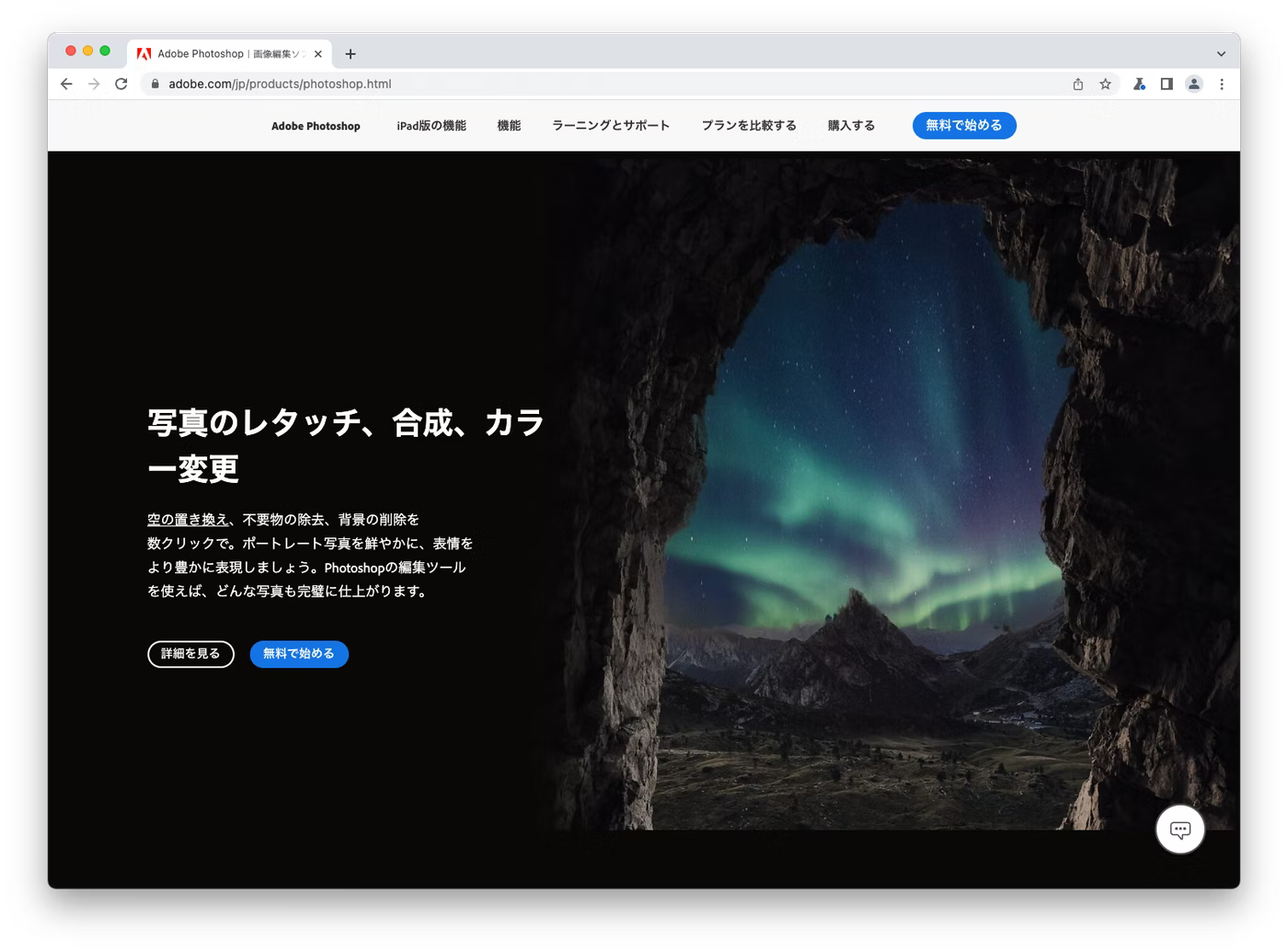
日本語のWebサイトは常に改行問題を抱えています。たとえばPhotoshopのランディングページで「写真のレタッチ、合成、カラー変更」というヘッドラインが以下のように改行されていたら如何でしょうか?非常に読みにくい上にユーザーに与える印象も悪くなりますよね。
これらの問題を解決するHTML/CSSは前回の記事で紹介しました。簡単にまとめますと。
- word-break: keep-all; + overflow-wrap: anywhere; + <wbr> は特定の条件下でレイアウトが崩れる問題はありますが、最もきれいに改行できます
- <span> + display: inline-block; はレイアウトが崩れる事を極力さける事が可能ですが、改行させたい場合に利用します
しかし、これらの手法は手動でHTMLタグを入れていくという方法で、実際の運用としてはかなり難しいものとなっています。この問題を解決する手法として、BudouXが面白いソリューションになっていたので、アドビのJapan R&Dでも実際に検証してみました。今回の記事ではBudouXの使い方や仕組み、adobe.comに導入する際に直面した問題、カスタムモデルを構築した話、アドビでのBudouXの活用事例などを紹介していきます。
BudouXとは
BudouXは機械学習を用いて、テキストを読みやすい単位に分割するツール・ライブラリです。サードパーティの分かち書きを行うツール(MeCab1等)に依存せず、クライアントサイドで扱えてかつわずか15KBでJavaScriptのファイルだけで完結します。更にデータセットさえあれば、日本語だけでなくどの言語にも依存しない作りになっています。
こちらにデモサイトがあるので、気になる方は試して見て下さい。
BudouXの使い方
簡単な使い方
文節ごとに区切ったリストを取得できます。
import { loadDefaultJapaneseParser } from 'budoux';
const parser = loadDefaultJapaneseParser();
console.log(parser.parse('今日は天気です。'));
// ['今日は', '天気です。']
HTML文字列を翻訳
HTML文字列を翻訳して、文節毎に<wbr>を挿入することも可能です。
console.log(parser.translateHTMLString('今日は<b>とても天気</b>です。'));
// <span style="word-break: keep-all; overflow-wrap: break-word;">今日は<b><wbr>とても<wbr>天気</b>です。</span>
HTML要素に適用
例えば以下のpタグに直接BudouXを適用することも可能です。
const ele = document.querySelector('p.budou-this');
console.log(ele.outerHTML);
// <p class="budou-this">今日は<b>とても天気</b>です。</p>
parser.applyElement(ele);
console.log(ele.outerHTML);
// <p class="budou-this" style="word-break: keep-all; overflow-wrap: break-word;">今日は<b><wbr>とても<wbr>天気</b>です。</p>
BudouXはどのように動作しているか?
BudouXは与えられた文字列を一文字ずつシーケンシャルに見ていき、その都度改行するか否かを判別する事で二値分類に問題を帰結させています。使用する特徴量としては、
- 改行ポイントの前後3文字のUnicodeブロック2&Unicode値とその組み合わせ
- 前3文字で改行ポイントがあったか否か
などが使われています。
また、BudouXはAdaboostアルゴリズム3を利用しています。Adaboostは弱学習器を組み合わせて、強学習機を作成するブースティング4の一種で、誤分類したデータの重みパラメータを増やし、誤差が最小になるような重みパラメータを決定していくアルゴリズムです。非常に分かりやすく解説しているYouTube動画があるので、以下に貼っておきます。
adobe.comへ導入する際の課題点
BudouXは文節に区切る問題においては非常に素晴らしい精度を持っており、皆さんのWebサイトにすぐ導入できるレベルのツールです。私もadobe.comで利用できないかを検討し、様々な調査を行ってきた結果、課題点がいくつか見えてきました。
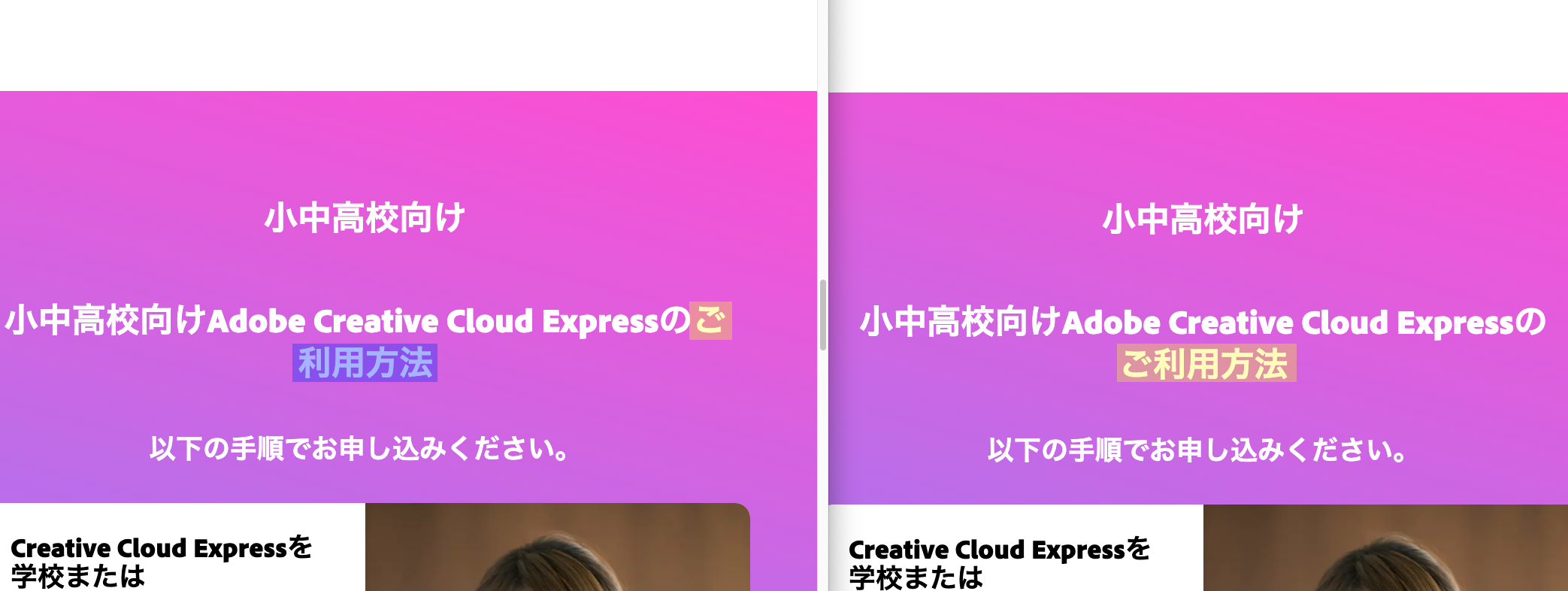
お、ご、などの尊敬語に弱い
小中高校向けAdobe Creative Cloud Expressのご利用可能をBudouXのデフォルトモデルで分割すると、以下のように分割されてしまいます。原因としては、デフォルトの学習データに尊敬語に関するデータが不足している点が挙げられます。なお、デフォルトの学習データは京都大学情報学研究科と日本電信電話株式会社NTTコミュニケーション科学基礎研究所が公開している解析済みブログコーパスを利用しています。
import { loadDefaultJapaneseParser } from 'budoux';
const parser = loadDefaultJapaneseParser();
console.log(parser.parse('小中高校向けは無料でご利用いただけます。'));
// ['小中高校向けは', '無料でご', '利用いただけます。']
// It should be ['小中高校向けは', '無料で', 'ご利用いただけます。']
半角英数字に関する学習データが足りない
先程の解析済みブログコーパスの中身を見ていくと、以下のように全角英数字が利用されています。例えばvodafoneやsoftbankのように全角英字が使われています。
// BudouXでは "▁" (U+2581)で区切り入れて、学習しています
J−SA06:vodafone→softbank,▁もちろん▁プリペイド携帯電話
BudouXのデフォルトモデルは半角英数字に関する学習データが不足しています。全角英数字と半角英数字ではUnicodeブロックの値&Unicode値が異なるため、学習結果に差が出てきます。特にadobe.comでは製品名などで頻繁に半角英数字(Photoshop等)を利用しているので、これらを追加で学習する必要があります。
長い複合名詞が分割されていない
BudouXのデフォルトモデルは文節毎に分割しているので、長い複合名詞を分割することはできません。しかし、adobe.comでは以下のような長い複合名詞(特にマーケティング用語)が頻繁に登場します。20文字以上の複合名詞では、文字が横幅に収まりきらない事もあるので、前回の記事の問題のようなレイアウトが崩れる可能性もあります。
// Asis
デジタルエクスペリエンスプラットフォーム分野
マーケティングオートメーションソリューション
検索エンジンマーケティングキャンペーン
ジャーニーオーケストレーションプラットフォーム
デジタルアセットマネジメントストラテジスト
デジタルコマースプラットフォーム市場
動画編集プロフェッショナル
// Tobe
デジタル▁エクスペリエンス▁プラットフォーム▁分野
マーケティング▁オートメーション▁ソリューション
検索▁エンジン▁マーケティング▁キャンペーン
ジャーニー▁オーケストレーション▁プラットフォーム
デジタル▁アセット▁マネジメント▁ストラテジスト
デジタル▁コマース▁プラットフォーム▁市場
動画編集▁プロフェッショナル
adobe.com用にBudouXカスタムモデルの学習
このようにBudouXのデフォルトモデルにはいくつか問題がありました。これはあくまでデータセットに問題があるだけで、新しいデータでモデルを再学習する事で解決するのではないか?という仮説の元、adobe.comのテキストデータを用いて再学習する事で、新たにBudouXのカスタムモデルを構築できるのではないかと考えました。
カスタムモデルの構築方法
日本語の学習用データセットを用意すれば、BudouXのカスタムモデルを構築する事ができます。学習用データセットはセパレーター "▁" (U+2581)で区切られたテキストファイルの事を指しています。BudouXはセパレーターで区切られた単位で改行できるように学習していきます。
Adobe Tagetの▁Aiを▁利用する▁機能を▁ご紹介します。
アドビは、▁デジタル▁アセット管理の▁リーダー
Photoshop Lightroomを▁使って▁スムーズに▁ステッチング
このテキストデータmysource.txtを使って以下のコマンドを活用するとカスタムモデルファイルが出力されます。
$ pip install -r requirements_dev.txt
$ python scripts/encode_data.py mysource.txt -o encoded_data.txt
$ python scripts/train.py encoded_data.txt -o weights.txt
$ python scripts/build_model.py weights.txt -o mymodel.json
学習データの収集と前処理
ここまででカスタムモデルの構築方法は理解できたかと思います。セパレーターで区切られたadobe.comのテキスト学習データをどのように用意するのかが次の課題になってきます。具体的な手順しては次のようになります。
- Scrapy5を用いてadobe.comからh1,h2,h3タグのテキストを抽出
- GiNZA6の形態素解析で尊敬語が入ったテキストを優先的に抽出
- GiNZAの文節APIを用いて、文節ごとに区切る
- GiNZAを用いて複合名詞を分割する
- GiNZAで処理しきれない部分を一括置換して、データクレンジング
1. Scrapyを用いてadobe.comからh1,h2,h3タグのテキストを抽出
Scrapyのrunspiderコマンドを使って、csvの形式でh1,h2,h3タグのテキストを抽出。
$ scrapy runspider headline.py -o headlines.csv -t csv
import scrapy
import unicodedata
import re
HTML = re.compile(r"<[^>]*?>")
headlines = set([])
def clean_text(txt: str):
"""
Clean the given text
Parameters
----------
txt : str
Text to be cleaned
"""
txt = HTML.sub("", txt)
txt = txt.replace("\xa0", "")
txt = txt.replace("\n", "")
txt = txt.replace("•", "")
return txt.strip()
def is_japanese(string: str):
"""
Check if the given source string is Japanese
Parameters
----------
string : str
source string
"""
for ch in string:
name = unicodedata.name(ch)
if "CJK UNIFIED" in name \
or "HIRAGANA" in name \
or "KATAKANA" in name:
return True
return False
class HeadlineSpider(scrapy.Spider):
name = 'headline'
allowed_domains = ['business.adobe.com', 'www.adobe.com']
start_urls = ['https://www.adobe.com/jp/']
def parse(self, response):
# h1, h2, h3タグを抽出
for res in [response.xpath('//h1').extract(), response.xpath('//h2').extract(), response.xpath('//h3').extract()]:
for tag in res:
title = clean_text(tag.title())
# 日本語のテキストが入っていて、重複していなければ
if len(title) >= 0 and title not in headlines and is_japanese(title):
headlines.add(title)
yield {"title": title.strip()}
for href in response.xpath('//a').xpath('@href').extract():
# 日本語のページリンクだけをたどる
if any(["jp" in href and allowed_domain in href for allowed_domain in self.allowed_domains]):
# 次のページ
yield scrapy.Request(href, callback=self.parse)
2. GiNZAの形態素解析で尊敬語が入ったテキストを優先的に抽出
尊敬語が入った文章はadobe.comにいくつかありますが、GiNZAの形態素解析を使って判定を行い、優先的に学習データに加えるように抽出します。接頭辞に"お"や"ご"が使われていれば、そのテキストは尊敬語が含まれていると判定する単純なものとなっています。
$ cat headlines.csv | python honorific_language_filter.py > filtered_headlines.csv
import spacy
nlp = spacy.load('ja_ginza_electra')
# 尊敬語の接頭辞
honorific_prefixes = set(["お", "ご"])
while True:
try:
text = input().strip()
doc = nlp(text)
is_display = False
for sent in doc.sents:
for token in sent:
is_display = is_display or (token.tag_ == "接頭辞" and token.text in honorific_prefixes)
if is_display:
# 尊敬語が入った文章を表示
print(text)
except:
pass
3. GiNZAの文節APIを用いて、文章を文節ごとに区切る
Scrapyによって抽出されたテキストをGiNZAの文節APIを使って、セパレーター "▁" (U+2581)で分割します。
# スクレイピングしたテキストを文節に区切る
$ cat headlines.csv | python bunsetu.py > headlines.txt
# 尊敬語のテキストも文節に区切る
$ cat filtered_headlines.csv | python bunsetu.py > filtered_headlines.txt
$ head -n 10 headlines.txt
質問:▁動画マーケティングの▁戦略は▁どのように▁策定するべきですか?
自信を▁持って▁Eコマースを▁展開
共有コンテンツの▁表示に▁Creative Cloud▁サブスクリプションが▁必要ですか?
両社の▁提携で▁実現した▁最高の▁生産性
桐生先生が▁教える!▁フォトオンライン講座の▁過去の▁動画を▁視聴
リモートワークの▁ための▁Adobe Signプログラム
質問:▁データ分析と▁データマイニングには、▁どのような▁関係が▁ありますか?
質問:▁B2Bマーケティングと▁B2Cマーケティングの▁違いは▁何ですか?
実は▁20年前に▁始まっている▁クルマの▁Iot
import sys
import spacy
import ginza
nlp = spacy.load("ja_ginza_electra")
try:
while True:
jp = input().strip()
doc = nlp(jp)
for sent in doc.sents:
print("▁".join([str(span) for span in ginza.bunsetu_spans(sent)]), end="")
print()
except:
pass
4. GiNZAを用いて複合名詞を分割する
先程の文節APIとは異なり複合名詞のみ抽出して、名詞ごとにセパレーター "▁" (U+2581)で分割した辞書を作成します。compound_nouns.txtが出来上がったら、これを使ってheadlines.txtやfiltered_headlines.txtに含まれるテキストを置換していきます。
$ cat headlines.txt | python compound_noun.py > compound_nouns.txt
$ head -n 10 compound_nouns.txt
フォト▁プラン
マーケット▁プレイス
ライセンス▁形態
チーム▁ライブラリ
バージョン▁履歴
コンプリート▁プラン
デスクトップ▁アプリケーション
各種▁プラン
単体▁プラン
プレミアム▁プリセット
# この後に何らかの方法でheadlines.txtとfiltered_headlines.txtのテキストを置換して下さい
import re
import spacy
nlp = spacy.load('ja_ginza_electra')
# カタカタだけ
RE_KANA = re.compile(r"[ァ-ヴー]+")
# カタカナ+漢字(2文字以上)
RE_KANA_KANJI = re.compile(r"([ァ-ヴー]+)([々〇〻\u3400-\u9FFF\uF900-\uFAFF\uD840-\uD87F\uDC00-\uDFFF]{2,})")
# 漢字(2文字以上)+カタカナ
RE_KANJI_KANA = re.compile(r"([々〇〻\u3400-\u9FFF\uF900-\uFAFF\uD840-\uD87F\uDC00-\uDFFF]{2,})([ァ-ヴー]+)")
# 同じ名詞が入らないようにする
uniques = set()
while True:
line = input().strip()
# カタカナ+漢字を分割
for i in RE_KANA_KANJI.findall(line):
if i[0] + i[1] in uniques:
continue
doc = nlp(i[0])
uniques.add(i[0] + i[1])
for sent in doc.sents:
chunks = [str(i) for i in sent] + [i[1]]
if len(chunks) > 1:
print("▁".join(chunks))
# 漢字+カタカナを分割
for i in RE_KANJI_KANA.findall(line):
if i[0] + i[1] in uniques:
continue
doc = nlp(i[1])
uniques.add(i[0] + i[1])
for sent in doc.sents:
chunks = [i[0]] + [str(i) for i in sent]
if len(chunks) > 1:
print("▁".join(chunks))
# カタカナを分割
for i in RE_KANA.findall(line):
if i in uniques:
continue
doc = nlp(i)
uniques.add(i)
for sent in doc.sents:
chunks = [str(i) for i in sent]
if len(chunks) > 1:
print("▁".join(chunks))
5. GiNZAで処理しきれない部分を一括置換して、データクレンジング
最後は力技になってきますが、GiNZAで処理しきれなかった部分を一括で置換します。例えば、GiNZAの文節APIでは以下のようにその他はその▁他として分割されてしまいます。解析済みのコーパスと違い、GiNZAは高精度に文節の区切りや形態素解析を行ってくれますが、手動での修正は必須となります。骨の折れる作業ですが、これは一行ずつ確認していき、誤っている部分はいくつかパターンが見受けられるのでプログラムで一括置換するのをオススメします。
BAD
Creative Cloudの▁その▁他の▁アップデートを▁見る
GOOD
Creative Cloudの▁その他の▁アップデートを▁見る
BAD
アドビ、▁未来の▁働き方に関する▁調査を▁7カ国で▁実施
GOOD
アドビ、▁未来の▁働き方に▁関する▁調査を▁7カ国で▁実施
カスタムモデルの学習
ここまでの工程で学習用に使用するテキストファイルは用意できましたが、全てを学習データとして使用しない(後で評価に使う)ので、カスタムモデルの学習に使用するテキストだけを抽出します。使用する学習データの総数や尊敬語が含まれる学習データの配分は都度調整していきます。
# 学習データをランダムに3000だけ抽出
$ sort -R headlines.txt | head -n 3000 > training1.txt
# 尊敬語のテキストの学習データをランダムに1000だけ抽出
$ sort -R filtered_headlines.txt | head -n 1000 > training2.txt
# 最後に突き合わせて、重複を排除した結果を学習データとする
$ cat training1.txt training2.txt | uniq > training.txt
後は以下のコマンドでカスタムモデルの学習をしていきます。学習が終わった後はadobe_model.jsonというモデルファイルを出力する事でカスタムモデルの学習の工程は全て終了となります。
$ pip install -r requirements_dev.txt
$ python scripts/encode_data.py training.txt -o encoded_data.txt
$ python scripts/train.py encoded_data.txt -o weights.txt
#entries: 78761
#features: 13116
Outputting learned weights to adbe_weights.txt ...
=== 0 ===
min error: 0.13644828169969803
best tree: 99
training accuracy: 0.8635517183003216
testing accuracy: 0.8575599847657738
=== 1 ===
min error: 0.34343661876250464
best tree: 16
training accuracy: 0.8635517183003216
testing accuracy: 0.8575599847657738
=== 2 ===
min error: 0.33905799334967146
best tree: 10
training accuracy: 0.8635517183003216
testing accuracy: 0.8575599847657738
=== 3 ===
...
$ python scripts/build_model.py weights.txt -o adobe_model.json
モデルファイルの中身
モデルファイルの中身を見ていく前にAdaboostは複数の決定株(Decision Stump)7と呼ばれる弱学習器、深さ1レベル決定木を基本的に使用するアルゴリズムであるという前提に着目する必要があります。
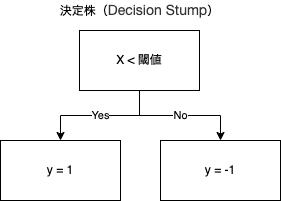
それぞれの決定株は同一の発言権を持っているわけではありません。発言権は割り当てられた信頼度(とそれによって出力されるスコア)によって異なり、最終的にいくつもある決定株のスコアの合計によって、最終的な予測が行われます。その数式を以下に示します。少しこの数式を解説すると、信頼度$\alpha_n$と決定株$h_n(x)$の結果(1 or -1)の合計をスコアとして、$sign$関数に通して、最終的な予測結果を得る事ができるという意味となっています。
$$
\begin{align}
H(x) &:= sign \biggl(\sum_{n=1}^N \alpha_n h_n (x)\biggr) \
\end{align}
$$
ようやくモデルファイルの中身になりますが、出力されるモデルファイルは特徴量に対する信頼度x決定株の結果がJSONの辞書形式で記録されています{"<特徴量>":<信頼度x決定株の結果>}。例えば、モデルファイルの中身の一部である以下の"UW3:\u3092": 12873に注目してみます。UW3:\u3092は改行一つ前の文字が "を"(U+3092)で、12873は信頼度が12873 x 決定株の結果が1であることを示しています。これにより、"を"の後は改行される可能性が高い事を意味しています。
{..., "UW3:\u3092": 12873, ...}
モデルブレンディング
このままでも十分に既存のデフォルトモデルより高い精度のカスタムモデルを開発する事ができますが、モデルブレンディングによって更に高い精度と汎化性能を得ることができるのではないかと考えました。
モデルブレンディングとは複数のモデルで予測した結果を組み合わせる事で高精度のモデルを作るアンサンブル学習の一種です(よくKaggleで使用されています)。本来であれば違うアルゴリズムの予測モデルを組み合わせる手法ですが、今回はBudouXのデフォルトモデルとadobe.com用のカスタムモデルを組み合わせます。最終的な評価結果においてモデルブレンディングが有効かどうかは、次の節で解説します。
# デフォルトモデルとカスタムモデルを1:1でブレンド
$ python blending.py ja-knbc.json adobe_model.json > blendv1.json
# デフォルトモデルとカスタムモデルを1:2でブレンド
$ python blending.py ja-knbc.json adobe_model.json adobe_model.json > blendv2.json
import sys
import json
models = []
dic = {}
output = {}
# モデルファイルのリストを読み込み
for i in sys.argv[1:]:
with open(i) as f:
models.append(json.load(f))
# モデル毎にスコア(信頼度x決定株の結果)をまとめる
for m in models:
for k, v in m.items():
if k not in dic:
dic[k] = []
dic[k].append(v)
# 重みパラメータは平均をとる
for k, v in dic.items():
output[k] = sum(v) // len(v)
# モデルファイル出力
print(json.dumps(output))
モデルの評価
最後にカスタムモデルの評価となります。比較するモデルは
- BudouXのデフォルトモデル
- adobe.com用に学習したカスタムモデル
- 1と2をブレンディングしたモデル
評価時に使用したデータ(総数19480)はadobe.comにあるヘッドラインから抽出したテキストで学習データと同じ用に前処理を行っています。これをscikit-learn8のsklearn.metrics.classification_reportを用いて、各モデルを評価していきます。
precision recall f1-score support
none 0.9538 0.9945 0.9737 360511
line break 0.9713 0.7954 0.8746 84908
accuracy 0.9565 445419
macro avg 0.9626 0.8949 0.9242 445419
weighted avg 0.9571 0.9565 0.9548 445419
precision recall f1-score support
none 0.9778 0.9914 0.9846 360511
line break 0.9613 0.9044 0.9319 84908
accuracy 0.9748 445419
macro avg 0.9695 0.9479 0.9582 445419
weighted avg 0.9746 0.9748 0.9745 445419
precision recall f1-score support
none 0.9761 0.9937 0.9848 360511
line break 0.9709 0.8967 0.9323 84908
accuracy 0.9752 445419
macro avg 0.9735 0.9452 0.9586 445419
weighted avg 0.9751 0.9752 0.9748 445419
結果としてはadobe.com用に学習したカスタムモデルは1と2をブレンディングしたモデルが両者とも、既存のBudouXのデフォルトモデルの性能を上回っている結果となりました。ブレンディングによる評価性能の向上に関しては多少精度に影響を与えていますが、どういった重みでブレンディングしていけば良いのかに関しては今後の課題となります。
活用事例
12月に公開されたAdobe Creative Cloud ExpressのWebサイトにて日本のエンジニアリングチームで開発したBudouXのカスタムモデルを導入しました。Adobe Creative Cloud ExpressのWebサイトはAdobeのGithub.comにてソースコードは公開されているので、そちらにPull Requestを送りました。(なお、導入時にこちらの問題にぶち当たってモバイルではBudouXを適用しないようにしています。)
尊敬語の対応
半角英数字の対応
長い複合名詞の対応
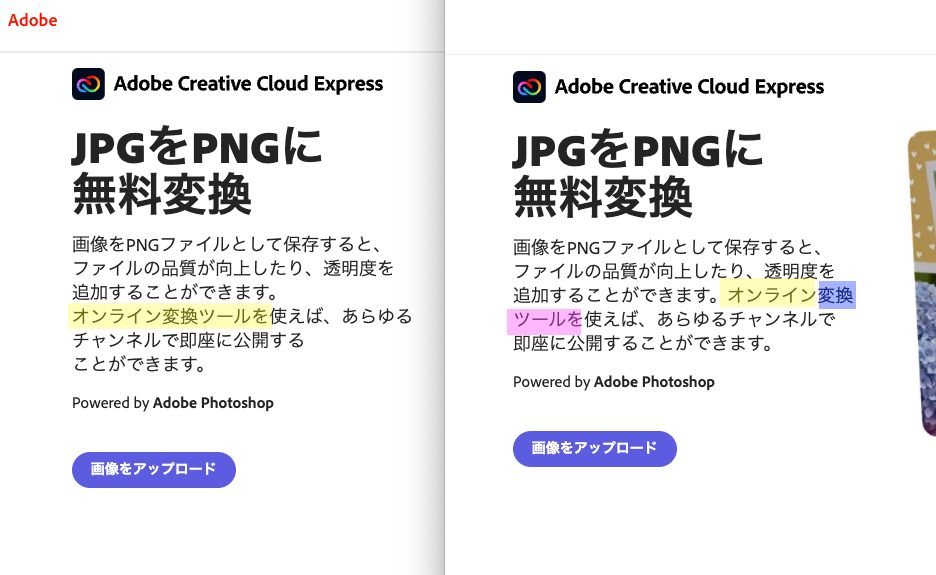
BudouXへのContribution
adobe.comのデータを学習している際に、numpyの計算にてOOM(Out of memory)になっている箇所があったので、行列の計算を分割する事でOOMの問題を解決するPull Requestを作成しました。
具体的にはAdaboostの学習データのエラー誤差を計算する部分を、全データをnumpyの行列のメモリに乗せて計算していたのを、
$$
\begin{align}
\varepsilon_m &:= \frac{\sum_{n=0}^{N-1} w^{(m)}_{n} I \left[ y(x_n, \theta_m) \neq t_n \right]}{\sum_{n=0}^{N-1} w^{(m)}_{n}} \
\end{align}
$$
以下のように、データを分割し、メモリに乗る単位(チャンク)で計算します。
$$
\begin{align}
\varepsilon_m &:= \frac{
\sum_{n=0}^{L} w^{(m)}_{n} I \left[ y(x_n, \theta_m) \neq t_n \right]+
...+
\sum_{n=L * M}^{N-1} w^{(m)}_{n} I \left[ y(x_n, \theta_m) \neq t_n \right]
}{\sum_{n=0}^{N-1} w^{(m)}_{n}} \
\end{align}
$$
-
MeCabは 京都大学情報学研究科−日本電信電話株式会社コミュニケーション科学基礎研究所 共同研究ユニットプロジェクトを通じて開発されたオープンソース 形態素解析エンジン。 ↩
-
Unicodeブロックとは、符号位置 (code points) の連続する範囲を意味する。今回のケースでは、この範囲によって文字の種類(漢字、ひらがな、カタカナ、半角英数字等)を区別する。 ↩
-
https://ja.wikipedia.org/wiki/%E3%83%96%E3%83%BC%E3%82%B9%E3%83%86%E3%82%A3%E3%83%B3%E3%82%B0 ↩
-
オープンソースのWebスクレイピングフレームワーク。 ↩
-
Universal Dependenciesに基づくオープンソース日本語NLPライブラリ。 ↩
-
scikit-learnはPythonのオープンソース機械学習ライブラリ。 ↩