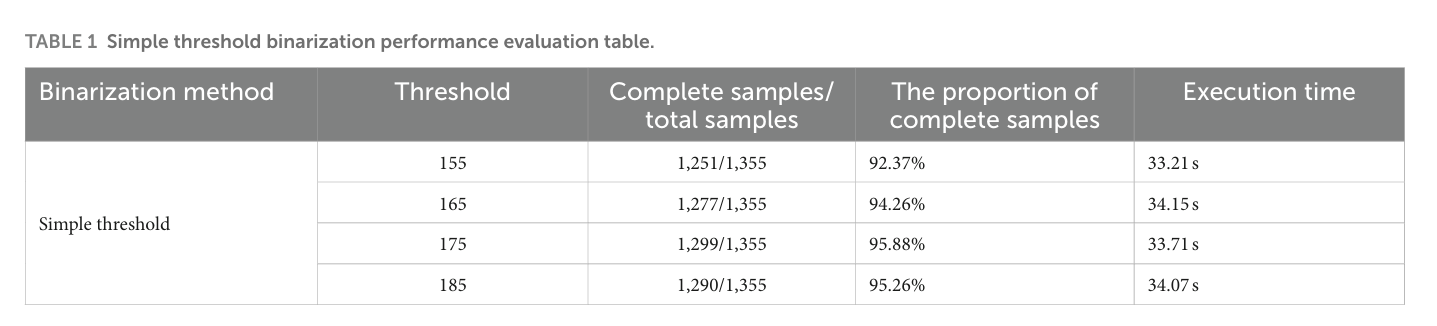
異なるしきい値での処理時間は 33.21 秒から 34.15 秒と非常に小さいことがわかる。しきい値が 175 の場合、最高のパフォーマンスが得られ、1,355 のサンプルのうち 1,299 の 2 値化された DSM ボディ輪郭が完全で、サンプル全体に対する完全なサンプルの割合は 95.88% であった。プロセスを完了するのに要した時間は 33.71 秒である。
次に、Otsu の閾値二値化法をテストした。
図 5 は、Otsu の方法を使用したさまざまなクラスの DSM の二値化結果を示している。

ここで、A~F は 6 つの DSM グレードの画像、A1~F1 は Otsu の閾値二値化の結果である。Otsu の閾値二値化法を使用すると、最大輪郭を効果的にセグメント化できることがわかる。対応するパフォーマンス メトリックは表 2 に示されており、すべてのサンプルに対する完全なサンプルの割合は 98.37% で、計算を完了するのに必要な時間は 255.28 秒であった。

Otsu の方法は、さまざまな DSM グレードの画像二値化の処理で良好な結果を示したが、実際のフィールド アプリケーションでは計算時間が長すぎる。主な理由は、分散を計算するために、0~255 の範囲のすべてのグレーレベルをトラバースする必要があることである。
各レベルの分散を計算する時間をTとすると、合計計算時間は256Tとなり、DSM画像の二値化の処理効率が大幅に低下する。効率を向上させながら画像の最適なしきい値が得られるように、ミサゴ最適化アルゴリズム(OOA)をOtsuのしきい値二値化法に適用した。OOAは、海から魚を狩るミサゴの戦略を使用して、最適なしきい値を見つける。DSM画像のしきい値ベースの二値化の新しい方法は、OOA-Otsuアルゴリズムと名付けられている。 OOA-Otsu アルゴリズムの処理フローを図 6 に示す。
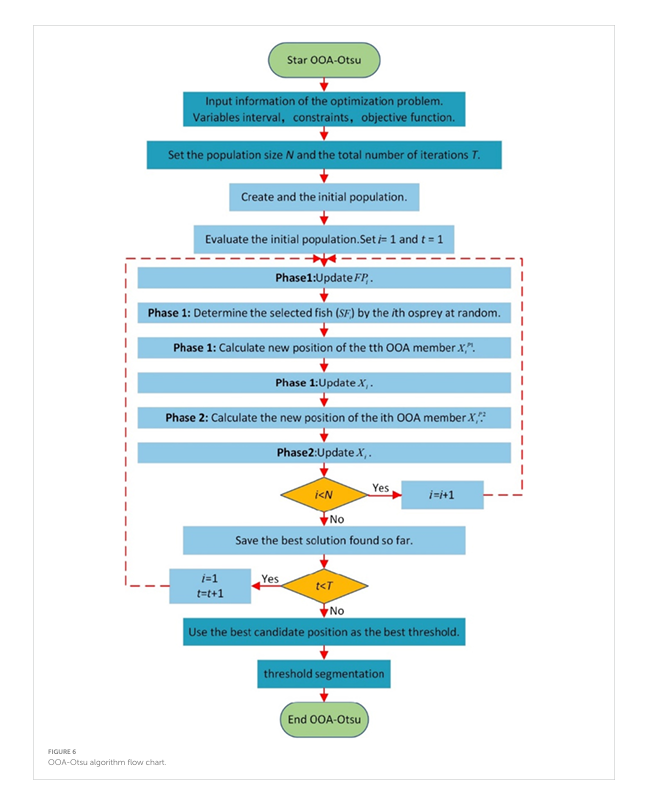
図 6 で、N は個体群サイズ、T は最大反復回数、i は i 番目のミサゴ、t は現在の反復回数、FPi は i 番目のミサゴの魚の集合、SFi は i 番目のミサゴが選択した魚、Xi は i 番目のミサゴの現在の位置、Xi P1 はフェーズ 1 における i 番目のミサゴの位置、Xi P2 はフェーズ 2 における i 番目のミサゴの位置を表す。このアルゴリズムでは、Otsu の計算プロセスにおける最適なしきい値が、OOA アルゴリズムにおけるミサゴ個体群の座標 Xi と見なされる。
OOA アルゴリズムは、ミサゴの捕食行動をシミュレートするために使用され、各ミサゴの位置の適合度が計算され、反転される。各反復で、位置の適合度が比較され、座標 Xi が更新され、最終的に最適なしきい値が決定される。その目的は、Otsu の網羅的方法によって達成される最適値に到達することである。
図 7 は、さまざまな DSM グレードに対する OOA-Otsu アルゴリズムの結果を示している。
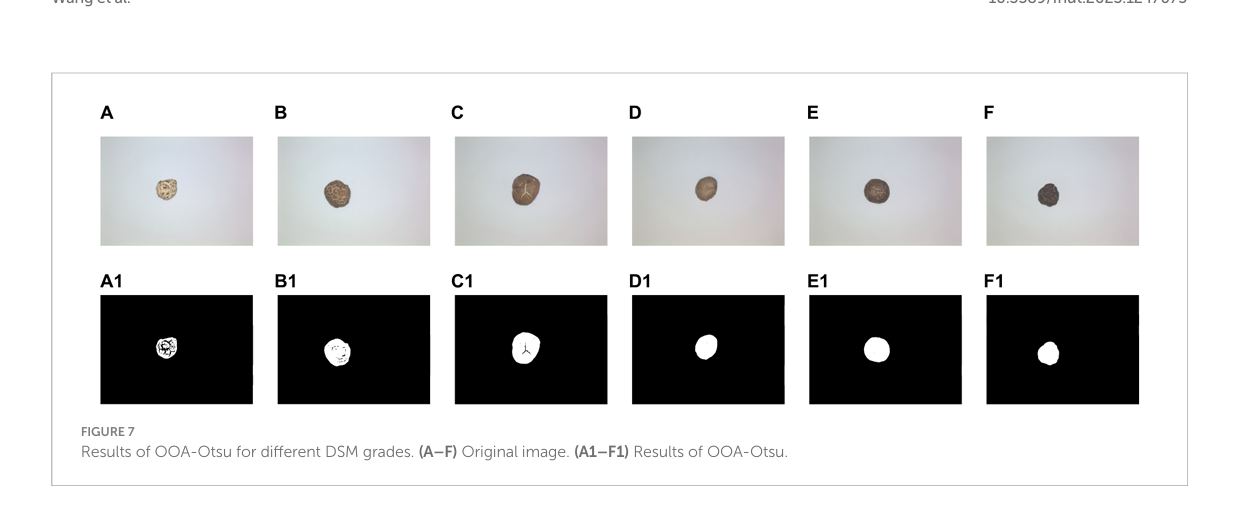
ここで、A~F は 6 つの DSM グレードの画像、A1~F1 は OOA-Otsu による処理結果である。OOA-Otsu は DSM の最大輪郭を効果的にセグメント化できることがわかる。
OOA-Otsu のパフォーマンス分析は表 3 に示されており、完全なサンプルが合計サンプルに占める割合は 99.31% であり、この割合を達成するのに要した時間は 52.89 秒であった。
3 つの閾値二値化方法の全体的なパフォーマンスを表 4 で比較する。

この論文で提案されている OOA-Otsu は、異なるグレードの異なる DSM 画像を二値化するときに、最短時間で最高の精度でより完全な輪郭情報を保持し、最高のパフォーマンスを実現する。
3.2.2 乾燥シイタケのグループ化
OOA-Otsu プロセスの後、画像内の DSM のすべての輪郭が取得される。一部の DSM キャップのテクスチャ特性により、本体の最大輪郭の内側に無関係な輪郭が含まれる場合がある。また、DSM の周囲に残渣が存在する可能性があり、これらの無関係な輪郭もしきい値セグメンテーションプロセス後に表示されるため、DSM の正確な画像を取得するために輪郭フィルタリングを続行する。さらに、分類ネットワークでは同じ入力画像の長さと幅が必要なため、ROI 領域は、トリミングされた画像の長さと幅が同じになるように調整され、スケーリング操作によって DSM 画像の比率が歪むのを防ぐ。
図 8 は、DSM セグメンテーションの結果を示している。
図 8A では、赤いボックスは DSM の最小外側長方形を示し、緑のボックスは調整された最小外側正方形を示している。トリミングおよびサイズ変更された最小正方形 ROI の結果を図 8B に示す。

3.3データ拡張
切り取られた DSM 画像はピクセル サイズが異なる。ピクセル サイズを一定にするために、ダブル キュービック補間法を使用して、スケーリングされた画像の品質を確保した。
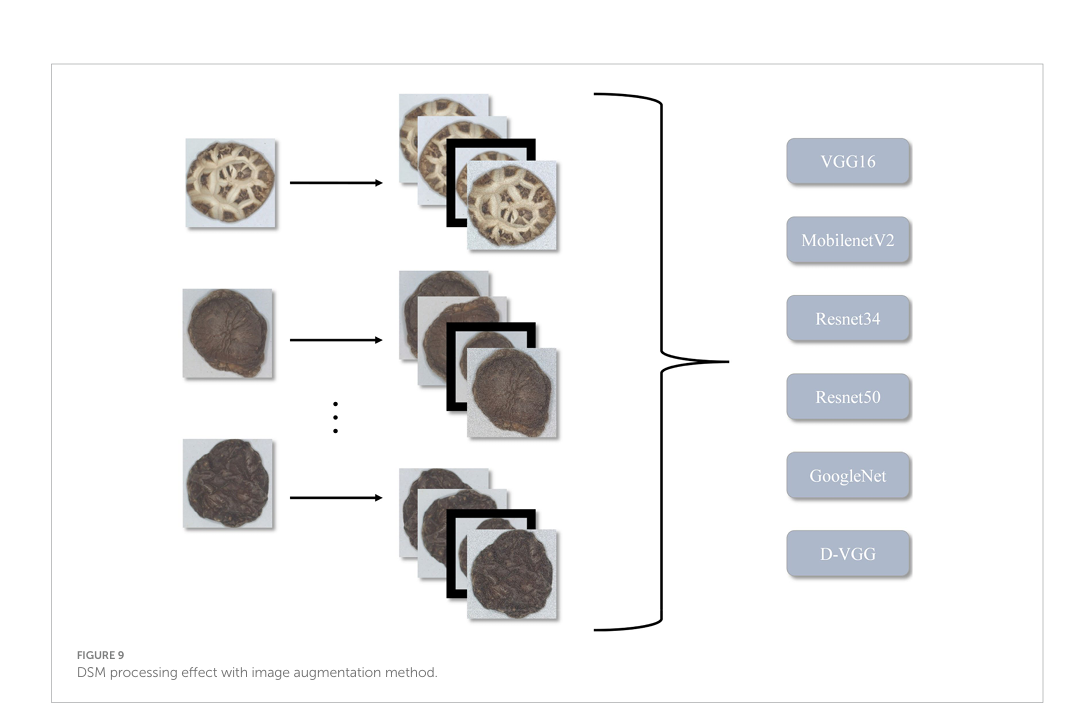
DSM 画像のピクセル サイズは、224 × 224 に均一にサイズ変更された。過剰適合を回避し、モデルの一般化能力と認識精度を向上させるために、データ拡張法を使用してサンプル画像の数を増やした。DSM のテクスチャ特性を考慮して、Python ライブラリ imgaug を使用して、水平および垂直反転、ガウス ノイズの追加、および等スケール スケーリング (25) を実行し、既存のデータセットに対する拡張操作を実行して、モデル トレーニング用のサンプルをさらに生成した。
図 9 は、画像拡張法による DSM 処理効果を示している。
最終的なさまざまな DSM グレードの画像の詳細な数は、表 5 に示す。
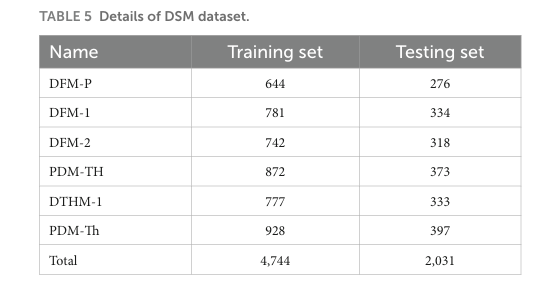
画像拡張後のサンプル総数は 6,775 で、具体的には、DFM-P が 920 個、DFM-1 が 1,115 個、DFM-2 が 1,060 個、PDM-TH が 1,245 個、DTHM-1 が 1,110 個、PDM-Th が 1,325 個でした。最終的なデータセット画像の 70% がトレーニング セットとして使用され、残りの 30% がテスト セットとして使用された。
4.モデル構築
4.1 D-VGGモデルの全体的なフレームワーク
Visual Geometry Group (オックスフォード大学) が提案した VGG16 ネットワーク モデルは、古典的な CNN の 1 つであり、画像分類、画像セグメンテーションなどのタスクによく使用される。この論文では、提案された DSM グレード認識ネットワークは VGG16 に基づいている。まず、VGG16 ネットワークの畳み込み層は、完全接続層の代わりにグローバル平均プーリング層を採用することで、DSM グレード認識タスク用に最適化された。改良されたネットワーク構造 (図 10) は、5 つのスタック モジュール、グローバル平均プーリング層、およびソフトマックス層で構成され、各スタック モジュールには 2 セットの畳み込みが含まれている。

次に、収束速度を加速しながらモデルの微妙な DSM 機能の学習を強化するために、残差モジュールとバッチ正規化メソッドが改良されたネットワークの各スタック モジュールに導入された。グレーディング精度をさらに向上させるために、改良されたチャネルアテンションモジュールが提案され、改良されたネットワーク構造に導入されて、DSM画像の各チャネルの重み付けシェアが強化された。最終的なネットワークモデルはD-VGGと名付けられ、その全体構造を図11に示す。
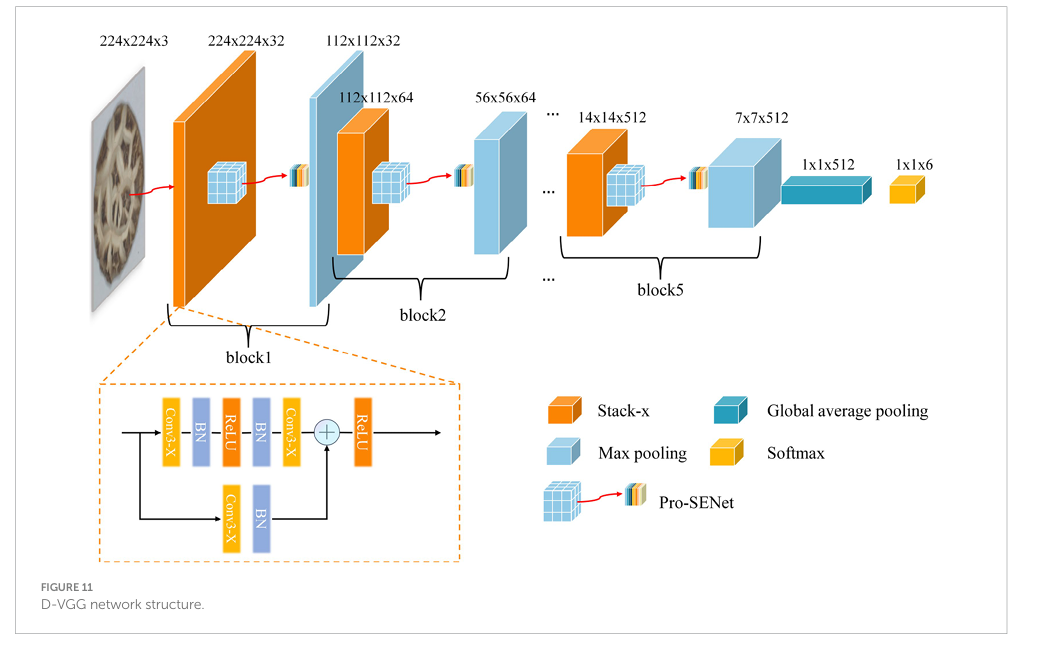
4.2 畳み込み層構造と完全結合層の変更
D-VGGネットワークのネットワーク構造は、5つのブロック層、グローバル平均プーリング層、およびソフトマックス層で構成されていることがわかる。その中で、各ブロック層はスタックモジュール、修正されたチャネルアテンションネットワーク、およびプーリング層で構成されている。
次に、D-VGGの各部分について詳しく説明する。
異なるグレードの DSM の形態特性とテクスチャ特性が異なるため、ネットワークの最前面に、2 セットの畳み込み操作を含む深さ 32 の畳み込みグループ モジュールが追加された。同時に、ネットワーク内の深さ 512 の畳み込みグループ モジュールの最後のセットが削除された。畳み込み層の深さを減らす戦略は、モデルの複雑さとパラメーターの数を減らし、過剰適合のリスクを減らし、DSM グレード認識タスクにおけるモデルの一般化能力を向上させることを目的としている。
次に、当初 3 セットの畳み込み層を持つ深さ 256 と 512 の畳み込みグループを、深さ 32、64、128 の畳み込みグループと一致する 2 セットの畳み込み層に調整した。この操作により、ネットワーク構造が最適化され、その後のモデル構築と改善が容易になる。最終的に、ネットワーク モデル全体に 5 つの畳み込みグループができました。各グループには 2 つの畳み込み層が含まれています。畳み込みグループの機能と構成をより適切に説明するために、畳み込みグループは「スタック」に名前が変更されました。
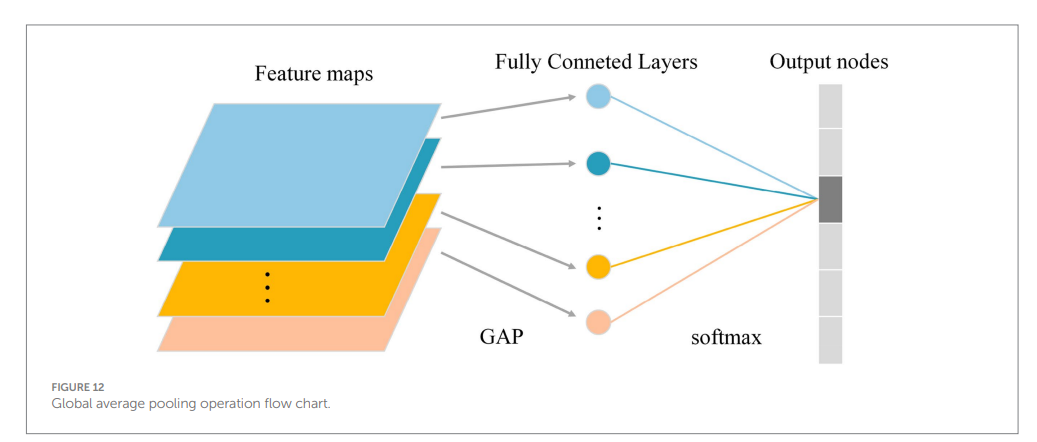
完全に接続された層は、ディープラーニング ネットワーク モデルのパラメーターの数が多く、トレーニングに大量のメモリが必要になる主な理由です。DSM グレード認識タスクでは、最終的な分類が 6 つのカテゴリにわたって実行されましたが、ImageNet データセットでトレーニングされた 1,000 クラス分類タスクと比較してニューロンが冗長すぎることが判明し、モデルのオーバーフィッティングにつながる可能性がある。そのため、最後の畳み込みプールされた特徴マップに対してグローバル平均プーリング操作を実行し、512×1×1 の出力を取得した。
その後、拡散処理された特徴マップがソフトマックス レイヤーに入力され、最終的なグレーディング結果が完成した。
グローバル平均プーリング操作のフローは図 12 に示されている。
改良された VGG ニューラル ネットワーク モデルは VGG-REV と名付けられた。VGG-REV ネットワーク レイヤー構造には、5 つのスタック モジュール、グローバル平均プーリング レイヤー、およびソフトマックス レイヤーが含まれている。その VGG-REV ニューラル ネットワーク構造は図 10 に示す。
4.3 残差とバッチ正規化
DSM の色とテクスチャ情報は、モデル学習において重要な役割を果たす。
異なる DSM グレードの微妙な特徴を抽出するために、ResNet ネットワークで導入された残差構造を活用し、VGG-REV モデルの各スタック モジュールの入力層に 1×1 ショートカット ブランチを追加して、DSM 特徴のテクスチャ情報と改良されたニューラル ネットワーク間の接続を強化する。残差構造を追加した後の単一スタック モジュールのネットワーク構造を図 13A に示す。

CNN の畳み込み層の主なタスクは、画像の特徴を抽出することである。異なる DSM グレードの機能が処理のために畳み込み層に入ると、畳み込みパラメータの更新により出力データの分布が不均一になる可能性があり、ニューラル ネットワーク モデルに影響を及ぼす。この問題を解決するために、各畳み込み層とアクティベーション関数の間にバッチ正規化層を導入して、モデルの収束を加速し、トレーニング プロセスを安定化させる。モデルのトレーニング中、バッチ正規化では、小さなバッチのデータの平均と標準偏差を使用し、調整のために分散が 1、平均が 0 の領域にマッピングして、出力データをより安定させます。バッチ正規化の計算プロセスを式 (1) ~ (5) に示す。
まず、各ラウンドのトレーニングバッチデータの平均と分散を計算します。
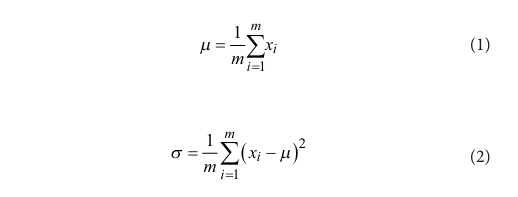
ここで、x_i は入力データ サンプルの総数である。平均と分散を取得した後、バッチは分散が 1 のゼロ平均正規分布に正規化される。

ここで、ε は、分母がゼロになって計算が無意味になる場合を避けるために使用される小さな正の数である。データ正規化が特徴分布に与える影響を避けるために、関数はさらに再構築され、元の特徴分布が復元される。
計算式は次のとおりである。
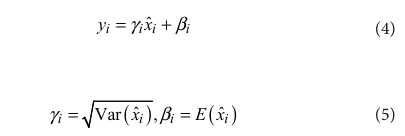
γ_i、β_iはCNNトレーニングプロセスを通じて取得され、Var(x)は分散関数、E(x)は平均値関数です。バッチ正規化ステムはスタックモジュールネットワーク構造に導入され、改善された構造は図13Bに示され、VGG-REV-RES-BNニューラルネットワークと呼ばれる。
4.4 チャネルの注目度を向上させる Pro-SENet
実際の制作環境では、DSM 画像は単一の背景を持つが、認識プロセスは必然的に不均一な照明と細い毛髪の点粒子の出現によって特徴付けられ、大量のノイズを導入する可能性がある。
このノイズは、モデルトレーニングに使用されるデータへと渡され、ネットワーク内を伝播するにつれて特徴層パラメータの学習に影響を与え、最終的には DSM グレード認識プロセスに影響を与える。
この問題を解決するために、改良されたチャネルアテンションネットワーク Pro-SENet が提案されている。これは、各特徴の値を自動的に学習することにより、DSM の詳細な特徴に関連付けられた重みを増やし、干渉要因の重みを抑制する。チャネルアテンションネットワーク構造には、スクイージング、刺激、および特徴の再スケーリングの 3 つの主要な部分が含まれる。提案された設計により、チャネルアテンションのスクイージング部分と刺激部分が次のように改善される。
4.4.1 圧迫
スクイージング操作は、同じサンプルの入力バッチに対して実行され、空間次元の次元 W×H×C の特徴画像に対して、グローバル平均プーリング (GAP) およびグローバル最大プーリング (GMP) 操作が適用される。
GAP が適用された各チャネルの特徴マップ W×H は、出力次元が 1×1×C である 1 つのグローバル特徴のみを持つ実数にスクイージングされる。GMP を使用して処理された各チャネルについて、そのチャネルの最大値がその特徴マップとして抽出され、出力次元も 1×1×C になる。
最後に、これら 2 セットのデータが平均化され、合計されて、スクイージング操作の出力が得られる。元の GAP 操作を GAP 操作と GMP 操作に置き換えると、GAP 重みの不均一な分布が緩和され、GMP から取得したデータによって有効チャネルの重みがさらに強化されることは注目に値する。具体的な式は、式 (6) ~ (8) に示されている。

ここで、Fsq1 は GAP 法、Fsq2 は GMP 法、uc は入力データ バッチの特徴画像、W と H はそれぞれ特徴画像の幅と高さ、(i j, ) は特徴画像上の座標である。上記の処理プロセスの後、最終的な出力チャネルは Zc であり、その出力は C の特徴マップ スクイーズ結果である。
4.4.2 シミュレーション
圧縮によって得られた結果は、深さを変えるために線形に変化し、ReLU6活性化関数に入力される。初期のReLU活性化関数と比較して、ReLU6関数は、不均一なチャネル学習重みを回避し、改善された圧縮操作による過度の重み分布への影響を軽減し、より適切なチャネル重みをもたらす。次に、各チャネル深度の重みは、初期の深さの別の線形変化によって取得され、最後にシグモイド活性化関数を使用して確率分布が0と1の範囲に調整される。方程式は式(9)に示される。
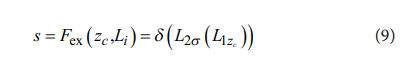
ここで、F_ex は励起法、L1 と L2 は線形変化処理に使用される完全結合層、s は ReLU6 活性化関数、d はシグモイド活性化関数である。最後に、長さ C のベクトル S が得られる。
4.4.3 機能の再スケーリング
最終的に得られたチャネル重みSは、チャネルごとに初期入力特徴画像行列に掛け合わされ、元の特徴チャネル次元の再スケーリングを完了する。式は式(10)に示されている

F_scale は特徴再スケーリング方法、uc はチャネル C の特徴画像、Sc は長さ C の重みベクトルである。最後に、特徴再スケーリング プロセスの出力結果 Uc が得られる。改良されたチャネル アテンション構造を図 14 に示す。
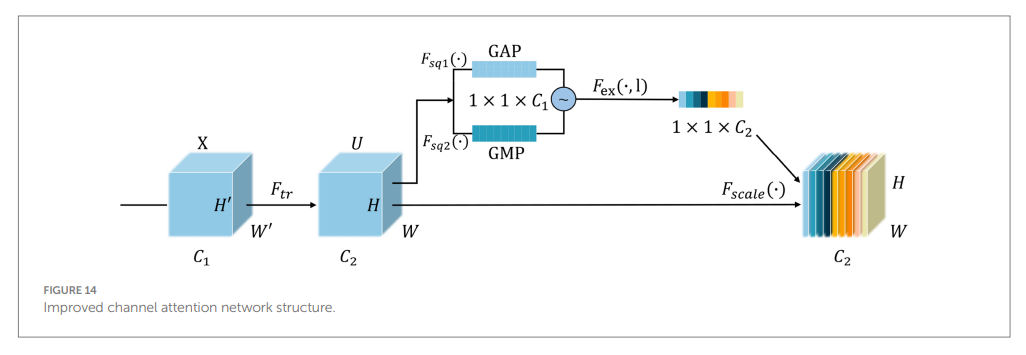
この研究で提案された改良されたチャネル アテンション ネットワーク モジュール (Pro-SENet) は、プラグ アンド プレイ モジュールである。VGG-REV-RES-BN 特徴抽出ネットワークに基づいて、改良されたチャネル アテンション モジュールを追加して、DSM 画像特徴重み付けネットワークを定式化し、モデルの認識精度をさらに向上させる。得られた最終的なニューラル ネットワーク モデルは、単に D-VGG と呼ばれる。
5. 結果
5.1.1 アブレーション実験
さまざまな改善がモデルのパフォーマンスに与える影響を調査するために、一連のアブレーション実験を実施した。実験には、一貫したハイパーパラメータを持つ同じ構成環境を使用した。
実験結果を表 6 に示す。
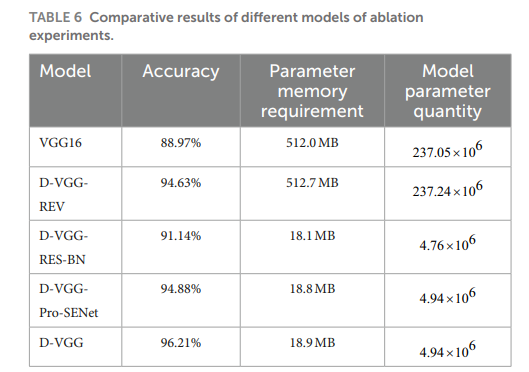
このうち、D-VGG-REV は、ネットワークの畳み込みと完全接続層を変更せずに D-VGG から開始して得られたモデルであり、D-VGG-RES-BN は残差構造とバッチ正規化を追加せずに得られたモデルであり、D-VGGPro-SENet は Pro-SENet ネットワークを融合しないモデルである。
これらのネットワークの比較は、各改善方法がモデルに与える影響を調べるのに役立つ。
表 6 から、VGG16 モデルは DSM の精度を識別する上で最悪の結果を示していることがわかる。これは主に、収集された DSM 画像データの背景が単一であり、VGG16 ネットワークの単純なモデルには複雑すぎるためである。 D-VGG-REV モデルでは、D-VGG と比較して精度が 1.58 パーセントポイント (pp) 低下し、モデルメモリサイズが 18.1 MB から 512.7 MB に増加している。ネットワークの畳み込み層と完全接続層を修正することで、ネットワークのパフォーマンスが向上し、モデルに必要なメモリが大幅に削減されたと結論付けることができる。モデルが D-VGGRES-BN の場合、モデルの精度は 5.07 pp 低下する。残差モジュールとバッチ正規化は、ネットワークのパフォーマンスを向上させるのに効果的であると結論付けることができる。これは主に、モデルの深さが増すにつれて DSM の特徴情報の詳細レベルが徐々に低下し、残差モジュールの導入によってこの問題が解決されるためである。さらに、バッチ正規化により、ネットワークのトレーニングと収束が高速化され、不均一なデータがモデルに及ぼす悪影響が防止されるため、認識精度が向上する。 D-VGGPro-SENet モデルの精度は 1.33pp 低下する。これは主に、チャネル アテンションを備えたモデルが DSM の特徴チャネルをより効果的かつ適応的に学習し、モデル学習に有利なチャネルの重みを高めることができるためである。
図 15 は、50 回の反復における各モデルの精度の比較を示している。要約すると、本研究で提案された改良方法は、VGG16 ネットワークと比較して大幅なパフォーマンスの向上を達成した。

5.2 学習率とバッチサイズがモデルのトレーニングに与える影響
学習率 (LR) とバッチ サイズは、ディープラーニング モデルのトレーニングにおいて重要なパラメーターである。最適な初期 LR とバッチ サイズの値を決定するために、実験が行われ、これらのハイパーパラメーターのさまざまな値の影響が比較された。
5.2.1 学習率がモデルトレーニングに与える効果
最初にバッチ サイズを 32 に設定し、異なる LR がモデルのパフォーマンスに与える影響について実験を行った。LR は、桁数と、同じ桁の異なる値で比較された。
実験結果を表 7 に示す。
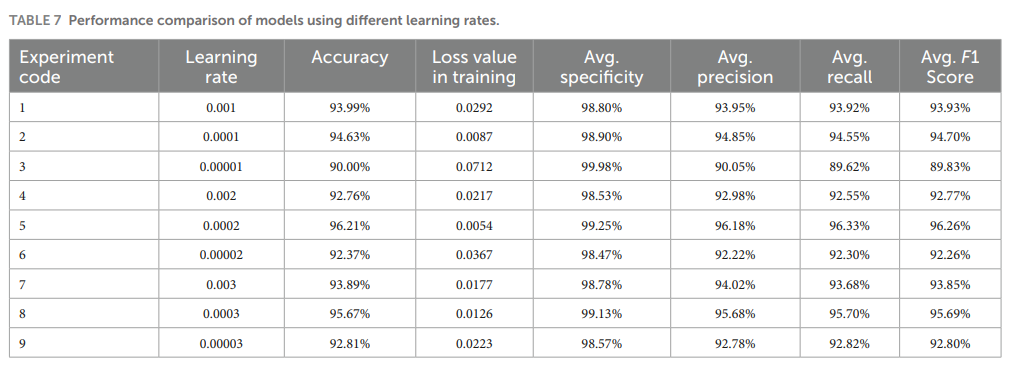
LR は 10-3 から 10-5 の範囲であったため、10-4 桁の値で最高の精度と最小の損失値が得られた。これは主に、初期 LR が 10-3 の桁に設定されていたため、大きすぎるため、ネットワークが最適解に安定して収束できず、パラメーター空間内でより大きな距離をジャンプし、最適なグローバル最小値を逃してしまうためある。
対照的に、初期 LR を 10-5 の桁に設定した場合、ネットワークの勾配の減少が遅すぎた。これは、LR が小さすぎるために反復制限に達した後、最適な結果が得られなかったためである。
したがって、ネットワーク モデルは 10-4 の桁で LR に対して最高の精度と最良のトレーニング結果を達成したと結論付けることができる。

図 16A、B は、それぞれ異なる初期 LR の大きさに対するモデルのトレーニング中の精度と損失値の変化を示している。これに基づいて、初期 LR を 0.0001 から 0.0003 の間で変化させて、横断的比較を実施した。
表 7 から、このモデルの最適な初期 LR は 0.0002 であり、最高の精度率 96.21% と最小のトレーニング損失値 0.0054 が得られたことがわかる。

図17A、Bは、10-4桁の異なるLR値に対するモデルのトレーニング中の精度と損失値の変化を示している。
5.3 ネットワーク評価
本研究では、モデルの有効性を評価するための評価指標として、精度 (ACC)、適合率 (P)、特異度 (S)、再現率 (R)、F1 スコア (F1)、平均指標 (補足表 S1) を使用した。
補足表 S1 では、TP、TN、FP、FN、ki、Ni はそれぞれ、真陽性、真陰性、偽陽性、偽陰性、評価指標、グレード N のサンプルの総数を表している。評価指標のうち、F1 は再現率と特異度を組み込んだ複合指標であり、値が高いほど全体的に優れたモデルであることを示す。ネットワーク評価式を補足表 S1 に示す。