はじめに
Kagglerの登竜門的な課題である、titanicコンペに改めて挑戦してみました。自身がこれまで勉強してきたことの再整理も含めて、課題に取り組んでおります。また本記事は【前編】【後編】に分けて、【前編】では、扱うデータの特徴をつかむこと、【後編】で予測モデルの構築に重きを置いて記載します。
動作環境
・Kaggle kernel上
コード
ライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import plotly.offline as py
import plotly.graph_objs as go
import cufflinks as cf
py.init_notebook_mode(connected=True)
# デフォルトでPlotlyがオンラインモードになっているので、オフラインモードへと変更
# cf.go_offline()# 恒久的にデフォルトをオフラインモードに
データセットの読み込み
train=pd.read_csv("../input/train.csv")
test=pd.read_csv("../input/test.csv")
data=[train,test]
データの中身を確認
train.info()

test.info()

train.head() #trainの先頭の5行を表示する

各カラムの説明としては以下を参照
・PassengerId – 乗客識別ユニークID
・Survived – 生存フラグ(0=死亡、1=生存)
・Pclass – チケットクラス
・Name – 乗客の名前
・Sex – 性別(male=男性、female=女性)
・Age – 年齢
・SibSp – タイタニックに同乗している兄弟/配偶者の数
・parch – タイタニックに同乗している親/子供の数
・ticket – チケット番号
・fare – 料金
・cabin – 客室番号
・Embarked – 出港地(タイタニックへ乗った港)
train.tail() #同様にtrainの末尾の5行を表示しよう。

データ欠損の確認
train.isnull()
train.isnull().sum() #各列の欠損値を数える

train.notnull().sum() #逆に、欠損値でないところを数える

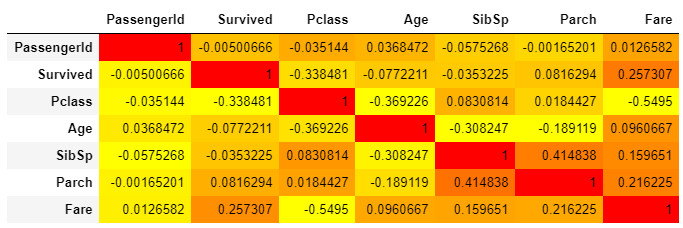
相関関係の確認
train.corr().style.background_gradient(cmap="autumn_r")
# Styler機能を用いて、色調を"autumn_r"として一覧表にして表示してみる
# train.corr()はデータの各要素(各列)同士の相関係数を表形式で視覚化する
# 文字列データは自動的に外してくれる
生存率
全体の生存率
この事故で生き残った人はどれほどで、亡くなった人はどれほどいたのだろうか?
生き残った人と亡くなった人の割合を円グラフにし、それぞれの人数を棒グラフにして、左右に並べて表示
fig,ax=plt.subplots(1,2,figsize=(8,4))
ax[0].pie(train["Survived"].value_counts(),labels=["Deceased","Survived"] , autopct='%.1f%%' )
ax[0].set_title("Ratio of the Survived/Deceased")
sns.countplot(train["Survived"],ax=ax[1])
*棒グラフはseaborn使った方が楽
ax[1].set_title("The number of Survived/Deceased people")
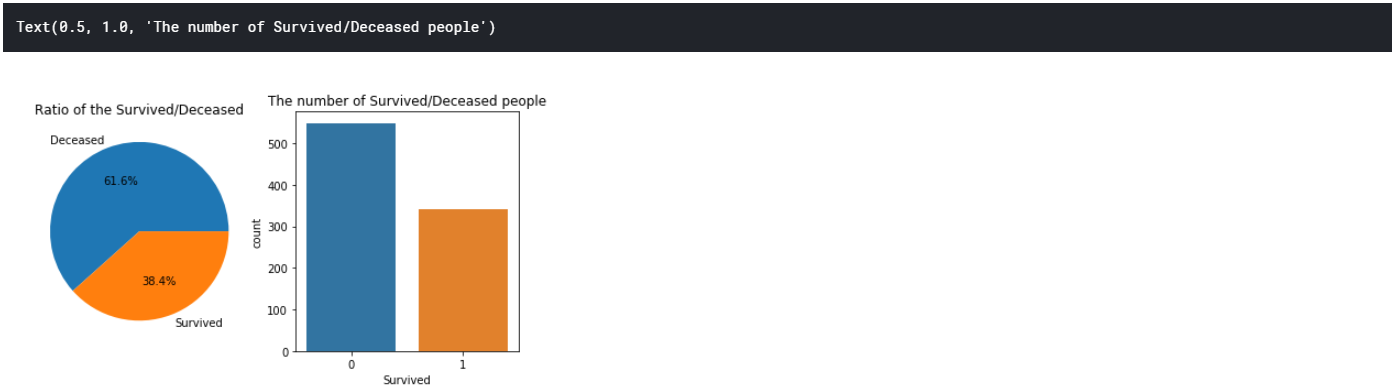
print(train.Survived.mean())

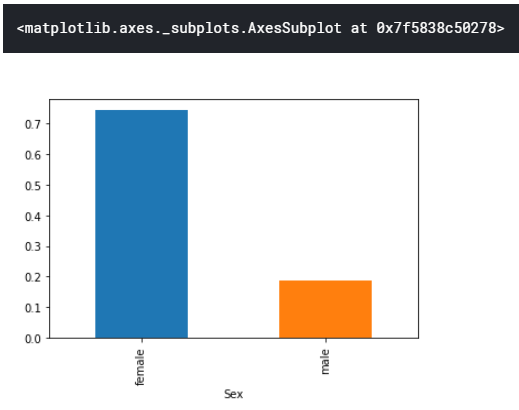
生存率 vs sex(性別)
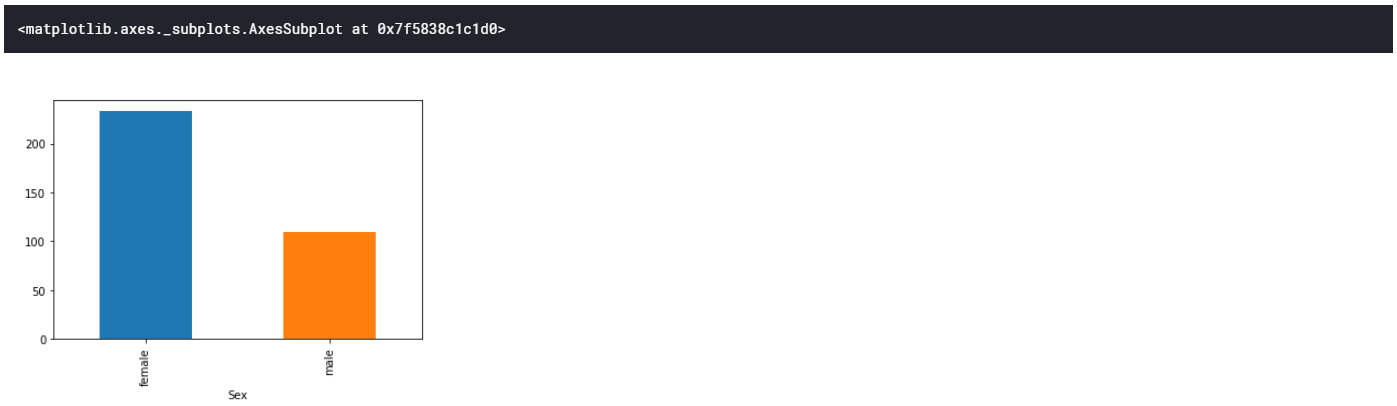
train.groupby(["Sex"]).sum()["Survived"]
# 男女でそれぞれ何名の方が生存したかを表示

train.groupby(["Sex"]).sum()["Survived"].plot.bar()
# 男女でそれぞれ何名生き残ったかを、pandasのビルトイン描画機能を用いてグラフ化
生存率 vs Pclass(チケットクラス)
train.groupby(["Pclass"]).mean()["Survived"].plot.bar()

train.groupby(["Pclass"]).mean()["Survived"]
# train.groupby(["Pclass"])["Survived"].mean() #でもOK

生存率 vs sex & P-class
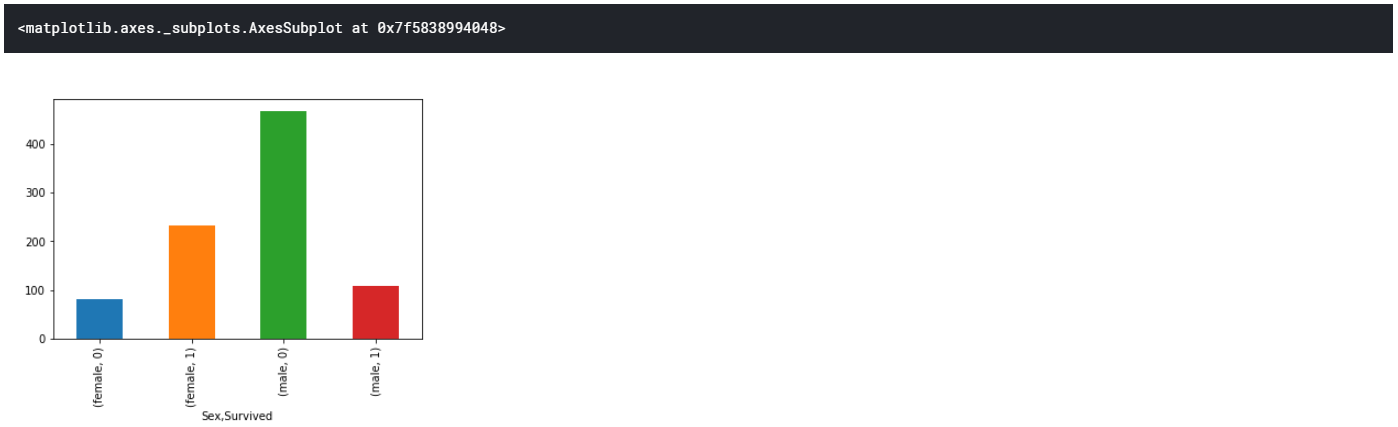
上の方法では、生き残った人数しかわからないため、亡くなった人数も同時に調べたい。
女性で亡くなった人数、生き残った人数
男性で亡くなった人数、生き残った人数
を取得する
train.groupby(["Sex","Survived"])["Survived"].count()
# train.groupby(["Sex","Survived"]).count()["Survived"]だと、動作しない

これもpandasのビルトインの描画機能で棒グラフを作成
train.groupby(["Sex","Survived"])["Survived"].count().plot.bar()
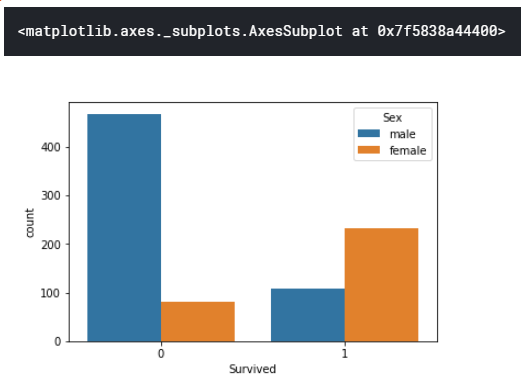
練習のため、seabornで同じ意味合いの棒グラフをプロット
棒グラフの横軸(カテゴリ)は"Survived"とし、縦軸はその人数とする。
ただし、棒グラフは性別でわけ、男性についてのグラフと女性についてのグラフが隣り合わせでプロットされるようにする
# seaborn使って、性別ごとに2本のバーをまとめる
sns.countplot(x="Survived",hue="Sex",data=train)
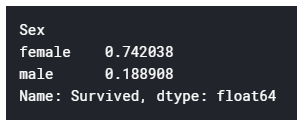
性別ごとに生存率を求めてみよう
# 生存率を求める
train.groupby(["Sex"]).mean()["Survived"]
train.groupby(["Sex"]).mean()["Survived"].plot.bar()
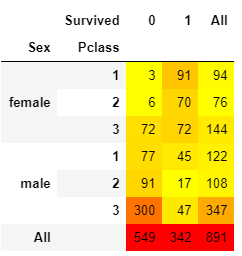
"Sex"(2値),"Pclass"(3値)を元に6つにセグメントを分割し、それぞれについて生き残った人数を調べ、
表形式で表示し、これに"autumn_r"の色調で色をつける
pd.crosstab([train["Sex"],train["Pclass"]],train["Survived"],margins=True).style.background_gradient(cmap='autumn_r')
# crosstabを使うとgroupbyと似たようなまとめかたができるが、groupbyと違って、抽出した集合にたいしてmeanやmaxなどの演算ができない
# 人数だけ見てるとよくわからない
Pclass,Sexによって出費額がどのように分布するかを図示してみよう。
violinplotを用いる
violinplot
sns.violinplot("Pclass","Fare",data=train,hue="Sex",split=True)
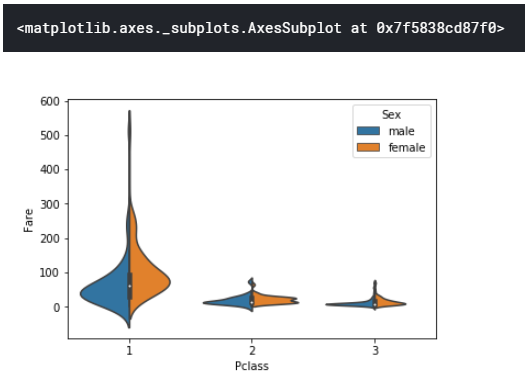
1等級のチケットは値段のばらつきが相当大きいようである。
そして、少数ではあるものの2等・3等より安い値段で1等に乗っていた
乗客もいたという点で、単純に1等が一番高いとは言えないことがわかった。
人によってここまで値段がばらついているあたり、大人の事情が垣間見える。
ところで、グラフをよくみると、縦軸が負の部分にプロットが食い込んでいることがわかる。
もしかして、"Fare"には負の数が含まれているのだろうか。
お金をもらって乗船している人がいるということだろうか。
min()関数を使って"Fare"列の最小値を見てみよう。
train.Fare.min()

さすがに最小値は負の数ではなかった。
violinplotの両側はカーネル密度推定の曲線であり、一つ一つのデータが正規分布による広がりを持っているため、
負の数が要素に含まれていなくても分布のプロットが負の領域にさしかかることが起こりうる。
Fareには負の数は含まれていなかったものの、無賃で乗船できた方はいたことがわかった。
無賃で乗った人は何人いて、そのうちの何割が生き残ったのだろうか。
調べてみよう。
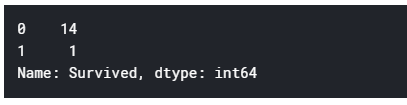
train["Fare"]の値が0である行のうち、Survivedが1であるデータ数、0であるデータ数を数える。
train.loc[train.Fare==0,"Survived"].value_counts()
残念ながら、無賃で乗船した方は一人を除いて全員(train分に限るが)亡くなったようである。
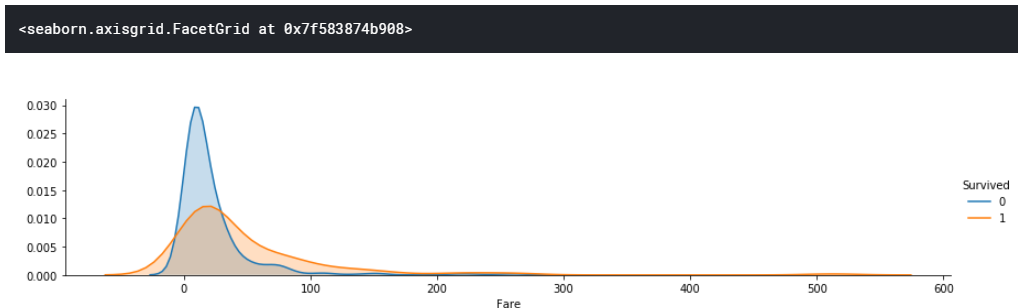
次に、生き残った人・亡くなった人をhueで区別して、それぞれについての乗車賃の分布をカーネル密度推定のグラフで示そう。
残念ながら、無賃で乗船した方は一人を除いて全員(train分に限るが)亡くなったようである。
カーネル密度推定グラフ
次に、生き残った人・亡くなった人をhueで区別して、それぞれについての乗車賃の分布をカーネル密度推定のグラフで示す
facet = sns.FacetGrid(train, hue="Survived",aspect=4)
facet.map(sns.kdeplot,'Fare',shade= True)
# facet.set(xlim=(0, 100))
facet.add_legend()
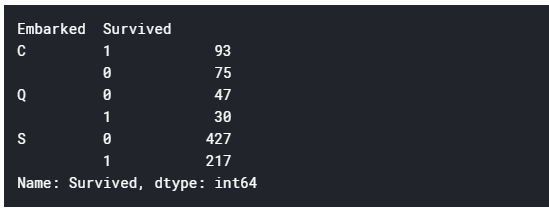
どの港から乗ってきたかによってどれだけ生存率が異なるだろうか。
3つの港ごとの生存者数・志望者数を調べる
train.groupby("Embarked").Survived.value_counts()
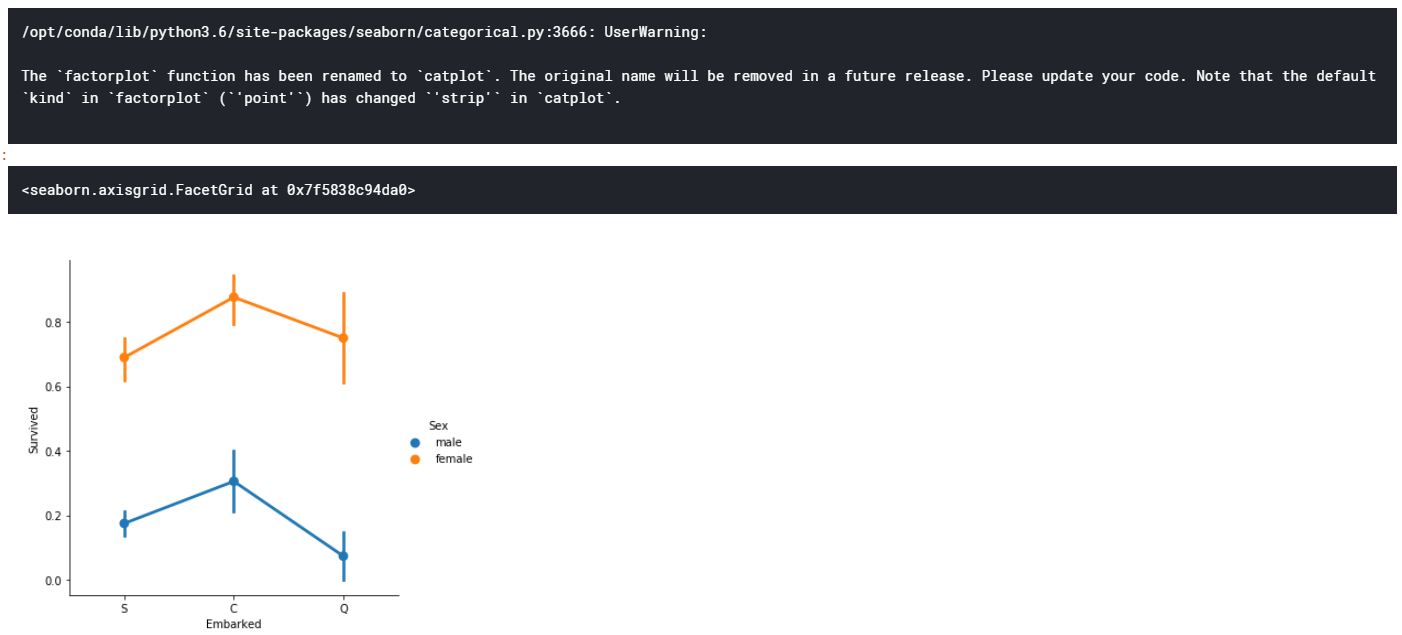
港ごとの生存率を、性別で区別して、factorplot(pointplotの形式)で描画
sns.factorplot("Embarked","Survived",data=train,hue="Sex")
# sns.factorplot("Embarked","Survived",data=train)
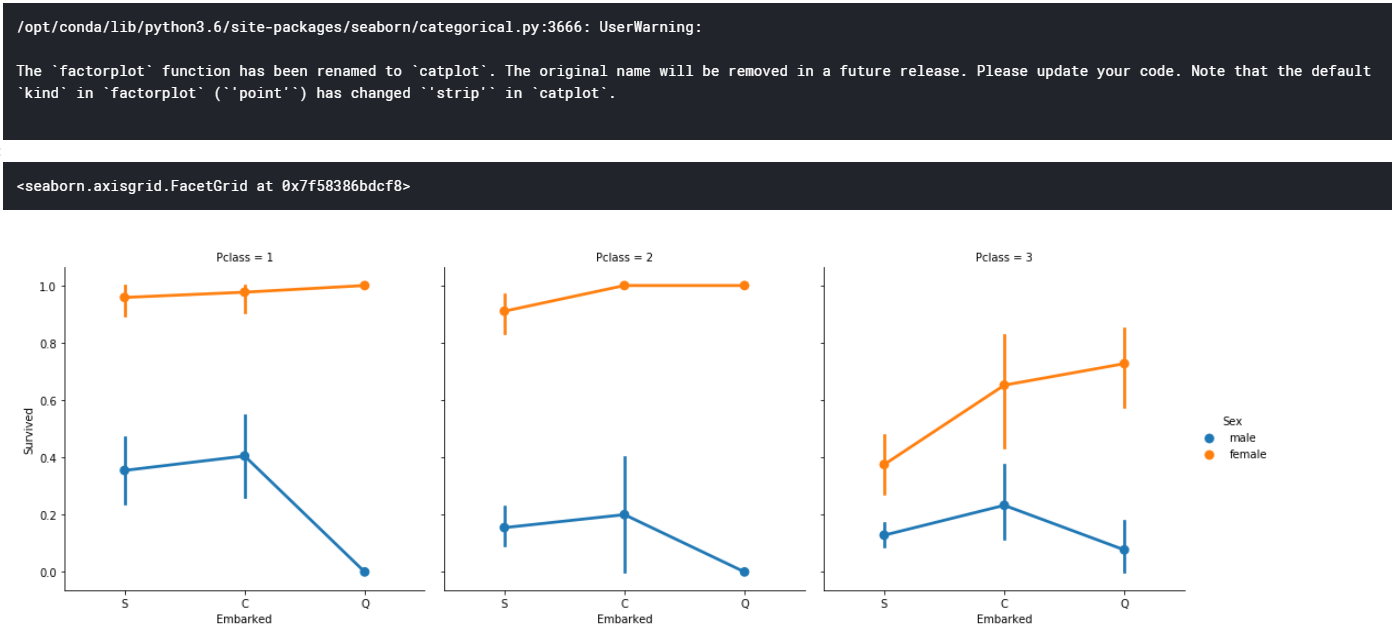
次は、横軸:各港、縦軸:生存率 を性別で区別したグラフを、Pclassごとに3つに分けて描画し、3つのグラフを並べる。
sns.factorplot("Embarked","Survived",data=train , hue="Sex", col="Pclass")
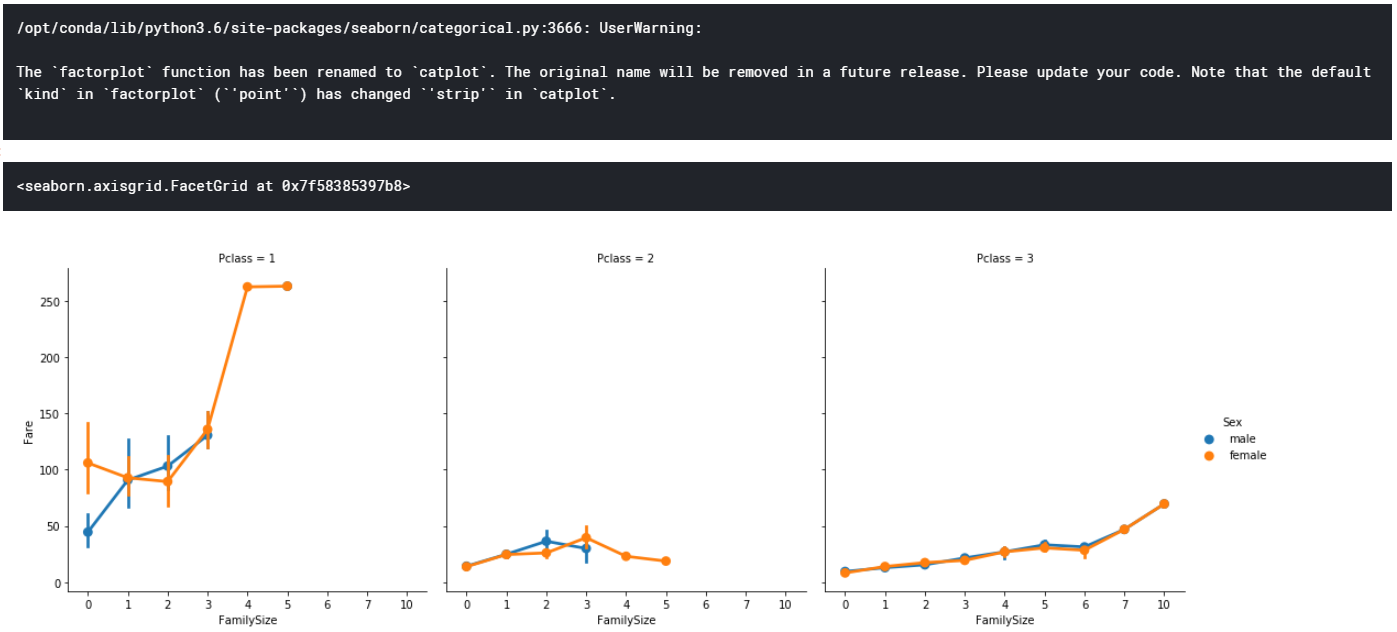
temp=pd.DataFrame()
temp["FamilySize"]=train["SibSp"]+train["Parch"]
temp["Pclass"]=train["Pclass"]
temp["Sex"]=train["Sex"]
temp["Fare"]=train["Fare"]
sns.factorplot("FamilySize","Fare",data=temp,hue="Sex",col="Pclass")