もうこの絵見て。全部入れたったわ。
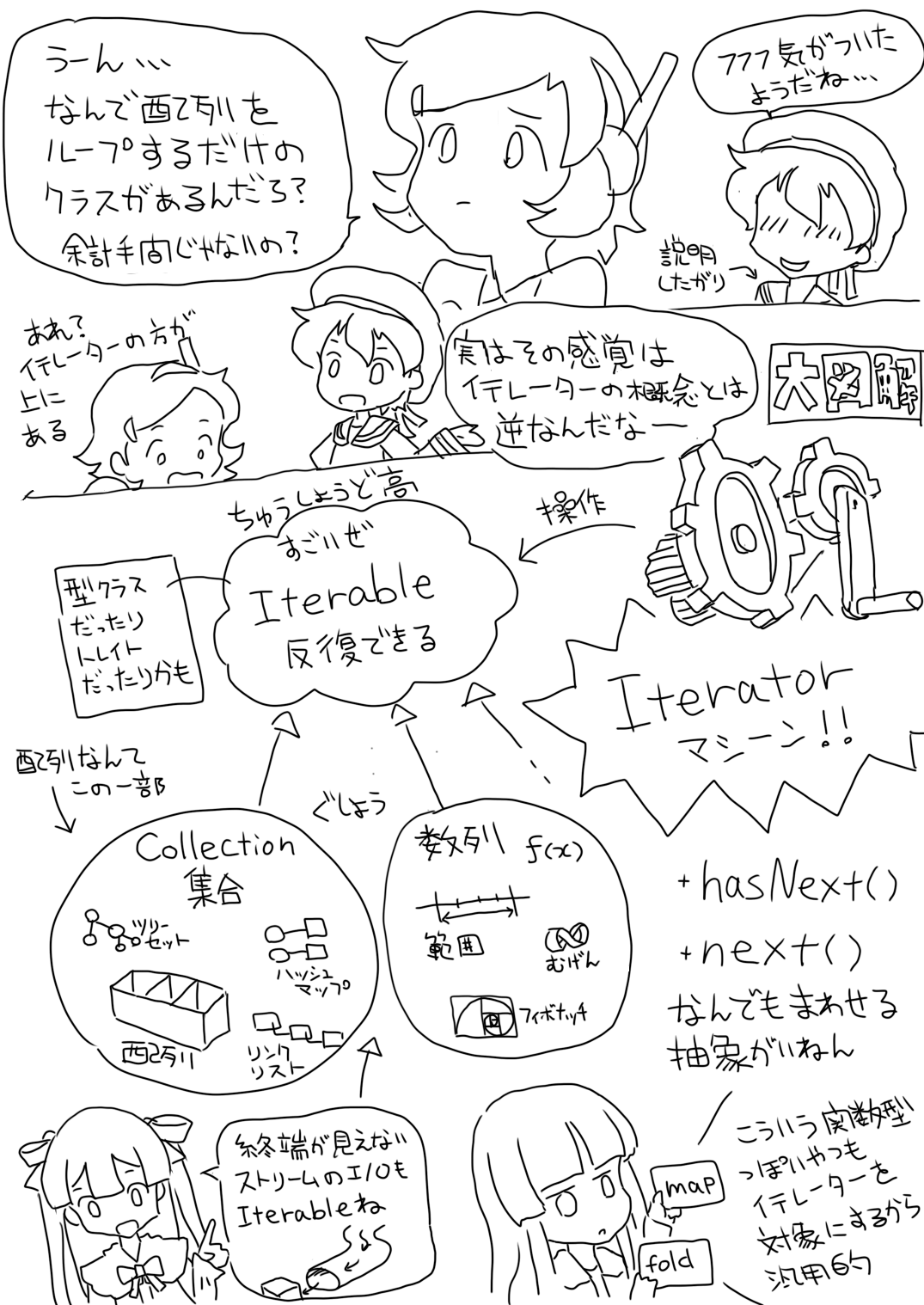
Iterator はただ回りくどいだけの、制限付き配列走査 for ループってことじゃないですよ。単方向読み取り専用配列で扱うほうが安全だからそうしてるんだよねと思ってたら、大きく誤解しちゃいますよ。
反復可能 = Iterable は、さまざまなデータ構造 (型) に共通する、かなり上位の抽象概念 (型クラスとかかも) です。その概念の、人が触れることができる操作部分が Iterator なのです。
単純な固定長配列以外にも、データ構造にはさまざまなものがあります。データ構造を直接扱うと、それぞれ固有のアルゴリズムで繰り返しを作らないといけません。また、計算で要素が生成されるもの、走査開始時点でまだ終端がわからないもの、そもそも終わりのない無限反復、といった、for (i = 0; i < 要素数; i++) では表せないものも、反復可能であるのは確かです。
データ構造に対してハードコードする繰り返しでビジネスロジックを書いてしまうと、後で対象データの構造を変更したいときが大変です。せっかくオブジェクト指向の醍醐味=ポリモーフィズムがあるのに、データ構造の実装をシュッと差し替えできないのは、残念ですね。
たとえば、単体テストでは固定数の素朴な配列を使っておき、本番ではストリーミングIOで非同期にデータが来る、みたいなの、やりたいじゃないですか。
そこで出ました「関心の分離」です。「反復可能」という概念に着目して、繰り返しの実体にまつわる複雑さと、繰り返されるビジネスロジックとを分離するのです。そして、繰り返しなんてのは Iterator と呼ばれるなにか (抽象) がやってくれるはず、こっちの仕事はその中身どうするかだけに集中、と自己完結しちゃいましょう。
モダンなプログラミング言語やフレームワークを使っていると、標準機能の中に Iterator が折り込み済みで、いつの間にか無意識にできていたりします。標準の組み込み機能にしてしまうぐらい、これ有用なパターンなんですよね。
だったらわざわざ自分でやらなくたって... まったくそのとおりです。くどいかもしれませんが、デザインパターンは、プログラムを書くためのスキルではない、という話です。名前を持っている概念、その意味を共有して理解するのが、いちばん大事なとこですよ。だからこそ、みんな大好き Iterator の理解はぜったいに外せませんよね。