強化学習ってかっこいいですよねえ。
今回は, pythonの環境「OpenAIGym」の「MountainCar」で遊んでみたので, 紹介します。
ちなみに, Google Colab使ってやってます。
こちらの記事をかなり参考にしました。OpenAI Gym 入門
さらっとQ学習
学習方法としてQ学習を振り返ります。どうでもええ!という方は, 読み飛ばしてください。
Q学習において, $Q\left( s_{t},a_{t}\right)$は状態行動価値といい, ある状態$st$において, 行動$a_{t}$をとった際の価値を表します。ここで$t$という表記を使ったのは, 時間という意味ではなくある状態という単一的な状態を表します。
ここでいう価値とは, 状態遷移した際に一時的にもらえる報酬ではなく, エピソードを最後まで完遂した際にもらえるであろう累積的な報酬のことをさします。
よって方策のとり方としては, ある状態$s_{t}$において$\max_{a\in At}(Q(s_{t},a))$となるような$a$を選べば良いということになります。
状態行動価値の更新
一般に状態行動価値の更新方法は, 以下のように表されます。
$$\begin{aligned}Q\left( s_{t},a_{t}\right) \ \leftarrow Q\left( s_{t},a_{t}\right) \ +\alpha \left( G_{t}-Q\left( s_{t},a_{t}\right) \right) \end{aligned}$$
ここで, Q学習の場合$G_{t}$は
$$G_{t}=r_{t+1}+\gamma\max_{a\in At}[Q(s_{t+1},a)]$$
$s_{t+1}$というように, 現在の状態ではなく次の状態においても考慮していることがわかります。これは未来に得られる報酬も考慮しているのだということだわかります。
$r_{t+1}$を即時報酬といい, 遷移してすぐにもらえる報酬, $\alpha$は学習率と呼び, 一回の学習でどの程度値を更新するのかを決めます。$\gamma$は割引率といい将来の報酬をどの程度参考にするかを決めます。
エピソード(ゲーム)を繰り返すことでこの, 状態価値関数を更新し最適な方策を求めていくのがこの$Q$学習です。
MountainCarルール
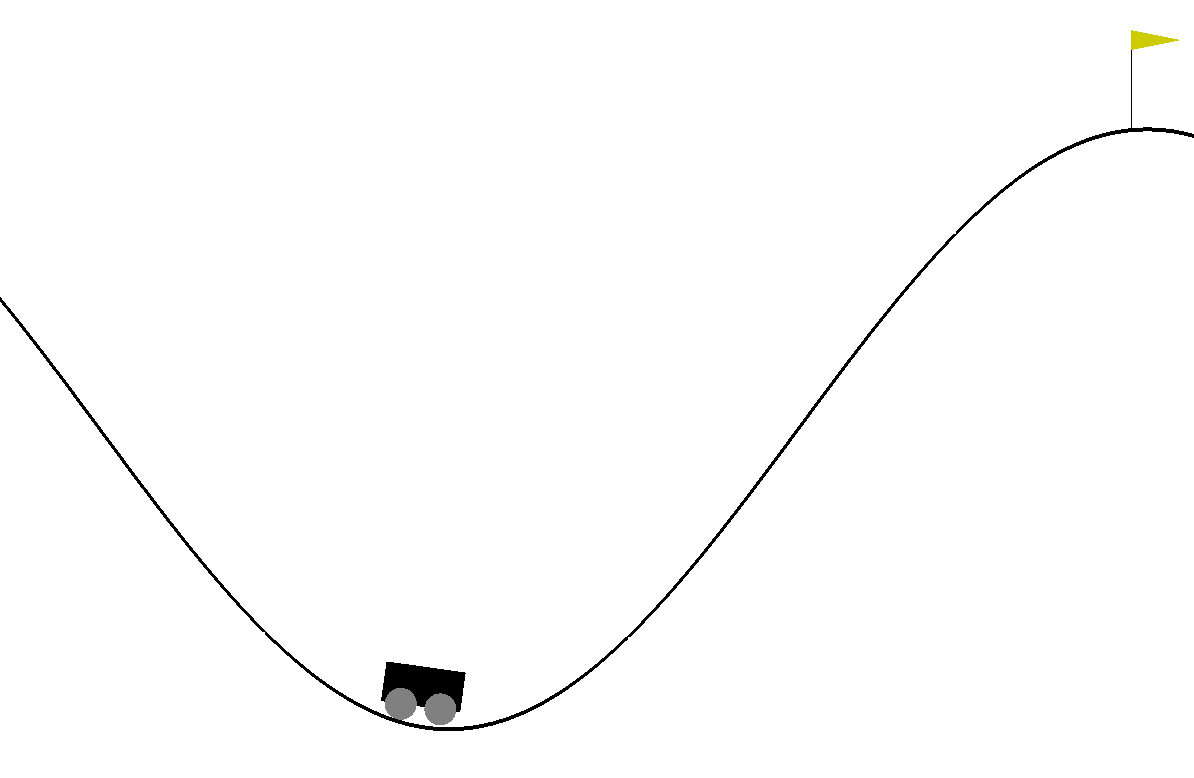
この環境では, 車の位置が右側の旗の位置に到達すると, ゲームが終了します。到達しない限り, 行動をするごとに-1の報酬を得ます。
もし、200回の行動を経てもゴールに達せれない場合もゲーム終了です。その場合、-200の報酬を得たことになります。つまり-200よりもより大きい報酬を得ようと強化学習させるわけです。
行動は, 左に移動:0, 動かない:1, 右に移動:2の三つに制限されます。
準備
Google Colabで状態描写するために色んなもの入れてますが, 結局はgymさえ入れればいいです。
# gymのインストール
$ pip install gym
# 必須ではない(colab使うときはおすすめ)
$apt update
$apt install xvfb
$apt-get -qq -y install libcusparse8.0 libnvrtc8.0 $ibnvtoolsext1 > /dev/null
$ln -snf /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so.8.0 /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so
$apt-get -qq -y install xvfb freeglut3-dev ffmpeg> /dev/null
$pip install pyglet
$pip install pyopengl
$pip install pyvirtualdisplay
ライブラリインポート
いらないものもあるので適宜選んでも構いません。
import gym
from gym import logger as gymlogger
from gym.wrappers import Monitor
gymlogger.set_level(40) #error only
import tensorflow as tf
import numpy as np
import random
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
import math
import glob
import io
import base64
from IPython.display import HTML
Q学習実装
行動の種類や, 環境の使い方はgithubを参考にしています。
GitHub MountainCar
class Q:
def __init__(self, env):
self.env = env
self.env_low = self.env.observation_space.low # 位置と速度の最小値
self.env_high = self.env.observation_space.high # 位置と速度の最大値
self.env_dx = (self.env_high - self.env_low) / 40 # 50等分
self.q_table = np.zeros((40,40,3))
def get_status(self, _observation):
position = int((_observation[0] - self.env_low[0])/self.env_dx[0])
velocity = int((_observation[1] - self.env_low[1])/self.env_dx[1])
return position, velocity
def policy(self, s, epsilon = 0.1):
if np.random.random() <= epsilon:
return np.random.randint(3)
else:
p, v = self.get_status(s)
if self.q_table[p][v][0] == 0 and self.q_table[p][v][1] == 0 and self.q_table[p][v][2] == 0:
return np.random.randint(3)
else:
return np.argmax(self.q_table[p][v])
def learn(self, time = 5000, alpha = 0.4, gamma = 0.99):
log = []
for j in range(time):
total = 0
s = self.env.reset()
done = False
while not done:
a = self.policy(s)
next_s, reward, done, _ = self.env.step(a)
total += reward
p, v = self.get_status(next_s)
G = reward + gamma * max(self.q_table[p][v])
p,v = self.get_status(s)
self.q_table[p][v][a] += alpha*(G - self.q_table[p][v][a])
s = next_s
log.append(total)
if j %100 == 0:
print(str(j) + " ===total reward=== : " + str(total))
return plt.plot(log)
def show(self):
s = self.env.reset()
img = plt.imshow(env.render('rgb_array'))
done = False
while not done:
p, v = self.get_status(s)
s, _, done, _ = self.env.step(self.policy(s))
display.clear_output(wait=True)
img.set_data(env.render('rgb_array'))
plt.axis('off')
display.display(plt.gcf())
self.env.close()
扱う状態$s$としては, 現在の車の位置(position), 現在の速度(velocity)があります。どちらも連続値をとっているので, get_status関数で離散的な値(40, 40)にしています。q_tableは状態価値関数の保存場所で, (40, 40)の状態のそれぞれに, 行動の種類, (3)を乗じたものとなっています。
env = gym.make('MountainCar-v0')
agent = Q(env)
agent.learn()
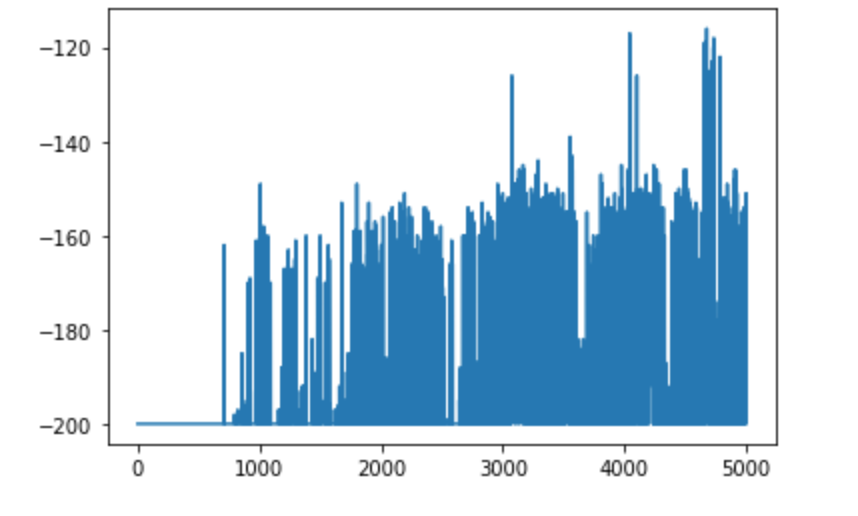
大体5000回の学習で, ゴールにも到達できる回数が増えてきました。
ちなみにgoogle colabでアニメーション確認したいときは,
from IPython import display
from pyvirtualdisplay import Display
import matplotlib.pyplot as plt
d = Display()
d.start()
agent.show()
でみれます。
感想
今回は説明がかなり雑になってるので, 徐々に更新していきます。もっとGymで遊んでいきつつ情報発信していきます。ではまた!