GMKtec EVO-X2 を LLM サーバとして構築する手順(Ubuntu + ROCm 環境)
GMKtecの EVO-X2 を入手した。本機は LPDDR5X 128GB 搭載かつ APU構成のため、その大容量メモリをVRAMとして活用できる点が特長である。
比較的安価に「VRAM容量特化PC」を手に入れられるということで、自宅LAN内の LLMサーバ用途 として構築を進めた。
⚠️ 注意: 2025年10月現在、ROCm対応の成熟度はまだ低く、GPUを利用した画像や動画の生成速度は「カス」と言っていいレベルであるらしい。将来的にROCmがこなれて性能が改善されれば、画像生成や動画生成にもある程度使えるのではと期待したいところ。
構築手順メモ
1. OS 用 SSD 差し替え
- 付属の Windows11 インストール済み NVMe SSD は取り外して保管。
- 空の NVMe SSD を用意して Ubuntu をインストール。
- 注意点: 公式手順(参考動画)では、接着されたゴム足を剥がした下のネジを外す必要がある。日本人の感覚では正気を疑う方法だが、これが正しい手順である。
2. Ubuntu 24.04 インストール
特に問題なくインストール可能である。
3. AMD ドライバーインストール
-
AMD公式サイト から、
Ubuntu 24.04.3 HWE 用 Driver 25.10.4をダウンロード
2025/10/01現在のバージョンはこんな感じ。
ubuntu24.04.3HWE用のドライバ25.10.4をダウンロードしてインストールした。

- インストール例:
sudo apt install ./amdgpu-install-VERSION.deb
4. ROCm 6.4 インストール
-
上記ドライバ導入で
amdgpu-installコマンドが利用可能になる。 -
ROCm インストール手順:
sudo amdgpu-install -y --usecase=rocm --no-dkms sudo usermod -a -G render,video $LOGNAME reboot -
インストール確認コマンド:
apt show rocm-libs -a hipcc --version -
注意:
rocminfoで表示されるROCk module versionは カーネルモジュールのバージョン であり、ROCm全体のバージョンとは異なるので誤解しないこと。
5. amdgpu_top の導入
-
Umio-Yasuno/amdgpu_top から deb を入手し、
apt install。 - 確認ポイントは「Memory Usage → GTT」の総量。
-
初期状態: 約 64GB
-
後述の設定で 128GB まで拡張可能。
ちなみにこの画面ショットは後続手順にてGTTのサイズを128GBまで目一杯広げた状態。
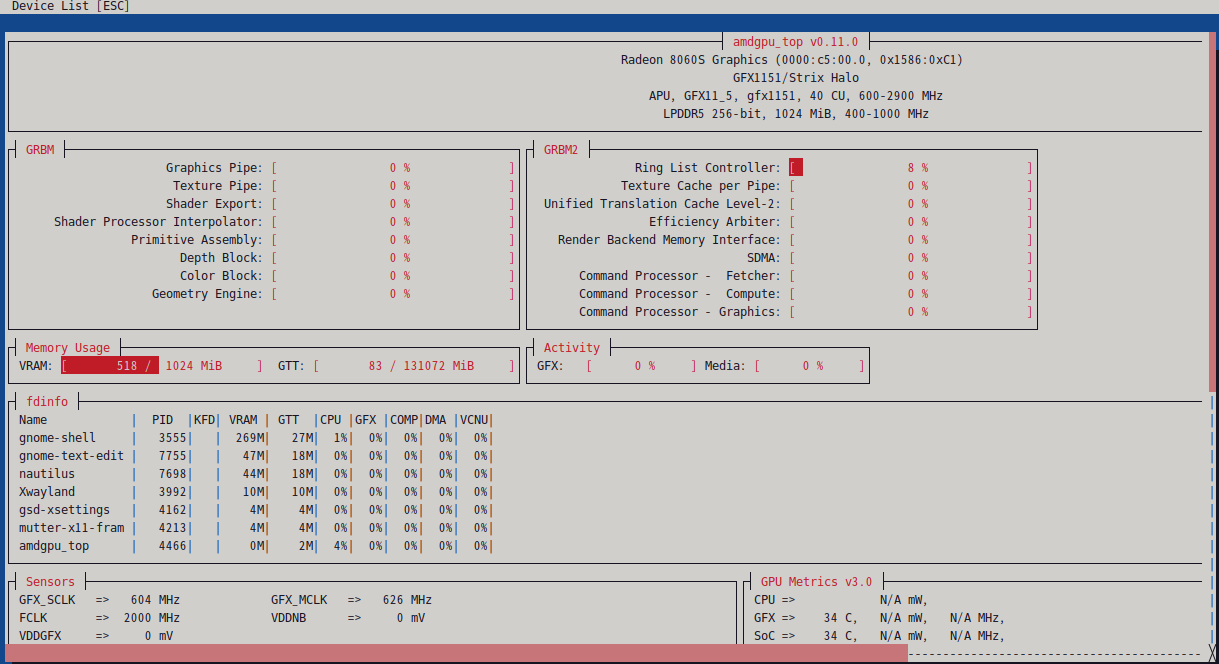
-
6. GTT サイズ最大化
- 参考: Zenn記事
-
sudo nano /etc/default/grubにて
GRUBの設定ファイルに以下を追記し、GTT を 128GB に拡張。ファイル編集後、以下のコマンドで適用してOS再起動すると反映されるはず。GRUB_CMDLINE_LINUX_DEFAULT="quiet splash amdttm.pages_limit=33554432 amdttm.page_pool_size=33554432"sudo update-grub - 単位は「4KBページ数」。33554432ページ ≒ 128GB。
7. llama.cpp インストール(Vulkan版)
- LM Studio / Ollama は(原因不明ながら) GPU を利用できず、やむなく
llama.cppを直接ビルド。 - Vulkan版 llama.cpp を参考資料に従って構築。
参考資料 https://light-of-moe.ddo.jp/~sakura/diary/?p=2242
※記事が消えると困るので手順をコピーしておく
$ git clone https://github.com/ggml-org/llama.cpp.git
$ sudo apt install libvulkan-dev glslc cmake build-essential libcurlpp-dev
$ cd llama.cpp
$ mkdir build-vulkan
$ cmake -B build-vulkan -DGGML_VULKAN=ON
$ cmake --build build-vulkan --config Release -j
8. llama-swap 導入
-
llama.cppはモデル切替が煩雑なため、 llama-swap の導入で妥協。
9. Open WebUI インストール
- open-webui
- 今回はLLMサーバを(ローカル上ではあるが)外部に用意するので
「If Ollama is on your computer, use this command:」パターンで導入。 - 前提として Docker インストールが必要。
初期構築時点ではNGだったもの、或いはしばらくアップデートを待ってから試してみたいもの
LM Studio
-
アプリ内部にVulkan / ROCm 版それぞれのllama.cppを内蔵しているが、
- ROCm版: GPUが検出されず使用不可(統合GPU未対応?)
- Vulkan版: 動作はするが遅すぎ & GPU利用されていない模様
-
結果、CPUオンリー動作でtokens/secが全く伸びなかったので不採用。
2025/10/10追記:
LM Studio 0.3.30、vulkan llama.cpp v1.52.1の組み合わせでは
正常にGPUとVRAMを使って動作することを確認。
vlukan llama.cppの方のリリースノートにiGPUで動作しないバグを解消、とあったのでその影響と思われる。
ただ、同時にROCm llama.cpp(linux)もv1.52.1で同様にiGPU関連バグを修正、とされており、ランタイムとして選択できるようにはなっていたが、モデルのロードまではできるものの、メッセージを投入すると異常終了する挙動になっていた。残念。
Ollama (ROCm版)
- LM Studio同様、GPUを利用できず不採用。
- 本家はVulkan版の開発予定なし。Fork版は存在するが将来性があるかどうか不明瞭だったので不採用。
modprobe 経由の共有メモリ拡張
- 参考
- 設定しても
amdgpu_topの GTT 総量が変化せず失敗。 - GRUB方式なら確実に拡張可能なので、こちらを採用した。
amd-strix-halo-toolboxes
ROCmも含めてコンテナ化してあるパッケージっぽい。
https://github.com/kyuz0/amd-strix-halo-toolboxes
セットアップの記録
https://zenn.dev/libratech/scraps/fae5ec1340e155
FastFlowLM
RyzenのNPUをLLMの計算に使うためのバイナリであるが、2025/10現在はWindowsのみ対応。
issuesによるとLinux対応も意思はある、とのことなので実装待ち。
https://github.com/FastFlowLM/FastFlowLM
まとめ
- EVO-X2 の 128GB LPDDR5X を フルにVRAM化 できることを確認。
- ただし 2025年10月時点では、ROCm経由の LLM 推論速度は実用に耐えない水準である。
- 今後の ROCm 改善に期待しつつ、暫定的に Vulkan版
llama.cpp+llama-swap+Open WebUIの構成で運用してみることにする。