サイバーエージェントから日本語大規模言語モデルが登場しました。
さくらのクラウドのGPUサーバで動くか確認してみます。
複数のモデルが公開されおり、今回は3つのモデルを試してみます。
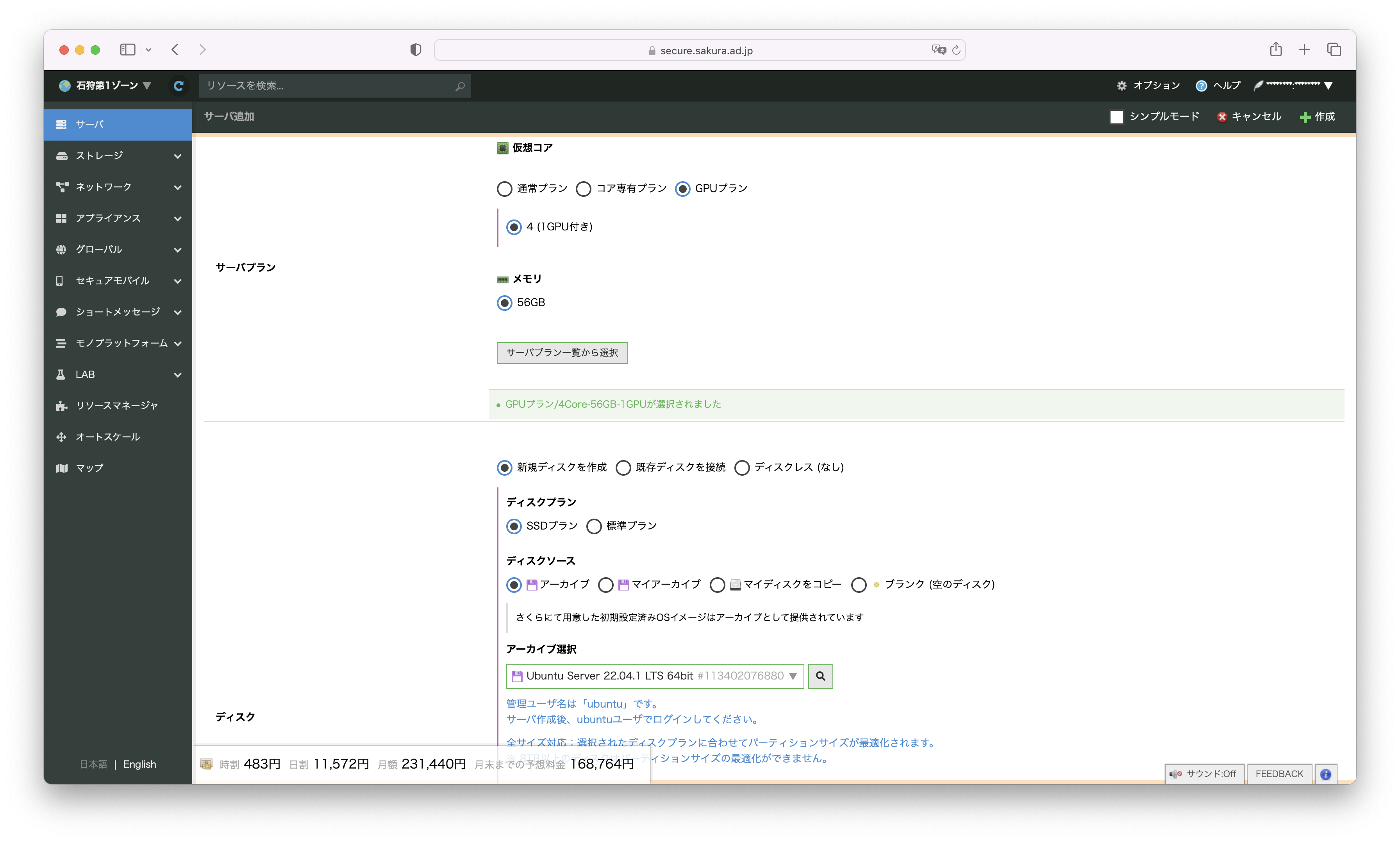
1.GPUサーバの作成
さくらのクラウドのコントロールパネルから、石狩第1ゾーンを選択し、サーバ追加画面を開きます。
サーバプランは GPUプラン を選択、ディスクのアーカイブは Ubuntu 22.04.1 LTS を選択します。
ディスクサイズは 100GB を選択します。
2.GPUドライバのインストール
GPUサーバが完成したら、SSHでログインします。
NVIDIAのドキュメント通りにインストールを行う。
https://docs.nvidia.com/datacenter/tesla/tesla-installation-notes/index.html
$ sudo apt-get install linux-headers-$(uname -r)
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID | sed -e 's/\.//g')
$ wget https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/cuda-keyring_1.0-1_all.deb
$ sudo dpkg -i cuda-keyring_1.0-1_all.deb
$ sudo apt-get update
$ sudo apt-get -y install cuda-drivers
インストールが終わったら再起動を行う。
3.pythonライブラリのインストール
$ sudo apt install python3-pip
$ pip3 install transformers accelerate
4.サンプルコードを動かしてみる(open-calm-1b)
open-calm-1bをまずは動かしてみます。
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>>
>>> model = AutoModelForCausalLM.from_pretrained("cyberagent/open-calm-1b", device_map="auto", torch_dtype=torch.float16)
Downloading (…)lve/main/config.json: 100%|███████████████████████████████████████████| 610/610 [00:00<00:00, 1.85MB/s]
Downloading pytorch_model.bin: 100%|█████████████████████████████████████████████| 2.94G/2.94G [00:36<00:00, 81.4MB/s]
Downloading (…)neration_config.json: 100%|████████████████████████████████████████████| 116/116 [00:00<00:00, 267kB/s]
>>> tokenizer = AutoTokenizer.from_pretrained("cyberagent/open-calm-1b")
Downloading (…)okenizer_config.json: 100%|████████████████████████████████████████████| 323/323 [00:00<00:00, 839kB/s]
Downloading (…)/main/tokenizer.json: 100%|███████████████████████████████████████| 3.23M/3.23M [00:00<00:00, 3.82MB/s]
Downloading (…)cial_tokens_map.json: 100%|████████████████████████████████████████████| 129/129 [00:00<00:00, 410kB/s]
>>>
>>> inputs = tokenizer("AIによって私達の暮らしは、", return_tensors="pt").to(model.device)
>>> with torch.no_grad():
... tokens = model.generate(
... **inputs,
... max_new_tokens=64,
... do_sample=True,
... temperature=0.7,
... top_p=0.9,
... repetition_penalty=1.05,
... pad_token_id=tokenizer.pad_token_id,
... )
...
>>>
>>> output = tokenizer.decode(tokens[0], skip_special_tokens=True)
>>> print(output)
AIによって私達の暮らしは、より便利に快適になりつつあります。
しかしその反面、「人」が「モノ」「コト(サービス)」に無意識に反応しなくなっているのではないか?そんな疑問を抱いてしまいます。「自分さえ良ければ良い!」という風潮や消費者のモラル低下による商品への無関心化などが挙げられますね!そのような状況下において私達は今後
>>>
スムーズに出力されました、AIによって便利になる世界から生まれる状況を問題提起しているようなことを言っているように見えます、賢そうです。ただ途中で出力が切れているのが気になります。
5.サンプルコードを動かしてみる(open-calm-3b)
次にopen-calm-3bを動かしてみます。
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>>
>>> model = AutoModelForCausalLM.from_pretrained("cyberagent/open-calm-3b", device_map="auto", torch_dtype=torch.float16)
Downloading (…)lve/main/config.json: 100%|███████████████████████████████████████████| 611/611 [00:00<00:00, 1.67MB/s]
Downloading pytorch_model.bin: 100%|█████████████████████████████████████████████| 5.70G/5.70G [01:17<00:00, 73.4MB/s]
Downloading (…)neration_config.json: 100%|████████████████████████████████████████████| 116/116 [00:00<00:00, 376kB/s]
>>> tokenizer = AutoTokenizer.from_pretrained("cyberagent/open-calm-3b")
Downloading (…)okenizer_config.json: 100%|███████████████████████████████████████████| 323/323 [00:00<00:00, 1.02MB/s]
Downloading (…)/main/tokenizer.json: 100%|███████████████████████████████████████| 3.23M/3.23M [00:00<00:00, 3.74MB/s]
Downloading (…)cial_tokens_map.json: 100%|████████████████████████████████████████████| 129/129 [00:00<00:00, 398kB/s]
>>>
>>> inputs = tokenizer("AIによって私達の暮らしは、", return_tensors="pt").to(model.device)
>>> with torch.no_grad():
... tokens = model.generate(
... **inputs,
... max_new_tokens=64,
... do_sample=True,
... temperature=0.7,
... top_p=0.9,
... repetition_penalty=1.05,
... pad_token_id=tokenizer.pad_token_id,
... )
...
>>>
>>> output = tokenizer.decode(tokens[0], skip_special_tokens=True)
>>> print(output)
AIによって私達の暮らしは、便利になり豊かになる一方です。しかし一方でその陰には危険や犯罪が潜んでいるのも事実です。「安全・安心」な生活を送るために「防犯対策」「防災対策」、何かあった際のための事前の備えをしておくことが重要です。『Safety2.0』とは、【新たな脅威】【攻撃者】【侵入手
>>>
こちらもスムーズに出力されました。AIを使う上でのアドバイスのような出力がありいい感じです。
ただこちらも途中で出力が切れているのが気になります。
6.サンプルコードを動かしてみる(open-calm-7b)
次にopen-calm-7bを動かしてみます。
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>>
>>> model = AutoModelForCausalLM.from_pretrained("cyberagent/open-calm-7b", device_map="auto", torch_dtype=torch.float16)
Downloading (…)lve/main/config.json: 100%|███████████████████████████████████████████| 611/611 [00:00<00:00, 1.69MB/s]
Downloading (…)model.bin.index.json: 100%|████████████████████████████████████████| 42.0k/42.0k [00:00<00:00, 287kB/s]
Downloading (…)l-00001-of-00002.bin: 100%|████████████████████████████████████████| 9.93G/9.93G [01:27<00:00, 114MB/s]
Downloading (…)l-00002-of-00002.bin: 100%|████████████████████████████████████████| 3.95G/3.95G [00:35<00:00, 112MB/s]
Downloading shards: 100%|███████████████████████████████████████████████████████████████| 2/2 [02:04<00:00, 62.13s/it]
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████| 2/2 [00:06<00:00, 3.39s/it]
Downloading (…)neration_config.json: 100%|████████████████████████████████████████████| 116/116 [00:00<00:00, 389kB/s]
>>> tokenizer = AutoTokenizer.from_pretrained("cyberagent/open-calm-7b")
Downloading (…)okenizer_config.json: 100%|███████████████████████████████████████████| 323/323 [00:00<00:00, 1.10MB/s]
Downloading (…)/main/tokenizer.json: 100%|███████████████████████████████████████| 3.23M/3.23M [00:00<00:00, 3.75MB/s]
Downloading (…)cial_tokens_map.json: 100%|████████████████████████████████████████████| 129/129 [00:00<00:00, 466kB/s]
>>> inputs = tokenizer("AIによって私達の暮らしは、", return_tensors="pt").to(model.device)
>>>
>>> with torch.no_grad():
... tokens = model.generate(
... **inputs,
... max_new_tokens=64,
... do_sample=True,
... temperature=0.7,
... top_p=0.9,
... repetition_penalty=1.05,
... pad_token_id=tokenizer.pad_token_id,
... )
...
>>>
>>> output = tokenizer.decode(tokens[0], skip_special_tokens=True)
>>> print(output)
AIによって私達の暮らしは、ますます便利で豊かになることでしょう。そしてそれは同時に、自動化やロボット化によって職場環境や人間の労働環境も変化していきます。そうした時代だからこそ、「人間にしかできない仕事」や「機械では代用できない仕事」、あるいは「人と人をつなぐコミュニケーションの仕事」といった仕事は、より重要になっていくはずです。
『Clova』という新しい通信
>>>
いろいろ質問してみる
>>> inputs = tokenizer("さくらインターネットはどんな会社ですか?", return_tensors="pt").to(model.device)
>>> with torch.no_grad():
... tokens = model.generate(
... **inputs,
... max_new_tokens=64,
... do_sample=True,
... temperature=0.7,
... top_p=0.9,
... repetition_penalty=1.05,
... pad_token_id=tokenizer.pad_token_id,
... )
...
>>> output = tokenizer.decode(tokens[0], skip_special_tokens=True)
>>> print(output)
さくらインターネットはどんな会社ですか?
- 大きく分けると、通信系のインフラ事業とデータセンターの2つです。どちらもネットワークやサーバーなどの技術で、IT社会を支えるという仕事ですね。ただ、当社の場合、通信系だけだと難しいので、主にデータセンターに注力しています。また、最近ではハードウェアの販売だけでなく、運用保守までサポートして、システム
>>>
>>> inputs = tokenizer("今期のオススメのアニメを教えてください", return_tensors="pt").to(model.device)
>>>
>>> with torch.no_grad():
... tokens = model.generate(
... **inputs,
... max_new_tokens=64,
... do_sample=True,
... temperature=0.7,
... top_p=0.9,
... repetition_penalty=1.05,
... pad_token_id=tokenizer.pad_token_id,
... )
...
>>> output = tokenizer.decode(tokens[0], skip_special_tokens=True)
>>> print(output)
今期のオススメのアニメを教えてください。
最近、漫画や小説を読みました。特に面白かったのは「惡の華」「オンノジ」「ぼっち・ざ・ろっく!」「俺物語!!」の4つです。どれも面白かったので、お勧めの漫画がありましたら教えて下さい。お願いしますm(_ _)m
よくドラマとかにでてくるセリフで、「お前はもう
>>>
こちらもスムーズに出力されました。
AIによって変わりつつある社会について述べています。いい感じです。
感想
これまでのフリーで利用できるLLMと違って、日本語大規模言語モデルということもあり文脈がある文章が生成されているように感じました。多少日本語がおかしい部分はありますが、何かに使えるかもしれません。
今後、さらに日本語大規模言語モデルが広がっていき便利になったらいいなと思います。
付録 OpenCALMをHTTP APIから利用する
OpenCALMをHTTP APIから利用するための記事を書きました。
ぜひこちらもお読みいただければ幸いです。
付録 cloud-initで簡単にOpenCALM環境を作る
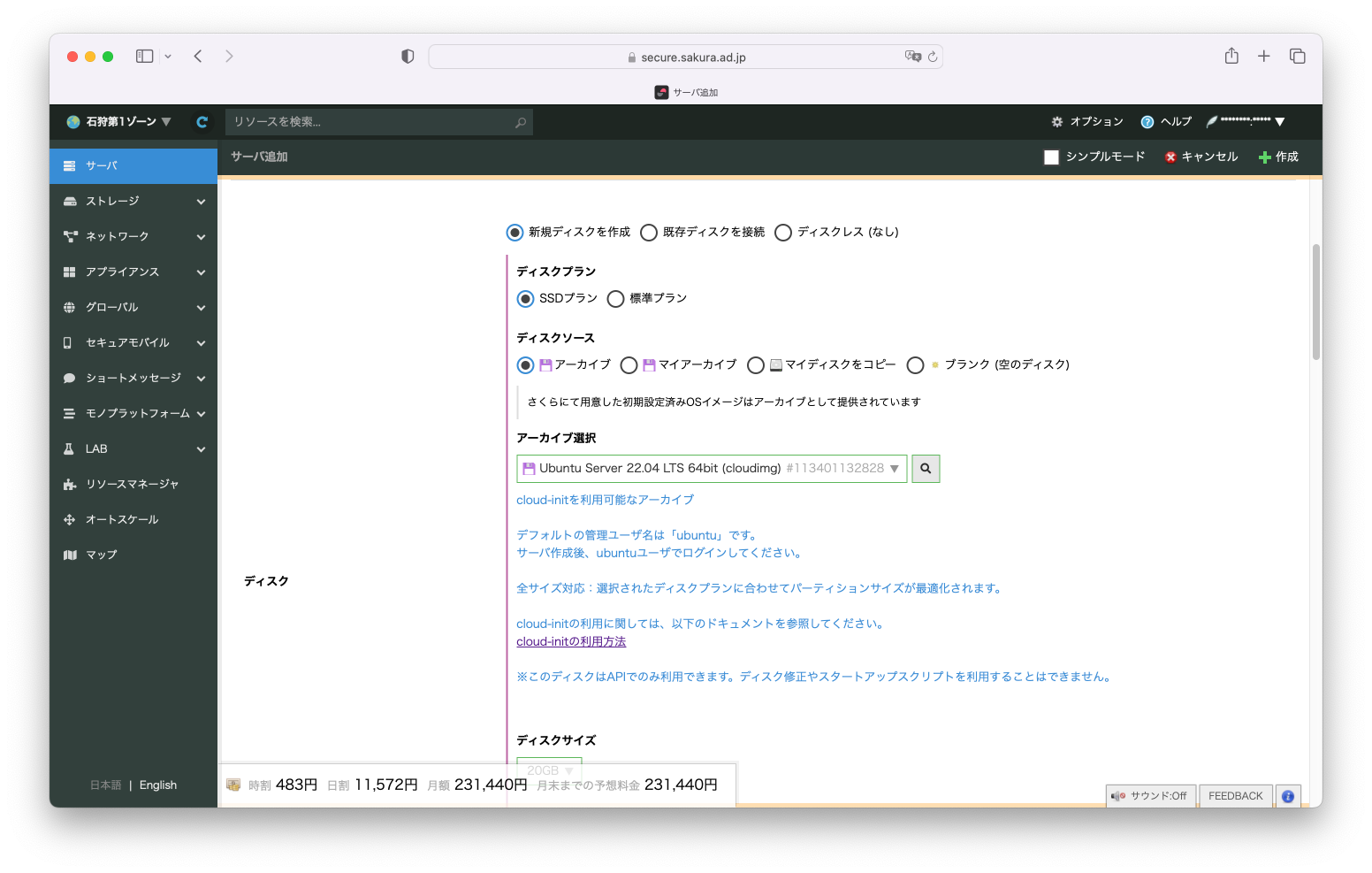
cloud-initを使って、簡単に環境を作ることができます。
サーバの作成方法は、1.GPUサーバの作成と基本的に変わりません。
ディスクのアーカイブは Ubuntu Server 22.04 LTS 64bit (cloudimg) を選択します。
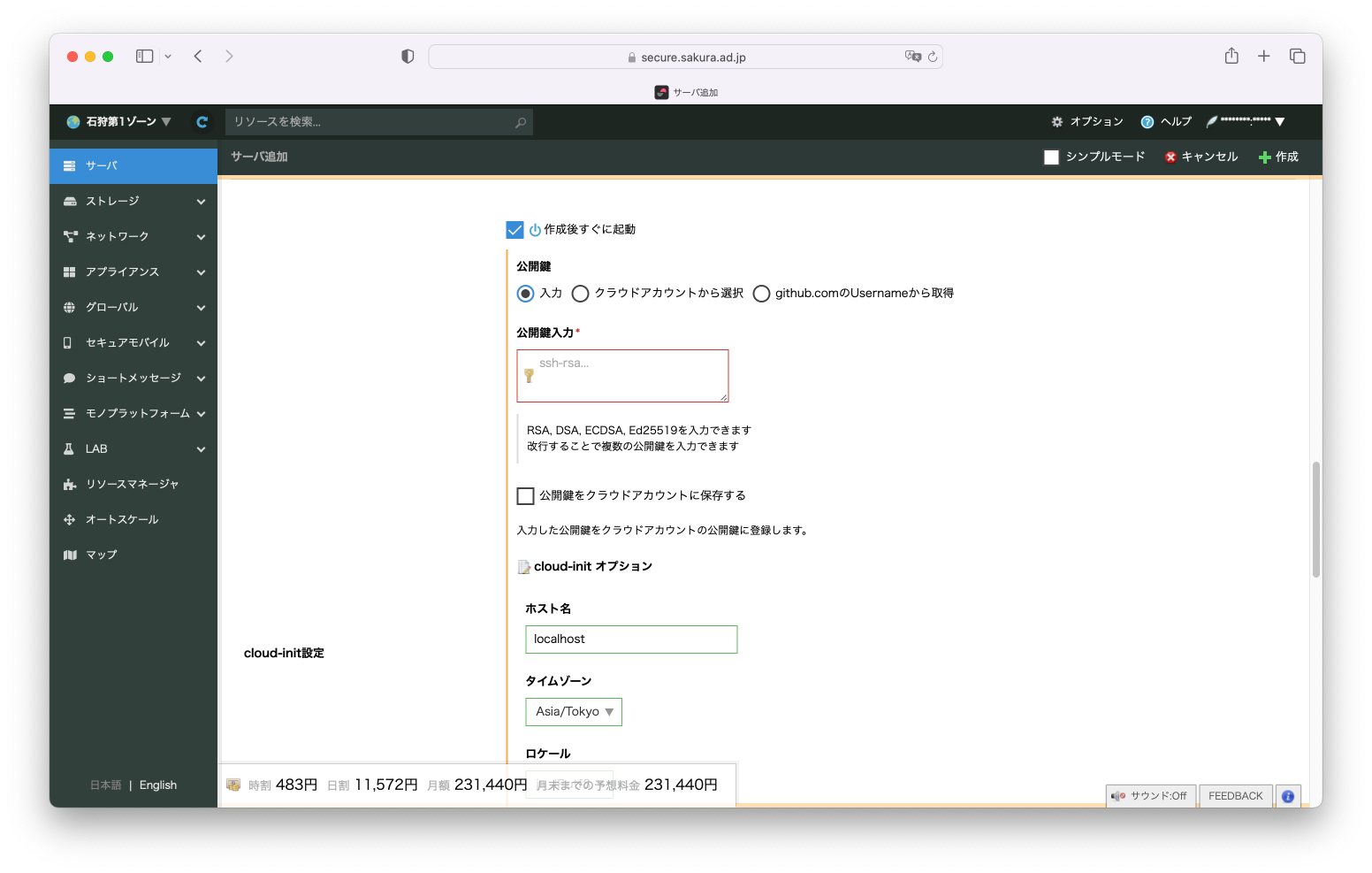
公開鍵を指定します、3種類の選択方法から選択してください。SSH接続時に利用します。
追加ユーザデータにcloud-initのコードを貼り付けます。
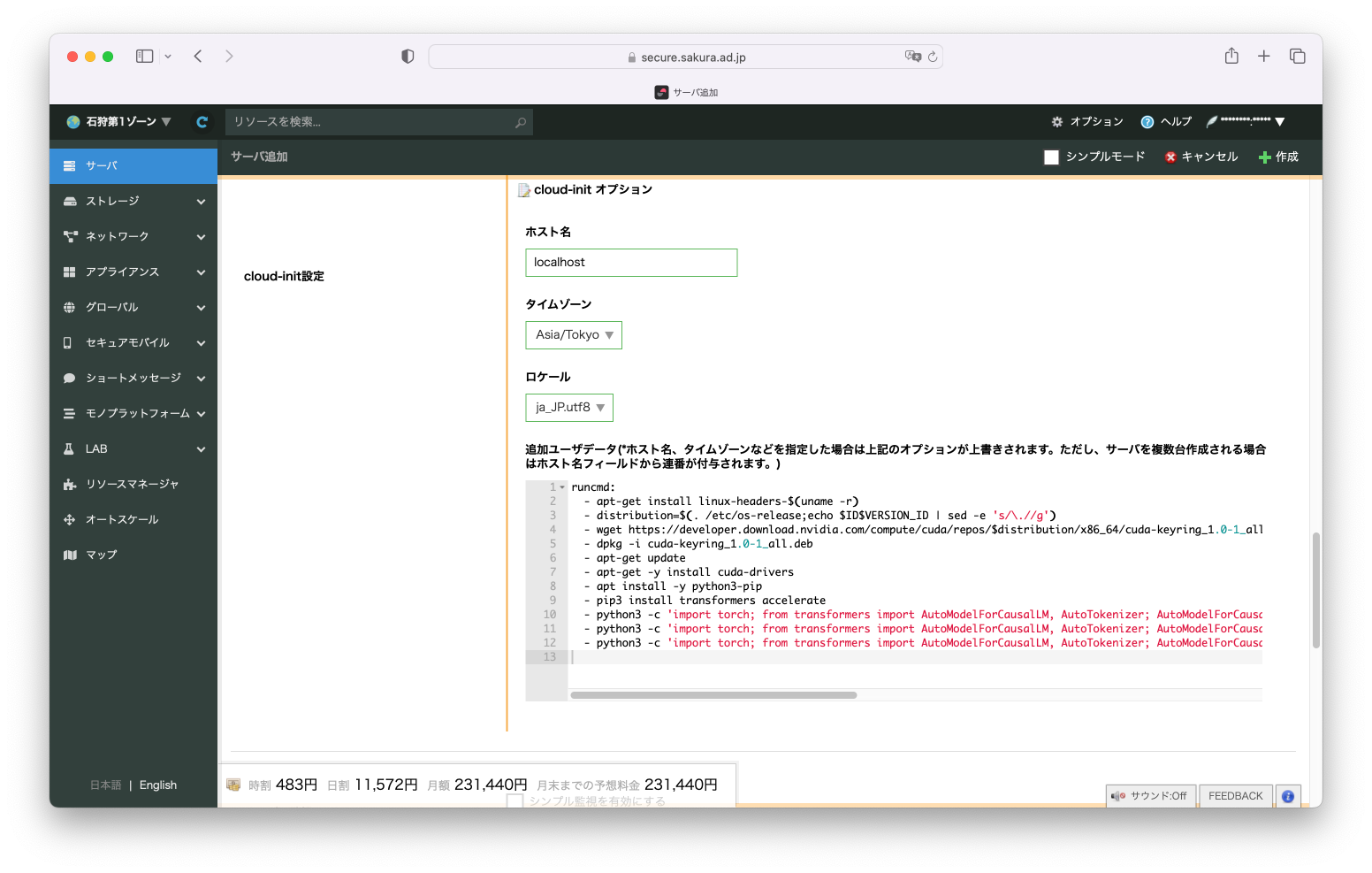
cloud-initのコードはこちらにあります。
この内容で作成していただくことで、GPUドライバのインストール、pythonライブラリのインストール、OpenCALMモデルのダウンロードを自動でおこなってくれます。便利ですね。
30分ほどかかります。
ぜひご活用ください。