
みなさん、こんにちは。Retty CTO の樽石です。
この記事は Retty Advent Calendar 25日目です。メリークリスマス。
昨日は @ttakeoka の『MFIにむけてRettyの取り組み』でした。
今年も残りわずかになりました。いかがお過ごしですか?
Retty はこの 1 年でエンジニアがほぼ倍増しました。それによって、情報発信者が増え、Advent Calendar に参加出来るようになりました。みんな楽しそうにしていて、うれしいです。
Retty Inc. Advent Calendar 2016 - Qiita
さて、今年最後の Retty Advent Calendar 記事を書くということで、はじめは 1年のまとめ的内容にしようかと思いましたが、それでは平凡で面白くありません。そこで、ネタになりそうなマニアックな技術的記事で締めくくりたいと思います。
内容は、Retty でおこなった今年のユニークな技術的取り組み「Retty 機械学習基盤を秋葉原に買い物に行って自作した話」です。
※ この記事は機械学習の技術や歴史の記事ではありません。そちらに興味がある場合は、楽天研究所 Moriさんのアドベントカレンダーや まとめのまとめあたりから読み始めていただきますと幸いです。
※ 読みやすさのために図やロゴを多用しました。記事中のソフトウェア名、製品名、社名、店舗名およびロゴは各社の商標、登録商標または著作物です。
※ 内容は正確性を意識しておりますが無保証です。
Retty の機械学習基盤アーキテクチャ概要
まず、はじめに Retty 機械学習基盤のアーキテクチャについて概要を説明します。
NVIDIA のコンシューマ向け GPU を 2 つ搭載した Intel アーキテクチャの自作 ATX タワーマシンを 5 台並べています。
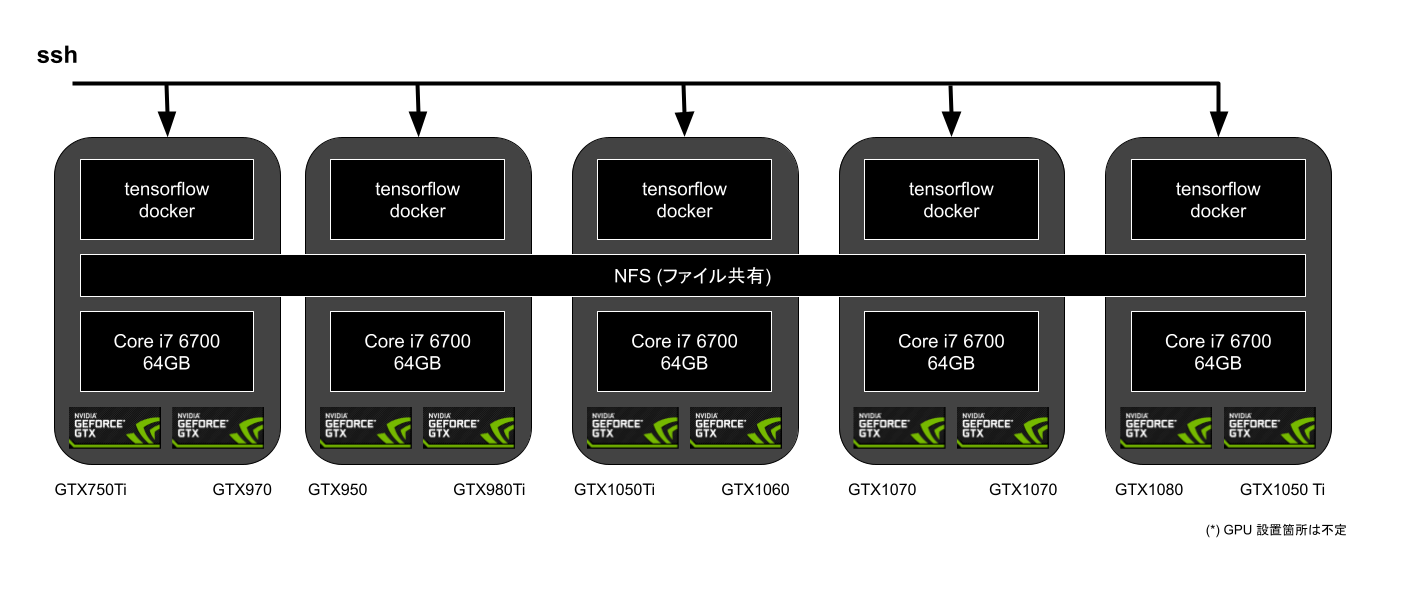
その各マシンに ssh でログインできる docker コンテナが稼働していて、ログインして GPU を利用します。5台のマシンの各 docker コンテナのホームディレクトリは NFS で共有されていて、どのマシンにログインしても同じデータにアクセスが出来ます。
GPU は合計 10 個、機械学習エンジニアには「どこにログインしても同じファイルにアクセスできるプリエンプティブル・コンテナ1」に見えます。

Retty 機械学習基盤を使って開発された技術の活用例
Retty 機械学習基盤を作って開発された技術の一部を紹介します。
写真のカテゴリ分類
まずは機械学習の典型的な活用例である写真の分類です。Retty では、写真を「料理」「外観」「内観」「メニュー」に分けて掲載しています。
引用: https://retty.me/area/PRE13/ARE14/SUB1401/100001178822/photos/
この分類は今まですべて手作業で行っていたのですが、CNN による料理写真の判定精度が実用レベルに達したため、本番サービスに適用しました。
料理写真のタグ付け
画像分類の応用で、写真に映っている料理を発見し、写真にタグ付けをする技術を開発しました。下は、パンケーキのタグを付けた写真を自動でお店代表写真に選出している例です。
Before
検索流入キーワード: パンケーキ

After
検索流入キーワード: パンケーキ

引用: https://retty.me/area/PRE01/ARE164/LCAT9/CAT161/
もともと、Rettyに掲載されているお店の代表写真はそのお店に対してひとつに決まっていました。ところが例えば上記のお店のように「オムライスとパンケーキ」の両方が名物のお店の場合、オムライスの写真が常に代表写真になってしまい、パンケーキを探しにきたユーザさんに対してもオムライスの写真を見せてしまいます。
この写真タグ付け技術により、パンケーキを探しに来たユーザさんにはパンケーキの写真を、オムライスを探しに来たユーザさんにはオムライスの写真を見せることが可能になりました。
超解像 (写真の鮮明化)
超解像は、画像の解像度を高解像度化して、より鮮明な画像に変換することです。
従来は、画像変換の標準的なアプローチをもとにエッジ調整などを加えて超解像化することが多かったのですが、近年、ディープラーニングを活用した超解像技術が大きく発展しています。
Retty でもディープラーニングを用いた写真の超解像化を行いました。

(お店からの写真: https://retty.me/area/PRE13/ARE1/SUB101/100000868744/)
差がわかりにくかもしれないので、拡大した写真も掲載します。


※この技術がもっと発展すれば「非可逆圧縮」の圧縮率をもっと高められるかもしれないですね。注目の技術だと思います。
他にも、口コミをディープラーニングしてお店の特徴を抽出したり、一眼レフ風の写真を発見して良い写真の候補を発見したりするなど、合計で 30 以上の PJ で新技術を作りました(数名で)。新技術とはいっても、次から次へと論文が出てくるのでキャッチアップと自社データでの応用という意味合いが強かったと思います。
また、これらの技術を機械学習エンジニア以外の人でも簡単に使えるようにするために、「機械学習 Web アプリ」を作成しました。
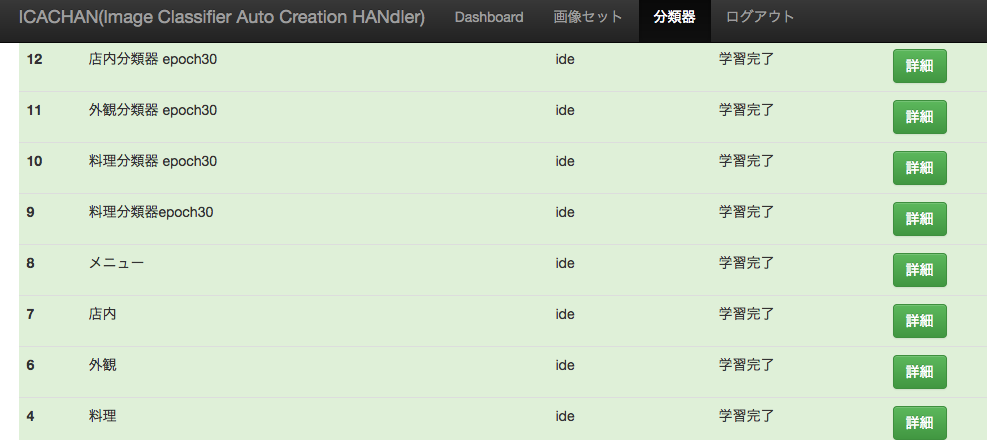
これらは、ICACHAN(画像分類) / MICANCNN (画像変換) / TACOCNN (自然言語処理) と呼ばれ、社内で親しまれています。



機械学習基盤を自作した 6 つの理由
Rettyはサービス開始当初から昨年まで全て AWS で動いています。今年から Google の BigQuery や Azure など複数のクラウド活用が始まったのですが、クラウド以外を使ったことはありません。
そんな Retty が、ハードウェアを自社で購入して、独自の基盤を構築しました。主な理由は以下になります。
- 最新の機械学習技術であるディープラーニングを行うには GPU が必須であった
- GPU を使いたい機械学習エンジニアが、クラウドのGPU付インスタンスの価格に驚き、利用を躊躇していた
- GPU の性能に関する情報が少なく、機械学習を行うのにどれぐらいの費用がかかるのかわからなかった
- アルゴリズムによって CPU・GPU・メモリ・IO・ネットワークのどれがボトルネックになるかが異なるため、どのインスタンスを使えば良いのかを機械学習エンジニア自身が毎回考えていて、機械学習そのものになかなか取りかかれなかった。
- ssh でログインする開発形態になるため、クラウドサービスとオフィスのネットワーク・レイテンシの問題で開発生産性が上がらなかった。
- GPUの市場価格が毎月下落していたため、必要な時期に必要な分だけGPUを増設すれば、ローコストでシステムを構築できそうと考えた。
上記のように、様々な理由があったのですが、一言でいえば**「エンジニアが24時間好きなだけ定額でGPUを使える環境」**を用意したかったということです。この課題は解決し、今では必ず誰かが1日中、GPU を使っている状態になっています。
機械学習基盤の実現方法
Retty 機械学習基盤を作るにあたり、今後の展開を考慮して、いくつかの要件を決めました。
- 会社のフェーズ、機械学習の要件に応じて容易に改良・スケールできること
- データや環境があらかじめ用意されていて、機械学習そのものにすぐに取り掛かれること
- 基盤の PDCA のためにマシンを再インストールしても、機械学習エンジニアの作業データが無くならないこと
- 投資効果を最大化するため、また社内に技術を蓄積するため「市場最安値のパーツを購入し、あとはオープンソース・ソフトウェアと技術で解決」すること
これらを実現するためにPDCAを回した結果、以下のようなアーキテクチャになりました。
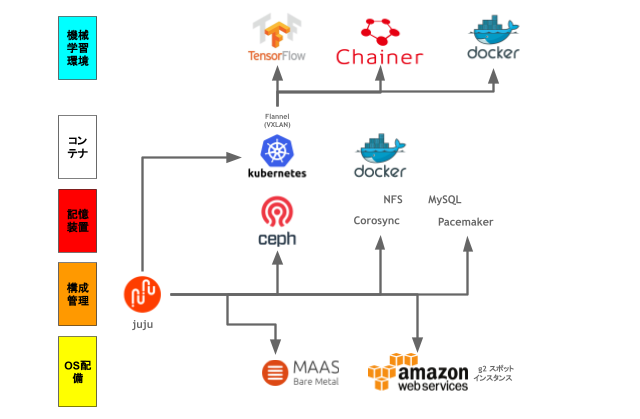
- juju による構成管理
- MaaS による OS 自動配備 / AWS スポットインスタンス
- ceph を利用した分散ストレージシステム
- corosync / pacemaker を使った NFS サーバクラスタ
- 機械学習に必要なすべてを詰め込んだ Docker イメージ
- Kubernetes を使った VXLAN 管理、および Docker コンテナ・スケジュール
juju による構成管理

juju はインフラの構成管理ツールです。 Ansible や Chef、Puppet と類似のツールになります。特徴は Ubuntu の標準ツールであること、インスタンスのブートストラップが可能で後述する MaaS との相性が非常に良いこと、そしてスケールさせることが簡単なことです。例えば、48 台の機械学習マシンを追加するには以下のコマンドを実行します2。
juju add-unit -n48 akiba
※ 独断と偏見ですが、juju の使いやすさは他を圧倒すると思います。この使いやすさを徹底するアプローチは apt を開発した Debian 系ディストリビューションの文化なのかなと思います。
なお、Retty 機械学習基盤では、Docker (Kubernetes) を多用しています。構成管理の大部分は Docker 上で行っており、juju は Docker (Kubernetes) 実行環境を構成するところに絞っております。
MaaS による OS 自動配備 / AWS スポットインスタンス

MaaS とは ベアメタル環境から OS を自動でインストール出来る Ubuntu 純正の OS 配備システムです。PXE ブートを活用することによって、素のハードウェアに自動で Ubuntuをインストールすることが出来ます。Software RAID や bonding にも対応している本格的なシステムです。Retty 機械学習基盤では、MaaS を活用することで、自作PCを自動で機械学習基盤クラスタに組み込んでいます。
また、juju は MaaS 以外にも AWS / Azure / GCP といった様々なクラウドシステムに対応しています。Retty機械学習基盤では、スポットで GPU 計算資源が必要になった時にクラウドのスポットリソースを使ってスケールさせています3。
ceph を使った分散ストーレジシステム
ceph は複数のサーバに接続されているストレージを、ネットワークを使って一つのストレージに仮想化することが出来る分散ストレージ・システムです。分散ブロックデバイスとしての使い方が人気で、Retty機械学習基盤でも ceph をブロックデバイスとして利用しています。
(最近、安定版がリリースになった cephfs も一部で利用しています)
corosync / pacemaker を使った NFS サーバクラスタ
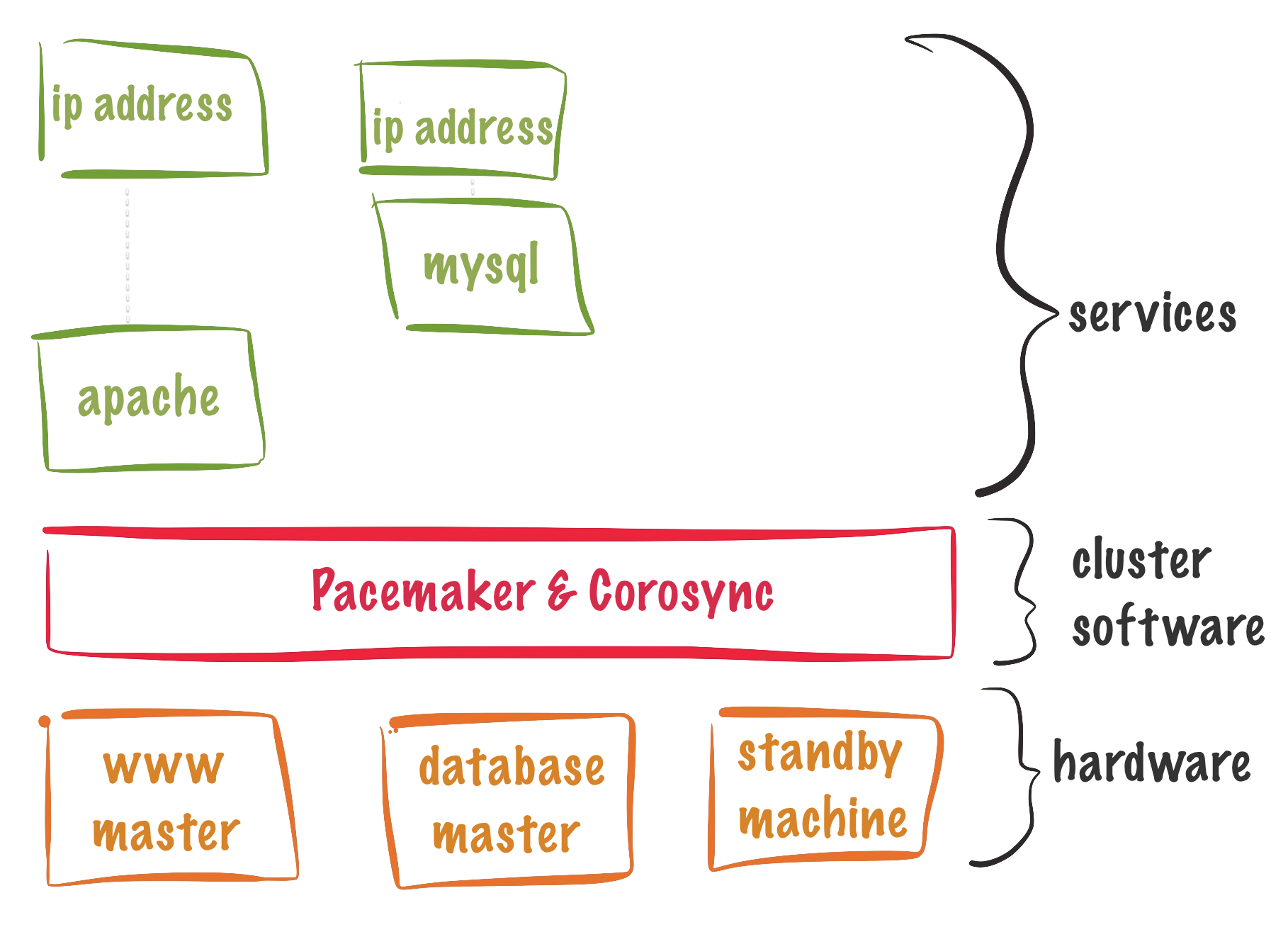
マシンのメンテナンスを行っても止まらない NFS サーバを提供するために、ceph を使ってブロックデバイスを作成し、corosync と pacemaker でシングルマスタ&フェイルオーバする NFS サーバを構築しました。
機械学習に必要なすべてを詰め込んだ Docker イメージ

機械学習をするには、tensorflow / chainer だけでなく、gensim / mecab / cabocha / word2vec / fastText / keras などのいろいろなライブラリやツールが必要で準備が大変です。そこでその大変さを解消すべく、Retty で機械学習するのに必要なすべてのツールを入れた Docker イメージを作っています。ホストマシンに NVIDIA のドライバをインストールしておけば
docker run --privileged -it --rm 192.168.0.1/retty-runtime-anaconda
のようにするだけですぐに機械学習に取り掛かることが出来ます。なお、この Docker イメージは 10G (圧縮して5G) 以上あるため、Retty 機械学習基盤内に Private Docker Registry を用意し、そこからイメージを pull し、起動できるようにしています。これにより、従来70分ほどかかっていた docker pull の時間が 5 分程度に短縮されました。
(↑の機械学習 docker イメージは、CPU だけでも動くので手元の Mac でも動きます)
Kubernetes を使った VXLAN 管理、および Docker コンテナ・スケジュール

上記の Docker イメージに ssh でログインできる機能を追加した Docker (ホーム Docker) を Kubernetes を使って各マシン上で動かしています。仮想ネットワークは flannel によるシンプルな VXLAN で動いています。ホーム Docker はすべてのホストマシンで動ているため、機械学習エンジニアはすべてのマシンにログインすることができます。ホームディレクトリは上記のフェイルオーバ機能の付いたNFSサーバ上に置いてあります。これによって、どのマシンにログインしても機械学習エンジニアは同じファイルにアクセスすることができます。
また Kubernetes 上で Docker を動かしています(Docker in Kubernetes)。これによって、このホーム Docker から docker コマンドや docker-compose などのシンプルな docker 機能を機械学習エンジニアが利用できます。
Retty機械学習基盤の工夫
Retty 機械学習基盤のパフォーマンスや生産性を向上するために、ディスク・ネットワーク・GPU・DB にいくつかの工夫を施しています。
ディスクのパフォーマンス
各マシンに6本のSSDを刺し、合計 30 本の SSD ディスクで分散ストレージを構成しています。 iotop によるパフォーマンス計測では、ceph のリバランス(データの再配置)処理で 1 ノードあたり最大 450 MB/s (3.6Gbps) 程度の書き込みスループットが出ています。ここはもう少し改良の余地があると思いますが、現状の性能要件としては十分な性能が出ています。
ちなみに、Retty 機械学習基盤でメインで使っているマザーボード(z170チップセット)は SATA が6本しかありません。そこで、その6本をすべて ceph に割り当て、システムの起動はSSDディスクを SATA to USB アダプタを使って USB に挿して行っています。したがってディスクは1ノードあたり7本あります。このようにした理由は、ceph ブロックデバイスの利用が増え、ディスク容量が足りなくなってディスクを追加する必要が出たためです。
ネットワークのパフォーマンス
ネットワークは内蔵のイーサポートに加え、Dual ポートギガイーサ PCIe デバイスを差し、3本のボンディングを構成しています。 安価なファンレス L2 スイッチを利用したかったため、リンクアグリゲーションではなく、Adaptive Load Balancing を使って、トラフィックの分散を行っています。

↑のように、マシンの台数に比べてイーサケーブルの数がたくさんあります。
GPU のベンチマーク
tensorflow および chainer が動作する様々な種類のGPUを用意していることから、開発中にベンチマークを取りました。Maxwell アーキテクチャの一部 (GTX 750ti / 970 / 980ti) と Pascal アーキテクチャのコンシューマ向けの大半のモデル (GTX 1050ti / 1060 / 1070 / 1080) を用意しています。その結果、アルゴリズムによって、GPU 毎に性能や省エネ、コスパに差が出ることがわかりました。
ここでは、その一部を紹介させていただきます(なお環境がそろっていないタイミングで計測したデータが多いため、若干比較が難しいところがあります。ご了承ください)。
スピード
1 秒あたりの処理数(アルゴリズムによってバッチの意味が異なったため便宜上処理数と呼んでいます)を計測しました。グラフは train.py と char_cnn.py の2つの学習アルゴリズム毎に各GPUでどれだけのスピードが出ているかを表しています。数値が大きいほど高速です。傾向としては、型番の数字が大きいほど高速であるのですが、train.py の場合、なぜか GTX980Ti だけ非常に高速になりました。
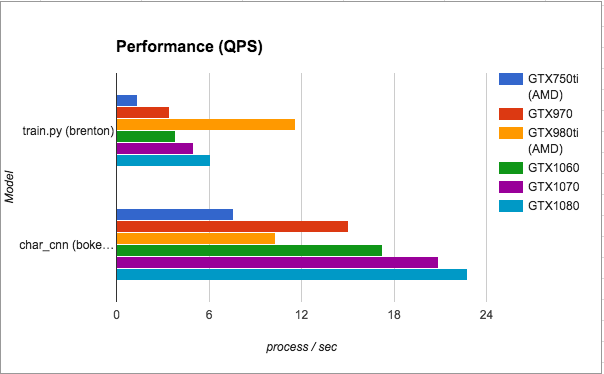
また、char_cnn.py において、GTX980Ti のスピードが遅くなっています。これは計測を行った当時、GTX980Tiは AMD の安価な CPU 上で動いていて、char_cnn.py が CPU センシティブなアルゴリズムであったことが原因と考えられます。train.py では CPU が AMD にもかかわらず最高速で動き、char_cnn.py では 750Ti とあまり変わらないという結果が非常に興味深いです。ここについて深堀したい人を募集しています。
省エネ
エネルギー効率を計測しました。1W・秒あたりの処理数です。
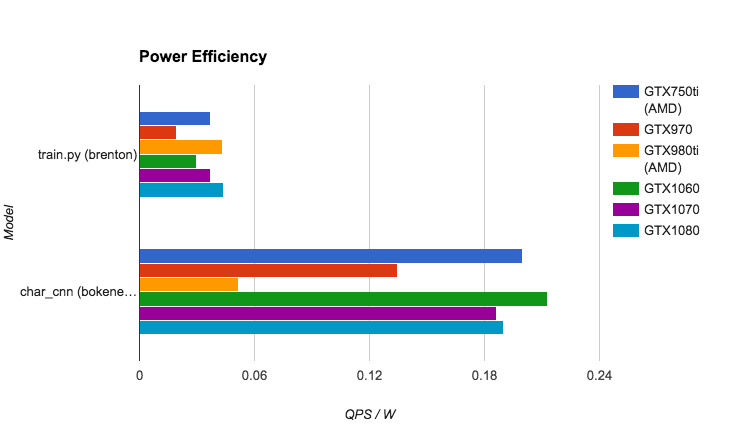
Maxwell の 970 と比べ、Pascal アーキテクチャが全体的にエネルギー効率が良くなっていますが、GTX750Ti が補助電源不要ということもあり、非常に高効率でした。
コスパ
GPU本体価格 (2016/10月前後) と消費電力(実消費電力)からコストを計算しました。1円あたりのイテレーション数です。ただし、GPU は本体価格の変動が激しいため、あまり参考にはならないかもしれません。
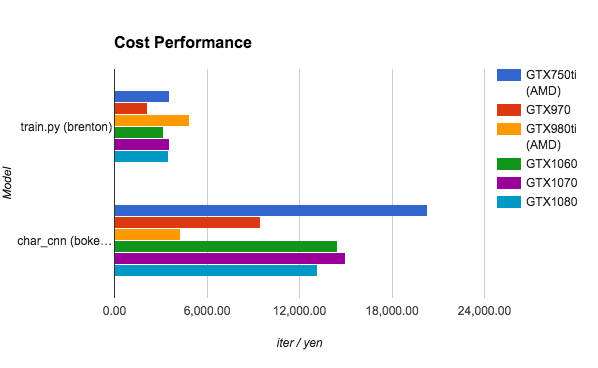
なお、消費電力は市販のワットモニターを用いて目視で計測しました。
その他
その他の特筆すべき点として、Pascal アーキテクチャの電力効率が良くなっています。Maxwell アーキテクチャの場合、電源にかなり気を使わなければいけなかったのですが、Pascal アーキテクチャにしてからは解消しました。
また、コスパに関して、GPUの価格変動が激しく、コスパの順位がタイミングによって大きく入れ替わっていました。例えば、980Ti は5か月で価格が半分まで下落しています。
現状の GPU は発展途上のデバイスで、製品がすぐアウトレットになってしまい、値段が大きく変動するようです。そのため、RettyではGPUを少しずつ購入することで、価格変動リスクを軽減しました。GPU を SaaS で提供する事業者は価格設定が大変ではないでしょうか?
最後に、Retty 機械学習基盤の形がほぼ確定してきたこともあり、あらためてベンチマークを取るフェーズかなと思います。クラウドにスケールする仕組みも作れたので、コンシューマ向け GPU とサーバ向けの GPU の性能比較を行うことも可能です。気になる方はぜひ Retty Advent Calendar を Subscribe してくれたり、または遊びにきてくれたり、はてぶでブックマークしてくれるとうれしいです。学生さんじゃなくてもOKです。
自分専用データベース
機械学習を行うにはデータが必要です。しかも膨大な量です。Retty には公開可能な数百万件の口コミ情報や一千万件近い料理関連写真があり、それらや中間情報を保持した非常に巨大なデータベースがあります。
実験をスムーズに行うためには、このデータベースをもとに自由にいじれる自分専用データベースある方が便利です。しかし、データベースがあまりにも巨大なため、そう簡単に用意することは出来ません。AWS RDS のデータベーススナップショットから自分専用のデータベースを作成するには、半日近くの時間がかかってしまっていてほとんど実現出来ていませんでした。
Retty 機械学習基盤では、ceph のブロックデバイス・スナップショット技術およびクローン技術を活用することで、最大で半日かかっていた自分専用データベースの作成時間を 3 秒に短縮することが出来ました4。約 12,000 倍の高速化です。従来を徒歩の速度とすると、宇宙に脱出する速度に達したことになります。世界が変わりました5。
はまったところ
Retty 機械学習基盤開発中に基盤全体がクラッシュしてしまう問題が発生しました。大きく二つの理由がありました。
CIFS への DoS アタック
開発初期に安価な市販の NAS を使って画像データを置いておいたのですが、機械学習マシンからのアクセス負荷に NAS が耐えられず、CIFS ファイルシステムカーネルモジュールがおかしくなって機械学習マシンの Linux Kernel がすべて Oops を吐いて止まってしまいました。機械学習マシンにモニターを接続しておらず、デバッグが若干大変だったため、kdump をこのタイミングで導入し、調査しました。NFS を導入し、CIFS から卒業したことで解決しました。
ネットワークセグメントが1つかしない
現在の Retty 機械学習基盤はすべてのマシンを同じ 24 ポートファンレスハブに接続しています。これにより、時折ブロードキャストパケットが大量に発生し、その L2 セグメントが使えなくなってしまうことが起こりました(半年で2回ほど)。いまのところは二回なら良いかなという判断でいますが、ここは今後改良する可能性があるところです。
なお、SPOF という観点では、物理ネットワークと電源(含む、オフィスの停電)があるのですが、機械学習基盤が使えなくなったときは、ランチタクシーに乗ったり、グルメ調査費を使ったりして美味しいご飯を食べに行ってるようです。コミュニケーションが活発になるので、むしろ SPOF はあったほうが良いのかもしれません。
Retty機械学習基盤の開発環境
機械学習基盤の開発当初は、機械学習基盤としてサービスを提供しながら、同時に基盤の改良を加えていました。はじめは開発者が1名だったこともあり、それでも十分に回っていたのですが、クラスタを導入し始めたあたりから、開発者が二人になったこともあいまって、改良をスムーズに行うことが難しくなってきました。そこで、「機械学習基盤そのものの開発を行う環境」を新しく用意しました。
こちらは、OS自動配備まで含めた開発ができるように仮想マシンを活用しています。GPU は VT-d によって特定の仮想マシンにデバイスそのものを割り当てる形になります。したがってGPUは一部の仮想マシンでしか使うことはできず、GPUを活用する基盤の開発には若干の制約があります。
仮想マシンの作成

仮想マシン管理には libvirt を使っています。一番のメリットはコマンドラインでの仮想マシン管理がやりやすいことと、RedHat 主体で作っているため多くの Linux ディストリビューションで標準で使えることです。
仮想マシンのプライマリ・ディスクを機械学習基盤の ceph 上に作っています。仮想マシンの作成には virt-install というコマンドラインを使っているのですが、ceph との対応が不十分であったため、機能追加しました。
※ virt-install のライセンスが GPL ですので、こちらのパッチも GPL でのライセンスになります。
diff -ru /usr/share/virt-manager/virtinst/devicedisk.py /usr/local/share/virt-manager/virtinst/devicedisk.py
--- /usr/share/virt-manager/virtinst/devicedisk.py 2015-11-30 20:47:47.000000000 +0000
+++ /usr/local/share/virt-manager/virtinst/devicedisk.py 2016-11-09 05:12:36.513295726 +0000
@@ -464,6 +464,7 @@
"source_volume", "source_pool", "source_protocol", "source_name",
"source_host_name", "source_host_port",
"source_host_transport", "source_host_socket",
+ "auth_username", "auth_secret_type", "auth_secret_uuid",
"target", "bus",
]
@@ -744,6 +745,9 @@
seclabel = XMLChildProperty(Seclabel, relative_xpath="./source")
+ auth_username = XMLProperty("./auth/@username")
+ auth_secret_type = XMLProperty("./auth/secret/@type")
+ auth_secret_uuid = XMLProperty("./auth/secret/@uuid")
#################################
# Validation assistance methods #
@@ -867,6 +871,12 @@
self._change_backend(None, vol_object, parent_pool)
def set_defaults(self, guest):
+ pool = self._storage_backend.get_parent_pool_xml()
+ if pool.source_auth_type != "":
+ self.auth_username = pool.source_auth_username
+ self.auth_secret_type = pool.source_auth_type
+ self.auth_secret_uuid = pool.source_auth_secret_uuid
+
if self.is_cdrom():
self.read_only = True
diff -ru /usr/share/virt-manager/virtinst/storage.py /usr/local/share/virt-manager/virtinst/storage.py
--- /usr/share/virt-manager/virtinst/storage.py 2015-12-24 16:30:15.000000000 +0000
+++ /usr/local/share/virt-manager/virtinst/storage.py 2016-11-05 04:29:29.270748502 +0000
@@ -380,7 +380,10 @@
"capacity", "allocation", "available",
"format", "hosts",
"_source_dir", "_source_adapter", "_source_device",
- "source_name", "target_path",
+ "source_name",
+ "source_auth_type", "source_auth_username",
+ "source_auth_secret_uuid",
+ "target_path",
"permissions"]
@@ -406,6 +409,10 @@
default_cb=_default_source_name,
doc=_("Name of the Volume Group"))
+ source_auth_type = XMLProperty("./source/auth/@type")
+ source_auth_username = XMLProperty("./source/auth/@username")
+ source_auth_secret_uuid = XMLProperty("./source/auth/secret/@uuid")
+
target_path = XMLProperty("./target/path",
default_cb=_get_default_target_path)
このパッチをあてると、以下のようなコマンドライン引数で ceph のブロックデバイスを仮想マシンのプライマリディスクに割り当てることができます。
virt-install --name=hoge --vcpus=4 --memory=4096 --disk rbd:hoge/fuga ...
デスクトップ化
この開発マシンをデスクトップ化して、「Retty機械学習基盤のダッシュボード」としてビジュアライズしています。開発マシンのGPUを使って、50インチ、4Kのモニタを接続し、広大なビジュアル空間で機械学習エンジニアに現在の機械学習基盤の状況をわかるようにしています。

また、HDMIスプリッタを活用して、基盤エンジニアの手元でもダッシュボードが見られるようになっています。

また、それだけではもったいないため、基盤開発者がこのマシン上で基盤を直接開発できるようにしたり、機械学習エンジニアが機械学習ロジックの開発をできるようにしたりしています。
この開発マシンはメモリが128Gあります。そして、機械学習基盤の各マシンと 3Gbps 帯域幅の共有バス(3ポートイーサネット)で繋がっており、あたかもひとつのマシンのようになっております。
つまり、Rettyには**「合計で448GBのメモリを搭載したデスクトップマシン」**があります。「メモリの量=開発生産性に直結」ですから、本当に良い時代になりました。GPU も合計で 12 個、20,000コア以上を搭載したデスクトップマシンです。使ってみたいと思った方は[こちら]
(https://www.wantedly.com/projects/39661#_=_)をご覧ください。
まとめ
最後までお読みいただきありがとうございました。
Retty機械学習基盤は**「エンジニアが24時間好きなだけ定額で 20,000 GPU コアを使えて、500 GBクラスのメモリを搭載し、ミッション・コントロール・センターとして機械学習環境をアメーバのようにクラウド中にスケールさせることが出来るデスクトップマシン」**になりました。
「GPUとはいったい何だろう?」という状態から開始したプロジェクトでしたが、「市場最安値のパーツを調達し、あとはオープンソース・ソフトウェアと技術で解決する」という制約をもうけ、様々な PDCA を回しました。機械学習基盤の作成を通して、機械学習基盤以外にも応用可能なサーバサイド技術の発明にもつながっています。Retty によるオープンソース・コミュニティ活動も動き始めました。
学生時代に朝5時に電気屋に並んで先着1名限定のビデオデッキを980円で購入したり、一ヶ月のガス料金800円で生活したりしてきた、小生としても今回のローコスト開発はかなり良い結果だったのではないかと思います(この価格なら一人一セット割り当ても可能)。
そして、その間に、Rettyの収益力も大幅に強化され、テクノロジーへの投資予算が増えてまいりました。来年はいよいよテクノロジーに対する投資をさらに何歩も進めるフェーズになります。Rettyではこの収益をテクノロジーの源泉である「エンジニア」に還元、投資強化をしていきます。
**「メモリ500GBのビッグデータ処理デスクトップマシン」を思う存分活用したい機械学習エンジニアの皆さん、そして「アメーバのようにクラウド中にスケールする機械学習基盤」**にさらなるイノベーションを起こしたいサーバサイドエンジニアの皆さん。Rettyは「食を通じて世界中の人々を Happy に」というビジョンのもと、「飲食店情報の世界のインフラ」を目指して、今後もフルスロットルで技術開発を進めていきます。
最後まで、お読み頂きましてありがとうございました。かなりマニアックなテイストに振りましたが、この記事が日本で機械学習を志す若者へのクリスマス・プレゼントになることを願っています。また少しでも当社に興味を持っていただければ幸いです。続きはこちらで。それではみなさん、良いお年をお迎えください。
おまけ
当社エンジニアでPCゲームマニアの Yuta が初号機を組み立てている様子

開封したところ

完成

GTX 1080 抽選会で抽選に外れ、悔しがってる社員エンジニア、インターン生、機械学習もくもく会参加者

2016/12/25 12:41: 画像が見えなくなっていた問題を修正しました。
-
若干堅苦しい表現ですが、つまり「基盤 PDCA のために1台ずつマシンが止まる可能性があるけど、ファイルはマシン間で共有されてるので、チェックポイントなどをきちんと実装して、他のマシンから学習が復帰可能なように作ってね」という意味です。一見乱暴な話に聞こえますが、このアーキテクチャを使いこなすことがローコストでテクノロジーのイノベーションを加速することに繋がります。こちらも参考にしてください: https://cloudplatform-jp.googleblog.com/2015/05/vm-3-vm.html ↩
-
akiba とは Retty 機械学習基盤のロールの名前です。 ↩
-
例えば、AWS Tokyo リージョンにおける g2.2xlarge のスポットインスタンス価格は 2016/12/20 時点で約 $0.15/h 程度です。 ↩
-
なお、現在のところ ceph ブロックデバイスを扱う Linux カーネルモジュールでは、スナップショットを使ったクローンブロックデバイスを扱うことが出来ないため、自分専用DBは仮想マシンを間に挟んで実現しています。 ↩
-
クラウド・ネイティブな会社にいる事で、インフラ・コア技術の動向に関して若干浦島太郎な状態だったのですが、やはりコア技術の様々な選択肢を応用して、丁寧に最適化すれば、革命的な事業インパクトをおこせることがわかりました。今後も全方面に対する最新技術の応用を積極的に行い、事業を加速していきたいと思います。 ↩