共有すること
60,000点のファッションアイテムのデータを使って、DeepLearningを実装する方法
この記事を書いた人の特徴
・独学でプログラミングを勉強中
・プログラミングの実務経験なし
・大学時代はゴリゴリの文系(教育学部)で、数学が苦手。プログラミングにも全く興味なかった。
なぜ共有するのか?
主な目的は、下記の3点
①DeepLearningに関する知識を定着化するため
②プログラミング実務未経験でも用意されているライブラリを使えばDeepLearningを実装できることを横展開したいため
③忘れた時に見直すため
「ゼロから学ぶDeepLearning」を読んだ。何となくわかりそうだけど、どう実装すればいいかわからなかった。
その時に参加したDeepLearningに関するセミナーが凄くわかりやすかった。
その時に学んだ知識を自分なりに咀嚼し直して、知識の型化・横展開をしたいと思った。
この記事を読むのに向いている人
・Pythonを勉強している
・とりあえず自分の手を動かしながら学びたい
・「ゼロから学ぶDeepLearning」を一通り読んだ。なんとなくわかりそうだけど、どうやって実装するかイメージできない
・機械学習の実装の流れを体感したい
・「手書き文字の認識」以外もしたい
・ファッションが好き
この記事を読むのに向いていない人
・機械学習で用いられる理論をちゃんと説明してほしい人
開発環境
MacOS 10.13.3
Python 3.6.3
前提条件
コードはデスクトップに保存した《sample.py》に実装
DeepLearning実装の流れ
①データの準備・整形
②ニューラルネットワークの実装
③実装したニューラルネットワークにデータを学習させる
④ニューラルネットワークに推論させる
⑤その推論が合っているかどうか確認
コード例
# 各種モジュール(Keras/NumPy/Matplotlib)のインポート
from __future__ import print_function
import keras
from keras.datasets import fashion_mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
import numpy as np
import matplotlib.pyplot as plt
# データセットの取得(訓練データとテストデータの分割)
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
# データの内容確認
print("\n")
print("--データの内容確認--")
print(x_train.shape) #(60000, 28, 28)
print(x_test.shape) #(10000, 28, 28)
print(y_train.shape) #(60000,)
print(y_test.shape) #(10000,)
print("\n")
# データの整形
# Numpyのreshameメゾットを利用
x_train = x_train.reshape(60000,784)
x_test = x_test.reshape(10000,784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# データの正規化
x_train /= 255
x_test /= 255
# テストデータの内容確認
print("\n")
print("--x_train[0]--")
print("\n")
for a in range(28):
w = ""
for b in range(28):
w_next = "{0:.0f}".format(x_train[0][28 * a + b]) + " " #format関数 "{0:指定したい書式の型}".format(変数)
w += w_next
print(w)
print("\n")
# 訓練データの整形
y_train = keras.utils.to_categorical(y_train,10)
y_test = keras.utils.to_categorical(y_test,10)
# ニューラルネットワークの実装①
# 今回のニューラルネットワーク:入力層 → 隠れ層① → 隠れ層② → 出力層
# relu:Relu関数/softmax:softmax関数
# Dropout:ドロップアウト(過学習を防ぐために設定 → 推論の精度が向上する)
## 入力層
model = Sequential()
## 隠れ層①
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dropout(0.2))
## 隠れ層②
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
## 出力層
model.add(Dense(10, activation='softmax'))
## 要約の出力
model.summary()
print("\n")
# ニューラルネットワークの実装②
# loss:損失関数の設定(categorical_crossentropy:クロスエントロピー)
# optimizer:最適化アルゴリズムの設定(RMSprop:リカレントニューラルネットワークに対して設定するのが良いらしい)
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
# ニューラルネットワークの学習
# epochs:ニューラルネットワークに何回学習させるか
history = model.fit(x_train, y_train,
batch_size=128,
epochs=20,
verbose=1,
validation_data=(x_test, y_test))
# ニューラルネットワークの推論
score = model.evaluate(x_test,y_test,verbose=0)
print("\n")
print("Test loss:",score[0])
print("Test accuracy:",score[1])
print("\n")
# ニューラルネットワークの推論があっているか確認
## 推論した結果(数字)とファッションアイテム名は、下記のitemsのように設定されている
def fashion_classify(predict):
items = {0:"Tシャツ/トップス",1:"ズボン",2:"プルオーバー",3:"ドレス",4:"コート",5:"サンダル",6:"シャツ",7:"スニーカー",8:"バック",9:"アンクルブーツ"}
return items[int(predict)]
## 結果表示
print("--x_test[0]の推論結果--")
predict = model.predict_classes(x_test[0].reshape(1,-1),batch_size=1,verbose=0)
print(fashion_classify(predict))
print("----")
print("\n")
# 画像を表示
img = x_test[0].reshape(28,28)
plt.imshow(img)
plt.show()
実行結果
下記コマンドで実行
cd desktop
python sample.py
Using TensorFlow backend.
/anaconda3/lib/python3.6/importlib/_bootstrap.py:219: RuntimeWarning: compiletime version 3.5 of module 'tensorflow.python.framework.fast_tensor_util' does not match runtime version 3.6
return f(*args, **kwds)
--データの内容確認--
(60000, 28, 28)
(10000, 28, 28)
(60000,)
(10000,)
--x_train[0]--
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 0 1 1 0 0 0 0 1 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 0 0 1 1 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0
0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0
0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0
0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0
0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0
0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0
0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1 1 0
0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0
0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0
0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0
0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0
0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 512) 401920
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_2 (Dropout) (None, 512) 0
_________________________________________________________________
dense_3 (Dense) (None, 10) 5130
=================================================================
Total params: 669,706
Trainable params: 669,706
Non-trainable params: 0
_________________________________________________________________
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
2018-02-25 14:12:50.765432: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
60000/60000 [==============================] - 12s 207us/step - loss: 0.5601 - acc: 0.7955 - val_loss: 0.4364 - val_acc: 0.8362
Epoch 2/20
60000/60000 [==============================] - 12s 196us/step - loss: 0.4017 - acc: 0.8532 - val_loss: 0.3862 - val_acc: 0.8567
Epoch 3/20
60000/60000 [==============================] - 12s 200us/step - loss: 0.3698 - acc: 0.8663 - val_loss: 0.3815 - val_acc: 0.8638
Epoch 4/20
60000/60000 [==============================] - 12s 194us/step - loss: 0.3496 - acc: 0.8733 - val_loss: 0.4229 - val_acc: 0.8556
Epoch 5/20
60000/60000 [==============================] - 14s 226us/step - loss: 0.3382 - acc: 0.8794 - val_loss: 0.3706 - val_acc: 0.8759
Epoch 6/20
60000/60000 [==============================] - 13s 221us/step - loss: 0.3293 - acc: 0.8823 - val_loss: 0.3795 - val_acc: 0.8738
Epoch 7/20
60000/60000 [==============================] - 14s 233us/step - loss: 0.3207 - acc: 0.8843 - val_loss: 0.3665 - val_acc: 0.8743
Epoch 8/20
60000/60000 [==============================] - 13s 214us/step - loss: 0.3167 - acc: 0.8872 - val_loss: 0.3661 - val_acc: 0.8779
Epoch 9/20
60000/60000 [==============================] - 15s 254us/step - loss: 0.3089 - acc: 0.8915 - val_loss: 0.3638 - val_acc: 0.8764
Epoch 10/20
60000/60000 [==============================] - 15s 242us/step - loss: 0.3042 - acc: 0.8936 - val_loss: 0.3886 - val_acc: 0.8766
Epoch 11/20
60000/60000 [==============================] - 13s 213us/step - loss: 0.2985 - acc: 0.8934 - val_loss: 0.3799 - val_acc: 0.8753
Epoch 12/20
60000/60000 [==============================] - 12s 208us/step - loss: 0.2989 - acc: 0.8950 - val_loss: 0.3841 - val_acc: 0.8807
Epoch 13/20
60000/60000 [==============================] - 13s 211us/step - loss: 0.2899 - acc: 0.8977 - val_loss: 0.3806 - val_acc: 0.8792
Epoch 14/20
60000/60000 [==============================] - 13s 217us/step - loss: 0.2906 - acc: 0.8993 - val_loss: 0.4081 - val_acc: 0.8796
Epoch 15/20
60000/60000 [==============================] - 14s 230us/step - loss: 0.2876 - acc: 0.9005 - val_loss: 0.4055 - val_acc: 0.8775
Epoch 16/20
60000/60000 [==============================] - 13s 215us/step - loss: 0.2828 - acc: 0.9002 - val_loss: 0.3899 - val_acc: 0.8846
Epoch 17/20
60000/60000 [==============================] - 14s 227us/step - loss: 0.2817 - acc: 0.9022 - val_loss: 0.4105 - val_acc: 0.8788
Epoch 18/20
60000/60000 [==============================] - 14s 240us/step - loss: 0.2807 - acc: 0.9022 - val_loss: 0.4054 - val_acc: 0.8792
Epoch 19/20
60000/60000 [==============================] - 13s 212us/step - loss: 0.2767 - acc: 0.9037 - val_loss: 0.4485 - val_acc: 0.8707
Epoch 20/20
60000/60000 [==============================] - 14s 229us/step - loss: 0.2704 - acc: 0.9057 - val_loss: 0.4265 - val_acc: 0.8871
Test loss: 0.426543106937
Test accuracy: 0.8871
--x_test[0]の推論結果--
アンクルブーツ
----
表示された画像
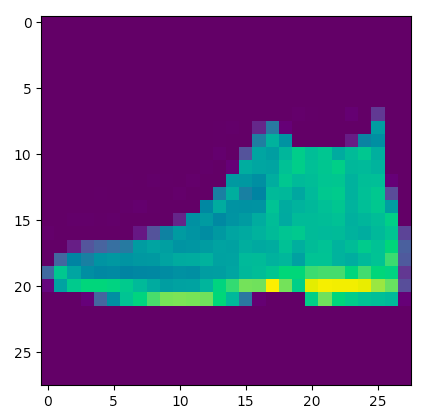
ニューラルネットワークの推論と実際のデータが合致したことがわかる。
今後の課題
・DeepLearningで用いられている語句の理解
・他のデータセット(アヤメの分類/赤ワインの味を10段階で評価したもの)をKerasで使えるようにする方法
・自分でデータセットを準備する方法
・DeepLearningを使えば社会が抱えるどんな課題が解決できるか考える(例:きゅうりの自動仕訳)
・その課題を解決するために、実際に実装してみる
・正解率の向上