前回に引き続き, OpneAIのgymで強化学習を実装してみました。CartPoleを深層強化学習でやってみたので紹介します。強化学習についての具体的な説明は, 前回の記事や前々回の記事をご覧ください。
前々回の記事 強化学習で山を登りたい
前回はSARSAとQ学習法の比較を行っています。
深層強化学習とは
前回の記事で触れた価値ベースの強化学習であるQ学習ですが, DeepQ学習手法を用いたいと思います。ではおさらいです。強化学習において,状態行動価値$Q\left( s_{t},a_{t}\right)$は, 遷移先で得られる価値$r_{t+1}$と学習率$\gamma$で表される, $r_{t+1}+\gamma\max_{a\in At}[Q(s_{t+1},a)]$に収束させることが目的でした。
なんだ簡単ですね。つまり深層学習でいう損失関数$L$を
$$L=(r_{t+1}+\gamma\max_{a\in At}[Q(s_{t+1},a)]-Q\left( s_{t},a_{t}\right))^2$$
として最適化を行っていけば良さそうです。
DDQN(Double DQN)
先ほど述べたQ-Learningの学習規則は, 目標とする値$r_{t+1}+\gamma\max_{a\in At}[Q(s_{t+1},a)]$に用いる状態行動価値は教師でありながら更新もされているので, 動的に最適化を行っていく手法です。これに対して, 教師とする状態行動価値を古いパラメータのものにすれば, 目標値と現在の学習している状態価値関数における相関を取り除き, 学習の発散, 振動を抑えることができます。よって, ターゲットとする値は新たな状態価値関数$Q^\theta(s_{t+1},a)$とすると,
$$r_{t+1}+\gamma\max_{a\in At}[Q^\theta(s_{t+1},a)]=Q(s_{t},a_{t})$$
となるように最適化をしていけばいいですね。このターゲットとする状態価値関数の重みは定期的に学習中のものからコピーして更新しながら学習を行います。
Experience Replay
今回の学習ではExperience Replayも使ってます。通常の強化学習では一つの行動をして次の状態に移動した際に, 状態価値関数の更新を行います。しかし今回の手法では, キューに遷移と報酬の履歴を保存し, 学習時にサンプルしてバッチ的に学習することで, サンプルの系列において時間的相関があると確率的勾配法がうまく働かなくなる問題を緩和しています。
CartPoleルール

この棒を長い間(500step)立て続ければクリアという形式です。与えられる状態は四つで, 台車の位置, 台車の速度, ポールの角度, ポールの角速度が与えられます。行動は, 左に台車を押す:0, 右に押す:1の2つに制限されます。ポールの角度が12度以上傾くか, 500ステップ耐久で終了です。
実装
今回はColab上でも動くように, コードを書いているのでよろしくお願いします。
まずはいろいろインストール。colabでアニメーションを描画するツールなどです。
# Colabで可視化するための依存ツールinstall
!apt update
!apt install xvfb
!apt-get -qq -y install libcusparse8.0 libnvrtc8.0 libnvtoolsext1 > /dev/null
!ln -snf /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so.8.0 /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so
!apt-get -qq -y install xvfb freeglut3-dev ffmpeg> /dev/null
!pip install pyglet
!pip install pyopengl
!pip install pyvirtualdisplay
!pip install gym[classic_control]
!pip install gym[Box2D]
!pip install pyvirtualdisplay
ライブラリのインポート
import gym
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Dropout, Activation
import numpy as np
import random
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
from IPython import display
from pyvirtualdisplay import Display
from tqdm import tqdm
from collections import deque
ネットワークを扱うためのクラスQ-Networkを定義します。
class QNetwork():
def __init__(self, action_space):
#学習するモデルの定義
model = Sequential()
model.add(Dense(128, input_dim = 4))
model.add(Activation("relu"))
model.add(Dense(128))
model.add(Activation("relu"))
model.add(Dense(action_space))
opt = keras.optimizers.Adam(learning_rate=0.01)
model.compile(loss='mse', optimizer=opt)
self.model = model
#targetとなる教師モデルの定義
model = Sequential()
model.add(Dense(128, input_dim = 4))
model.add(Activation("relu"))
model.add(Dense(128))
model.add(Activation("relu"))
model.add(Dense(action_space))
opt = keras.optimizers.Adam(learning_rate=0.01)
model.compile(loss='mse', optimizer=opt)
self.teacher_model = model
self.update_teacher()
def predict(self, x):
#学習するモデルによる予測
y = self.model.predict(x)
return y
def predict_by_teacher(self, x):
#ターゲットモデルによる予測
y = self.teacher_model.predict(x)
return y
def update_teacher(self):
#ターゲット(教師)モデルをアップデート
self.teacher_model.set_weights(self.model.get_weights())
次に, モデルを最適化していくクラスTrainerを定義します。通常でいうActorもこの中に入ってしまっています。
class Trainer():
def __init__(self, env, max_len = 1024, batch = 64, gamma = 0.95):
self.all = [] #持続ステップを保存する
self.gamma = gamma #学習りつ
self.env = env
self.env.reset()
self.QNet = QNetwork(2)
self.experiences = deque(maxlen = max_len) #experience_replayの実装
self.batch_size = batch #学習するバッチサイズ
self.training = False
def train(self):
self.run_episode()
def step(self, num, s):
next_s, reward, d, _ = self.env.step(num)
self.experiences.append([s, next_s, reward, d, num]) #[現在の状態, 変位先, 報酬, 終了か, actionの番号]
return next_s, reward, d
def policy(self, s, epsilon = 0.1):
#epsilon-greedy法で実装
if np.random.random() <= epsilon:
return np.random.randint(2)
else:
return np.argmax(self.QNet.predict(np.array([np.array(s)])))
def run_episode(self, times = 300):
for cnt in tqdm(range(times)):
done = False
s = self.env.reset()
stand_count = 0
if self.training:
#学習モデルの学習をする
self.update()
if cntt%10==0:
#教師モデルの重みを更新する
self.QNet.update_teacher()
while not done:
stand_count += 1
next_s, reward, done = self.step(self.policy(s), s)
if not self.training:
if len(self.experiences) == self.batch_size:
#experienceのデキューがバッチサイズ以上になったら学習かいし
self.training = True
s = next_s
if done:
self.all.append(stand_count)
print(stand_count)
return plt.plot(self.all)
def update(self):
#キューから適当にバッチサイズ分だけサンプリング
exp = random.sample(self.experiences, self.batch_size)
target = []
state = []
for e in exp:
s, next_s, reward, done, num = e
if not done:
#target-networkで予測して目標値を計算
reward += self.gamma * np.max(self.QNet.predict_by_teacher(np.array([np.array(next_s)])))
y = self.QNet.predict(np.array([np.array(s)]))
r = np.array([y[0][0], reward]) if num == 1 else np.array([reward, y[0][1]])
target.append(r)
state.append(s)
#バッチで学習
state = np.array(state)
target = np.array(target)
self.QNet.model.fit(state, target)
def show(self):
d = Display()
d.start()
s = self.env.reset()
img = plt.imshow(self.env.render('rgb_array'))
done = False
while not done:
next_s, reward, done = self.step(np.argmax(self.QNet.predict(np.array([np.array(s)]))), s)
s = next_s
display.clear_output(wait=True)
img.set_data(env.render('rgb_array'))
plt.axis('off')
display.display(plt.gcf())
やってることはこんな感じです。少し図がみにくいですが勘弁してください....
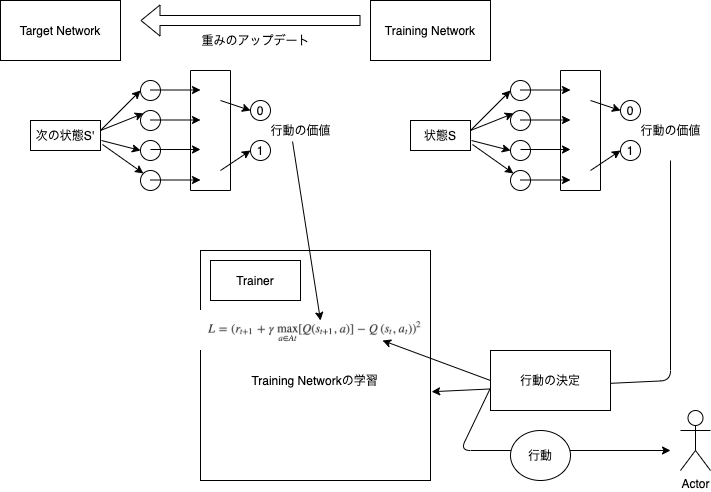
実行してみた
ENV = "CartPole-v1"
env = gym.make(ENV)
trainer = Trainer(env)
trainer.train()
こんな感じで実行してみました。trainer.run_episode()に学習したい回数の引数を渡してあげると学習回数を変えることができます。私の環境ではこんな感じになりました。
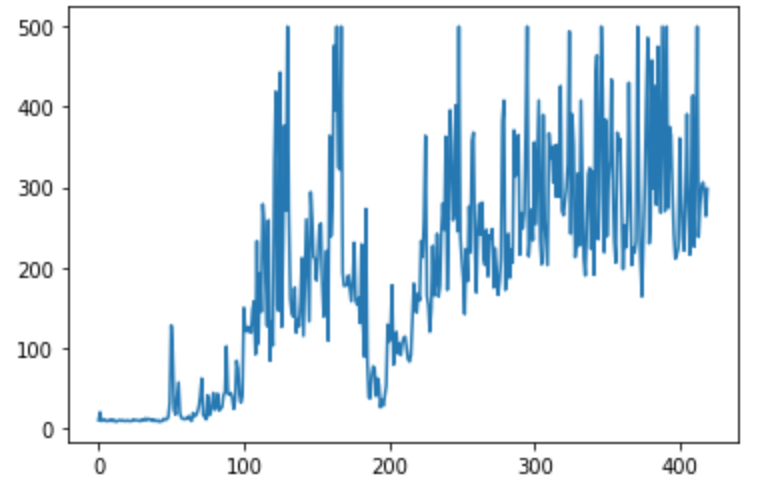
一瞬振動してしまっていますが, 300回をすぎたあたりでは500stepを連発しています。バッチサイズや, target-networdの重み更新の頻度を変えると学習の様子もだいぶ変化しました。
感想
前回できなかった, 連続的な状態もこれで扱うことができるようになりました。
ずっと価値ベースでの強化学習をしてきたので, 次回あたりでは方策ベースでの強化学習をしてみたいなと思います。ではまた!