以前、Tweetデータをワードクラウドで可視化する遊びをやってみたのですが、他の方のテキストマイニング手法をぼけーっと眺めていたら前回のデータを使い回して感情分析して遊べるんじゃない?と死ぬほどどうでもいい啓蒙を得られました。
概要
これから取り組む感情分析はネガポジ分析と呼ばれる感情分析手法の一つで、わかりやすく対象の単語が前向き(肯定的)なのか後向き(否定的)な意味合いを持つのかを判定する手法を指します。
本稿ではR言語でTwitterから得られたデータをもとにネガポジ分析を行う方法について触れていきます。
分析にあたって、対象の単語が肯定的に近い傾向があるのか、否定的に近い傾向があるのか、その度合いが付与された辞書を元に行います。
辞書には単語ごとに感情特性値と呼ばれる正負いずれかの数値が紐づけられています。
単語の感情特性値が負なら否定的、正であるなら肯定的であることを意味します。
前準備
文章を分析するためには、形態素(単語)ごとに分解する必要があります。
「Mecab」と呼ばれるパッケージをインストールします。下記のリンクを参考にインストールしてみてください(対応済の方について、再インストールする必要はないです)。
ついでと言っては何ですが、筆者は所属している会社の有識者からNEologd辞書を使うことを勧められたこともあってMeCab+NEologdで分析を行いました。
新語に対応していることもあって重宝しております。
導入をしたくなければ先に進んでも良いですが、以下のリンクを参考にインストールしてみると精度的に良いかも(※下記はWindowsのインストール方法です。MacOSは検証中です)。
・mecab-ipadic-NEologdをWindowsで使ってみる。
Tweetデータ取得
Rでは「rtweet」パッケージを使用してTwitterからデータを取得します。
# ライブラリ -------------------------------------------------------------------
library(RMeCab)
library(pipeR)
library(dplyr)
library(rtweet)
# ツイート取得 ------------------------------------------------------------------
# キーワードで検索(第一引数:検索したいキーワード、第二引数:取得件数、第三引数:リツイートを取得するか、第四引数:どの国のツイートを取得するか
keyword <- search_tweets("グラブル AND ガチャ",n=3200,include_rts = FALSE,langs = "ja")
# ファイルに書き込み
write.csv(keyword$text,file = "tweets.csv",sep = ",",col.names = T,row.names = F)
search_tweets関数を実行するとブラウザが開かれてTwitterとアプリ連携の認証が行われる画面が表示される場合がありますが、連携します的なボタンを押してしまって問題はないです。
連携に成功すると「Authentication complete.Please close this page and return to R.」(訳:認証が完了しました。このページを閉じてRに戻ってください。)と表示されますので、Rに操作を切り替えましょう。
単語感情極性表の読み込み
続いて、感情表現を定義したテーブルを読み込みます。
東京工業大学の高村さんが公開されている単語感情極性対応表を辞書として利用させてもらいます。
# 単語感情極性表の読み込み -------------------------------------------------------------------
# 単語感情極性表(Semantic Orientations of Words)の読み込み
sow <- read.table("http://www.lr.pi.titech.ac.jp/~takamura/pubs/pn_ja.dic",sep=":",
col.names=c("term","kana","pos","value"),
colClasses=c("character","character","factor","numeric"),
fileEncoding="Shift_JIS")
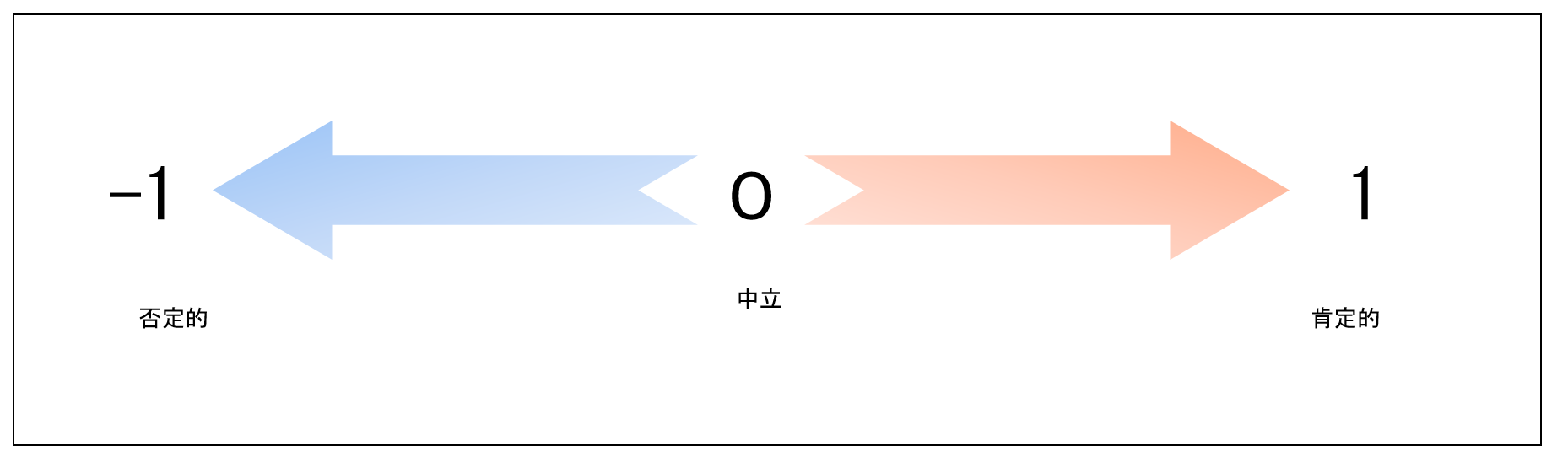
表を見てもらえればわかる通り単語に感情特性値が紐づけられており、-1に近いほど否定的、+1に近いほど肯定的な意味合いを示しています。
データ加工(形態素分析、感情スコア算出)
RMeCabの関数RMeCabFreqを使うと文章を形態素(単語)に分解した上で単語の出現頻度を算出してくれます。
さらに、分解した形態素の中から単語感情極性表に含まれるキーワードだけ抽出してマージする処理を行います。
その後、形態素の頻出度合い×感情特性値でスコアを算出していきます。
# データ加工 -------------------------------------------------------------------
# 頻出ワードを抽出
tweetword <- RMeCabFreq("tweets.csv")
# 単語感情極性表に含まれるものを抽出
tweetword2 <- subset(tweetword,Term %in% sow$term)
# 単語感情極性表の属性をマージ
tweetword2 <- merge(tweetword2,sow,by.x = c("Term","Info1"),by.y = c("term","pos"))
# 頻度(Freq) × 表の値(Value)でスコアを算出
tweetword2 <- tweetword2[4:(ncol(tweetword2)-2)]*tweetword2$value
可視化(パイチャート)
仕上げとして可視化を行います。
0.5~1.0の範囲をポジティブ、0~0.5の範囲をややポジティブ、0~-0.5の範囲をネガティブ、-0.5~-1の範囲をネガティブとして区分分けして合算します。
# 可視化 ---------------------------------------------------------------------
# 描画用データを作成
# 0.5~1.0 ポジティブ/0~0.5 ややポジティブ/0~-0.5 ややネガティブ/-0.5~-1 ネガティブ
tweetword2 <-c(sum(tweetword2 > 0.5 & tweetword2 < 1.0),
sum(tweetword2 > 0 & tweetword2 < 0.5),
sum(tweetword2 < 0 & tweetword2 < -0.5),
sum(tweetword2 < -0.5 & tweetword2 < -1)) %>>%
as.data.frame()
# パイチャートで描画
dv=c(tweetword2[1:4,])
pie(dv,radius=1,labels=c(paste("ポジティブ:",dv[1]),
paste("ややポジティブ:",dv[2]),
paste("ややネガティブ:",dv[3]),
paste("ネガティブ:",dv[4])),col=c("#08519c","#3182bd","#6baed6","#9ecae1"),
clockwise=T,border="#ffffff",main="グラブル ガチャ",cex.main=1)
pie関数を実行すると以下の結果が得られました。
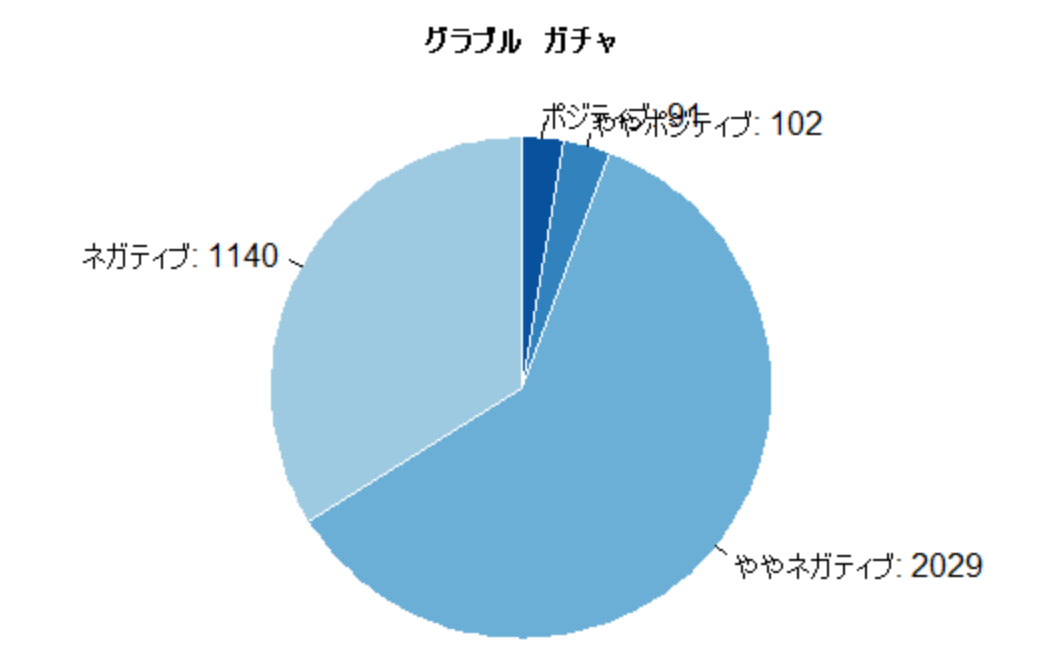
ネガティブなつぶやきが多い傾向にあることがわかったかと思います。
Twitterやってる人の多くは闇属性というのが筆者個人の認識なのでこんなもんかなとは思いましたが、Tweetデータの取得数を3200件しか取っていないということもあり信頼度はいまいちでしょう。
事細かに把握するにはより多くのデータが必要になるのでしょうが、それはまた別のお話ということで、ご興味を持たれた方は試してみてはいかがでしょうか。
あとガチャは悪い文明。