表やグラフをつくる際に意外と必要な機能。
知っているのと知らないのでは、天と地の差がある、そんなピボットテーブル機能をまとめてみました。
ちなみに私は学生時代、Excelのピボットテーブル機能も知らず、泣きながら実験データを整形していた記憶があります...
Qiitaへの投稿ということもあり、今回はpandasデータフレームで試してみました。
ピボットテーブルとは
Excelにある機能のひとつで、あらかじめ登録したリストのなかから必要なデータを取り出して、あらゆる方向から集計や分析を行うツールのことを指しています。
特に「集計」機能は便利で、下図の左のようなデータ形式から右のような結果を返すことができます。
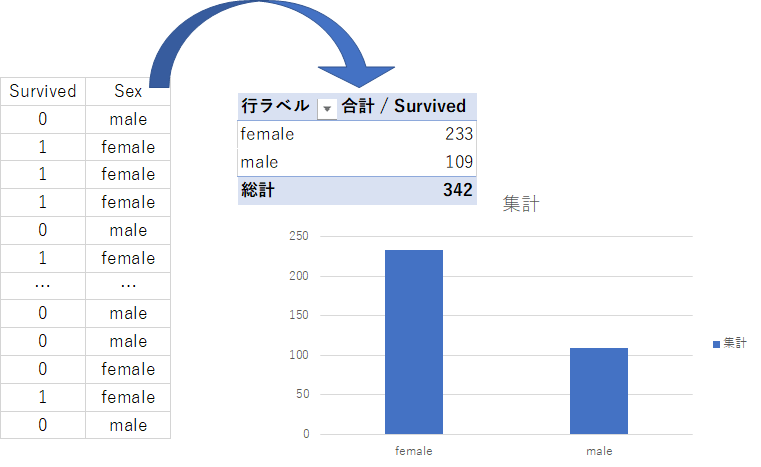
クロス集計したい時や、ちょっとややこしいグラフをつくる際などに必要になります。
今回はExcelではなく、pandasデータフレーム上で似たことをやってみます。
練習用に使ったデータ
kaggle Titanicコンペのtrainデータを拝借。
それぞれのカラムの意味については、こちらを参照ください。
本題
そのままだとこんな感じですので...

解釈が難しい!
準備
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Path
input_path = "../input_data/"
# Set Display Max Columns
pd.set_option("display.max_columns", 50)
train = pd.read_csv(input_path + "train.csv", sep=",", header=0, quotechar="\"")
# test = pd.read_csv(input_path + "bank/test.csv", sep=",", header=0, quotechar="\"")
# 扱いにくいので欠損値処理
train["Embarked"] = train.Embarked.fillna("S")
train["Age"]=train["Age"].fillna(train.Age.mean())
# 年齢を年代別へ
labels = [ "{0} - {1}".format(i, i + 9) for i in range(0, 100, 10) ]
train["Age"] = pd.cut(train["Age"], np.arange(0, 101, 10),
include_lowest=True, right=False,
labels=labels)
# 今回の目的に扱いやすそうなのに絞る
df = train[["PassengerId", "Survived", "Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]]
# データの確認
df.head()
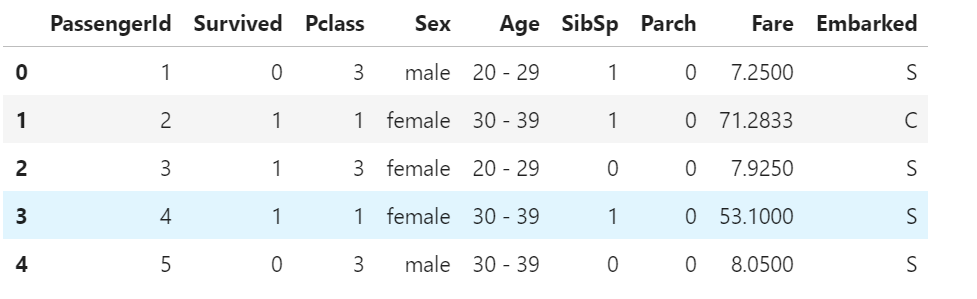
扱いにくそうな乗客者の名前などは消去。
使うのはpivot_table関数
最低限、必要な引数は下の3つ
・data(第一引数): 元データのpandas.DataFrameオブジェクトを指定。
・index: 元データの列名を指定。結果の行見出しとなる。
・columns: 元データの列名を指定。結果の列見出しとなる。
引数index, columnsに指定していない列の平均値が結果として算出されるが、型が数値でない列は除外されます。
基本的な使い方
df.pivot_table(index="Age", columns= "Sex", values="Fare")
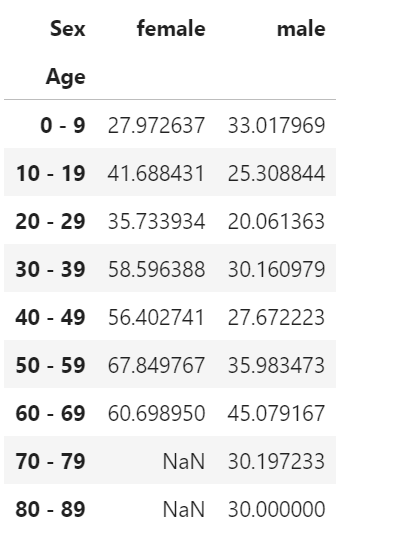
デフォルトでは集計の平均値を返している。
(引数にaggfuncを追加することで他の結果も計算できます。)
結果の値の算出方法を指定: 引数aggfunc
デフォルトでは平均値が算出されるが、引数aggfuncに関数を指定することでほかの方法で値を算出することが可能。
デフォルト(引数aggfuncを省略した場合)はnumpy.mean()が指定される。
df.pivot_table(index="Age", columns= "Sex", values="Fare", aggfunc='count')
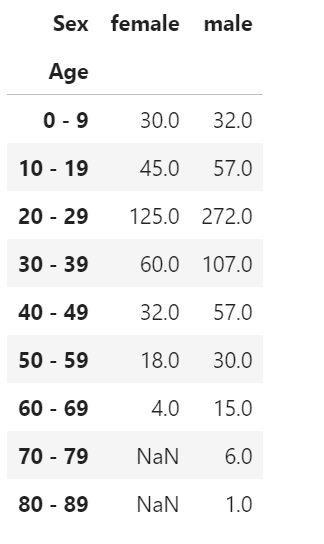
aggfunc='count'指定することで、当てはまるデータ個数を数え上げる。
行・列も複数選択できる:引数 index, columns
df.pivot_table(index="Age", columns= ["Pclass","Sex"], values="Survived", aggfunc='mean')
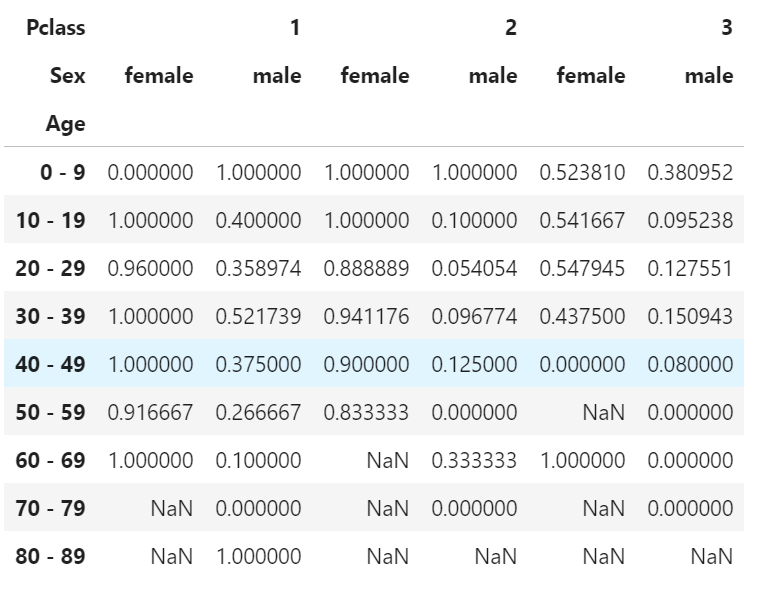
aggfuncに複数の算出方法を指定できる
df.pivot_table(index="Age", columns= ["Pclass","Sex"], values="Survived", aggfunc=["mean","count"])
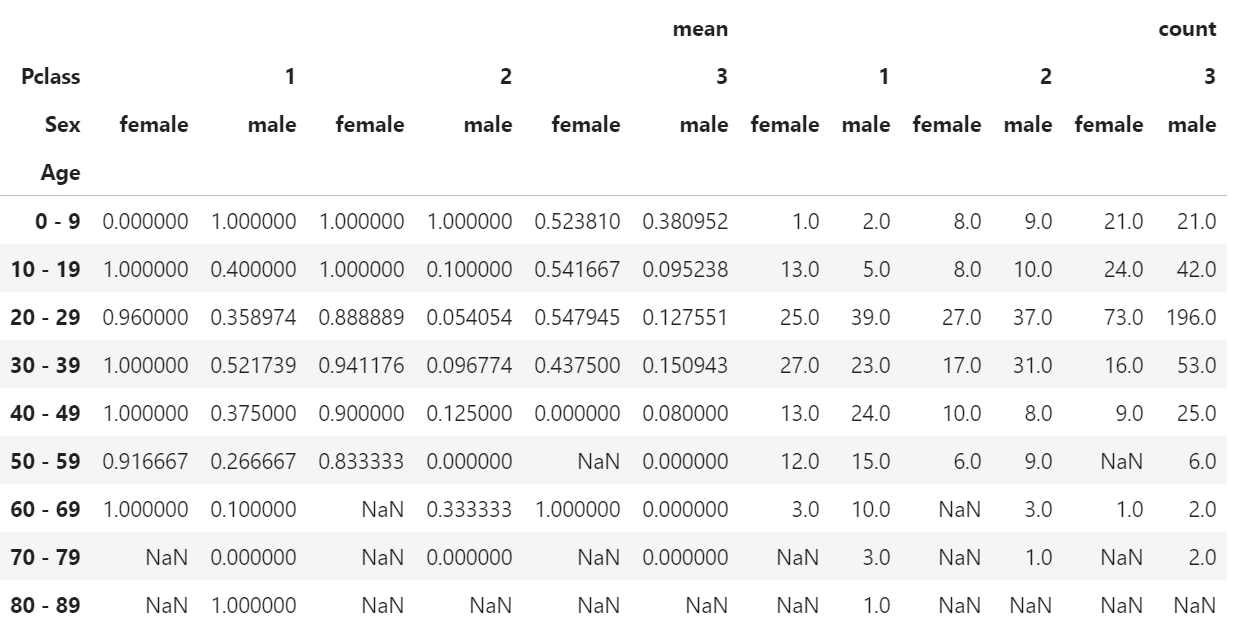
総計結果を追加する:引数margins, margins_name
df.pivot_table(index="Age", columns= ["Pclass","Sex"], values="Survived", aggfunc=["mean","count"],margins=True, margins_name="total")
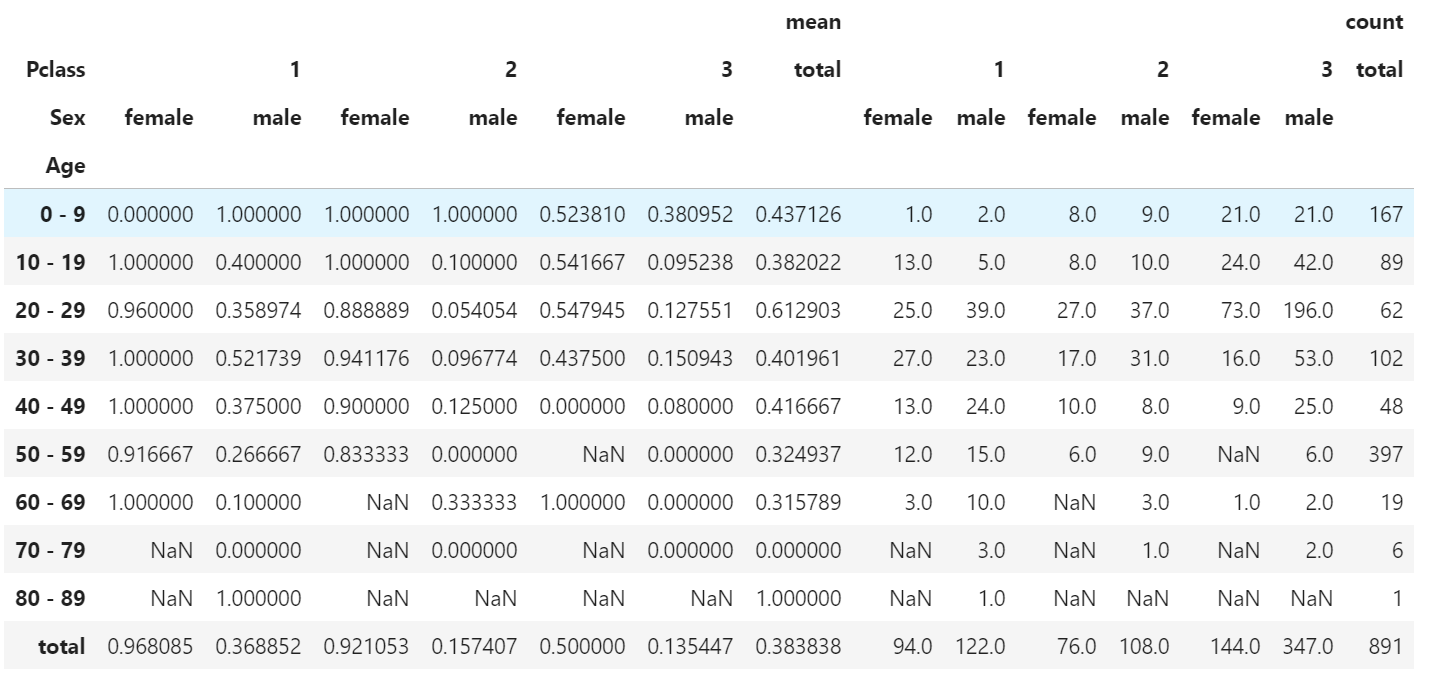
結果で規格化したい時はcross_tab関数を使う: 引数normalize
cross_tab関数の引数normalizeを指定することで、全体・行ごと・列ごとに規格化できる。
pd.crosstab(index=df.Age, columns= df.Sex, values=df.Fare, aggfunc='count', normalize=True)
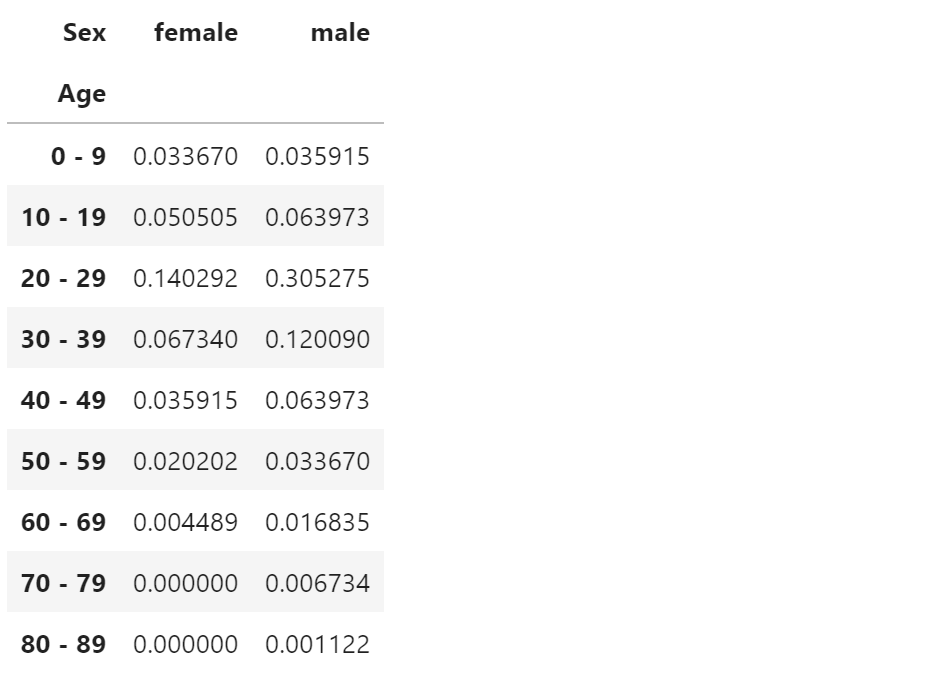
・normalize=Trueまたはnormalize='all'とすると、全体を合計すると1になるように規格化。
・normalize='index' or 'columns'とすると、行 or 列ごとに合計すると1になるように規格化。
以上。
ピボットデーブルの操作後、列が多層化するのですが、列指定で抜き出すことができません。
知ってる方いらっしゃいましたら、コメントください...
参照・引用
・http://yaginogogo.hatenablog.jp/entry/2016/04/22/011327
・https://note.nkmk.me/python-pandas-pivot-table/
・https://deepage.net/features/pandas-pivot.html
・https://boxil.jp/mag/a2149/
・https://deepage.net/features/pandas-pivot.html
・https://qiita.com/kshigeru/items/bfa8c11d1e6487c791d3
・https://qiita.com/hoto17296/items/3442af64c7acb682de6a