RAG、してますか?
・RAGしたい、という社内要望を聞いてデータソースを集めてもらうと、こういう激ムズ図を含むドキュメントがドンドコ出てくる。
・図の内容がすべて文字に情報が起きていればいいが、そうでない場合は図から意図を読み取るという前処理が必要。

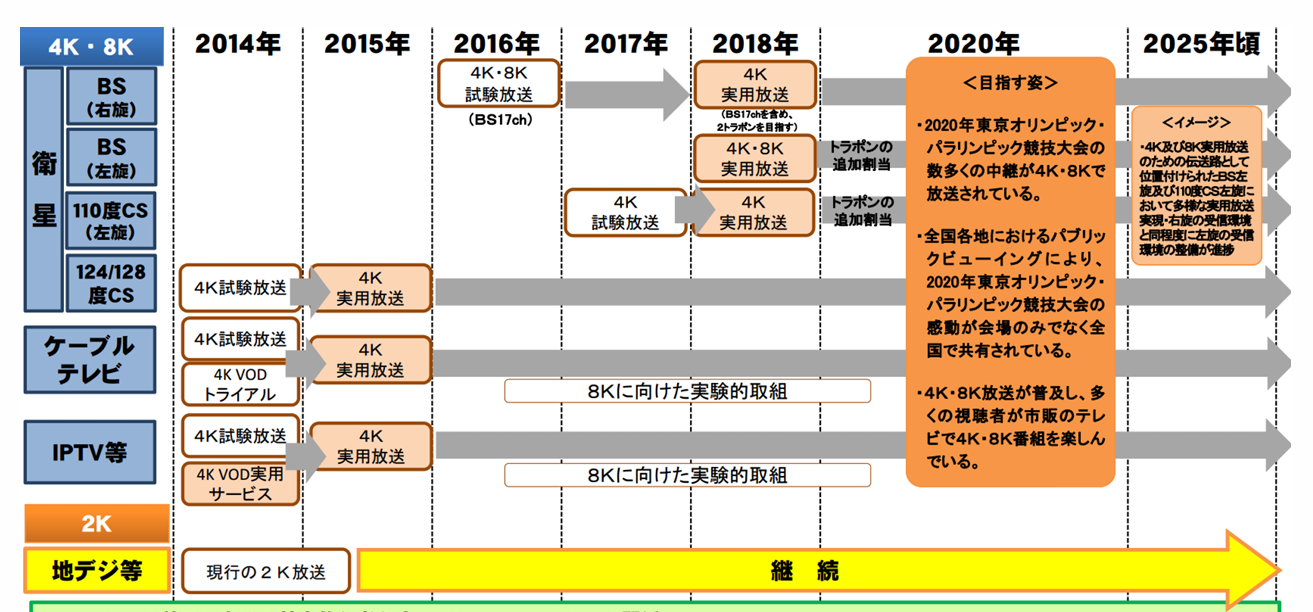
(線表の部分はテキストだけを拾うと意味が分からないものになってしまう)
サクッとエージェント化してみる
・資料には文字と図表が混在してることを想定して、OCRによる文字起こしと画像から意図を抽出する、といった2パターンの処理をエージェント化する。
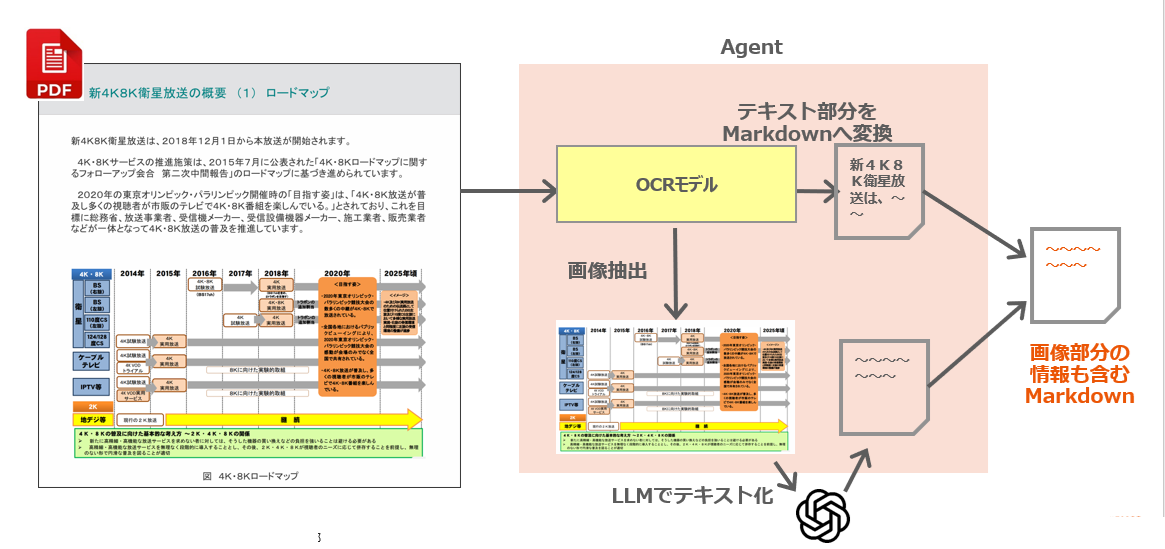
・ocrはDeepSeek-OCRを使う。文書の構造を把握してMarkdown化し、画像部分はそこだけ抽出してくれる。
・EC2にubuntu入れて、もろもろ入れてセットアップ。フロントはStreamlitで適当に。(このへんの詳細はまた別途)
できた。
試してみる
・PDF添付してOCR&要約を実行。しばらくまつ。
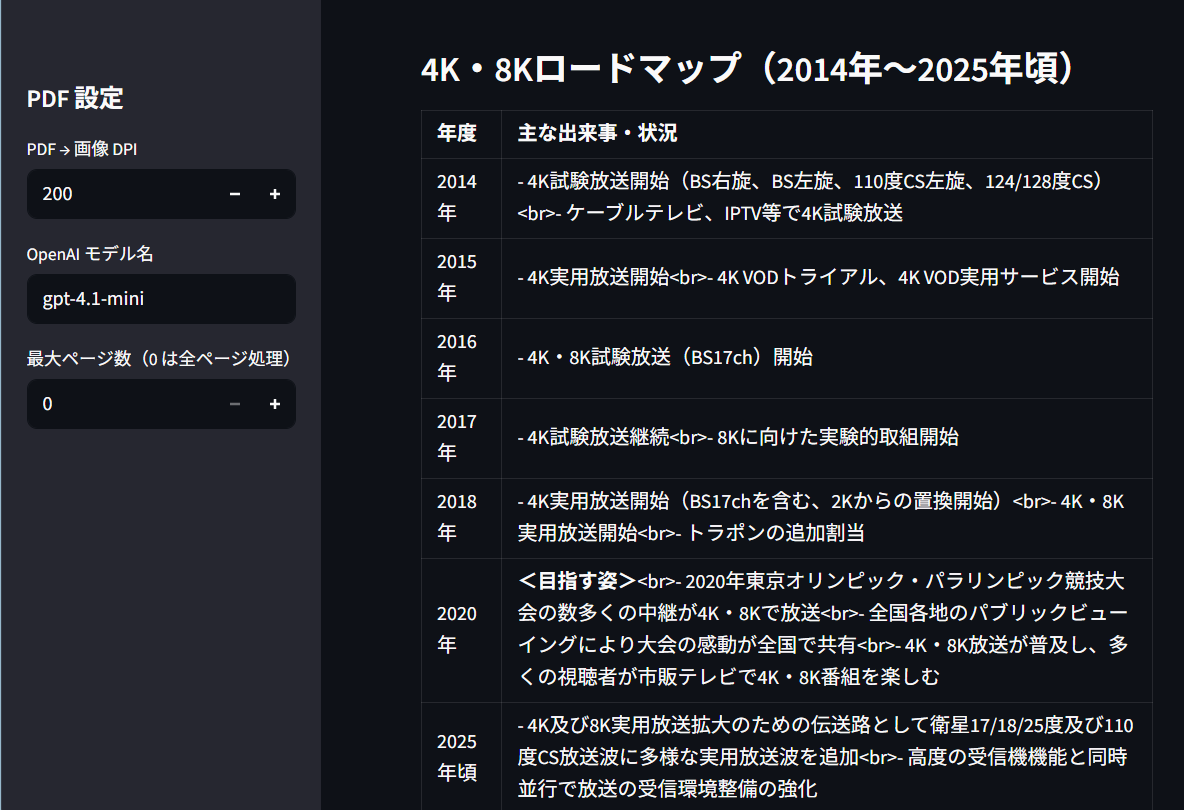
↓元の図
・いい感じ。例えば「124/128度CSの4K試験放送はいつ始まったか?」とかの情報が文字に起きている。
思ったこと&今後
・イメージ図のようなものはそもそも文字起こしをする必要が無いので、画像の内容によって文字起こしの要否を判断したり、動的にプロンプトを生成したりできると精度が上がるのでは。
・今後、もうちょっと手を入れてこれをvector DBに投入するところまで処理させたい。