キーワードに沿った画像を大量に集めて、まとめてダウンロードすることができるWebツール、画像クローラーを作りましたのでご紹介します。こちらから
Mashup Awardsという開発者コンテストにも応募しました。作品詳細
※ディープラーニングのエンジニアリング Advent Calendar 2017ですが手法などについてではなくデータ集めについてが中心になります。
画像クローラーについて
動いている環境
- さくらのVPS
- AWS S3
- CentOS 6.7
- Ruby 2.4系
- Rails 5.1系
- MySQL 5.7系
- Redis 2系
- 主な使用ライブラリ: httpclient(通信), Nokogiri(Webスクレイピング) Sidekiq(ワーカーキュー),
FastImage, (MeCab, mecab-ipadic-neologd,Natto(MeCabのRubyラッパー)), 各種SNSのライブラリやAPI
使い方
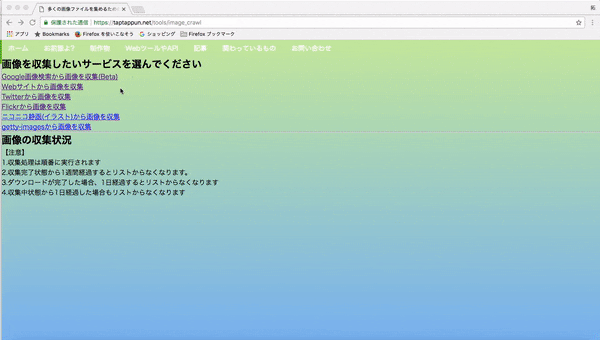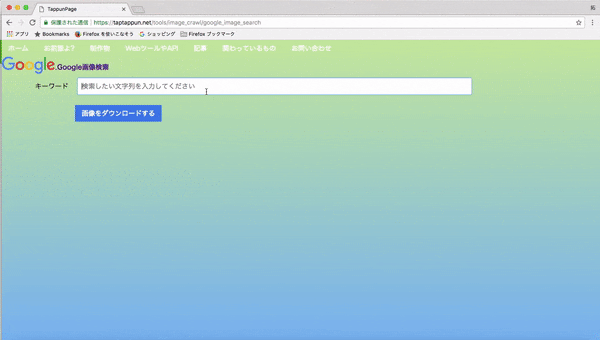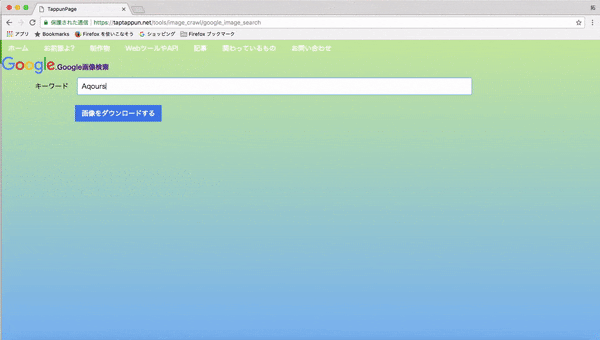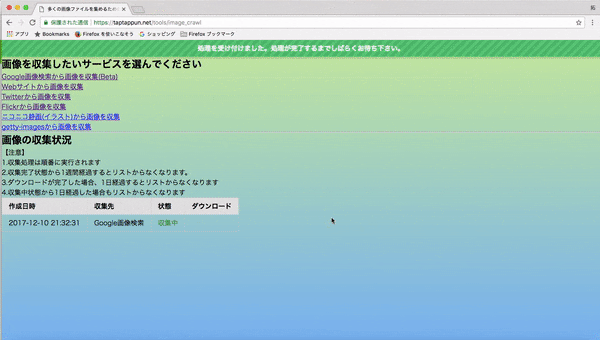
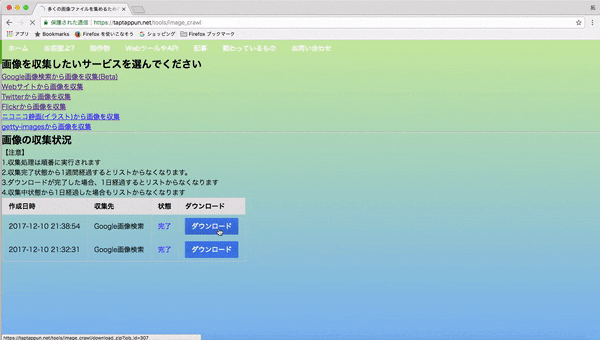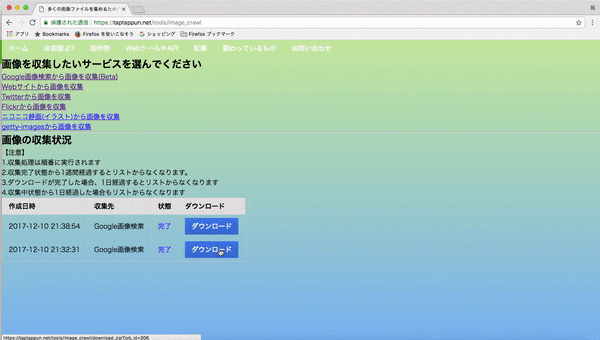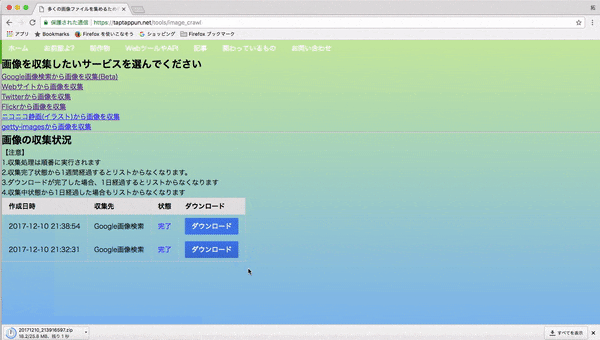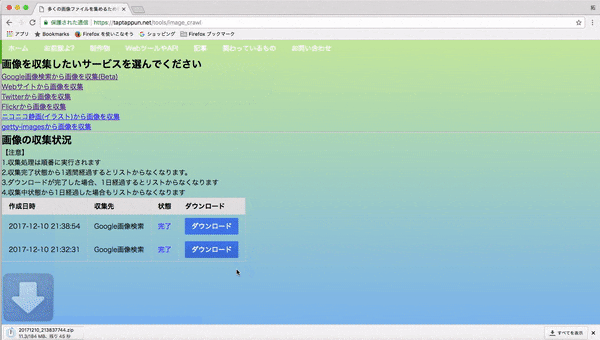
1.webページに行き、集めたい画像のキーワードを入力して画像を集める(集め終わるまで大体5分程かかります)
2.出来上がった頃に再びサイトを訪れてダウンロードする。(1回につき最大500枚の画像をまとめています)
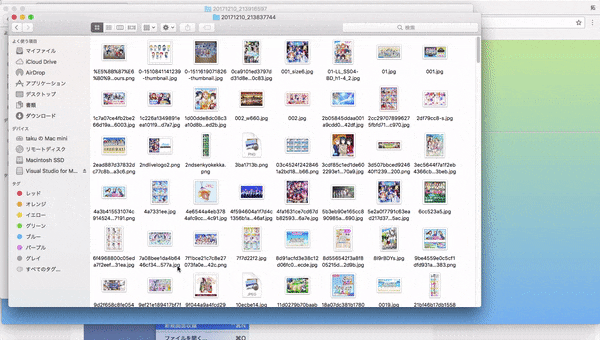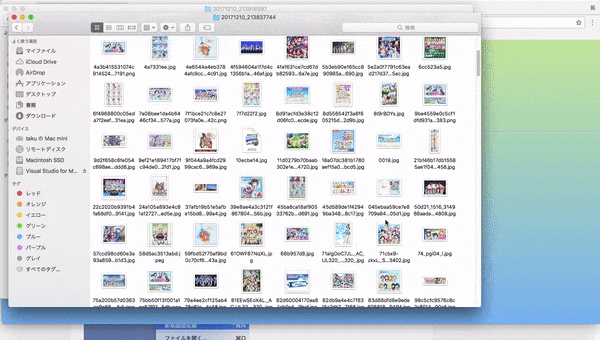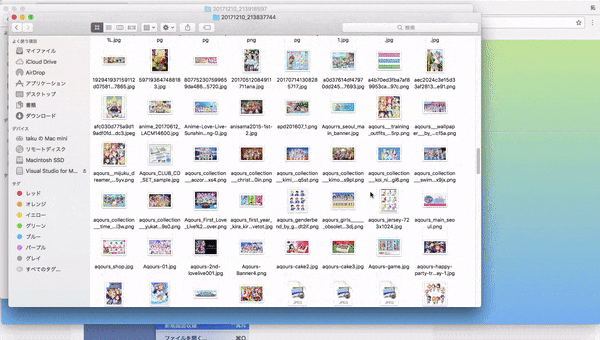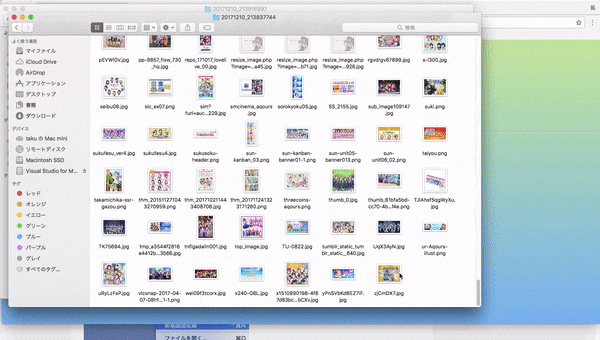
3.zipを展開するとなんかそれらしい画像が集められているのがわかると思います。
管理ツール
管理ツールも作成しています。以下のように、画像とそれに付随したタグ(title)や画像の収集元の情報も保持しています。(これらのデータもzipの中に含めるかどうかはニーズ次第で)
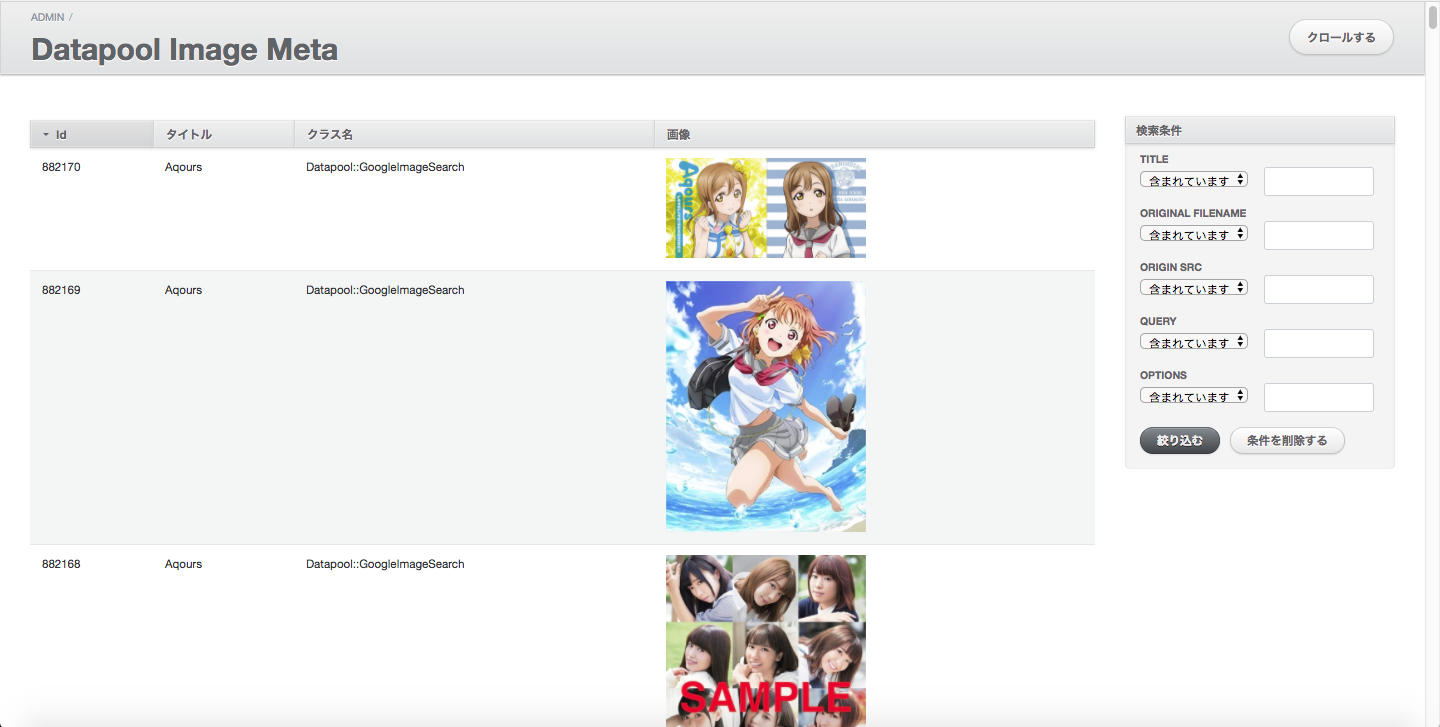
対応状況
現在、以下のWebサービスから検索して画像を集められるようにしています。
- Google画像検索(元画像のサイズで取得しています)
- Flickr
- ニコニコ静画
- getty-images
- Webサイト
今後、対応予定
- Pixiv
- 楽天
- Amazon
他、対応希望のサイトやサービスなどありましたら、実装したいと思います。
また、画像以外にも動画、音楽、PDF、3Dモデル、各種テキストの収集も現在実装しています。また、追加の機能や情報が必要でしたら実装します。
機械学習・ディープラーニング
つくるきっかけ
1. エロく見える画像をたくさん集めたかった
2. 2次元キャラ対話Botを作りたかった
そのために自然言語処理、機械学習・ディープラーニングの勉強をしましたが、
結局、ほとんどの時間がデータ集めに費やしたので、ここらへんをうまくやるためのツールを作成することにしました。
結論
学習させるために大量のデータを集めるのが一番大変!!
勉強したこと
挙げると大量にありすぎてキリがないので大いに参考さてせていただいた文献を各種挙げていきます。
-
ディープラーニング全般
などなどなど
ここらへんの内容を駆使して、りんなのような自然な会話ができるBotを実現するためのアルゴリズムの構築の勉強をしていました。
一応TF-IDFによるキーワード抽出 + MySQLを使っての検索キーワードの最適化を実装しました。該当部分の処理はこちら
https://github.com/TakuKobayashi/citore/blob/master/server/app/models/datapool/hatsugen_komachi.rb
後述のデータ収集時のタグ付けにも応用することができます。
目的のデータを集める手法
基本的にはGoogle画像検索などのWebサービス検索エンジンを活用
検索エンジンを活用
Google画像検索やFlickerなどのSNSには多くの画像があり、また検索エンジンが優秀なため、目的のデータを集めるにはこれらのサービスを活用する(自動化させるバッチを記述する)ことで目的のデータを集めることができます。現在、画像クローラーで実装したサービスにおける画像のキーワードとの結びつきは以下の通り。
| サービス | タグにしたもの | ソースコード |
|---|---|---|
| Google画像検索 | 検索したキーワード | コード |
| ツイート文(上記tf-idfでキーワード抽出) | コード | |
| Flickr | APIにあるtitle | コード |
| ニコニコ静画 | APIから取得できたtitle | コード |
| getty-images | APIから取得できたtitle | コード |
| Webサイト | 後述 | コード |
大体APIなどにあるtitleはその画像がどんな画像なのか表しているので、画像にタグをつける分には有効でした。
Webページからデータを取得
Webページからデータを取得する際、幾つかの工夫が必要でしたのでご紹介します。
Webページから画像のデータを取得する
webサイトにおいて画像を表示する場合HTMLは基本的に以下のように書きます。
<img src="url">
そのため、基本的にimgタグを検索し、そのsrcの中の値をHTMLから取得し、この値を基に画像のデータを取得します。
しかし、このsrcの値の中身は複数種類あるため、それぞれに応じたURLを自動整形する必要があります。
| ケース | 例 | 対応策 |
|---|---|---|
| 絶対URL | http://〜 | そのまま |
| rootパス | /image.jpg | 取得元のURLのホストとrootパスを結合 |
| 相対パス | image.jpg | 取得元のURLのホストとパスに相対パスを結合 |
| Base64 | data:image〜;base64 | 文字列を正規表現で置換し、Base64のデータの部分だけbinaryにencodeしてそのままファイル保存 |
さらに、一部imgタグがついているのに画像ファイルじゃないものも存在したため、一旦ファイルをダウンロードしてそのファイルが画像かどうか判別しています。詳しい処理はこちら
これにより、約99%はどのwebサイトからも画像のデータを取得することができるようになりました。
※なおこの処理を作成しているときほどtypoされているものを恨めしく思ったことはありませんでした。
Webページの画像が何なのか類推する
HTMLの中にはその画像がどんな画像なのか示すヒントがあります。それを基に画像にタグを付けています。
類推の方法は以下の通り
- imgタグ内のaltタグの値
- 1がなかったり、空っぽだったら、imgタグ内のtitleタグの値
- 2がなかったり、空っぽだったら、imgタグ内のnameタグの値
- 3がなかったり、空っぽだったら、imgタグ内の本文の値
- 4もなかったら、サイトのtitleタグの値
類推中、絵文字や文字化けするような文字があった場合全てそれらを除去して見るようにしています。これで大体のサイトでその画像がの画像がどんな画像なのか示すヒントを取得できるようになりました。(他にいい方法があるんですかね?)
Google画像検索による画像の収集について
おそらく最も画像検索のときに使うであろうGoogle画像検索を使っての画像収集の手法についてご紹介します。
-
https://www.google.co.jp/search?q=keyword&tbm=isch これでkeywordで検索された画像が取得できます。(tbm=ischこれが画像検索ということ意味するものです)
-
上記URLを実行した限りだと、75件ぐらいまでしか取れないので、ブラウザで解析したところスクロールページのページ番号を表す、startとijnをキーにした値をURLにつけるとページにまたがって検索できました。(調べた方法については以下のようにネットワークプロファイラを開き、送られているリクエストの値を読んで類推しました)
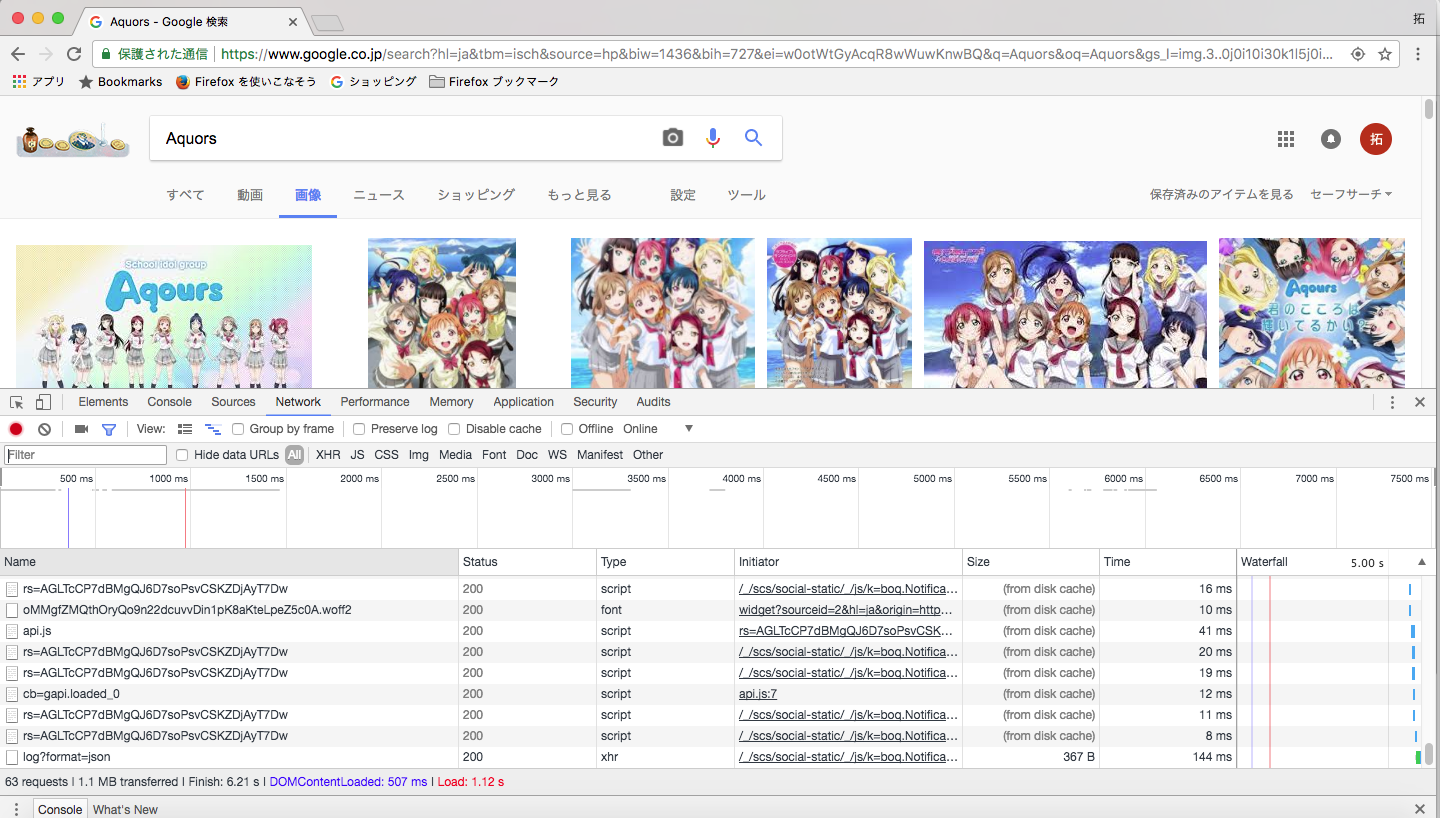
-
Googleの画像検索で取得されたHTMLのimgタグのデータを取得してしまうと小さいサムネイル画像になってしまいました。そこで、Google画像検索結果のHTMLの中にはどうやらaタグの中に元画像のURLとその画像が存在するwebサイトのURLが含まれているようだったので、aタグの中の値からその情報を取得するようにしました。(aタグの中のimgurlキーとimgrefurlキーがそれに該当)
以上の要領でデータを取得するのと同時に、Webページから画像データを取得する手法も併用して更に多くのデータを集めるようにしています。(詳しいソースコードはこちら)
まとめ
とにかく大量の画像を収集することに特化したWebツールを作りましたので紹介しました。
使っていただければ幸いです。
個人的にもこのツールを使って各種ディープラーニングの画像分類を勧めていきたいと思います。
また、ご要望などありましたらブラッシュアップや機能を追加していきたいと思います。