本記事は、re:Invent 2025にて現地の 12/3(水) に行われた、
AIエージェント向けの高品質なデータプロダクトに関するセッション参加レポートです。
ポイント
このセッションの主なポイントです。
- データの品質がAIの品質に直結する: AIエージェントの有効性は、基礎となるデータの品質とコンテキストに依存します。
- データプロダクトの定義拡大: AI活用に向けて、従来のデータセットだけでなくプロンプト、検索コーパス、トレーニングデータも「データプロダクト」として扱い、ライフサイクル管理や品質管理を行う必要があります。
- SageMaker Catalogの活用: 構造化・非構造化データに加え、AI資産(プロンプトやエージェント)のメタデータをSageMaker Catalogで一元管理し、ビジネスコンテキストを付与することが重要。
- AIによるデータ管理: AIエージェント自身を活用して、データカタログのメタデータ不足を検出し、自動修復する「Agentic Data Stewardship」の実践。
セッションについて
タイトル
Building high-quality data products for AI Agents (ANT332)
概要(日本語訳)
AIエージェントの効果は、それらが依存するデータに依存します。
このChalk Talkでは、AIエージェントが使用するための高品質なデータプロダクトとコンテキスト情報の構築・管理に焦点を当てています。
コンテキストエンジニアリング、RAG戦略、ファインチューニング用データセットのキュレーション、自動品質チェックなど、AIシステムに正確で最新かつ適切に管理されたデータを提供する方法を学びます。
また、AIコンテキストの管理、データドリフトの処理、Agentic AIの世界における従来のデータ管理活動についてもカバーします。
セッションタグ
- セッションタイプ: Chalk talk
- 対象レベル: 300 – Advanced
- 形式: Interactive
- トピック: Analytics, Artificial Intelligence
- 関心領域: Generative AI, Management & Governance, Governance, Risk & Compliance
- 対象ロール: Data Engineer, Data Scientist, IT Executive
- 対象サービス: Amazon DataZone, Amazon SageMaker
スピーカー
- Jason Berkowitz, Head of Data for Analytics AI Portfolio Marketing, Amazon Web Services
- Lakshmi Ramchandran Nair, Senior Specialist Analytics Solutions Architect, AWS
スケジュール
- 日時: Wednesday, Dec 3 | 11:30 AM - 12:30 PM PST
- 場所: Mandalay Bay | Level 3 South | South Seas C
AIへの信頼を構築するための4つのポイント
セッションの冒頭では、堅牢なAIアプリケーションを構築するための基盤として、以下4つの要素が挙げられました。
-
Accuracy (正確性):
AIモデルは事実に基づいた正確なデータから学習する必要があります。しかし、データの準備(Data Preparation)は依然としてエンジニアが最も時間を費やしている分野です。この時間を削減しつつ、品質を確保することが重要です。 -
Open and secure access (オープンかつセキュアなアクセス):
データへのアクセス性を高めると同時に、セキュリティも担保する必要があります。データにセマンティクス(意味論)を付与し、オープンな接続性を提供することで、開発スピードと生産性を向上させます。 -
Reliability and auditability (信頼性と監査可能性):
AIシステムには信頼性、回復力、品質、そして監査可能性が求められます。特にAIエージェントが自律的に動作する場合、その判断根拠となるデータの信頼性は不可欠です。 -
People and process (人とプロセス):
成功している企業は、技術だけでなく人材やプロセスにも投資しています。プロダクトエンジニアリングの手法やメタデータ品質の重要性を組織全体に教育することが重要です。
データのカオスを自動化する
「You can't automate chaos(カオスは自動化できない)」という言葉が紹介されました。
現実のデータにはエラー、不整合、欠損値、バイアスが含まれています。これらを放置したままAIに学習させても良い結果は得られません。
重要なのは、この「カオス」に対処するプロセスを可能な限り自動化し、データにコンテキスト情報(メタデータ)を付与し、エンリッチ(情報を拡充し、価値を高めること)することです。
メタデータこそが、アプリケーション(AI)がデータを正しく理解するための鍵となります。
データプロダクトとは
本セッションでは、「データプロダクト」を以下のように定義しています。
データプロダクト = データ + コンテキスト(メタデータ、ビジネスロジックなど)のパッケージ
単なる生のデータ資産(Raw Data Assets)と、管理された「データプロダクト」は区別されます。
組織内には大量のデータ資産がありますが、すべてをデータプロダクトにする必要はありません。
データ資産をデータプロダクトに変換するための4つの要素
あるデータ資産を、時間とコストをかけて「データプロダクト」に昇華させるべきかどうか判断するための、4つの基準が提示されました。
-
Recurring need and capability (継続的なニーズと能力):
一度限りの利用ではなく、複数の部門やアプリケーションから継続的な需要があるか?また、それを安定的に提供できる技術的能力があるか?
(例:複数のAIエージェントが同じ顧客住所ビューを参照する場合、それはデータプロダクトとして管理されるべきです) -
Sponsorship and resource commitment (スポンサーシップとリソースのコミットメント):
「プロダクト」にはオーナーが必要です。長期的な予算と人材が確保され、維持管理される体制があるか? -
Uniqueness and differentiation (独自性と差別化):
そのデータは既存のリソースよりも優れた解決策を提供するか?同じ役割のデータ資産が複数ある場合、最も価値のあるものだけに投資すべき。 -
Decommissioning (廃止計画):
スピーカーは非常に重要なポイントとして強調していました。作成当初から「いつ、どのように廃止するか」の基準が計画されている必要があります。持続可能なデータブロックを構築し、価値が低下した際にクリーンに廃棄できることが求められます。
データプロダクトの構成要素
データプロダクトとして提供される際に、備えるべき主な要素は以下の通りです。
- Packaged: ビジネス向けの成果物としてバンドルされている
- Lifecycle management: バージョニング、トレーニング、コンテキスト管理
- Accessible and usable: 早期統合と相互運用性
- Secure access control: 承認プロセス、有害コンテンツのフィルタリング
- Comprehensive metadata: タクソノミーやオントロジーを用いたコンテキストメタデータ
- Trust and observability: データ品質、リネージ、バイアスや幻覚(Hallucination)の検出
- Delivery channel: 価値を享受しやすいインターフェース
- Clear ownership: 明確な役割とビジネス整合性
AI時代のデータプロダクト再定義
AI時代においては、従来のデータプロダクトの定義をさらに拡張する必要があります。
以下の3つの要素も、再利用可能な資産として「データプロダクト」として扱うべきです。
- Prompt (プロンプト): AIエージェントへの指示書。バージョン管理や品質チェックが必要。
- Retrieval Corpus (検索コーパス): RAGで利用する知識ベース。情報の鮮度や正確性が重要。
- Training Data (トレーニングデータ): ファインチューニングに利用する高品質なデータセット。
これらを体系的に管理することで、AIエージェントの品質を向上させることができます。
デモ:SageMaker Catalogによるデータプロダクトの実装
セッションでは、Amazon SageMaker Catalog を中心としたデータプロダクト管理のデモが行われました。
3つの要素から構成された流れで説明されていました。
- ソースとキュレーション (Source and curation)
- カタログのエンリッチメント (Catalog enrichment)
- 消費 (Consumption)
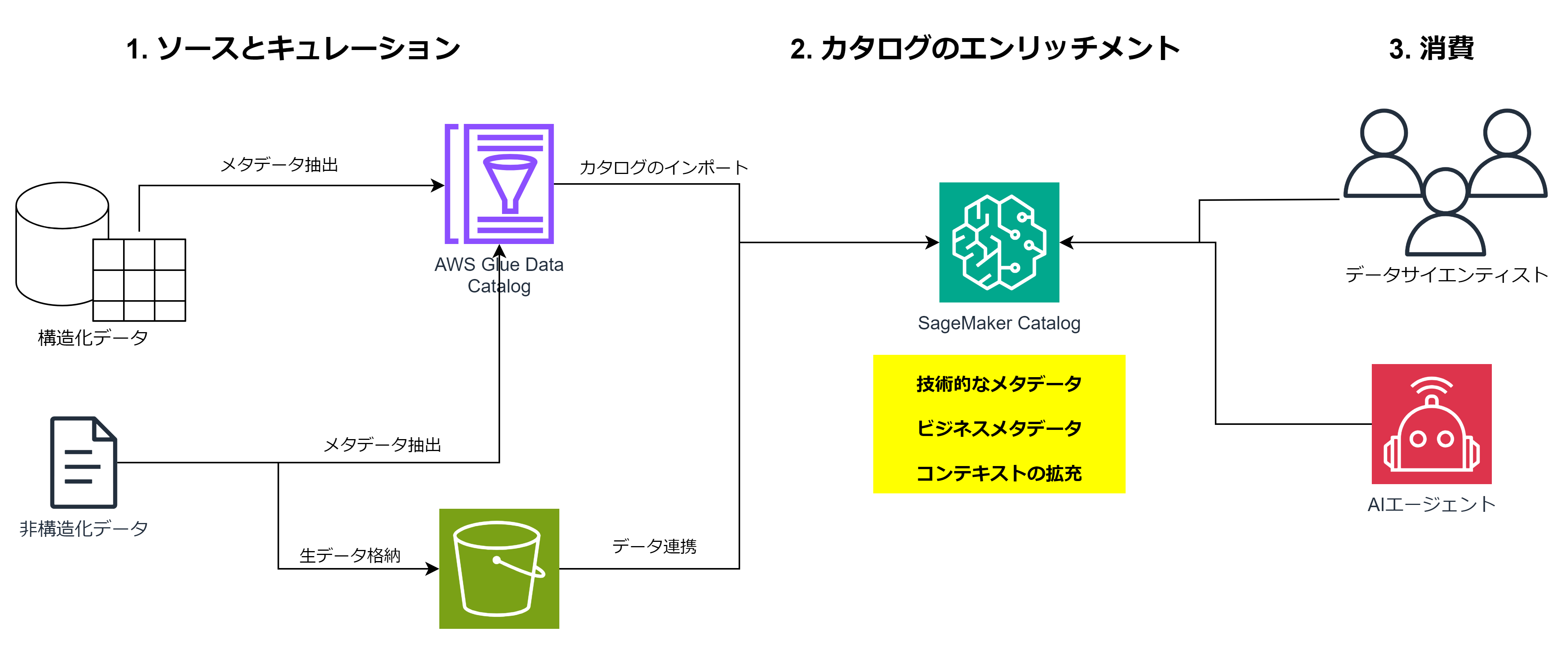
1. ソースとキュレーション (Source and curation)
構造化データ(Sales dataなど)と非構造化データ(画像、PDFなど)の両方を扱います。
- 構造化データは AWS Glue Data Catalog へ。
- 非構造化データは S3 に格納し、そのメタデータを抽出。
2. カタログのエンリッチメント (Catalog enrichment)
SageMaker Catalog のインベントリ(Inventory)にこれらのメタデータをインポートし、統合管理します。
ここでは技術的なメタデータだけでなく、ビジネスコンテキスト(利用用途、所有者、品質スコア、分類タグなど) も付与します。
デモでは、画像データから抽出した特徴量(テキスト埋め込みなど)をメタデータとしてカタログ化する様子が紹介されました。
3. 消費 (Consumption)
ユーザー(データサイエンティストやAIエージェント)は、このカタログを通じて信頼できるデータプロダクトを発見し、サブスクライブします。
デモのシステム構成は以下です。
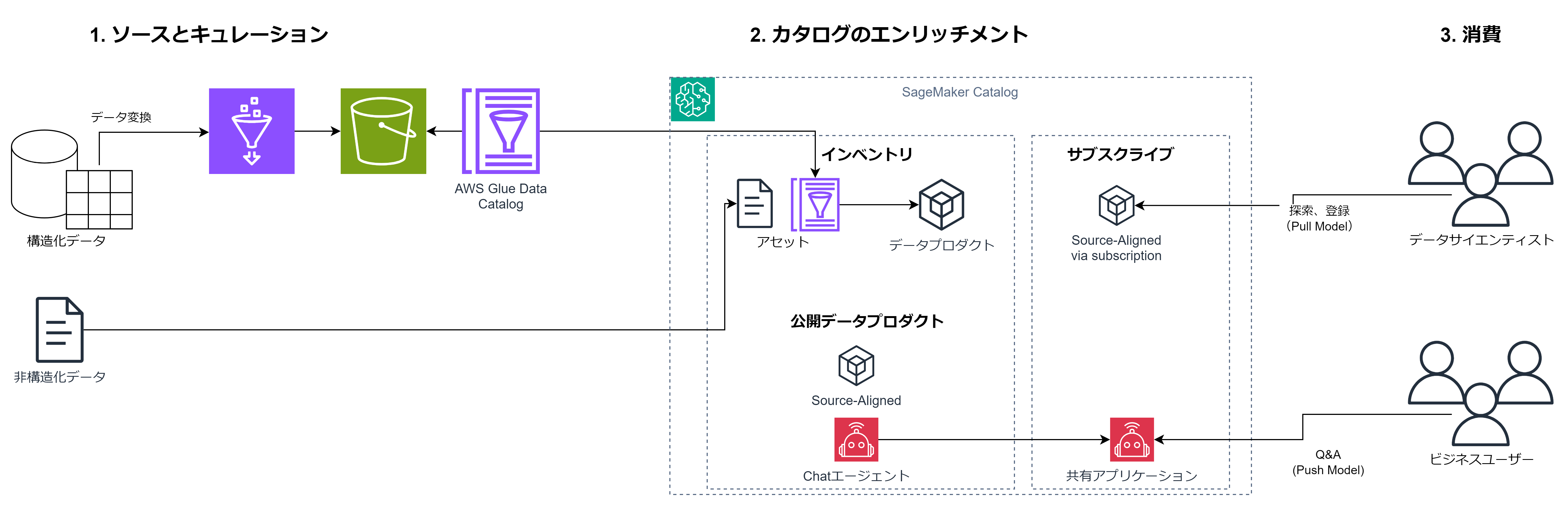
AIエージェントのためのデータ活用フロー
AIの精度(Accuracy)を向上させるための3つの主要なアプローチ(プロンプトエンジニアリング、RAG、モデルカスタマイズ)においても、
データプロダクトの考え方が適用されます。
高品質なプロンプトの実装
プロンプトも「作って終わり」ではなく、サイクルを回して改善します。
- 質問から始める
- 複雑なタスクを分解する
- コンテキストを含める
- 具体的な指示(Directives)と出力例(Example responses)を与える
作成したプロンプトテンプレート自体をカタログに登録し、組織内で共有・再利用可能にします。
高品質なRAGの実装
RAGにおいても、検索コーパスの品質が回答品質に直結します。
- データ準備: ソースデータからテキストとメタデータを抽出・チャンク化・埋め込み・インデックス化。
- 検索最適化: メタデータフィルターを活用したハイブリッド検索(キーワード検索 + ベクトル検索)。
- 回答生成: 検索結果をランク付けし、コンテキストとしてプロンプトに組み込む。
SageMaker Catalogから抽出したリッチなメタデータをJSON形式でRAGの知識ベースに組み込むことで、
AIエージェントがデータの意味(最終更新日、品質スコアなど)を理解して回答できるようになります。
Fine tuning through evaluation
ファインチューニングにおいても、以下のフローでデータを管理します。
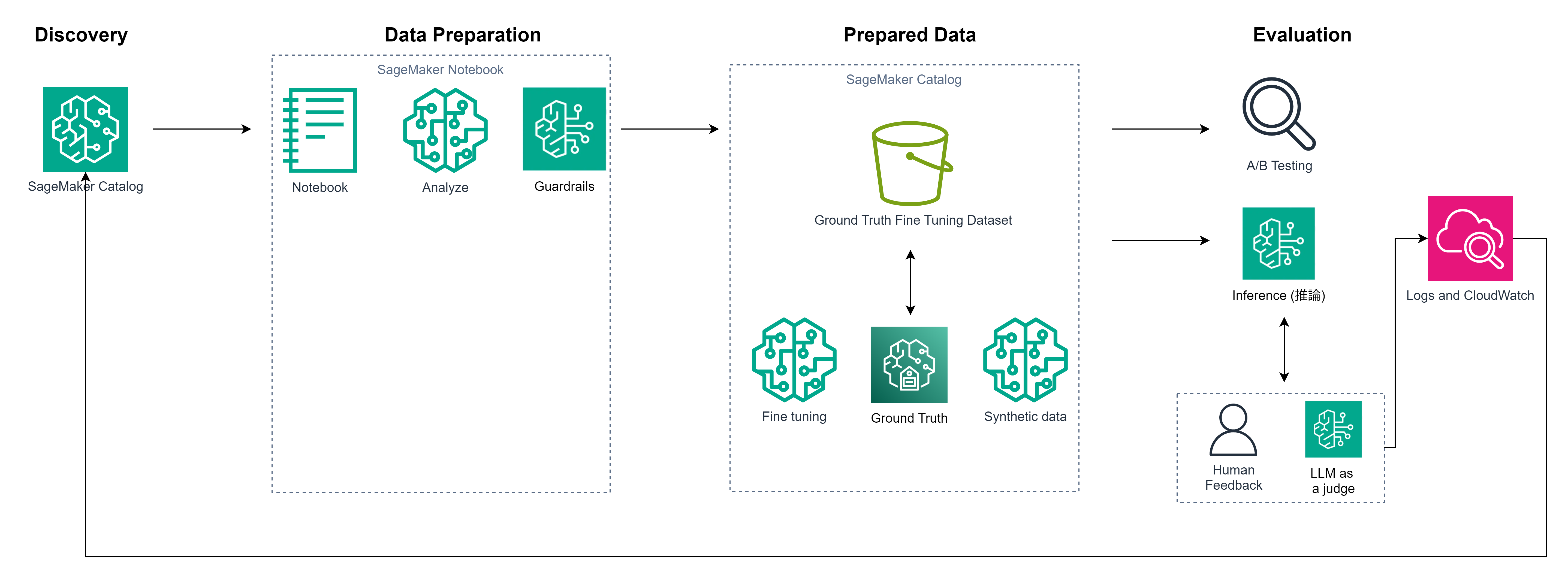
- Discovery: SageMaker Catalogでデータを探す。
- Preparation: SageMaker Notebookでデータを分析(ガードレールを適用)。
- Prepared Data: 作成したデータセット(Fine Tuning, Ground Truth, Synthetic Dataなど)を、SageMaker Catalogに登録。
- Evaluation: A/Bテストによる評価、人間のフィードバックや「LLM as a judge」による評価を行い、そのログをSageMaker Catalogにフィードバックする。
デモ:AIエージェントによるデータスチュワードシップ
セッションの最後に、「AIエージェントがデータカタログの品質を向上させる」というユースケースのデモがありました。
シナリオ:
組織内のデータカタログには、メタデータ(説明文、タグ、用語集など)が欠落している資産が多数あり、検索性が低い状態です。
データスチュワードは、AIエージェントを使ってこれを改善します。
- 指示: データスチュワードがエージェントに「メタデータに不備があるカタログをリストアップし、修正して」と指示。
- 検出: エージェントがカタログをスキャンし、品質スコアが低い資産を特定。
-
自動修復: エージェントがデータの中身を分析し、自動的に以下を実行。
- 適切なビジネスディスクリプション(説明文)の生成
- 分類タグ(PII/PHIなど)の付与
- 推奨ユースケースの追記
- サンプルSQLクエリの生成
- 結果: エージェントの修正により、メタデータ品質スコアが大幅に向上。
人間が手動で行うと膨大な時間がかかる「メタデータの整備」をAIエージェント自身に行わせることで、
データプロダクトの価値を高めるエコシステムが示されました。
まとめ
本セッションでは、AI時代における「データプロダクト」のあり方について議論されました。
単にデータを集めるだけでなく、コンテキスト(メタデータ)を付加し、製品としてライフサイクルを管理すること、
そして プロンプトやモデル自体もデータプロダクトとして扱うこと の重要さが示されました。
最後の「AIエージェントがデータスチュワードとして動作する」デモでは、
AIエージェントを活用しデータガバナンスを実現する方向性が示されており、印象的でした。
AIエージェントのパフォーマンスを最大化するために、データプロダクトの品質管理の重要性を学ぶことができました。
[re:Invent 2025] 参加レポート一覧はこちら (随時更新)