共有すること
CSVに保存したデータを使って、DeepLearingを実装する方法
今回は、CSVに保存したワイン1,600本分のデータを学習し未知のワインの味を10段階評価するAIソムリエとして実装する。

なぜ共有するのか?
主な目的は、下記の3点
① DeepLearningに関する知識を定着化するため
② プログラミング実務未経験でも用意されているライブラリを使えばDeepLearningを実装できることを横展開したいため
③ 忘れた時に見直すため
「ゼロから学ぶDeepLearning」を読んだ。何となくわかりそうだけど、どう実装すればいいかわからなかった。
その時に参加したDeepLearningに関するセミナーが凄くわかりやすかった。
その時に学んだ知識を自分なりに咀嚼し直して、知識の型化・横展開をしたいと思った。
この記事でわかること
① CSVデータをPythonを使って、訓練データとテストデータに分ける
② そのデータをニューラルネットワークに学習させる
③ 任意のデータを投入して、ニューラルネットワークに推論させる
今回は実際には存在しないワインのデータを投入して、その味を10段階評価する
この記事を書いた人の特徴
・独学でプログラミングを勉強中
・プログラミングの実務経験なし
・大学時代はゴリゴリの文系(教育学部)で、数学が苦手。
・プログラミングにも全く興味なかった。
・ワインの知識は0
この記事を読むのに向いている人
・Pythonを勉強している
・とりあえず自分の手を動かしながら学びたい
・「ゼロから学ぶDeepLearning」を一通り読んだ。なんとなくわかりそうだけど、どうやって実装するかイメージできない
・機械学習の実装の流れを体感したい
・「手書き文字の認識」以外もしたい
・CSVに保存したデータでDeepLearningを実装したい
・ワインが好き
この記事を読むのに向いていない人
機械学習で用いられる理論をちゃんと説明してほしい人
開発環境
MacOS 10.13.3
Python 3.6.3
前提条件
①CSVにまとめたデータを解析するコードはデスクトップに保存したwine.pyに実装
②今回利用するデータの内容
・ワイン(合計:1,600本)に含まれる成分(11種類)を分析して数値化したもの
・それぞれの味を10段階で評価したデータ
③ワインのデータは、デスクトップ上にwinequality-red.csvとして保存
※ CSV は下記の参考資料から取得可能
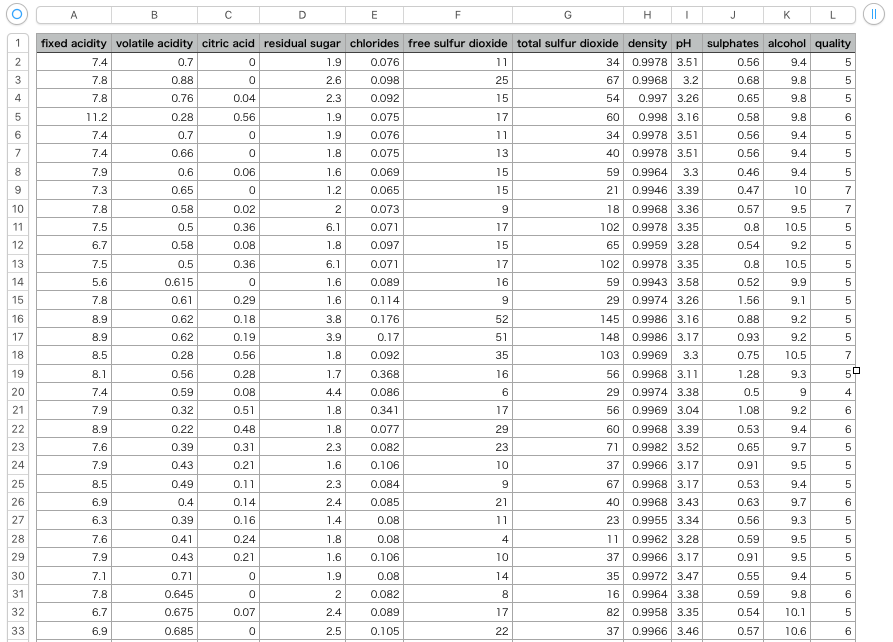
列とそれぞれの内容
| 列名 | 内容 | 備考 |
|---|---|---|
| fixed acidity | 酒石酸濃度 | |
| volatile acidity | 酢酸濃度 | |
| citric acid | クエン酸濃度 | |
| residual sugar | 残糖濃度 | |
| chlorides | 塩化ナトリウム濃度 | |
| free sulfur dioxide | 遊離SO2(二酸化硫黄)濃度 | |
| total sulfur dioxide | 総SO2(二酸化硫黄)濃度 | |
| density | 密度 | |
| pH | 水素イオン濃度 | 1:酸性 7:中性 14:アルカリ性 |
| sulphates | 硫化カリウム濃度 | |
| alcohol | アルコール度数 | |
| quality | 評価 | 10段階評価で評価したもの |
DeepLearning実装の流れ
①データの準備・整形(今回はCSVに保存されたデータの整形)
②ニューラルネットワークの実装
③実装したニューラルネットワークにデータを学習させる
④ニューラルネットワークに推論させる
⑤その推論が合っているかどうか確認
コード例
今回実装するニューラルネットワークは下記のような内容
| 項目 | |
|---|---|
| 入力層のサイズ | 50 |
| 隠れ層の数 | 3 |
| 隠れ層のユニット数 | 50 |
| 出力層のサイズ | 10 |
| 活性化関数 | relu |
| 誤差関数 | mean_squared_error |
| 勾配法 | RMSprop() |
| 学習回数 | 2000回 |
#モジュールの読み込み
from __future__ import print_function
import pandas as pd
from pandas import Series,DataFrame
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras.datasets import fashion_mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
from keras.optimizers import Adam
#CSVファイルの読み込み
wine_data_set = pd.read_csv("winequality-red.csv",sep=";",header=0)
#説明変数(ワインに含まれる成分)
x = DataFrame(wine_data_set.drop("quality",axis=1))
#目的変数(各ワインの品質を10段階評価したもの)
y = DataFrame(wine_data_set["quality"])
#説明変数・目的変数をそれぞれ訓練データ・テストデータに分割
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.05)
#データの整形
x_train = x_train.astype(np.float)
x_test = x_test.astype(np.float)
y_train = keras.utils.to_categorical(y_train,10)
y_test = keras.utils.to_categorical(y_test,10)
#ニューラルネットワークの実装①
model = Sequential()
model.add(Dense(50, activation='relu', input_shape=(11,)))
model.add(Dropout(0.2))
model.add(Dense(50, activation='relu', input_shape=(11,)))
model.add(Dropout(0.2))
model.add(Dense(50, activation='relu', input_shape=(11,)))
model.add(Dropout(0.2))
model.add(Dense(10, activation='softmax'))
model.summary()
print("\n")
#ニューラルネットワークの実装②
model.compile(loss='mean_squared_error',optimizer=RMSprop(),metrics=['accuracy'])
#勾配法には、Adam(lr=1e-3)という方法もある(らしい)。
#ニューラルネットワークの学習
history = model.fit(x_train, y_train,batch_size=200,epochs=1000,verbose=1,validation_data=(x_test, y_test))
#ニューラルネットワークの推論
score = model.evaluate(x_test,y_test,verbose=1)
print("\n")
print("Test loss:",score[0])
print("Test accuracy:",score[1])
#10段階評価したいワインの成分を設定
sample = [7.9, 0.35, 0.46, 5, 0.078, 15, 37, 0.9973, 3.35, 0.86, 12.8]
print("\n")
print("--サンプルワインのデータ--")
print(sample)
#ポイント:ワインの成分をNumpyのArrayにしないとエラーが出る
sample = np.array(sample)
predict = model.predict_classes(sample.reshape(1,-1),batch_size=1,verbose=0)
print("\n")
print("--予測値--")
print(predict)
print("\n")
#学習履歴のグラフ化に関する参考資料
#http://aidiary.hatenablog.com/entry/20161109/1478696865
def plot_history(history):
# print(history.history.keys())
# 精度の履歴をプロット
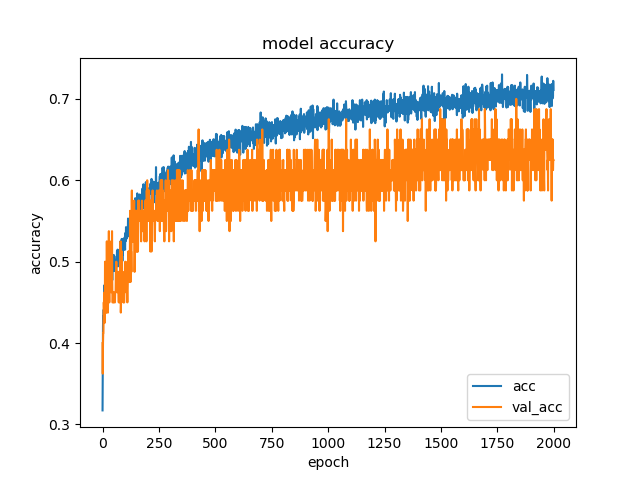
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['acc', 'val_acc'], loc='lower right')
plt.show()
# 損失の履歴をプロット
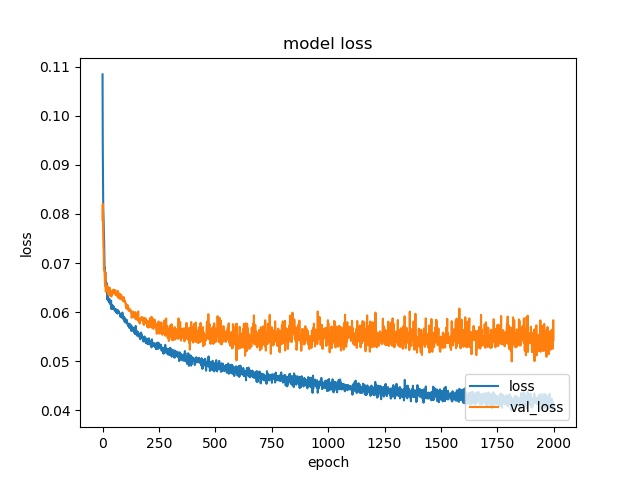
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['loss', 'val_loss'], loc='lower right')
plt.show()
# 学習履歴をプロット
plot_history(history)
実行結果
下記コマンドを入力して、コードを実行
cd desktop
python wine.py
Using TensorFlow backend.
/anaconda3/lib/python3.6/importlib/_bootstrap.py:219: RuntimeWarning: compiletime version 3.5 of module 'tensorflow.python.framework.fast_tensor_util' does not match runtime version 3.6
return f(*args, **kwds)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 50) 600
_________________________________________________________________
dropout_1 (Dropout) (None, 50) 0
_________________________________________________________________
dense_2 (Dense) (None, 50) 2550
_________________________________________________________________
dropout_2 (Dropout) (None, 50) 0
_________________________________________________________________
dense_3 (Dense) (None, 50) 2550
_________________________________________________________________
dropout_3 (Dropout) (None, 50) 0
_________________________________________________________________
dense_4 (Dense) (None, 10) 510
=================================================================
Total params: 6,210
Trainable params: 6,210
Non-trainable params: 0
_________________________________________________________________
Train on 1519 samples, validate on 80 samples
Epoch 1/2000
2018-02-26 20:23:28.314973: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
1519/1519 [==============================] - 1s 385us/step - loss: 0.1085 - acc: 0.3173 - val_loss: 0.0787 - val_acc: 0.4000
Epoch 2/2000
1519/1519 [==============================] - 0s 17us/step - loss: 0.0938 - acc: 0.3752 - val_loss: 0.0821 - val_acc: 0.3625
Epoch 3/2000
1519/1519 [==============================] - 0s 19us/step - loss: 0.0868 - acc: 0.4213 - val_loss: 0.0796 - val_acc: 0.4000
Epoch 4/2000
1519/1519 [==============================] - 0s 20us/step - loss: 0.0817 - acc: 0.4332 - val_loss: 0.0760 - val_acc: 0.4125
Epoch 5/2000
1519/1519 [==============================] - 0s 24us/step - loss: 0.0799 - acc: 0.4299 - val_loss: 0.0732 - val_acc: 0.4125
(...中略...)
Epoch 1996/2000
1519/1519 [==============================] - 0s 16us/step - loss: 0.0416 - acc: 0.7005 - val_loss: 0.0544 - val_acc: 0.6375
Epoch 1997/2000
1519/1519 [==============================] - 0s 16us/step - loss: 0.0415 - acc: 0.7123 - val_loss: 0.0525 - val_acc: 0.6500
Epoch 1998/2000
1519/1519 [==============================] - 0s 17us/step - loss: 0.0406 - acc: 0.7031 - val_loss: 0.0543 - val_acc: 0.6125
Epoch 1999/2000
1519/1519 [==============================] - 0s 17us/step - loss: 0.0401 - acc: 0.7222 - val_loss: 0.0583 - val_acc: 0.6250
Epoch 2000/2000
1519/1519 [==============================] - 0s 17us/step - loss: 0.0412 - acc: 0.7110 - val_loss: 0.0543 - val_acc: 0.6250
80/80 [==============================] - 0s 35us/step
Test loss: 0.054320948571
Test accuracy: 0.625
--サンプルワインのデータ--
[7.9, 0.35, 0.46, 5, 0.078, 15, 37, 0.9973, 3.35, 0.86, 12.8]
--予測値--
[7]
サンプルとして用意した任意のワインデータに対し、今回実装したAIソムリエはその味は10段階評価で[7]と評価した。
(ただし、正解率は62.5%と低い。)
学習履歴のグラフ化
このコードを実装している間に抱いた感想
投入したデータは本当にワインなのか? は、今回実装したコードでは判断できない。
下記データは 密度:1.0 / pH:7.0 で酒石酸・クエン酸等ワインに含まれている成分が一切含まれていない液体(=水)である。
[0,0,0,0,0,0,0,1,7,0,0]
このデータをAIソムリエに投入すると、[5] の結果を返す。
ここから、AIが推論した結果を盲目的に信用せず、本当に正しいかどうか検証するのが人間の役割になると感じた。
今後の課題
・正解率の向上
・なぜ、損失関数として〇〇を使うのか?/なぜ、学習回数が〇〇回なのか?/なぜ、隠れ層は◯層なのか? などを説明できる深い知識
参考資料
イベント
HP
《DeepLearningを気軽に実装できるライブラリ》
Keras
《Kerasを利用して実際にDeepLearningを実装する方法》
[Python]プログラミング実務未経験でもできる!60,000点のファッションアイテムのデータを使ってDeepLearningを実装する方法
《CSVデータを訓練データ・テストデータに分割する方法》
[Python]CSVデータをPythonを使ってデータを読み込む方法(赤ワイン1,600本分)
《学習経過の履歴をグラフ化して表示する方法》
KerasでMNIST - 人工知能に関する断創録
書籍
ゼロから作るDeep Learning
――Pythonで学ぶディープラーニングの理論と実装
データセット
赤ワインのデータ(1,600本分)
下記アドレスをクリックすると、CSVデータとしてダウンロード可能。
http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality
Docker を利用して Jupyter を構築
PC をできるだけ汚したくない場合や M1 Mac を使っていて Python をインストールできない場合、Docker を利用してみてはいかがでしょうか?
下記記事に手順をまとめていますので、参考になさってください。