はじめに
ここ数日ELKStackというものについて勉強したのでですが、1つで解決する記事が見当たらなかったので、残しておこうと思います。
バージョンが上がったせいのか、一筋縄ではいきませんでしたね。ええ。
特にKibana。
これがなかなか厄介でした。
さて、苦労話はこの辺にして、久しぶりの執筆はズバリELKStackです。
なんじゃそりゃ?と思う方もいるでしょうが、それらは後述していきます。
目次
この記事の目次です。
必要なところだけピックアップしてください。
- ELKStackとは
- Elasticsearch
- Elasticsearchの基本的な使い方
- Logstash
- Logstashの基本的な使い方
- Kibana
- Kibanaの基本的な使い方
- EX
- FilebeatとLogstashの連携
- Logstashでオリジナルフォーマットの読み込みを定義して使う
- Logstashで複数のファイルからログを抽出
ELKStackとは
筆者自身もよくわかっていないのですが、Elastic社による製品、Elasticsearch、Logstash、Kibanaを組み合わせた解析環境?のことです。
とりあえず私はログ解析にかかる時間を削減しようと思い、勉強してみました。
それぞれの概要や役割は後述しますが、これらを使うとサーバログやアプリケーションログがサクッと整理できたりします。
それぞれの役割
前述したように、ELKStackとはElastic社による製品を組み合わせた解析環境です。
それぞれの概要と、今回のケースにおける役割をざっと記載しておきます。
| 製品 | 概要 | 今回のケースにおける役割 | 使用するバージョン |
|---|---|---|---|
| Elasticsearch | No SQL?によるDB機能を持つ検索エンジンです。 データ解析やなんやらで有名企業の社内システムなどで導入されているようです。 |
Logstashが抽出したデータを蓄積し、検索したい条件に合わせて蓄積したデータを検索します。 | 7.16.3 |
| Logstash | ログ収集ツールです。 DBやファイルからログを収集、変換してElasticsearchにデータを投入します。 ログでなくてもデータは収集できるのですが、その名の通りログの収集に使われることが多いようです。 |
左記のとおり、アプリケーションログファイルの内容を抽出、変換し、Elasticsearchに投入します。 | 左記のとおり、アプリケーションログファイルの内容を抽出、変換し、Elasticsearchに挿入します。 |
| Kibana | Elasticseachが蓄積したデータを可視化する画面機能です。 KQLと言う独自言語でElasticsearch内に蓄積したデータを検索したり、統計を取ってグラフ化したりいろんなことができます。 |
収集したログデータから一部を抽出し、可視化します。 | 7.16.3 |
今回はこれらを一気に構築しますが、言わずもがな、それぞれで構築して独自アプリに使ったりもできますので、興味のある方はこれを機に色々試してみてください。
以降、製品ごとにインストール、設定を章立てとして紹介していきます。
Elasticsearch
Elasticsearchの環境構築
まずは、Elasticsearchの動作環境を構築します。
ダウンロード
こちらから環境に合わせたファイルをダウンロードします。
今回はWindowsで紹介するので、Windows版をダウンロードします。
LogstashとKibanaも同じところからダウンロードできるので、ダウンロードしておきましょう。
あと、Javaが入っていないと動きませんので、入っていない場合はJava8以上をインストールしておきましょう。
インストール
先にダウンロードしたZipファイルを解凍するだけでインストールは完了です。
あとは<解凍したフォルダ\bin>フォルダにあるelasticsearch.batを実行すれば起動します。
※これ以降は解凍したフォルダをELASTIC_HOMEとします。
Elasticsearchの設定
起動自体は何もしなくてもできますが、今回はKibana環境も構築するので、KibanaからElasticsearchの中身を直接いじれる設定を入れておきます。
設定ファイルは、最初はすべてコメントアウトされていて有効な行はありません。
構築する環境に合わせてホストやポート番号は変更しましょう。
今回は、コメントの後の最終行に、「http.cors.enabled: true」と追記してください。
■変更するファイル
ELASTIC_HOME\elasticsearch.yml
■追記する内容
http.cors.enabled: true
# この行以外はすべてコメントです。
# 必要なければ消してもいいですし、ポート番号など必要応じてコメントを復活し、内容を変更しましょう。
http.cors.enabled: true
設定を何も変更しない場合は、以下の設定で起動します。
- 動作するホスト:localhost
- ポート番号:9200
Zipファイルを解凍した後のツリーをこちらに記載しておきます。
ELASTIC_HOME
│
├─bin
│ elasticsearch.bat
│ ・・・省略
│
├─config
│ │ elasticsearch-plugins.example.yml
│ │ elasticsearch.keystore
│ │ elasticsearch.yml ★変更する設定ファイル
│ │ jvm.options
│ │ log4j2.properties
│ │ roles.yml
│ │ role_mapping.yml
│ │ users
│ │ users_roles
│ │
│ └─jvm.options.d
├─data
│ ・・・省略
│
├─jdk
│ ・・・省略
├─lib
│ ・・・省略
├─logs
│ ・・・省略
│
├─modules
│ ・・・省略
│
└─plugins
起動
Elasticsearchを起動しましょう。
起動方法は簡単で、ELASTICK_HOME\bin\elasticsearch.batを実行するだけです。
起動後の確認
ここからは起動確認や、テストデータ投入などをやっていきますが、この辺りはかの有名企業のブログこちらの方が詳しく説明されています。
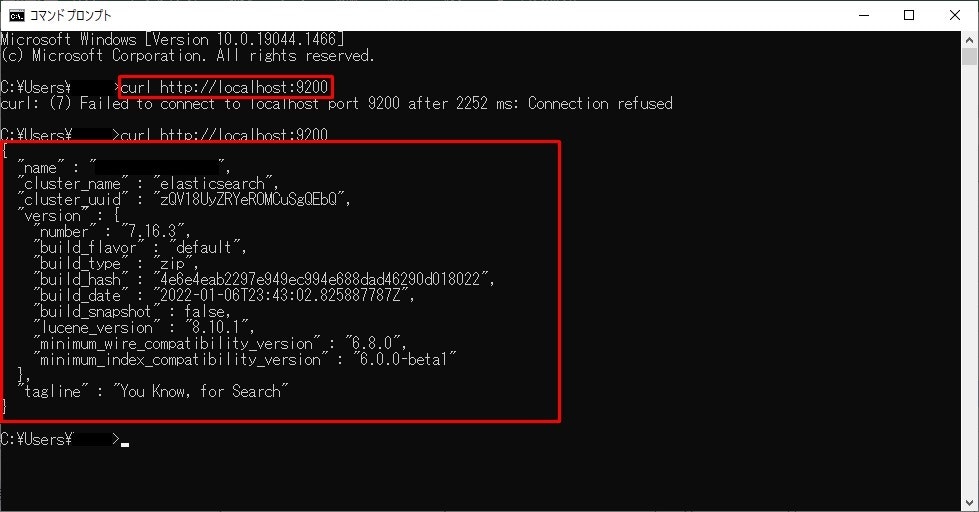
バッチで起動したら、コマンドプロンプトを起動し、curl http://localhost:9200とコマンドを実行してみましょう。
このような出力が得られれば無事起動し、実行中状態です。
サンプルデータの登録
Elasticsearchにサンプルデータを登録してみましょう。
ElasticsearchにはWebサーバ機能が同梱されていて、REST APIによる操作が可能で、起動しているホストとポートにHTTPリクエストを送ることでデータが登録や検索ができます。
Bodyの形式はJsonです。
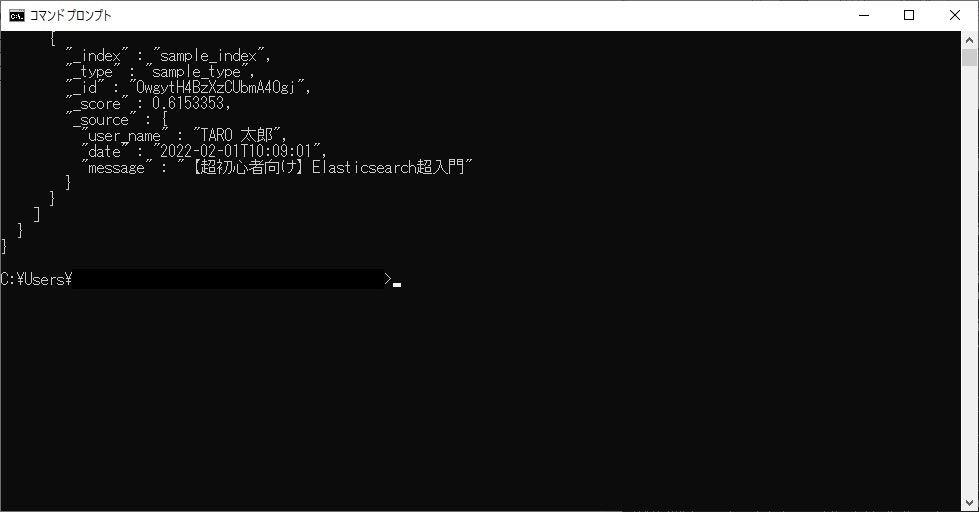
以下のファイルを用意し、さっそくデータを登録してみましょう。
{
"user_name": "TARO 太郎",
"date": "2022-02-01T10:09:01",
"message": "【超初心者向け】Elasticsearch超入門"
}
Body以外のリクエスト情報は以下です。
- メソッド:Post
- リクエスト形式:http://ホスト:ポート/index/type[/?pretty] ※末尾に「?pretty」をつけると、返却値のJsonが整形して返却されます。
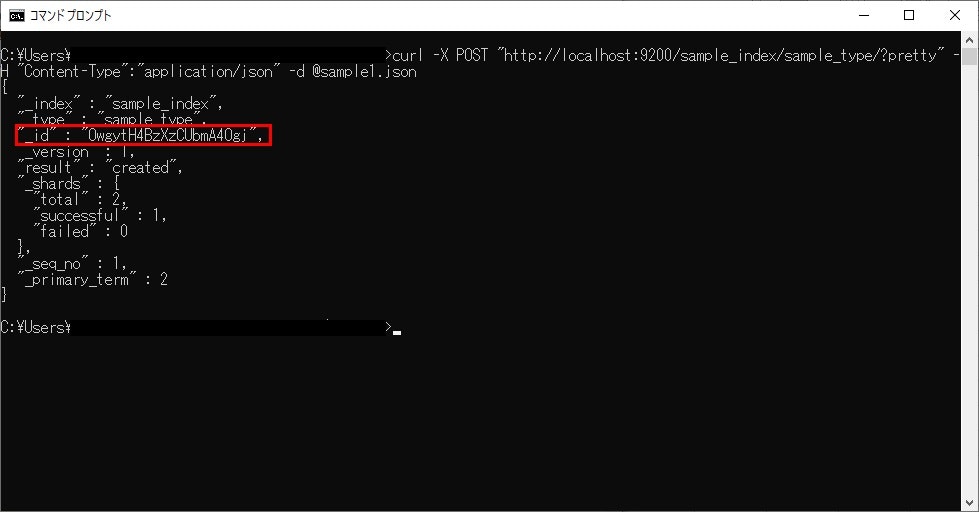
- URL:http://localhost:9200/sample_index/sample_type/?pretty
- ヘッダ:“Content-Type”:”application/json”
上記の情報でリクエストします。
次のイメージのような出力が得られれば登録成功です。
返却値のidは後で必要になるので控えておきましょう。
サンプルデータの検索
登録したサンプルデータ検索してみましょう。
検索はGETリクエストにより行います。
- メソッド:GET
- リクエスト形式:http://ホスト:ポート/index/type/id[?pretty] ※idの部分は、データ登録時の返却値を指定しましょう。
- URL:http://localhost:9200/sample_index/sample_type/OwgytH4BzXzCUbmA4Ogj?pretty
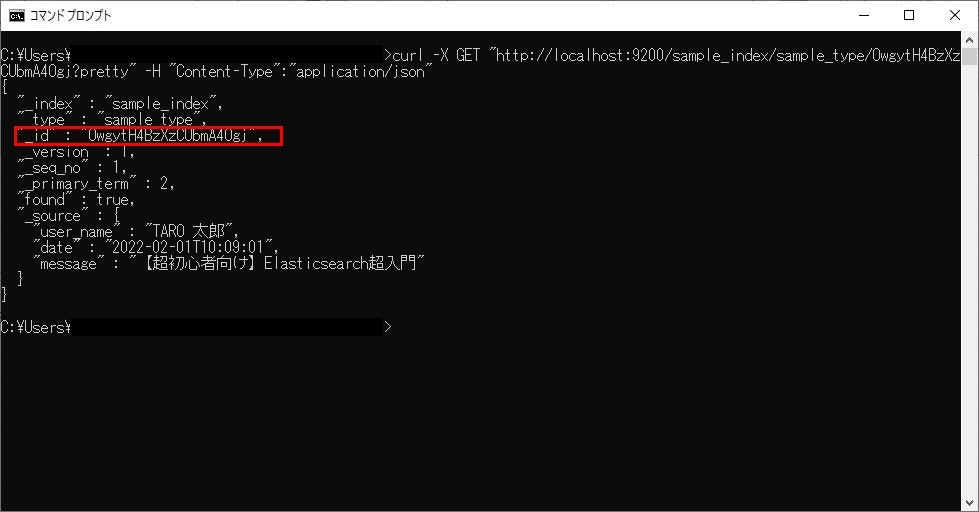
先ほど登録したーデータが取得できました!
Elasticsearchは検索エンジンなので、当然あいまい検索もできます。
あいまい検索をする場合は、Json形式で条件をリクエストしましょう。
{
"query": {
"match": {
"message": "超入門"
}
}
}
- メソッド:GET
- リクエスト形式:http://ホスト:ポート/index/type/_search[?pretty] ※indexの部分は、データ登録時ものを指定しましょう。
URL:http://localhost:9200/sample_index/sample_type/_search?pretty
検索条件にヒットし、登録したデータが取得できました!
Elasticsearchまとめ
Elasticsearchの環境構築と基本的な使い方はここまでです。
これまでのポイントをまとめておきます。
- インストールは解凍するだけ
- Kibanaから直接いじれる設定を入れる ※ここではまだ威力を発揮していません
- elasticsearch.batで起動
- JsonのREST APIを使用してデータの登録や検索が可能
次章はLogstashです。
構築したElasticsearchの実践編に入りますので、お楽しみに。
Logstash
Logstashとは
様々な形式のログを抽出、解析し、Elasticsearchにデータを登録する製品です。
テキストはもちろん、CSV、DBからのデータ、果てはExcelからもデータが取り込めるらしいです。
極めればどれくらい威力を発揮するかは筆者もまだわかっていません。
試してみたぜ!という方いらっしゃいましたら、ぜひコメントください。
Logstash環境構築
ここからLogstashの動作環境を構築していきます。
ダウンロード
先の章でElasticsearchと一緒にダウンロードしていますので、ここでの記載は省略します。
インストール
Elasticsearchと同様、ダウンロードしたファイルを解凍するだけです。
ただし、こちらは設定を整えてからでないと起動できません。
まずは設定ファイルを整えていきますが、一旦解凍後のツリーを記載しておきます。
※こちらも解凍したフォルダを以降はLOGSTASH_HOMEとします。
LOGSTASH_HOME
│ CONTRIBUTORS
│ Gemfile
│ Gemfile.lock
│ LICENSE.txt
│ NOTICE.TXT
│
├─bin
│ logstash.bat
│ ・・・省略
│
├─config
│ jvm.options
│ log4j2.properties
│ logstash-sample.conf
│ logstash.yml
│ pipelines.yml
│ startup.options
│
├─data
├─jdk
│ ・・・省略
├─lib
│ ・・・省略
├─logstash-core
│ ・・・省略
├─logstash-core-plugin-api
│ ・・・省略
├─tools
│ ・・・省略
├─vendor
│ ・・・省略
└─x-pack
・・・省略
サンプルの準備
まずは、最も単純で基本的な設定でLogstashというものを動かしてみます。
設定の前に、サンプルで読み込ませるファイルを用意しておきます。
任意の配置先に、以下の内容のファイルを作ります。
※サンプルは2つ用意しますが、1つでも問題ありません。
Date,Level,ErrorMessage,UserIde
2022-01-31 10:00:00,INFO,1-1情報です,1
2022-01-31 11:00:00,ERROR,1-1エラーです,1
2022-01-31 10:00:00,INFO,2-1情報です,1
2022-01-31 11:00:00,ERROR,2-1エラーです,1
2022-01-31 12:00:00,WARN,2-1警告です,1
2022-02-01 10:00:00,ERROR,2-2エラーです,1
2022-02-01 11:00:00,ERROR,2-3エラーです,1
2022-02-01 12:00:00,ERROR,2-4エラーです,1
Logstashの設定
サンプルができましたので、読み込ませるための設定をしていきます。
LOGSTASH_HOME\configにあるlogstash-sample.confをコピーし、その中を変更していきましょう。
ファイル名は「csv-sample.conf」とします。
Logstashの設定ファイルは、Jsonライクに定義していきます。
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
# 入力の設定
# ここではファイルを使用しますが、標準入力から受け付けたりもできます。
input {
file {
# 末尾を読み込むモード
mode => "tail"
# 対象ファイル
# Windowsでも"/"を使う
path => ["C:/Users/tarosa/Desktop/Elastic/sample/csv/*.csv"]
# ファイルのどこまで読み込んだか記録しておくファイル
# ここではLOGSTASH_HOMEに配置しています
# なくても動くかも?
# 拡張子は「.sincedb」
sincedb_path => "../csv-sample.sincedb"
# 読み込み開始位置など
start_position => "beginning"
codec => plain {
charset => "UTF-8"
}
}
}
# ファイルのフォーマットに合わせた解析設定
filter {
csv {
columns => ["Date", "Level", "ErrorMessage", "UserId"]
convert => {
# フィールドのデータはここで任意に変換できます
"UserID" => "integer"
}
# ヘッダー行を読み飛ばし
skip_header => true
}
# 取り込み後タイムスタンプを判定する行を指定します
date {
match => ["Date", "yyyy-MM-dd HH:mm:ss"]
}
}
# 出力先の設定
output {
# Elasticsearchに設定
# 構築したElasticsearchに合わせます
elasticsearch {
hosts => ["http://localhost:9200"]
index => "csv-sample"
}
# デバッグ用に標準出力にも出力しておきます
stdout {
codec => rubydebug
}
}
設定以外は省略しますが、設定後のツリーは以下のようになります。
LOGSTASH_HOME
│ ・・・省略
├─bin
│ logstash.bat
│ ・・・省略
│
├─config
│ jvm.options
│ log4j2.properties
│ logstash-sample.conf
│ logstash.yml
│ pipelines.yml
│ startup.options
│ csv-sample.conf ★このファイルを新規作成
│
├─data
├─jdk
│ ・・・省略
├─lib
│ ・・・省略
├─logstash-core
│ ・・・省略
├─logstash-core-plugin-api
│ ・・・省略
├─tools
│ ・・・省略
├─vendor
│ ・・・省略
└─x-pack
・・・省略
Logstash起動
設定とサンプルデータが完成したところで、いよいよLogstashを起動します。
起動後すぐにファイルの読み込みが始まりますので、Elasticsearchは起動しておきましょう。
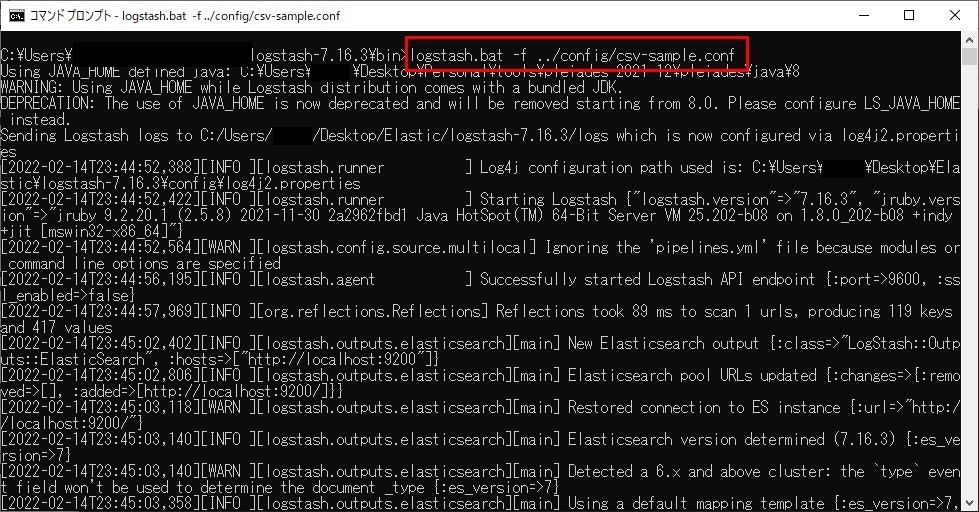
起動は、「logstash.bat」を使用しますが、引数に設定ファイルを指定します。
今回の場合、コマンドプロンプトを起動し、以下のコマンドで起動します。
コマンド:logstash.bat -f ../config/csv-sample.conf
実行するとすぐ取り込みが始まります。
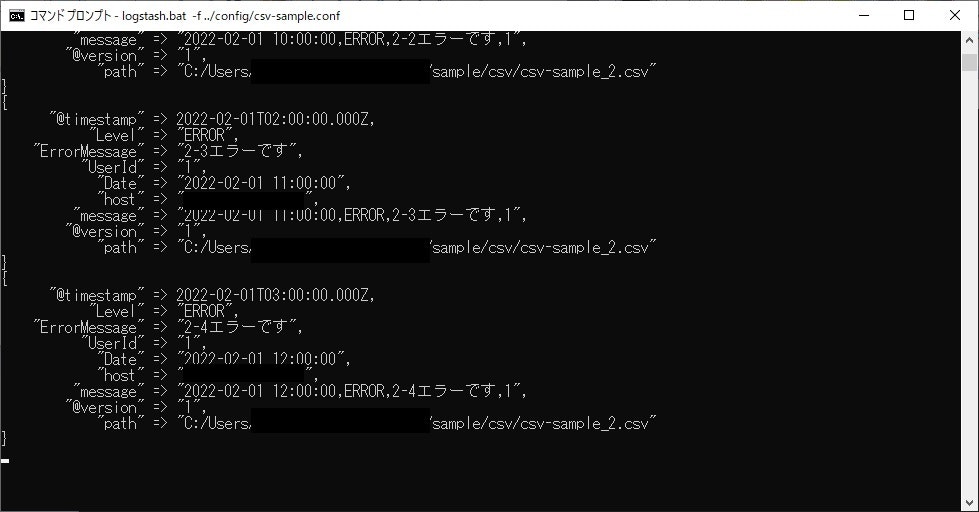
しっかり登録できましたね!
Logstashまとめ
Logstashの環境構築と基本的な使い方の紹介はここまでです。
ここまでのポイントをまとめておきます。
- インストールは解凍するだけ
- Jsonライクに設定を追加
- logstash.batで起動
ここまでで、ログデータを蓄積するデータベースの構築、登録までができました。
次章から、蓄積したデータを活用する方法を紹介していきます。
Kibana
Kibanaとは
Elasticsearchに蓄積したデータを可視化できるGUIツールです。
画面はWEBアプリで、ブラウザを使用します。
KQLという言語になりますが、Logstashで蓄積したログデータをはじめ、Elasticsearchに蓄積しているデータであれば、なんでも検索したり、グラフ化したりできます。
Kibana環境構築
ここからKibanaの環境を構築していきます。
ダウンロード
先の章でElasticsearchと一緒にダウンロードしていますので、ここでの記載は省略します。
インストール
他の製品同様、ダウンロードしたファイルを解凍するだけです。
ただし、こちらは設定を整えてからでないと起動できません。
まずは設定ファイルを整えていきますが、一旦解凍後のツリーを記載しておきます。
※こちらも解凍したフォルダを以降はKIBANA_HOMEとします。
KIBANA_HOME
│ ・・・省略
│
├─bin
│ kibana-encryption-keys.bat
│ kibana-keystore.bat
│ kibana-plugin.bat
│ kibana.bat
│
├─config
│ kibana.yml
│ node.options
│
├─data
├─node
│ node.exe
│
├─node_modules
│ ・・・省略
│
├─plugins
├─src
│ ・・・省略
ほぼほぼ省略ですが、大事なのはbinとconfigだけです。
起動前の設定
Kibanaの設定ですが、Elasticsearchがデフォルトの構成であればほぼ必要はありません。
ただ、デフォルトでは設定のすべてがコメントアウトされているので、Elasticsearchのホスト、ポートのコメントアウトを復活させます。
KIBANA_HOME\configにあるkibana.ymlを編集します。
■変更するファイル
KIBANA_HOME\config\kibana.yml
■編集する内容
Elasticsearchのコメントアウトを復活します。
必要に応じてホストやポートは書き換えましょう。
#elasticsearch.hosts: ["http://localhost:9200"]
↓
elasticsearch.hosts: ["http://localhost:9200"]
elasticsearch.hosts: ["http://localhost:9200"]
Kibanaの起動
こちらもバッチファイルを起動するだけです。
Logstash同様、Elasticsearchは起動しておきましょう。
KIBANA_HOME\bin\kibana.batを使用し、さっそく起動しましょう。
※出力が多すぎるのでコンソールイメージは割愛します。
Kibanaにアクセス
コンソールに長い文字列が表示され、そろそろ動き出したかな?と思ったら、ブラウザからKibanaにアクセスしましょう。
デフォルトでのアクセス先URLは「http://localhost:5601」です。
ホストやポートなど変更している場合は適宜修正してください。
ページが表示されれば、起動は完了しています。
初回はウェルカムページが表示されますが、2回目以降は出ません。
ここでは割愛しますが、チュートリアルもありますので、興味のある方はやってみてください。
■アクセス後のウェルカムページ
その後の操作
さっそく使っていきましょう。
まずは、「Explore on my own」ボタンから次に進んでいきましょう。
ホーム画面に遷移します。
■ホーム画面
カスタマイズ
いよいよ本番です。
Kibanaを自分好みにカスタマイズしていきます。
インデックスパターンの作成
まずは、ElasticsearchのデータをKibanaから読み込めるようにします。
それにはまずインデックスパターンというものを作成するのですが、この行為が省略されている記事が多く、筆者はここでハマりました。
いろんな記事で「here」リンクを押すと一言あるのですが、今見ている画面を見れがお分かりでしょう。
そう、ないんです。
「いや、ねえよ!」と。
ここにたどり着くまでになかなかの時間を要しました・・・
さて、気を取り直してインデックスパターンを作成します。
ここからはKibanaの画面ベースで紹介していきます。
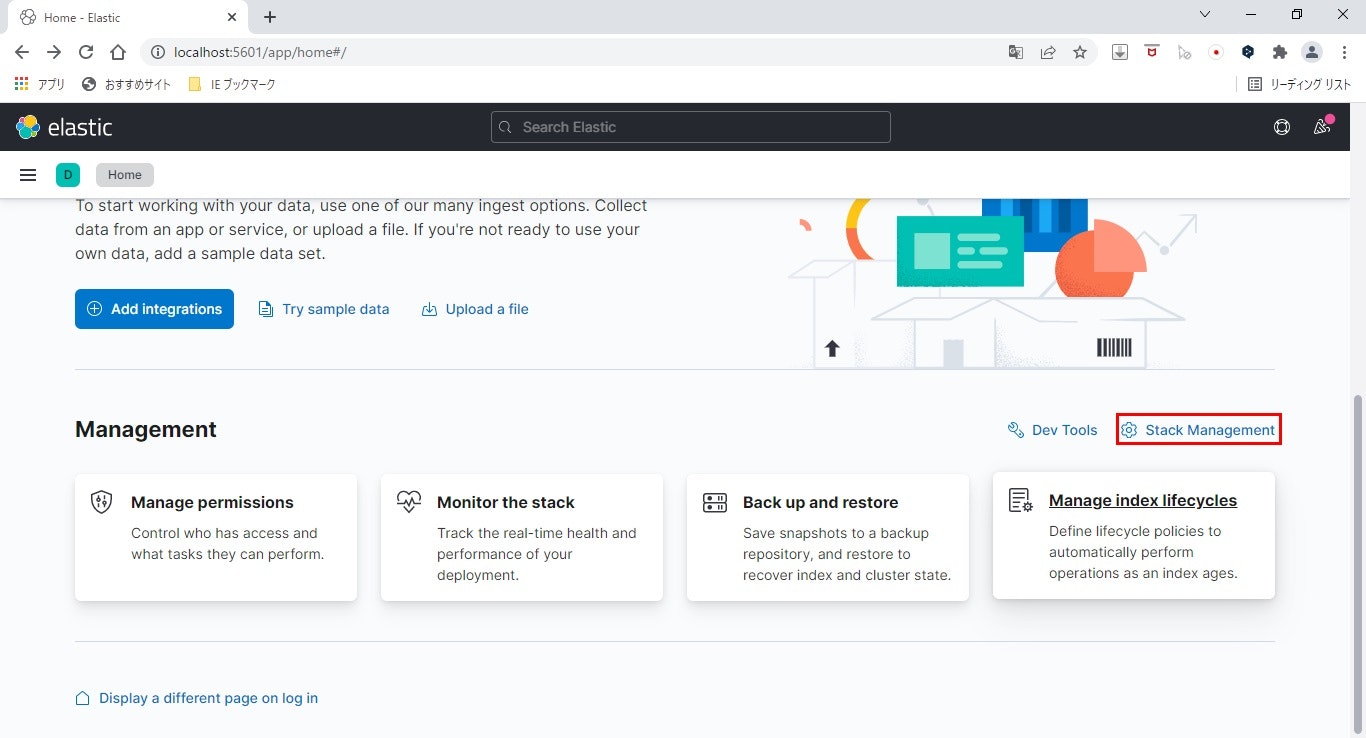
- Stack Managementを表示
画面下部の「Stack Management」リンクをクリックします。
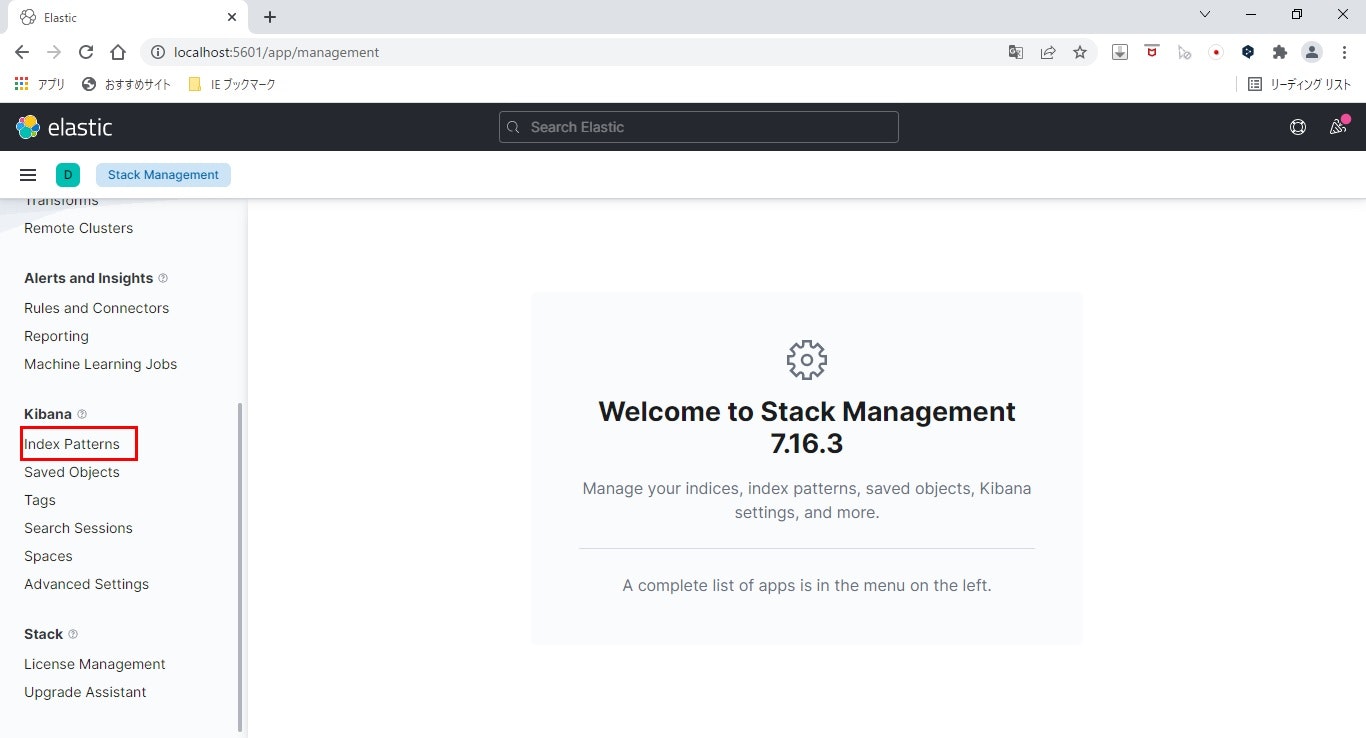
- インデックスパターン画面を表示
左メニューの「Index Patterns」をクリックします。
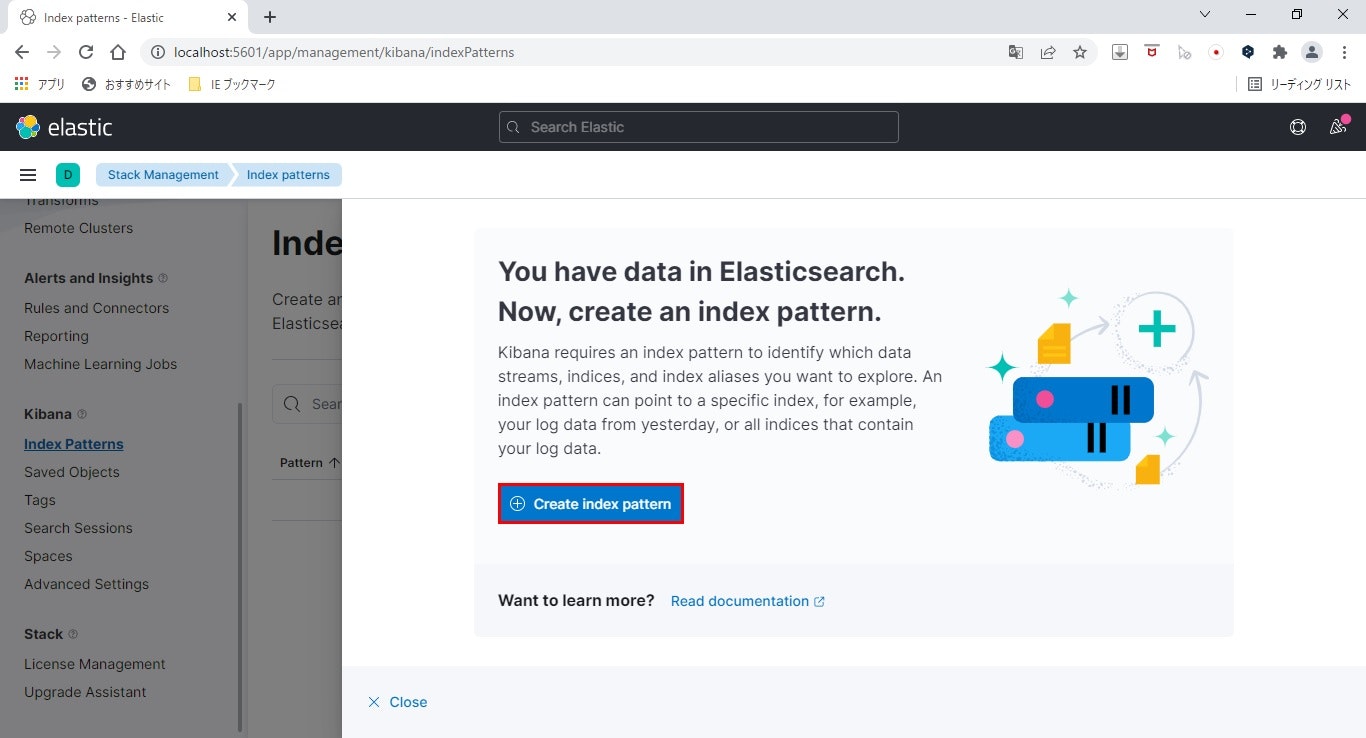
- インデックスパターン作成画面を表示
横からシュッと表れた「Create Index Pattern」をクリックします。
- 作成したインデックスを確認
右側にLogstashで作成したインデックス「csv-sample」が確認できます。
ここにインデックスが表示されない場合は、Logstashでのデータ登録に失敗していますので、Logstashの取り込み設定を見直し、再度取り込んでみてください。
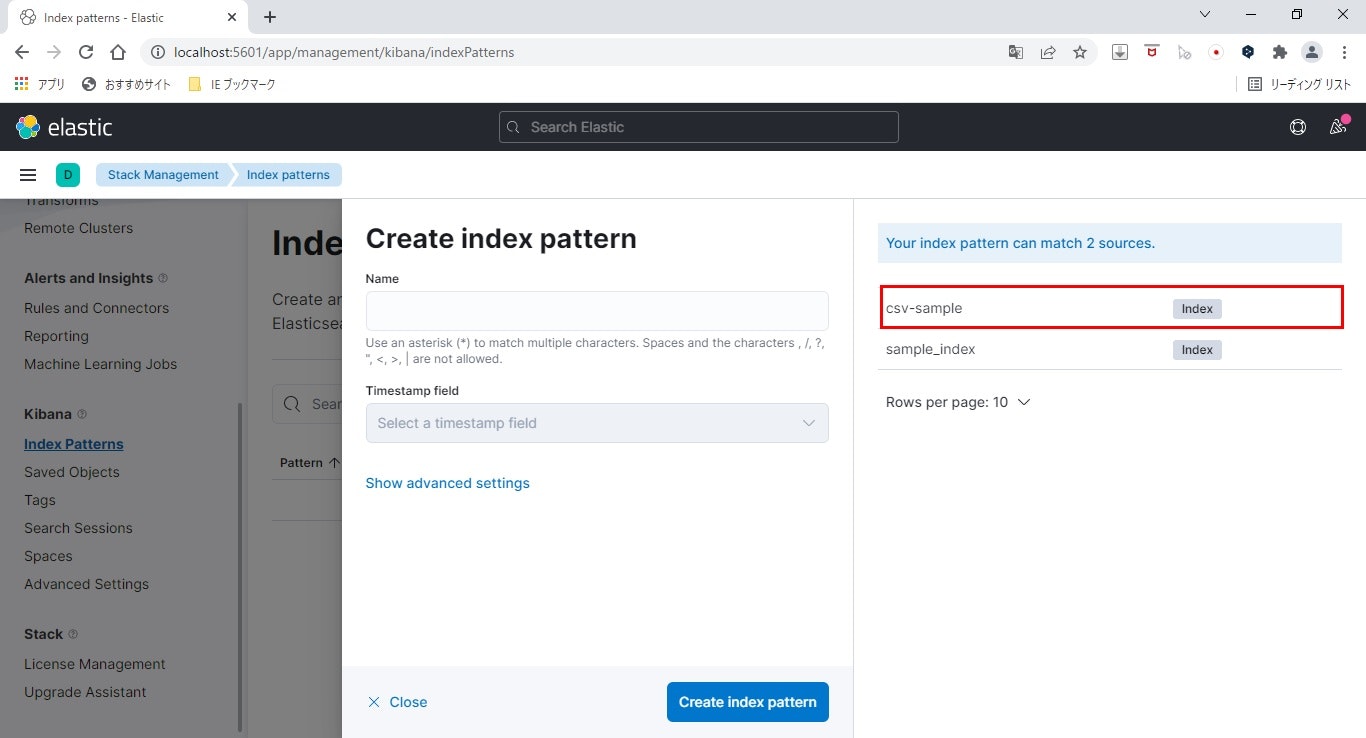
- インデックスパターンを作成
テキストボックスに「csv」と入力>ドロップダウンから@timestampを選択>Create index patternをクリックします。
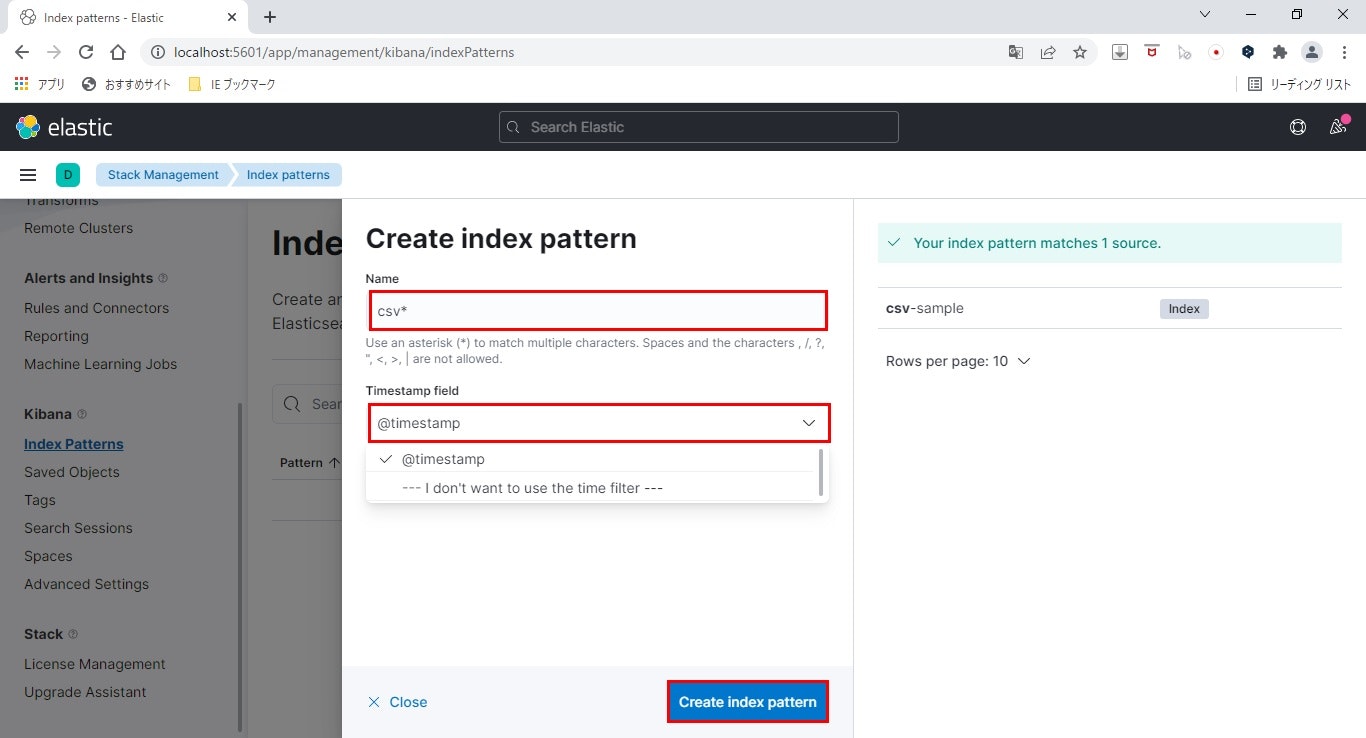
- 作成したインデックスパターンを確認
画面左上のIndex patternsをクリックします。
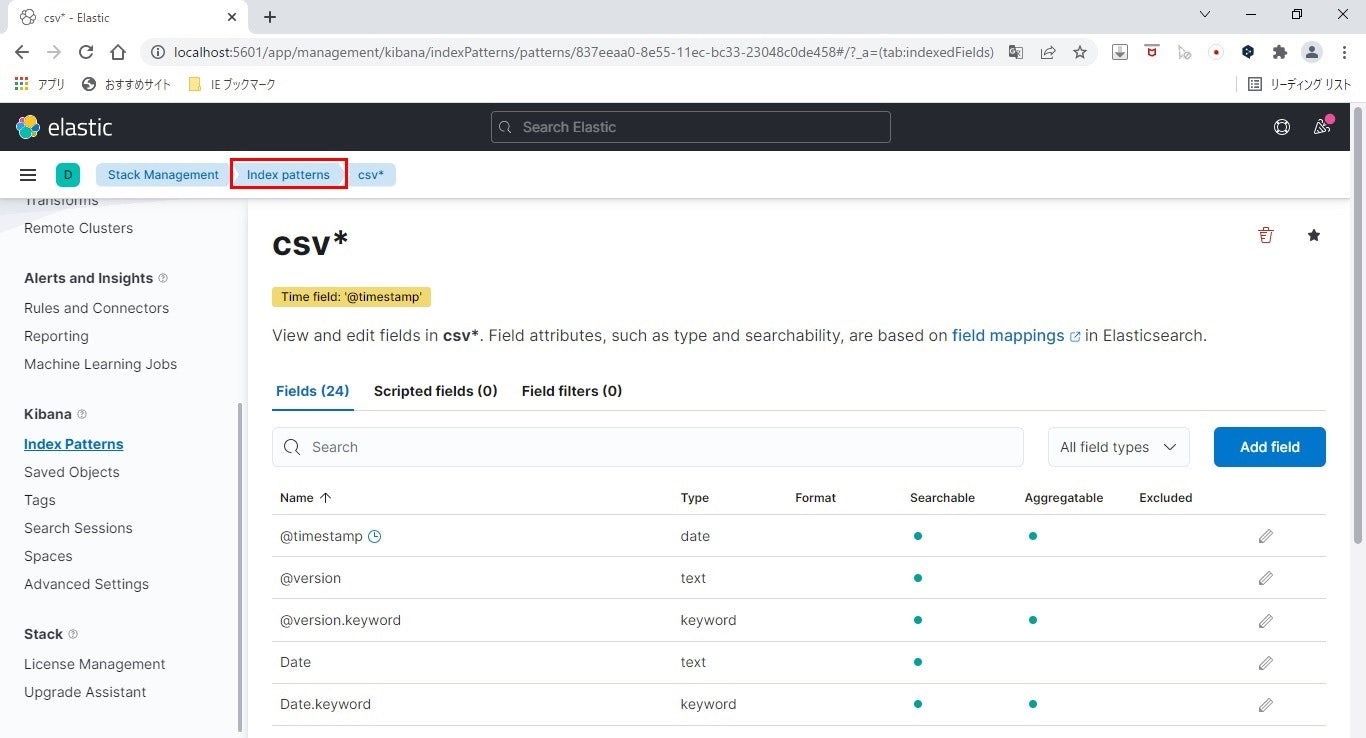
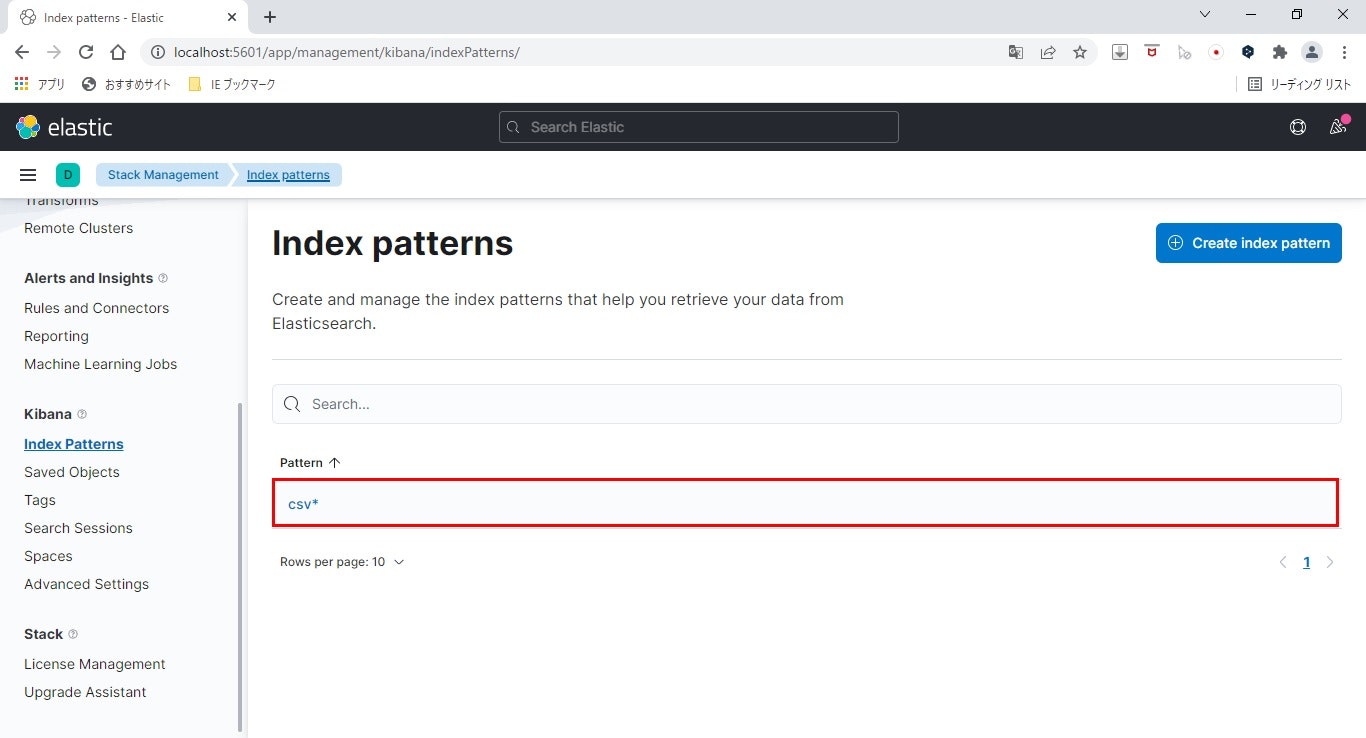
- 登録完了
作成したインデックスパターンが一覧に表示され、作成できたことが確認できます。
KQLで検索
Kibana上でデータを見る準備はできましたので、さっそく見てみましょう。
まずは、KQLという検索用言語を使って見てみます。
-
開発ツールの表示
左メニュー下部の「Dev Tools」をクリックします。
-
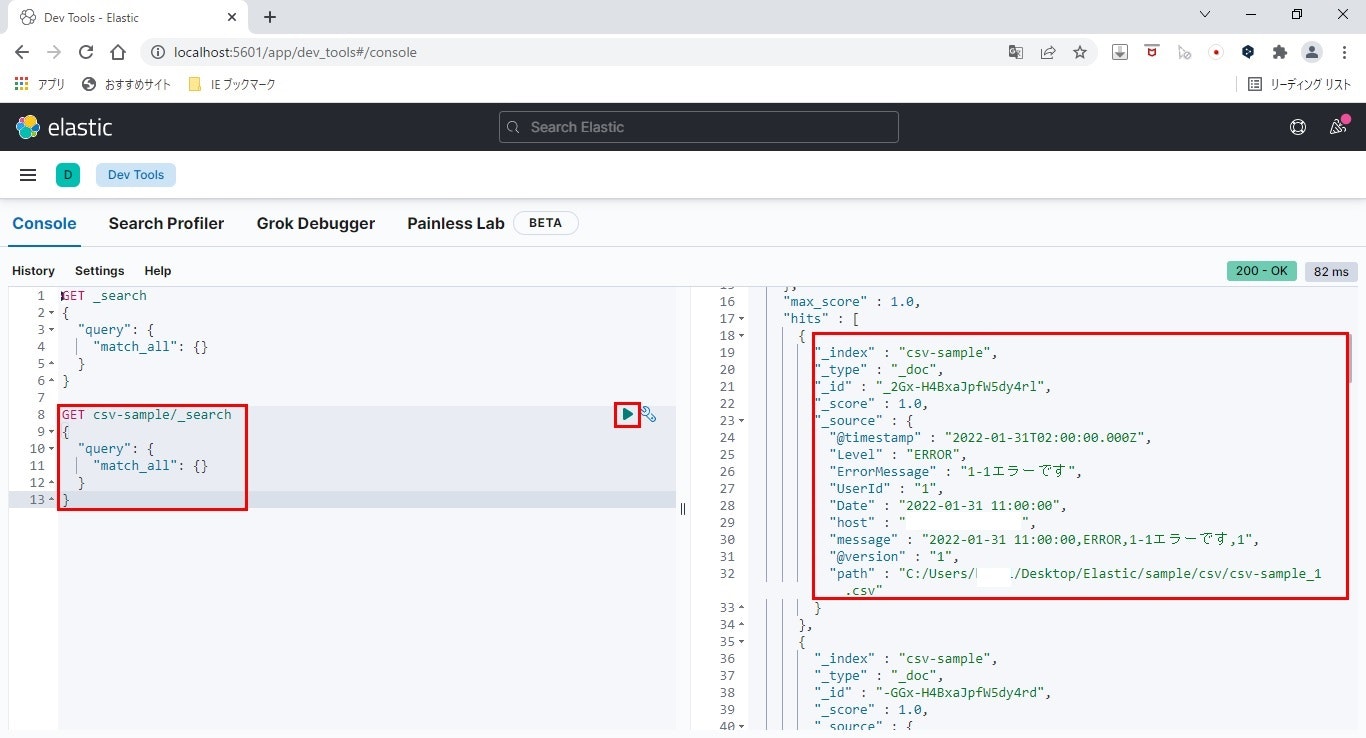
クエリを使用して検索
テキストボックスに以下のクエリを入力し、再生ボタンをクリックします。GET csv-sample/_search { "query": { "match_all": {} } } -
検索結果の確認
右側にcsv-sampleで登録した内容が表示され、登録した内容が確認できます。
ダッシュボードの作成
ここまでで、KibanaからElasticsearchに登録したデータを参照するところまでできました。
しかし、こんなJsonの状態ではGUIツールの意味がないですよね。
そこで、ダッシュボードというものを作成し、ビジュアライズします。
- ダッシュボードを表示
左メニュー上部の「Dashboad」をクリックし、ダッシュボード画面を表示します。
- 編集画面を表示
「Create new dashboard」をクリックし、編集画面を表示します。
- ビジュアライゼーションの作成
ダッシュボード内の一つの要素、ビジュアライゼーションを作成します。
「Create visuallization」をクリックし、編集画面を表示します。
- タイプを選択
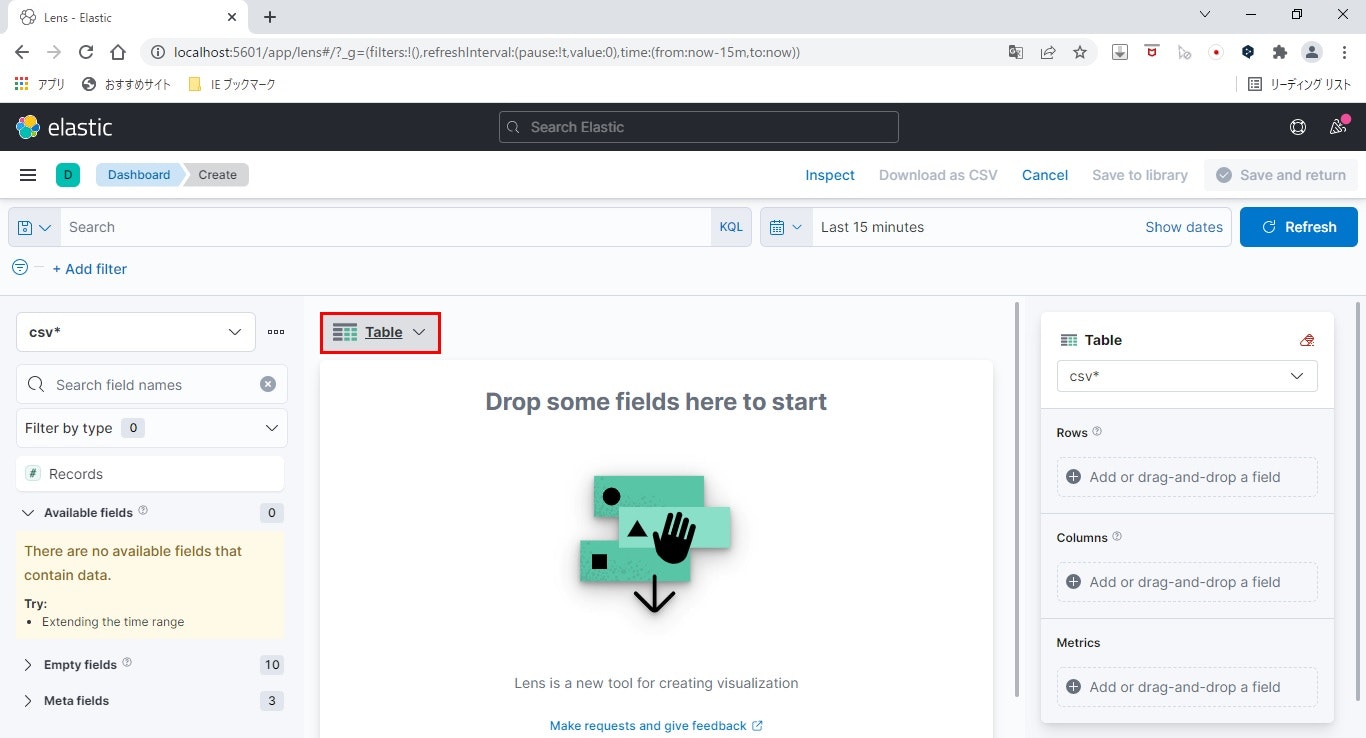
ダッシュボードに配置するビジュアライゼーションのタイプを選択します。
グラフとかたくさん選べますが、ここではテーブルを使用します。
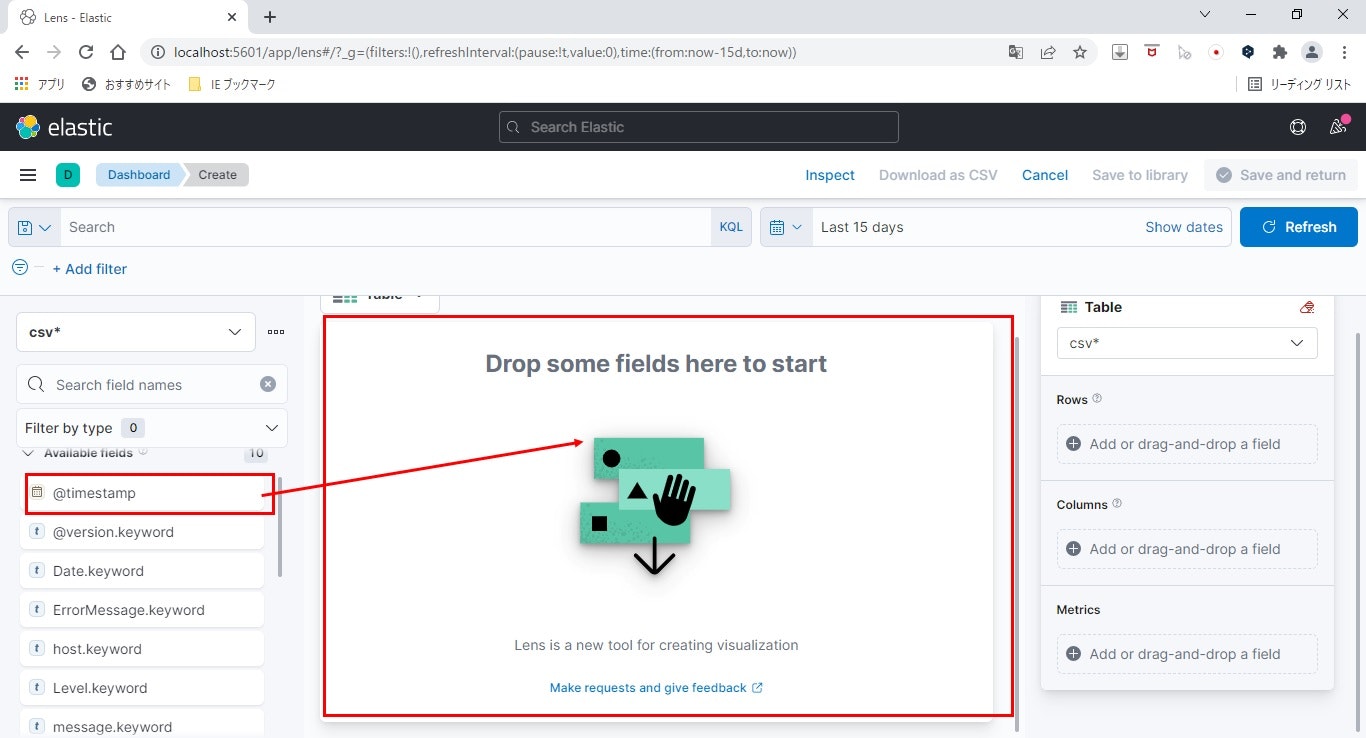
- 表示する要素を配置
左ツリーから任意のFieldを中央にドラッグアンドドロップし、表示する内容をカスタマイズします。
ここでは、タイムスタンプ、ログレベル、メッセージを配置します。
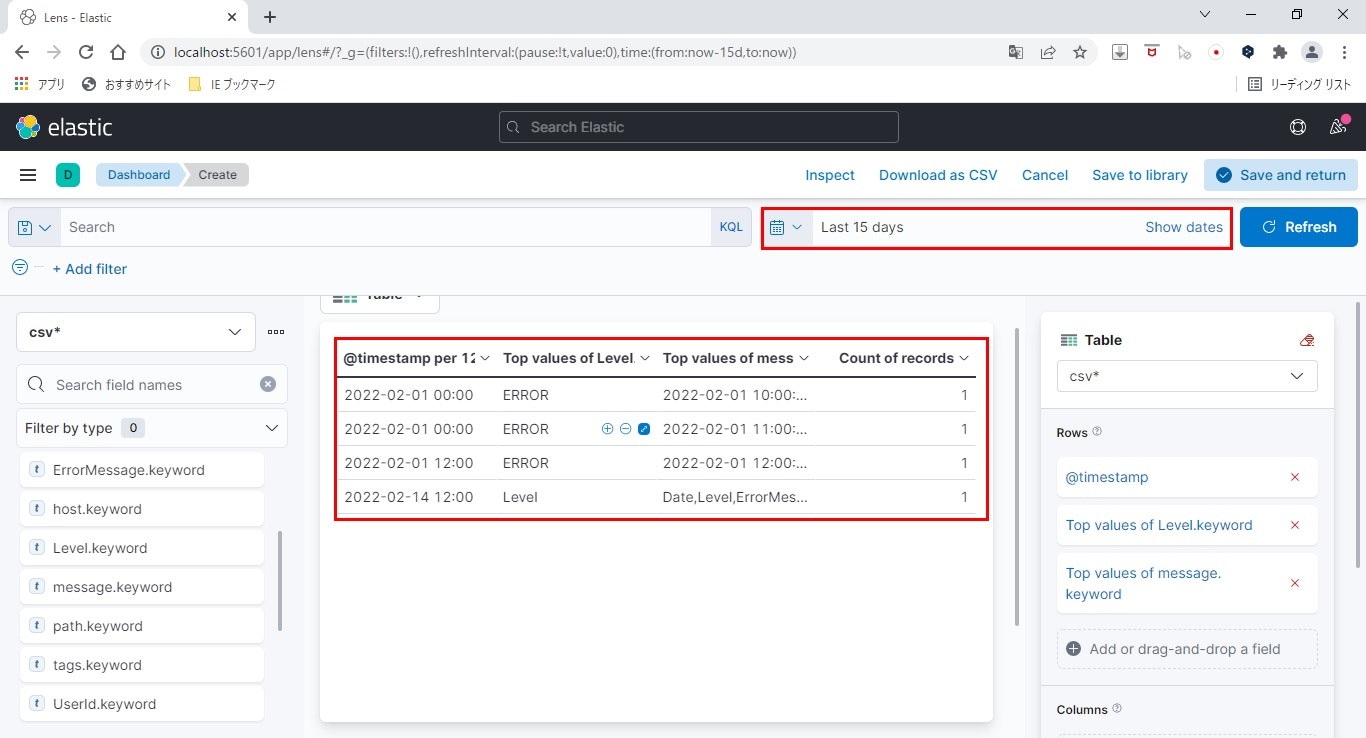
- テーブルの内容を確認
デフォルトで、タイムスタンプによる絞り込みが入っているので、右上のの検索対象のタイムスタンプをログ日付に合うように変更します。
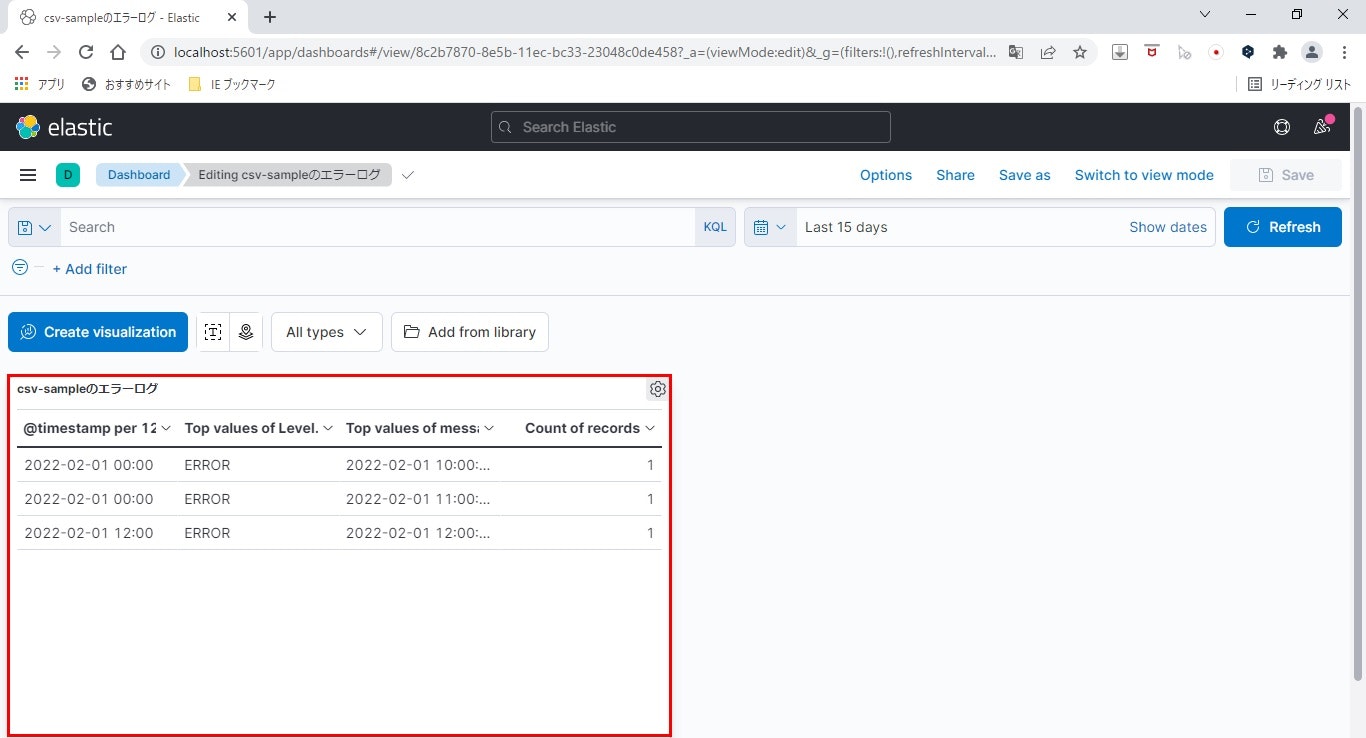
見事、テーブルの内容がビジュアライズに表示できました。
ちなみにテーブルの一番右、カウントはデフォルトでくっつき、消せないようです。
- さらに絞り込み
このままでもいいのですが、条件を指定してさらに絞り込みます。
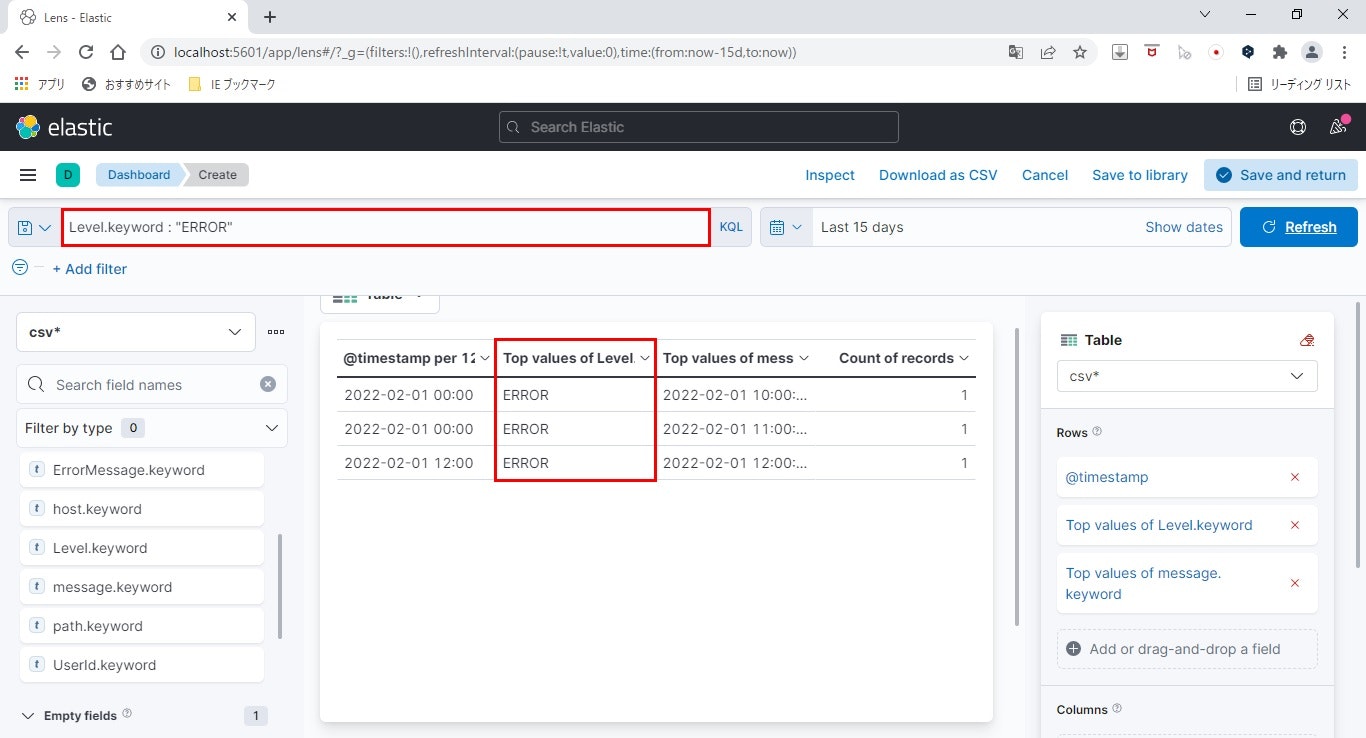
ここでは、ログレベルを「ERROR」に絞ります。
上部テキストボックスに、Level.keyword : "ERROR"と入力し、「Enter」します。
ログレベルにより絞り込まれ、ERRORログだけを抽出できました。
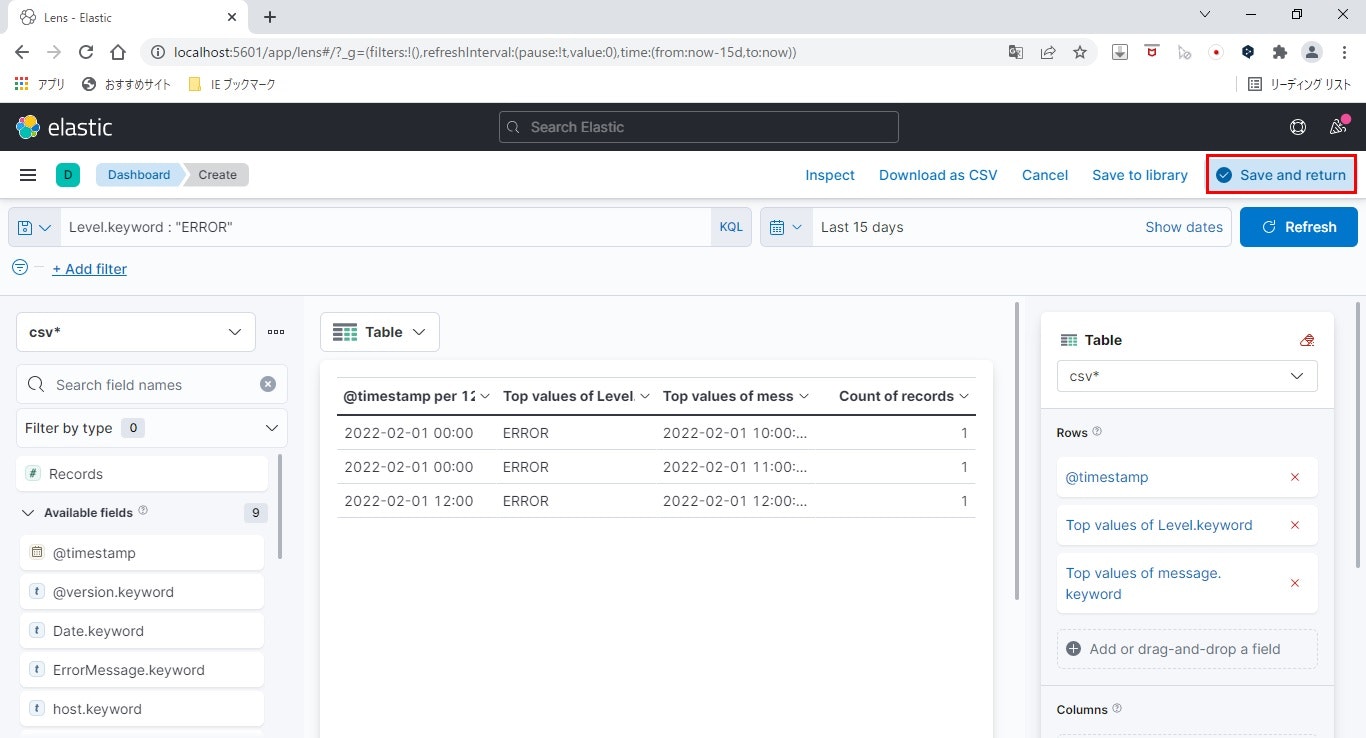
- ビジュアライゼーションの保存
ここまで作業をしたら、必ず保存しましょう。
まずはビジュアライゼーションです。
画面右上の「Save and return」をクリックします。
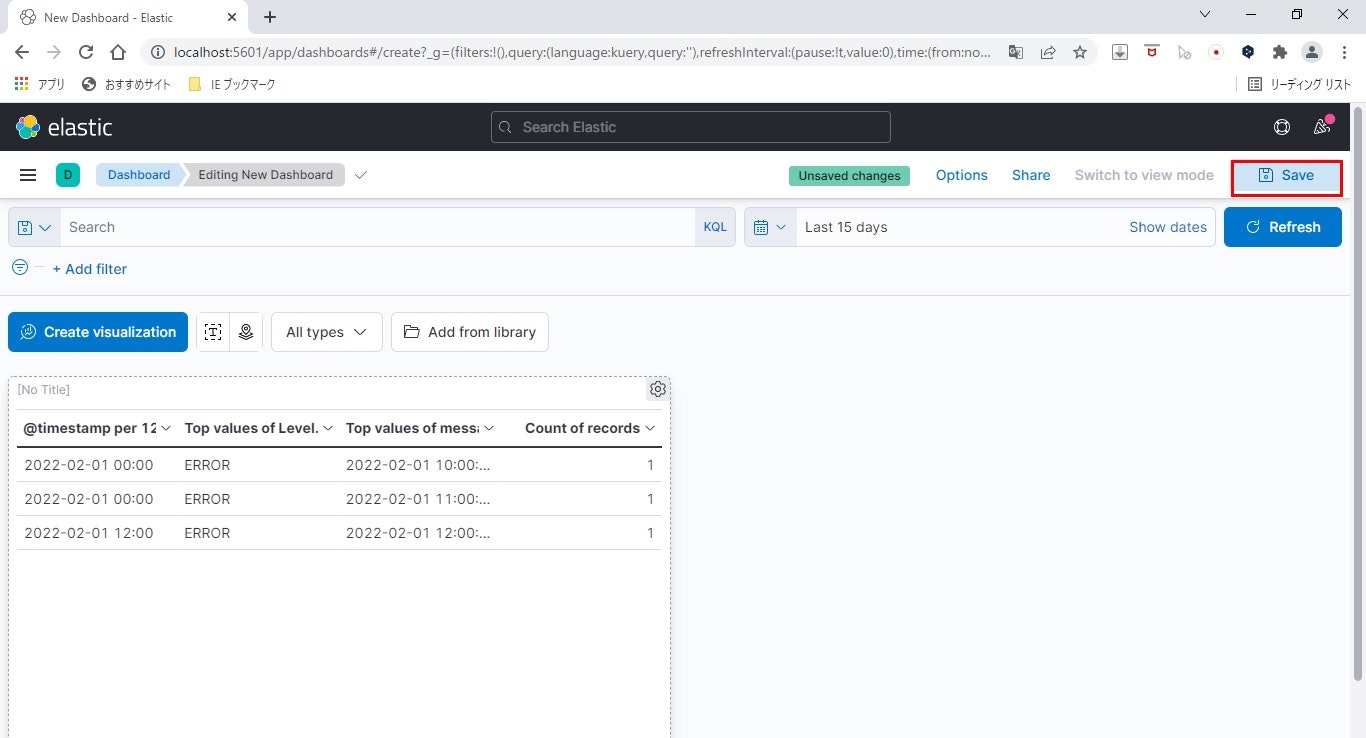
- ダッシュボードの保存
「Save」をクリックします。
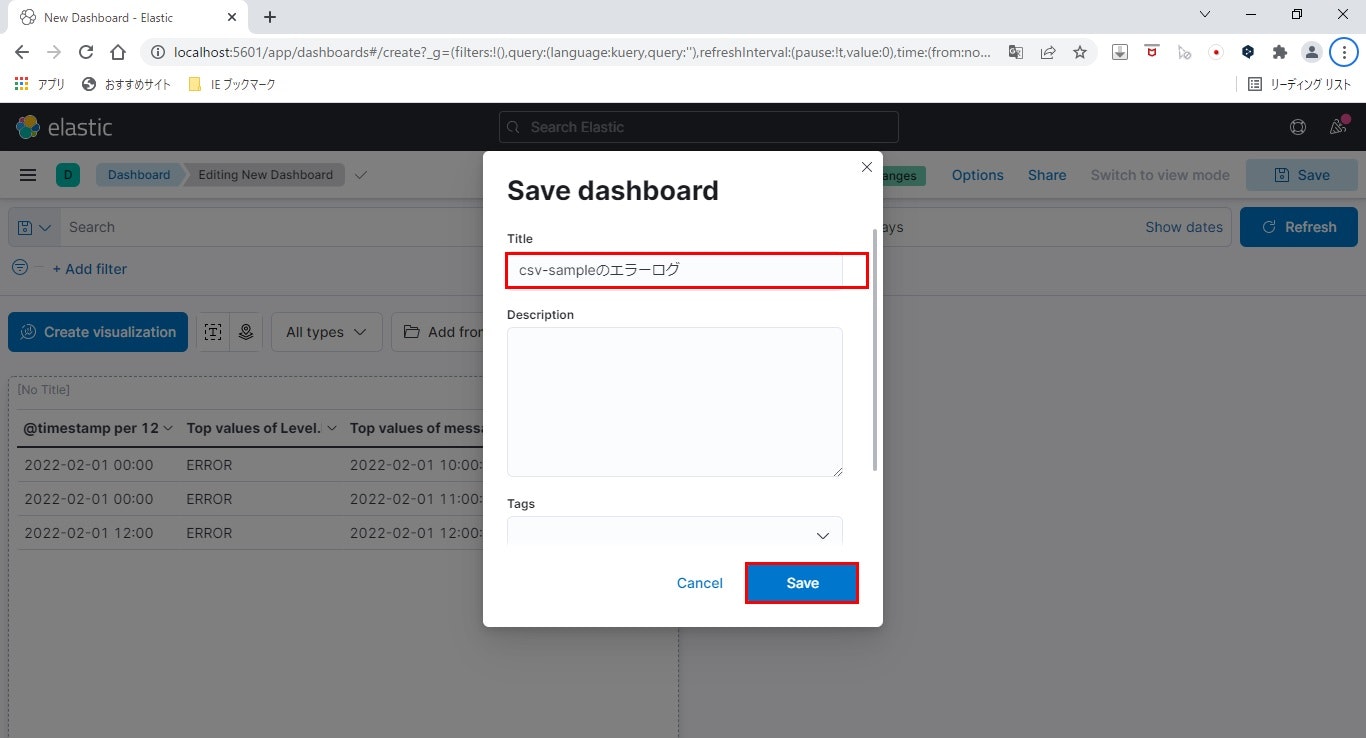
- 保存の完了
最後にダッシュボードのタイトルを入力し、「Save」をクリックします。
これで、ダッシュボードが登録できました。
あとはこのダッシュボードを開けば、エラーログだけを自動で抽出し、いつでもサマリを見ることができます。
これだけでもファイルをgrepしたりtailしたりする手間が省けますし、タイムスタンプで絞り込むのも容易になります。
今のままでも十分に便利ですが、もっと色々な使い方ができるので、ぜひ試してみてください。
Kibanaまとめ
Kibanaの基本的な紹介はここまでです。
こちらも、ポイントをまとめておきます。
- インストールは解凍するだけ
- 設定ではElasticsearchの設定をコメントを復活させる
- インデックスパターンを作成する
- KQLでデータを閲覧可能
- ダッシュボードを使用してデータのビジュアライゼーションが可能
さて、Kibanaの紹介までが終わったところで、ELKStackで使用する製品の紹介は全てです。
これだけの要素を知っていれば、それだけで色々なことができます。
これ以降の章は、知らなくてもいいけど、知っておくと便利になるかもしれないExtra編です。
興味のある方は最後までご覧ください。
EX. 複数のリモートサーバからログを集めて蓄積してみる
Extra編です。
ここからは、Filebeatという製品を使用し、複数のリモートサーバからログを集めて蓄積する方法をご紹介します。
Filebeatとは
ファイルを監視し、データを抽出できるツールです。
Logstashと何が違うの?と思う方もいるでしょうか。筆者もよくわかってません。
紹介記事を見ると、Filebeatの方が軽量ということですね。
その代わり、Logstashほど色んなことはできないんだとか。
複数のサーバからログを収集し、解析したい場合には、このFilebeatを使うのがポピュラー?なようです。
ログを収集したいサーバがあるのなら、そのサーバにLogstashを入れてしまえばよさそうですが、せっかくなのでFilebeatを使って、複数のログをLogstash、Elasticsearchに投入したいと思います。
FilebeatとLogstashの連携
上記の通りここからはFilebeatをLogstashと連携させます。
まずは、Filebeatの実行環境を構築します。
Filebeat環境構築
Filebeatのダウンロード
Elastcsearchと同じWEBよりFilebeatのZip版をダウンロードします。
インストール版もあるようなのですが、インストーラを使わなくても解凍するだけでインストールできるので個人的にはZip版がオススメです。
ここから先はZip版を前提に記載していきます。
インストール
こちらも他の製品同様、Zipファイルを解凍するだけです。
解凍後のツリーを記載しておきます。
こちらも、解凍したフォルダをFILEBEAT_HOMEとします。
FILEBEAT_HOME
│ .build_hash.txt
│ fields.yml
│ filebeat.exe
│ filebeat.reference.yml
│ filebeat.yml
│ install-service-filebeat.ps1
│ LICENSE.txt
│ NOTICE.txt
│ README.md
│ uninstall-service-filebeat.ps1
│
├─kibana
│ ・・・省略
│
├─module
│
└─modules.d
・・・省略
Filebeatの設定
こちらでは、読み込みファイルの設定、吸い出したログの出力先(Logstash)の設定をしていきます。
サンプルファイルは後程用意することとし、先にFilebeatの設定を行います。
変更するファイルは、「FILEBEAT_HOME\filebeat.yml」です。
こちらもほぼすべてコメントアウトされていますので、必要なところだけ復活させて内容を変更します。
なぜか出力をElasricsearchにする設定だけが生きていますので、その部分はコメントアウトします。
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
# Logstashのところを復活し、適宜変更します。
# ------------------------------ Logstash Output -------------------------------
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
# 読み込ませるファイル情報です。
filebeat.inputs:
- input_type: log
paths:
# 後程作成するサンプルファイルです。
- C:/Users/tarosa/Elastic/sample/log/log-sample.log
サンプルログの準備
Logstashと同じCSVでもいいのですが、実際のログってテキスト形式で、きれいにカンマ区切りになってることって少ないですよね。
同じことをやるのも芸がないので、独自のファイルフォーマットを使用したいと思います。
2022-02-20 10:00:00.000 [Thread1] DEBUG 処理開始
2022-02-20 10:01:23.456 [Thread1] INFO 処理開始を開始します。
2022-02-20 10:02:34.678 [Thread2] ERROR サンプルのエラー1です。
2022-02-20 10:02:35.000 [Thread2] ERROR サンプルのエラー2です。
2022-02-20 10:05:00.000 [Thread1] DEBUG 処理終了
2022-02-20 10:06:00.000 [Thread1] INFO 処理終了を終了します。
2022-02-20 10:06:01.000 [Thread1] WARN Thread2でエラーがありました。
ありがちな形式ですが、今回はこちらをサンプルとして使用します。
Logstashの設定
ログの解析、取り込みはLogstashを使用しますので、Logstashも設定します。
先に使用したCSVの設定はそのままに、複数のログを取り込む設定を追加でしていきます。
やることは全部3つです。
- オリジナルパターンの定義ファイルを追加
- 追加したパターンを使用した取り込み設定を追加
- Logstashに複数ファイルを取り込めるように設定を追加
オリジナルパターンの定義ファイル
まずは、オリジナルフォーマットを解析するためのパターンを定義したファイルを作成します。
「LOGSTASH_HOME\config」ディレクトリに以下のファイルを新規作成します。
Logstashのパターンは以下のルールに則り定義します。
- パターンの定義は正規表現を使用する
- ファイル拡張子は「.d」とする
- フォーマットは「パターン名 パターンを拾うための正規表現」とする
今回は新しく定義を追加しますが、Logstashにはデフォルトでパターンに使用できる正規表現が定義されていますので、パターン定義を作成する場合、定義済みのパターンを使用することもできます。
LOG_DATETIME (\d{4})-(\d{2})-(\d{2}) (\d{2}):(\d{2}):(\d{2})\.(\d{3})
THREAD_NAME \[.*\]
SAMPLE_LOG_PATTERN %{LOG_DATETIME:logdate} %{THREAD_NAME:thread} %{LOGLEVEL:level} %{GREEDYDATA:logmessage}
取り込み設定の追加
CSVのサンプル同様、Logstashの取り込み設定を行います。
「LOGSTASH_HOME\config」に、Filebeatからのログ読み込み用の設定ファイルを追加します。
今回はログ取り込みの定義だけでなく、複数のファイルを読み込むための設定も行います。
サンプルログの取り込み設定
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
# 入力のソースはFilebeatを使うので、beatsを指定します。
beats {
port => "5044"
}
}
filter {
# 入力した文字列の解析にはGrokプラグインを使用します。
grok {
# パターンファイルのディレクトリは、先ほど作成したパターンファイルのディレクトリを指定します。
# このファイルと同じディレクトリにあるファイルに、「../」を付加しているのは、読み込みはLogstashを実行したディレクトリの相対パスとなるからです。
# こちらはサンプルとして相対パスを使用しますが、必要なければ絶対パスを指定するのが無難です。
patterns_dir => ["../config/log-sample.d"]
# messageはパターンファイルに定義したものをにmatchさせます。
match => {"message" => "%{SAMPLE_LOG_PATTERN}"}
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "filebeat-log-sample"
}
stdout {
codec => rubydebug
}
}
パイプラインの設定
複数のログを同時に取り込むには、パイプラインの設定を追加します。
Logstashでは、入力ストリーム的なもののことを「パイプライン」と呼んでいます。
ここでは、先ほどのCSV取り込み用のパイプラインと、Filebeatから受け取ったログを取り込むパイプラインの2つを定義します。
パイプラインを定義するには、「LOGSTASH_HOME\config\pipelines.yml」を編集します。
こちらも初めはすべてコメントアウトされているので、必要な部分だけ復活させて編集します。
全部載せると多すぎるので、必要な部分だけ抜粋します。
# CSVサンプル用のパイプライン
- pipeline.id: csv-sample
pipeline.workers: 1
pipeline.batch.size: 1
# ここで詳細は指定せず、先ほど定義した設定を読み込みます。
# config.string: "input { generator {} } filter { sleep { time => 1 } } output { stdout { codec => dots } }"
# ここでも相対パスを指定する場合は「../」を付加します。
path.config: "../config/csv-sample.conf"
# Filebeat用のパイプライン
- pipeline.id: filebeat-log-sample
queue.type: persisted
path.config: "../config/filebeat-log-sample.conf"
設定完了後のツリー
先ほどのツリーに、新規作成したファイルが増えています。
LOGSTASH_HOME
│ ・・・省略
├─bin
│ logstash.bat
│ ・・・省略
│
├─config
│ jvm.options
│ log4j2.properties
│ logstash-sample.conf
│ logstash.yml
│ pipelines.yml ★ここは編集
│ startup.options
│ csv-sample.conf
│ log-sample.d ★ここに追加
│ filebeat-log-sample.conf ★ここに追加
│
├─data
├─jdk
│ ・・・省略
├─lib
│ ・・・省略
├─logstash-core
│ ・・・省略
├─logstash-core-plugin-api
│ ・・・省略
├─tools
│ ・・・省略
├─vendor
│ ・・・省略
└─x-pack
・・・省略
起動
いよいよ環境を起動します。
Elasticsearchは先ほど同様ですが、Logstashは起動コマンドが少し違いますので、以下のコマンドで起動してください。
コマンド:logstash.bat --path.settings ../config
■Logstashの起動
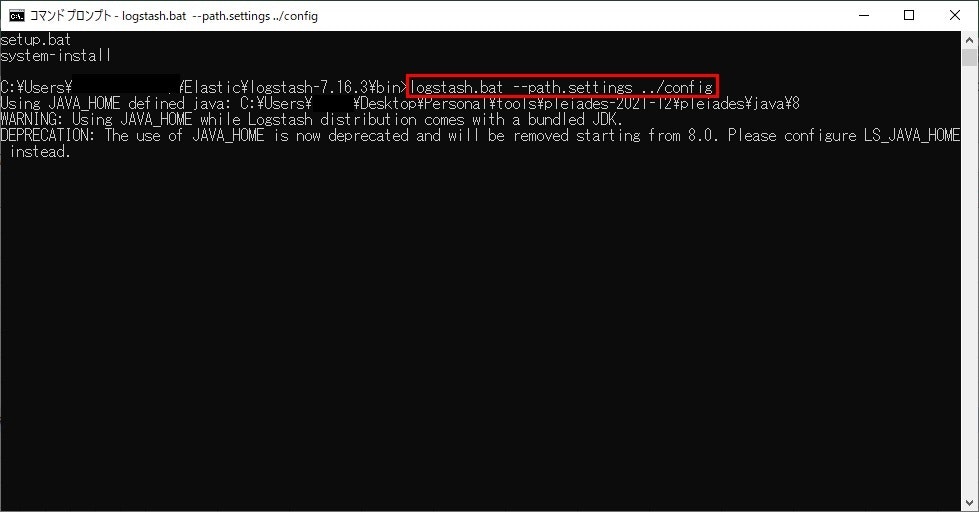
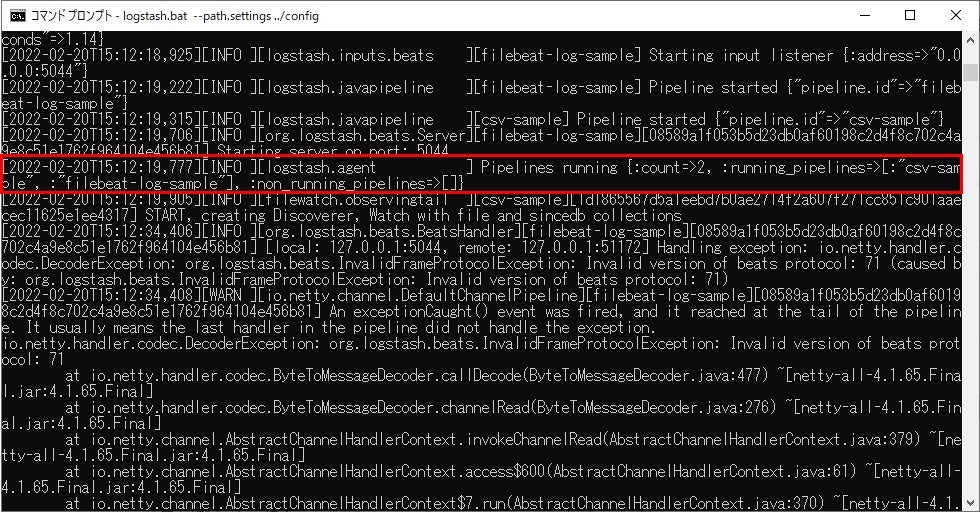
たくさん出力が出ますが、無事に起動すればパイプラインが起動した旨のメッセージが出ます。
■Filebeatの起動
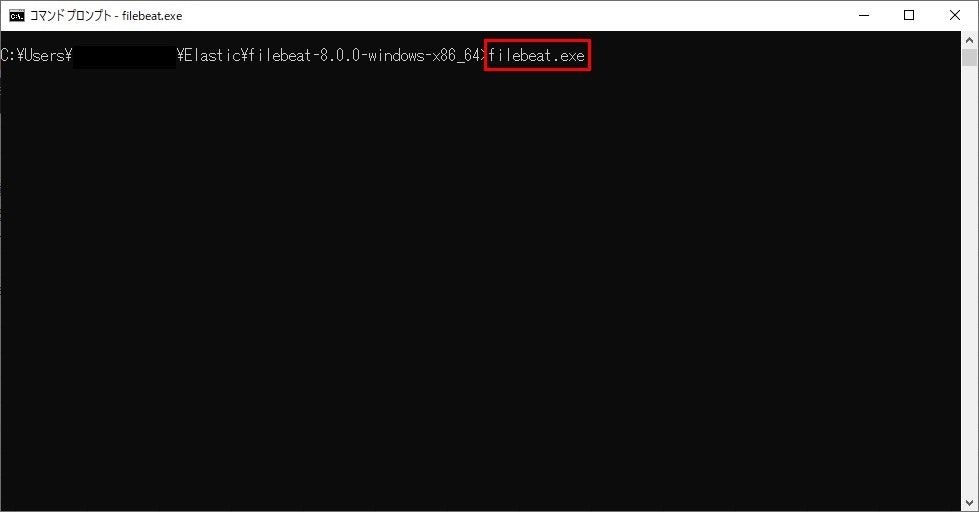
Filebeatの起動は以下のコマンドで行います。
Filebeatはサービスとして動かすのが王道?のようですが、今回はサンプルなのでフォアグラウンドのプロセスで普通に実行します。
と言っても、普通にfilebeat.exeをキックするだけです。
コマンド:filebeat.exe
Kibanaで確認
それではKibanaで確認しましょう。
先ほど同様、インデックスパターンを追加し、ダッシュボードを作成して確認します。
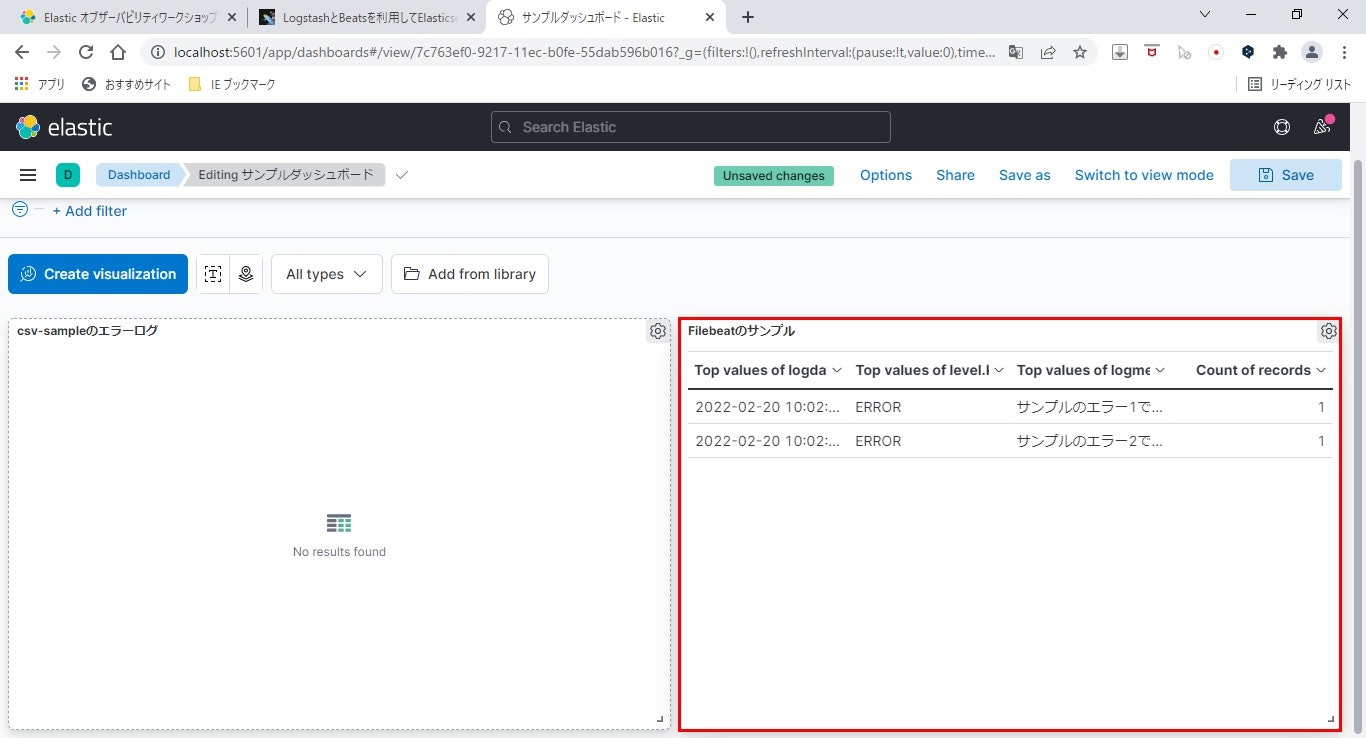
バッチリ作成できました!
おわりに
長編の記事を最後までご覧いただき、ありがとうございました。
うまく使えばログの解析をはじめいろんな業務が楽になるELKStack。
その世界の一片を紹介してみました。
これを機に、この製品を使って業務を効率化できた!という方が一人でも表れてもらえれば、筆者としてそれ以上にうれしいことはありません。