文字化けの仕組みエンコーディング
文字化けとは
コンピュータが文字を読み込んだ際に、本来表示されるべき文字が別の文字や記号として表示されてしまうことです。
文字化けのデメリット
正しい情報を読み取ることができなくなります。
発生のタイミング
Webサイトの閲覧時
¥メールの送受信
ファイルのダウンロード
文書の印刷時など
文字コード
文字コードは、「個々の文字に対して、個別に数字を割り当てる」ということが仕組みとして組み込まれています。つまりそれぞれの文字や記号に割り当てられた固有の番号。パソコンが理解できるのは数字のみです。パソコンは漢字や英語を出力することはできますが、実際にはそれらの文字を直接理解しているわけではありません。
文字コード例
Unicodeなど
Unicodeは、世界中のほぼすべての文字に対応することを目指した文字コードシステム。Shift_JISが日本語に特化しているのに対し、Unicodeは世界中の言語や文字を包括的にサポートしています。
UTF-8は、2025年現在、ほとんどのPCやスマートフォンなどのデバイスで標準的にサポートされています。可変長エンコーディング方式を採用しており、英数字などのASCII文字は1バイトで表現されます。
一方、日本語や中国語などの非ラテン文字は複数バイトで表現されますが、必要最小限のバイト数でエンコードされるため、データサイズを効率的に抑えることができます。
文字化けが起こる主な原因
ファイルの作成時と、読み込み時で、使用している文字コードの種類・形式が異なっているケースです。
具体的に調査
CSV保存形式は

UTFー8
該当エクセルファイル上で右クリックして「メモ帳で編集」を選択

文字コードは
編集画面でも確認できる

今回はUTF-8(BOM付)
文字コード変更して保存
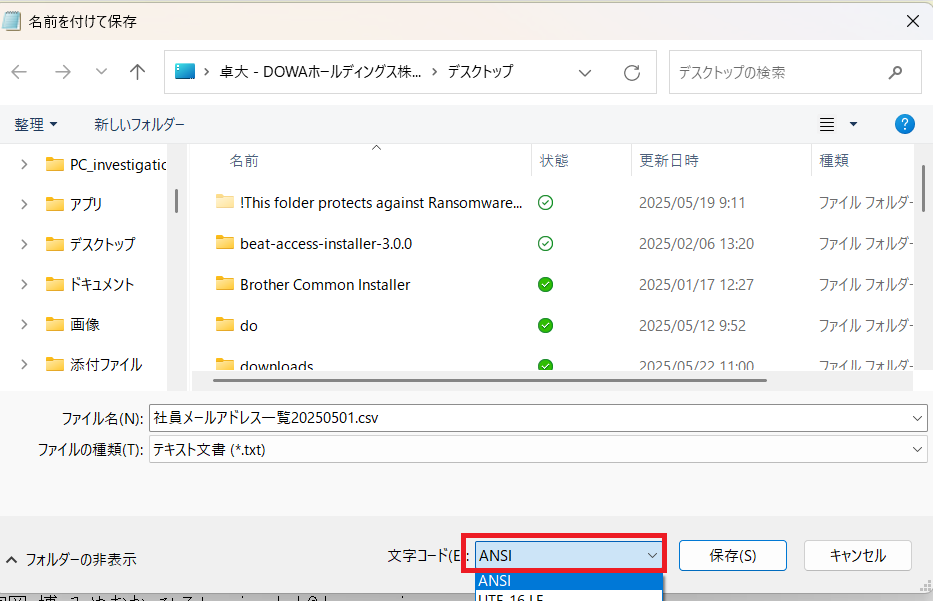
outlookのcsvインポートまで戻って
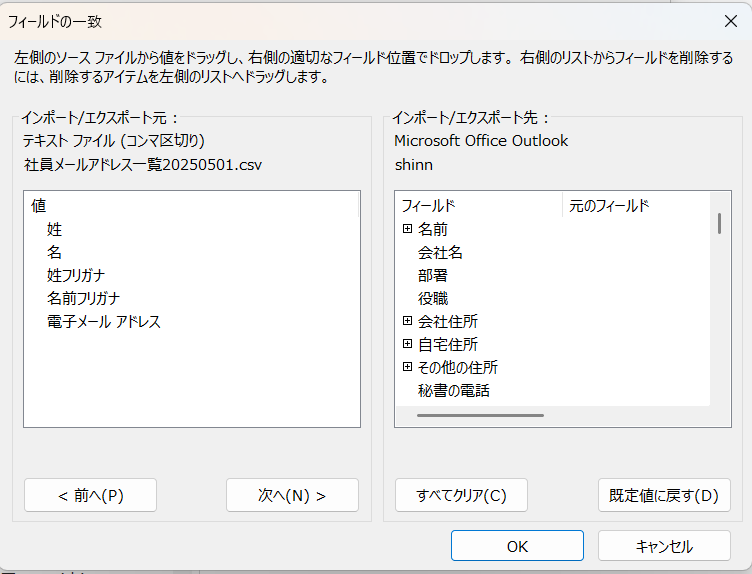
正しい日本語が左窓に反映しているので
完了して取り込んでみる

うまく取り込んで使うことができました。[shinnフォルダの中身が宛先としてでてきた
