Summary
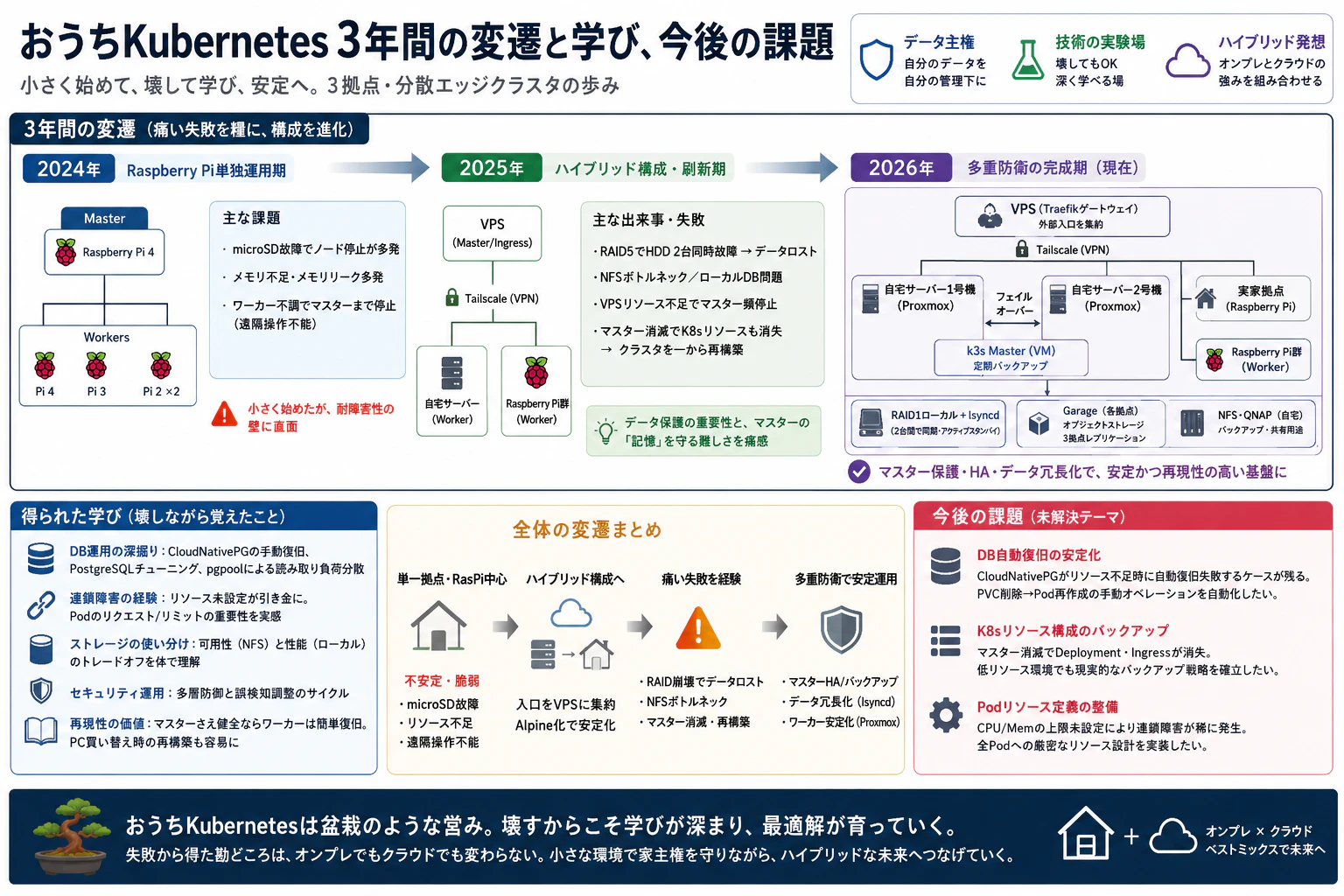
- 自宅・実家・クラウドの3拠点にまたがる分散Kubernetes環境を3年かけて構築・運用した際の気づきを共有
- Raspberry Pi単独構成から始まり、RAID崩壊・マスター消滅・NFSボトルネック・連鎖障害という痛い失敗を繰り返しながら、現在の安定構成にたどり着いた変遷を記録
- 業務では取り入れづらい技術を個人環境で積極的に試し、失敗を繰り返すことで得られる技術獲得の場としてホームラボの価値がある
やらないこと
- Kubernetesのインストール手順・コマンド詳細の解説
- 各OSSの機能詳細の解説
- ハイパースケーラー相当の大規模構成を前提とした議論
なぜホームラボを作るのか——「データ主権」と「技術の実験場」
世界的にGDPRをはじめとした法規制の遵守や個人情報保護の潮流が加速している。「自分のデータがどの国のサーバーに、どの法律のもとで保存されているか」をコントロールする権利、すなわち データ主権(Data Sovereignty) という概念が重要性を増している。
普段何気なく使っているクラウドストレージ、写真管理アプリ、パスワードマネージャー。それらのデータがどこに存在しているか、意識したことはあるだろうか。クラウドのマネージドサービスはスケーラビリティや運用負荷の軽減において優れた選択肢であり今後も大きな価値を持ち続ける。しかし「自分のデータを自分の管理下に置く」という選択肢も存在する。この問いに個人として向き合うことが、ホームラボ構築の出発点である。
もう一つの動機は、技術の実験場としての価値である。業務システムでは採用リスクが高く試しにくい技術——分散ストレージ、DBクラスタの冗長化、コネクションプーリング、読み取り負荷分散——を個人環境であれば積極的に導入し、失敗を恐れずに試すことができる。壊しても困るのは自分だけであり、その分だけ深く学べる。インフラ・セキュリティ・ネットワークの知識がホームラボの手入れを通じて自然と身についていく。まさに盆栽のような営みである。
クラウドかオンプレミスかという二項対立ではなく、データ主権・セキュリティ・コスト・利便性を見極めながら両者の強みを組み合わせるハイブリッドな発想が重要であると考えている。
やったこと
現在の構成——3拠点・分散エッジクラスタ
自宅・実家・クラウドVPSの3拠点をTailscale(WireGuardベースのVPN)で接続し、軽量KubernetesディストリビューションであるK3sの単一クラスタとして動作させている。以下に全体構成図を示す。
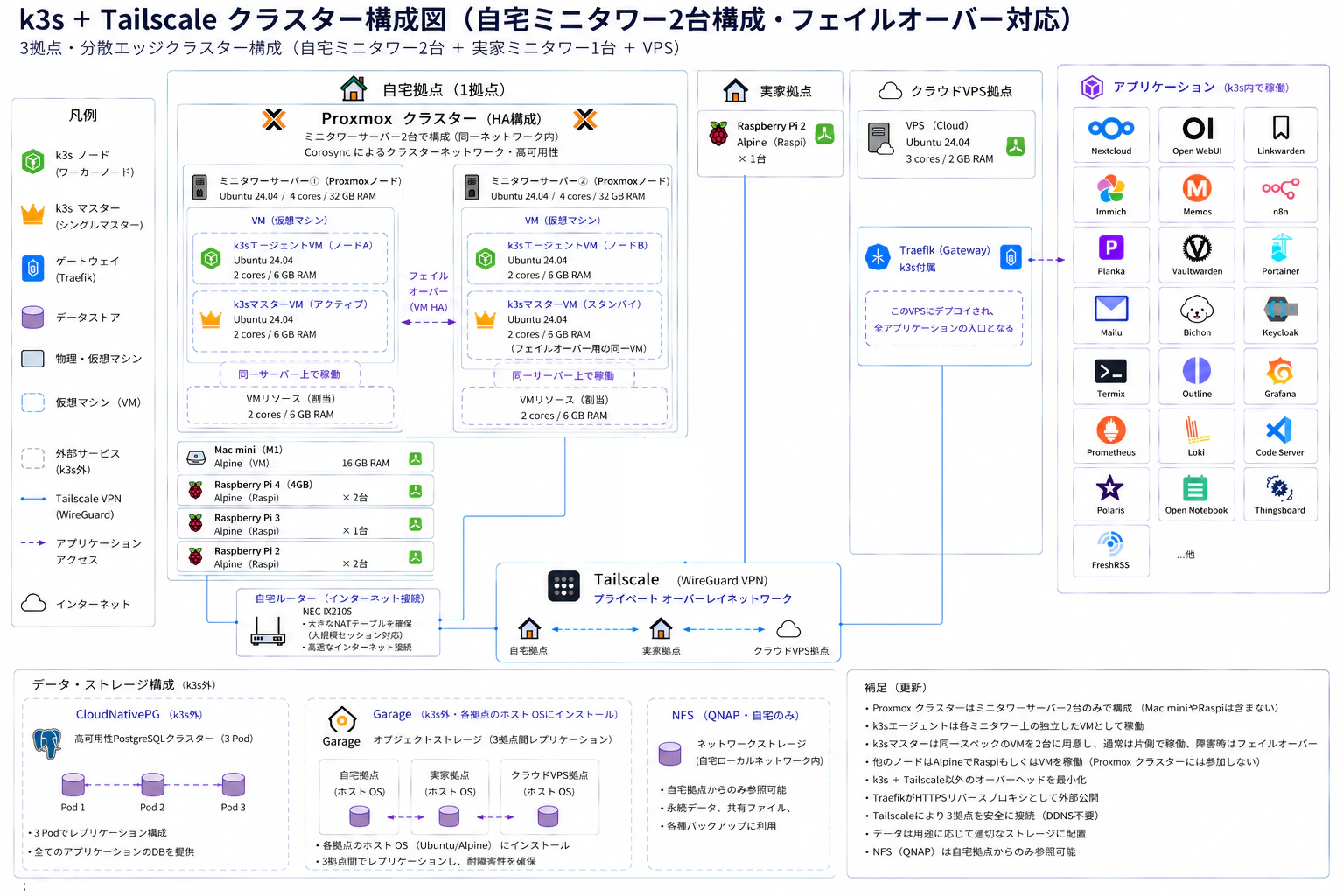
インターネットからの入口はクラウドVPS上のTraefik(リバースプロキシ)のみに絞り、すべての拠点はTailscaleのプライベートネットワークで安全に接続されている。
ノード構成
| 拠点 | ハードウェア | OS | 役割 |
|---|---|---|---|
| 自宅 | ミニタワーサーバー1号機(4コア/32GB RAM) | Ubuntu 24.04 | Proxmoxホスト。k3sマスターVM(2コア/6GB)+k3sワーカー |
| 自宅 | ミニタワーサーバー2号機(4コア/32GB RAM) | Ubuntu 26.04 | Proxmoxホスト(増設)。マスターのフェイルオーバー先+k3sワーカー |
| 自宅 | Mac mini M1(16GB) | Alpine (VM) | k3sワーカー |
| 自宅 | Raspberry Pi 4(4GB)× 2台 | Alpine | k3sワーカー |
| 自宅 | Raspberry Pi 3 × 1台 | Alpine | k3sワーカー |
| 自宅 | Raspberry Pi 2 × 2台 | Alpine | k3sワーカー |
| 実家 | Raspberry Pi 2 × 1台 | Alpine | k3sワーカー(エッジ拠点) |
| クラウドVPS | VPS(3コア/2GB RAM) | Ubuntu 24.04 | Traefikゲートウェイ。外部からのHTTP/HTTPSの入口 |
データ・ストレージ構成
| ストレージ | 用途 | 冗長化方式 |
|---|---|---|
| CloudNativePG(k3s内) | 全アプリケーションのPostgreSQLクラスタ(3 Pod) | Podレプリケーション |
| Garage(各拠点ホストOS) | オブジェクトストレージ(3拠点間レプリケーション) | 拠点間レプリケーション |
| NFS・QNAP(自宅のみ) | 標準的な永続データ・共有ファイル・バックアップ | 自宅ローカル冗長 |
| RAID1ローカル+lsyncd(自宅2台) | ストレージ性能要求が高いデータ・ローカルDBファイル | lsyncdによるアクティブスタンバイ同期 |
稼働しているサービス
| カテゴリ | サービス |
|---|---|
| ファイル・コンテンツ管理 | Nextcloud, Immich, FreshRSS, Linkwarden |
| 生産性・ノート | Memos, Outline, Open Notebook, Planka |
| 認証・セキュリティ | Vaultwarden, Keycloak |
| 自動化・開発 | n8n, Code Server, Termix, Open WebUI |
| 監視・可視化 | Grafana, Prometheus, Loki |
| インフラ・その他 | Traefik, Portainer, Thingsboard, Polaris, Bichon, Mailu |
3年間の変遷 〜失敗から強くなるクラスター〜
2024年:Raspberry Pi単独運用期
Raspberry Piのみでk3sクラスタを構成し運用を開始した。マスターノードをRaspberry Pi 4に、ワーカーをRaspberry Pi 4/3/2で構成した。
直面した問題は以下のとおり。
- microSDカードへのI/O負荷が大きく、カードの故障によるノードの機能停止が多発した
- メモリリークが多発するようになった。そもそもRasPiのリソースが潤沢ではなく、稼働するOSSによってはPCレベルのメモリ量を求めるため、RasPiだけではサービス稼働が厳しくなった
- ワーカーが不調になるとマスターごと停止してしまうこともあり、遠隔で操作することができなくなり、物理的な電源断による再起動を余儀なくされることが増えた
2025年:ハイブリッド構成・Alpine化・RAIDとマスターの刷新期
リソース増強のためミニタワーサーバーとVPS(2GB RAM)を追加導入し、マスターノードをVPSに配置した。Tailscale経由でVPSと自宅をクラスタリングし、インターネットからの入口をVPSに集約する現在の構成の原型を作った。あわせてRaspberry PiノードにAlpine Linuxを採用し、OS部分やログローテーションをRAM上で動作させることでmicroSDの酷使問題を大幅に軽減した。
ミニタワーサーバーの導入とともにRAID5によるストレージ運用も開始した。しかしこの時期、十分なメンテナンス時間を確保できない状況が続いた結果、HDDの異常に気づかないままHDDが2台同時故障し、データロストに至った。
ここで クラスタは再構築できても、データは二度と戻らない。 という気づきを得て、今後はデータ保護を優先するようになった。
この失敗を受け、2025年後半にRAID5からRAID1へ変更した。 1台の故障予兆をSMART監視・メール通知で早期検知する仕組みを整え、RAID1サーバー単体での冗長性を高めた。
この時期、NFSを経由したストレージアクセスに起因する問題も表面化し始めた。以下のような NFSボトルネックとローカルDB問題 が発生した。
- NFSはQNAPの処理性能とネットワーク遅延がそのままPodのレスポンスに影響するため、ストレージ性能要求の高いサービスで顕著な遅延が発生した
- 一部アプリケーションがローカルファイルとしてDBを持つ構成(SQLiteなど)では、NFSマウント越しのファイルロックが不整合を起こし、Podが再起動不可になるケースも発生した
この経験から、データの性質とアクセスパターンに応じてストレージを使い分ける方針に切り替えた。
- NFS(QNAP): アクセス頻度が低い共有ファイルやバックアップ用途に限定する。
- RAID1ローカルストレージ: ストレージ性能要求が高いデータおよびローカルDBを利用せざるを得ないアプリケーションについては、RAID1サーバーのローカルディレクトリへ直接保存する。ただしこの時点ではサーバーは1台であり、RAID1単体での冗長性に留まっていた。
さらに、数ヶ月ほど運用を続けていると、VPSの慢性的なリソース不足によりマスターが頻繁に停止が起きるようになった。マスターを自宅のミニタワーサーバーへ移動しようとしたところ、マスターが消滅するとDeployment・IngressなどすべてのK8sリソース構成も消えた。 Veleroなどのバックアップツールは存在するが、当時の低リソース環境では現実的な時間でフルバックアップが完了せず、結果としてクラスタを一から再構築する羽目になった。
マスターノードはクラスタ全体の「記憶」を持つ。低スペックで運用することのリスクを過小評価していた。
その後、自宅のミニタワーサーバーにマスターをVMとして構築し直したことでしばらくは安定したが、サービスのさらなる追加で再び不安定化の兆候が現れ始めた。
2026年:Proxmoxによる仮想化・lsyncdによるストレージ冗長化・多重防衛の完成
ミニタワーサーバーをもう1台追加し、両サーバーにProxmoxを導入した。これには以下の狙いがある。
-
マスターノードの保護
- マスターノードをProxmox上のVMとして稼働させ、定期バックアップを取得する。
- 2台のProxmoxホスト間でマスターVMをフェイルオーバーできるようにした。
- 非常時でも片系のx86_64サーバーとRaspberry Piノードだけでクラスタを維持できる体制となった。
-
ワーカーノードの安定化
- x86_64サーバーをProxmox上でVM化したことで、ワーカーノードにあらかじめメモリ上限を設定できるようになった。メモリリーク等が発生しても、Proxmoxホストから遠隔かつ他のVMに影響を与えず再起動等の措置が可能となった。
また副次的ではあるが、ProxmoxによりKubernetes以外の目的でVMを簡単に構築できるようになり、FreeBSDによるIoT機器向けWi-Fi APの構築など、気軽に使い捨て環境での学習が可能となった。
また、2台目のサーバー追加により、RAID1ローカルに保存していたデータをlsyncdで2台間リアルタイムに近い形で同期し、アクティブスタンバイ構成を実現した。1台が故障してもデータを保持したままもう1台へ切り替えられる体制となった。
これらの改善を通じ、Kubernetesの再現性という恩恵を受けられるようになった。マスターノードさえ健全であれば、ワーカーノードの復旧は容易で既存のPodを再稼働させられる。PCの買い替え時でも同じ構成を高い再現性で復元できる点は、個人運用でも大きな価値があると考える。
壊しながら覚える 〜ホームラボで積んだ運用経験〜
業務システムであれば慎重にならざるを得ない技術も、ホームラボであれば積極的に試せる。以下はその具体例である。
CloudNativePGとPVC障害の手動復旧
リソース不足等でCloudNativePGの自動復旧が失敗するケースに直面した。この場合、PVCを手動で削除してPodを再作成する必要がある。DBクラスタの自動フェイルオーバーは複雑な状態遷移を伴う。自動化の裏側にある挙動を手を動かして理解できたことは大きな収穫である。
PostgreSQLパラメーターチューニング
多数のサービスが単一のCloudNativePGクラスタへ接続する構成上、コネクション数の上限やワークメモリ量といったパラメーターチューニングは避けられない課題であった。接続数が上限に達してサービスがエラーを返す事象を経験しながら、max_connectionsやwork_memの調整を繰り返した。
pgpoolによる読み取り負荷分散への挑戦
さらに踏み込んで、pgpoolをクラスタ前段に配置し読み取りクエリをレプリカへ分散させる構成にも挑戦した。設定の複雑さやフェイルオーバー時の挙動確認など、一筋縄ではいかない部分も多いが、コネクションプーリングと負荷分散の仕組みを実運用の中で体得できた。
ノード連鎖障害の経験
あるノードの停止をきっかけに、そのノードで動いていたPodが別ノードへ退避し、そこで負荷集中が起きて別のPodまで巻き込んで落ちる——という連鎖障害を経験した。各PodへのCPU/Memリソース定義の重要性を痛感した出来事であった。本来であればPodのリソースリクエスト・リミットを適切に設定することでスケジューラーが適切にPodを配置し、こうした連鎖を防げる。
ストレージの可用性とパフォーマンスのバランス
先述の通り、可用性を重視してNFSストレージを使うとPodのレスポンスが悪くなり、一方でローカルストレージを使うとそのストレージを持つノードでしかPodを起動できなくなってしまう。ローカルストレージについては、冗長化が個別に必要であり、RAIDを適切に運用する必要がある。これらの点を総合してストレージを決定する必要があった。
セキュリティ対策と誤検知調整
ここでは詳しく取り上げないが、基本的なセキュリティ対策をさまざまなレイヤーで施しつつ、誤検知でアクセスできなくなってしまった場合はルールを見直す、と言ったサイクルも回していた。
今後の課題
以下の課題については、現時点でも完全には解消しておらず、今後の学習テーマになる。
| 課題 | 概要 |
|---|---|
| DB自動復旧の安定化 | CloudNativePGがリソース不足時に自動復旧に失敗するケースが残る。PVC削除→Pod再作成の手動オペレーションを自動化したい |
| K8sリソース構成のバックアップ | マスター消滅時にDeployment・Ingressがすべて失われる構造は未解決。低リソース環境でも現実的なバックアップ戦略の確立が必要 |
| Podリソース定義の整備 | CPU/Memの上限未設定により連鎖障害が稀に発生する。全Podへの厳密なリソース設計の実装が必要 |
まとめ・所感
おうちKubernetesの3年間は、まさに盆栽を育てるような営みであった。理想の形を追い求め、日々手を入れ、失敗を繰り返す過程で、インフラ・セキュリティ・ネットワーク・DBの知識が自然と身についた。
業務では採用しにくい技術を個人環境で積極的に試せることがホームラボの最大の価値だと感じている。RAID崩壊、マスター消滅、NFSボトルネック、連鎖障害、DBチューニング——これらは教科書には書いてあっても、実際に手を動かして失敗しなければ本当には理解できない類の経験である。オンプレであれクラウドであれ、システムを安定させるための勘どころは同じである。その勘どころを、壊しても許される環境で積めることがホームラボの醍醐味である。
クラウドかオンプレかという二項対立ではなく、データ主権・セキュリティ・コスト・利便性を見極めながら両者の強みを組み合わせるハイブリッドな発想が重要であると、小さなホームラボを通じて実感している。この感覚は規模こそ違えど、組織におけるハイブリッドクラウド戦略に直結する問いでもある。