はじめに
任意の文章に対して自動的に感情極性(ポジティブ,ネガティブ)の判定を行うスクリプトを作成したのでまとめてみたいと思います.
文章(文書)から感情極性の判定を行う分野では,Sentiment Analysisや評判分析と呼ぶこともあります.
従来では,単語極性辞書といって単語ごとに極性値(ポジティブ,ネガティブの値)を登録しておいて,それを用いて極性判定する手法がオーソドックスでした.
しかしながら,その手法だと極性辞書にない単語が出た場合に計算が出来ないという問題点や,そもそも単語の極性を一意に定めることが出来るのか?という問題があります.
(e.g. ”安い”という単語1つとっても,安くてお買い得!と言われると安いはポジティブですが,安い奴だなと言われるとネガティブな印象を受けます)
そこで本記事では,テキスト分類器とECサイトのレビューデータを用いてある文章の持つ感情極性を自動的に算出するスクリプトを紹介します.
レビューデータから学習することで, **極性辞書作成の手間を省ける点と構文的な情報を考慮して感情極性を判定できる点(単語の極性値を臨機応変に変えることが出来る)**に旨味が出るのでは!という期待を込めて作りました.
fastText
fastText1は,facebookが開発した単語のベクトル化とテキスト分類をサポートした機械学習です.
構造自体は下図のような3層のニューラルネットワークの構造となっており,Mikolovらの提案したCBoWのモデルにとても良く似た構造を持ちます.
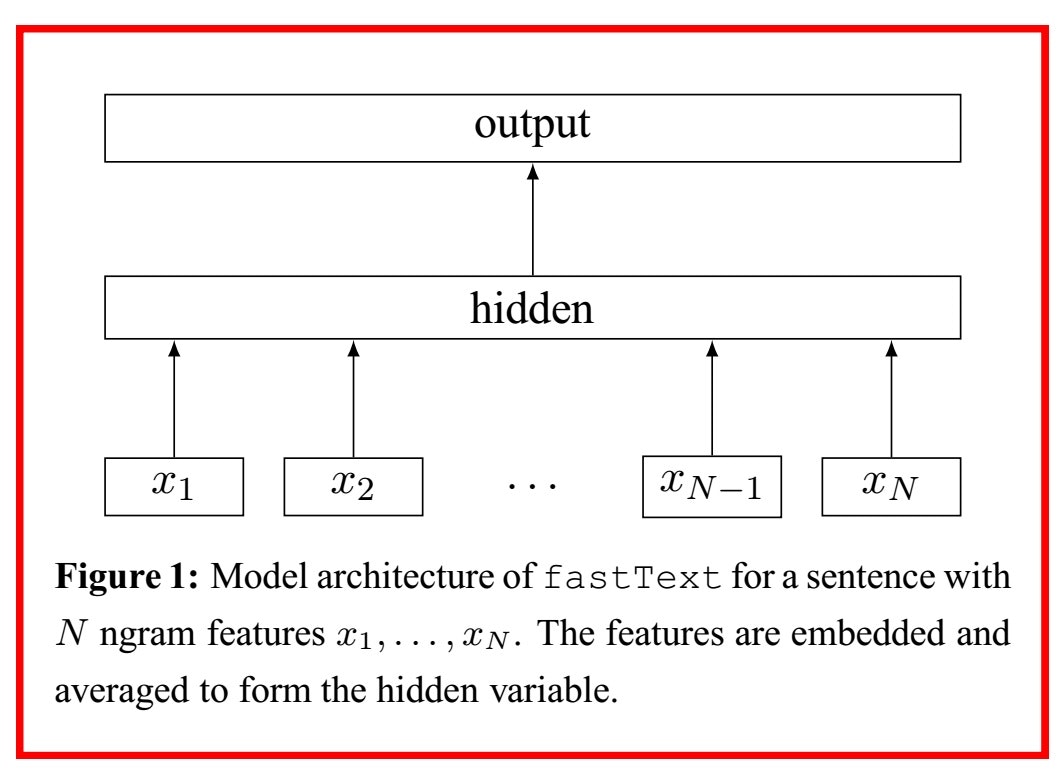
入力層では$i$番目の文書に含まれる単語のone-hotベクトルを与え,出力層でsoftmaxにより各文書が各クラスに所属する確率分布${\bf p}=(p_1,p_2,...,p_n)$を得ます.
排他的分類法(どれか1つのクラスを出力する)では,${\bf p}$の確率値が最も高いクラスを出力します.
学習データ
今回は,ECサイト(Amazonや楽天)のレビューデータを使って,文章の極性判定モデルを作成しました.
商品に対するレビューのうち,星の数を正解ラベル,レビュー本文を学習データとして用意します.
fastTextに学習させる場合,下のようなリストを作ってしまえばOKです.
正解ラベルは,_label_**,学習の素性は文書を分かち書きしたものをラベル以下に記述します.
__label__1, 読書 の 興味 の ない 娘 だっ た ので 、 まったく 見 て くれ ませ ん 。 白黒 だ し 、 挿絵 も かわいく ない ので 一 度 開い た っきり … 読み 聞かせ も だめ で
し た 。
__label__1, 開始 後 3 分 で 完売 し た よう です 。 買え ませ ん でし た 。
fastTextの学習
fastTextの学習はとても簡単です.
学習データ(train.lst)をinput_file,学習したモデルの保存先をoutputとする場合以下のコードだけで学習できます.
argvs = sys.argv
input_file = argvs[1]
output = argvs[2]
classifier = ft.supervised(input_file, output)
文章の感情極性判定
入力として与えた文章の感情極性を以下の式に従って求めます.
$score=\sum^{n}_{i=1}e_i p_i$
- $e_i$: $i$の場合の評価値($e=\{e_1=1, e_2=2,...,e_5=5\}$)
- $p_i$: 入力文が評価$e_i$として判定される確率
上の式で,$p_i$はfastTextの出力層の値,$e_i$は星の数を示しています.
文章の感情極性値$score$は,5に近づくほどpositiveで1に近づくほどnegativeと判定されます.
入力した文章が星の数の多いレビューの性質に近ければ,$score$が高くなります.
# -*- coding: utf-8 -*-
import sys
import commands as cmd
import fasttext as ft
def text2bow(obj, mod):
# input: ファイルの場合はmod="file", input: 文字列の場合はmod="str"
if mod == "file":
morp = cmd.getstatusoutput("cat " + obj + " | mecab -Owakati")
elif mod == "str":
morp = cmd.getstatusoutput("echo " + obj.encode('utf-8') + " | mecab -Owakati")
else:
print "error!!"
sys.exit(0)
words = morp[1].decode('utf-8')
words = words.replace('\n','')
return words
def Scoring(prob):
score = 0.0
for e in prob.keys():
score += e*prob[e]
return score
def SentimentEstimation(input, clf):
prob = {}
bow = text2bow(input, mod="str")
estimate = clf.predict_proba(texts=[bow], k=5)[0]
for e in estimate:
index = int(e[0][9:-1])
prob[index] = e[1]
score = Scoring(prob)
return score
def output(score):
print "Evaluation Score = " + str(score)
if score < 1.8:
print "Result: negative--"
elif score >= 1.8 and score < 2.6:
print "Result: negative-"
elif score >= 2.6 and score < 3.4:
print "Result: neutral"
elif score >= 3.4 and score < 4.2:
print "Result: positive+"
elif score >= 4.2:
print "Result: positive++"
else:
print "error"
sys.exit(0)
def main(model):
print "This program is able to estimate to sentiment in sentence."
print "Estimation Level:"
print " negative-- < negative- < neutral < positive+ < positive++"
print " bad <----------------------------------------> good"
print "Input:"
while True:
input = raw_input().decode('utf-8')
if input == "exit":
print "bye!!"
sys.exit(0)
score = SentimentEstimation(input, model)
output(score)
if __name__ == "__main__":
argvs = sys.argv
_usage = """--
Usage:
python estimation.py [model]
Args:
[model]: The argument is a model for sentiment estimation that is trained by fastText.
""".rstrip()
if len(argvs) < 2:
print _usage
sys.exit(0)
model = ft.load_model(argvs[1])
main(model)
実行方法
コマンドラインから以下のようにして実行します.
$ python estimation.py [model]
実行結果
実際に実行して文章の感情極性判定を行った結果がこちら.
ちなみに一度実行すると対話型になるため,終了したいときは"exit"と入力してください.
This program is able to estimate to sentiment in sentence.
Estimation Level:
negative-- < negative- < neutral < positive+ < positive++
bad <----------------------------------------> good
Input:
昨日行ったラーメン屋すごくおいしかった!
Evaluation Score = 4.41015725
Result: positive++
昨日行ったラーメン屋小汚い感じだったけどとても美味しかったよ!
Evaluation Score = 4.27148227
Result: positive++
昨日行ったラーメン屋オシャレなお店だったけど味はイマイチだったな
Evaluation Score = 2.0507823
Result: negative-
昨日行ったラーメン屋汚いしまずいし散々だったな
Evaluation Score = 1.12695298578
Result: negative--
exit
bye!!
なんだかそれっぽい結果が出てる!
ちゃんと構文的な情報というか,文章の顛末を考えて極性判定出来ている感じが伝わってきます.
まとめ
今回はテキスト分類器fastTextとECサイトのレビューデータを用いて,文章の感情極性判定を自動的に行うスクリプトを作りました.
ECサイトのレビュー文と評価値があれば問題ないので,Amazonでもポンパレモールのデータを使っても同じことができると思います.