Section1:TensorFlowの実装演習
『
問:以下の問いに記号で答えよ。
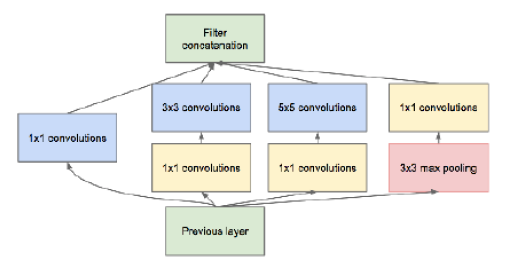
画像認識に用いられるCNNのアーキテクチャにはいくつか有名なものがある。その中の一つとしてGoogleNetと呼ばれるアーキテクチャがある。GoogLenetの特徴としてInception moduleと呼ばれる複数のフィルタ群により構成されたブロックがあげられる。以下の中でinception moduleに関する記述として誤っているものを一つ選べ。
(a) Inception moduleは通常のKKの畳み込みフィルタと比較すると非零のパラメータが増えているとみなせるため、相対的にdenseな演算であると言える。
(b) Inception moduleは大きな畳み込みフィルタを小さな畳み込みフィルタでグループで近似することで、モデルの表現力とパラメータ数のトレードオフを改善していると言える。
(c) Inception moduleには11の畳み込みフィルタが使われているが、このフィルタは次元削減と等価な効果がある。
(d) Inception moduleは小さなネットワークを1つのモジュールとして定義し、モジュールの積み重ねでネットワークを構築する。
』
→
回答例:
(a)
【考察】
GoogLeNetは、Inceptionモジュールの積み重ねで構成されたネットワーク。
→(d) GoogLeNetは、小さいinception moduleというmoduleを定義していて、この積み重ねで出来ているので、まずこれは定義通りなので、正解。
Inception:問いの画像で示しているように、小さいネットワークを1つのモジュールに定義する。
通常CNNでは人間フィルタサイズを定義して畳み込みを行うが、inception moduleについては、複数のフィルタを使う事で畳み込みを行うところが特徴。
これによって、伝統的なCNNよりも表現力が改善されたと言われている。
→(b)複数のフィルタによる畳み込みによって、パラメータ数を減らしながら表現力を改善していくというところで、これは正解。
さらに1x1のフィルタの畳み込みを行うため、複数チャンネルをまとめる事が出来て、次元削減につながり、パラメータ数を減らしながら、同様な精度を生かせるような仕組みになっている。
→(c)は、この通りの意味になるので、これも正解。
(a) denseな演算というところで、必要なパラメータ数は増えるが、非零のパラメータは増えていない(スパースな演算になる)。よって、これは間違い。
『
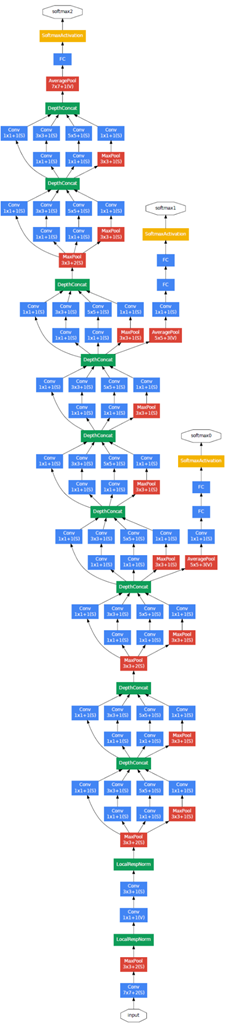
またもう一つのGoogLeNetの特徴としてAuxiliary Lossの存在が挙げられる。以下の中で、Auxiliary Lossに関する記述として間違っているものを一つ選べ。
(a) Auxiliary Lossを導入する事で、多層なネットワークでも計算量を抑える効果が期待出来る。
(b) GoogLeNetの学習ではネットワークの途中から分岐させたサブネットワークにおいてもクラス分類を行っている。
(c) Auxiliary Lossを導入しない場合でも、BatchNormalizationを加えることにより、同様に学習がうまく進む事がある。
(d) Auxiliary Lossによってアンサンブル学習と同様の効果が得られるため、汎化性能の向上が期待出来る。
』
→
回答例:
(a)
【考察】
GoogLeNetの構造図を見て分かるように、ネットワークの途中から分岐させた部分でクラス分類を行っている(最後でもクラス分類を行うが、途中でもクラス分類を行う)。
→(b) 正解。
BatchNormalizationというのは、勾配消失問題の対策の1つで、Auxiliary classifiersを追加しなくても、勾配消失問題を改善出来る。
→(c) 正解。
アンサンブル学習とは、複数の学習器に個別に学習させて、それらの予測結果を統合して汎化性能を高める手法。
GoogLeNetでは、Auxiliary classifiersを導入する事で、複数の学習器としてみなす事が出来て、汎化性能を高める事が期待出来る。
→(d) 正解。
1x1のフィルタの畳み込みを行う事で、次元削減を行っているため、計算量を抑える事は出来るが、Auxiliary classifiersの追加によって、計算量を抑えている訳ではない。
→(a) 間違い。
『
問:以下の空欄に入る選択肢を記号で答えよ。
Residual Network(ResNet)は、2015年のImageNetコンペティションとCOCOセグメンテーション内の主要なコンペティション5つ全てにおいて、2位以下を大きく引き離した最良モデルであり、深層学習に飛躍的な進展をもたらした。
ImageNetの分類タスクコンペティションにおいて、ResNetが登場する以前からニューラルネットワークは他手法を圧倒する性能を出していた。ResNetがそれ以前のモデルと顕著に異なる点は、層の深さである。
2012年に登場したAlexNetは8層、2014年に登場したVGG、GoogLeNetは、各々19、22層の深さを持つが、ResNetは152層の深さを持つ。
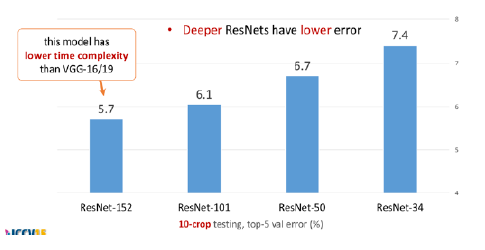
一般に、深層学習においてモデルを深く設計することはモデルの表現力を効率的に向上出来ると知られている。
しかし、ResNetの登場以前は(あ)問題によって、深いモデルを学習する事が出来なかった。
単純に層を積んだ深いモデルは、より浅いモデルと比べて、訓練誤差が大きくなる傾向がある。
ResNetはこの問題に取り組み、より深いモデルがより高い性能を発揮するように改善を行った。
(a) 勾配消失 (b) 非収束 (c) 過剰適合 (d) ノーフリーランチ
ResNetでは層をまたがる結合として(い)mappingを用いる。そうする事で、スキップコネクションの内側の層は、ブロックの入出力の残差学習をするという事になる。
(a) Identity (b) Residual (c) Recurrent (d) Convolution
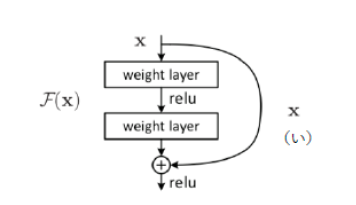
Resudual Blockの導入によって、(う)ことが期待される。この手法により、従来の層を深くすると学習出来ないという問題が解決された。
(a) ブロックへの入力にこれ以上の変換がない場合は、重みが0となり、小さな変換が求められる場合は対応する小さな変動をより見つけやすくなる
(b) ブロックの出力ごとに教師データを用意して誤差逆伝播を行うため、勾配消失問題を低減する
(c) ブロックへの入出力の差分が小さくなるように学習が行われ、勾配消失問題が低減する
(d) モデルパラメータを大幅に減らす事が出来、効率的な学習が出来るようになる
』
→
回答例:
(あ):(a)
(い):(a)
(う):(a)
【考察】
(あ) 例えば、活性化関数にシグモイド関数を使った場合、最大の勾配でも0.25なので、掛け続けると値はゼロに近づいて勾配がなくなってしまう。
連鎖律では、微分の掛け算を行うが、層が深くなるにつれ、0~1の値を掛け続けると、勾配がほとんどなくなっていく事になる。
(い) Identity mapping:スキップコネクションのこと。スキップするので、スキップした間は恒等写像になっている。
上の図にあるように、入力が入ってきた時に、Conv->ReLU->Conv->ReLUと言うのを通して出力されたものと、スキップされたIdentity mappingの値を足し合わせるIdentityBlockという接続がある。
この接続がある事により、上手く残差を学習する事が出来、勾配消失問題を解決する事が出来た。
(う) 仮に追加の層で変換が不要でも、重みを0にすれば良いことになる。
小さな変換がある場合は、重みの部分で少し小さい重みの変動を行う事で、IdentityMappingと足し合わせた時に、元の値から少し変化をした値を学習出来るようになっている。
これらの工夫により、層を深くした場合でも、学習が問題なく出来るようになった。
『
問:次の選択肢の中から誤ったものを1つ選べ。
(あ) 転移学習の極端な形式として、ワンショット学習がある。ワンショット学習は、転移前のタスクで表現学習を行い、その表現を利用する事で転移先のタスクを実行する。この時、転移先のタスクにおいてはラベル付き事例が与えられていない。
(い) 転移学習やドメイン適用とは、あるタスクで学習した事を別のタスクにおける汎化性能向上に役立てる事である。
(う) 機械学習システムがうまく動作しない場合、それがアルゴリズム自体の問題か、実装にバグがあるのかを判断する事は難しい。デバッグの際には、定量的な評価値を見るだけでなく、モデルから出力される画像・音声の可視化・可聴化が大切である。
(え) 表現学習における理想的な表現の仮説の1つに、その表現の中の特徴量が観測データの潜在的原因に対応している事が挙げられる。人の顔画像の表現学習というタスクに対し、最小二乗誤差基準の自己符号化器を用いると耳の生成が疎かになる。顔を表す耳と言う潜在的原因を捉えられていないと考えられる。このような問題に対するアプローチは敵対的生成ネットワークを用いる事である。
』
→
回答例:
(あ)
【考察】
(あ)ワンショット学習とは、画像をあるクラスに対して1枚用意した時に、その画像の特徴ベクトルを抽出する。
その抽出した特徴ベクトルが、同じクラスであれば、近い。違うクラスであれば離れている。というような学習を行う事によって学習を行う方法。
そもそも転移学習ではないので、これは間違い。
(い)転移学習とは、あるタスクで学習したことを、別のタスクに転用して汎化性能を向上する手法の事を言うので、これは正解になる。
(う)デバッグに関しては、実際にバグがあるかどうかを判断する事は難しい。例えば、精度は高くても、誤った学習をしている事はあるので、実際に出力される画像や音声を可視化して、本当に正しく分類されているのかを確認する事は大切なので、これは正解になる。
(え)表現学習における表現の仮説。生成については、確かに顔画像の生成において、耳が大きくなったりする事はある。
この問題に対するアプローチとして、敵対的ネットワークGANが作られた。
実際にGANを使う事によって、こういった上手く生成出来ない部分を生成しながら、ある程度は実際に生成するgeneratorと、その生成したものと、元からある画像の分類を行うdiscriminatorを騙しながら、generatorが生成する事で、問いの(え)にあるような表現がなかった場合、discriminatorの方は、生成された画像だと簡単に分かってしまうので、そういったところを騙すために、このような生成が上手く出来るようになった。つまり、これは正しい。
『
一般物体検知アルゴリズムのその他のアルゴリズムについて以下に述べた4つの記述内から正しいものを選べ。
(a) YOLOと呼ばれるネットワークアーキテクチャは検出速度は高速だが、画像内のオブジェクト同士が複数重なっている場合に、上手く検出できないという欠点がある。
(b) YOLOでは画像をある固定長で分割したセル毎に最大2つの候補領域が推定される。
(c) Single Shot Multi Box Detectorと呼ばれるネットワークモデルの誤差は、オブジェクト領域の位置特定誤差と各クラスの確信度に対する確信度誤差の2つの誤差の単純和で表現される。
(d) YOLOでは画像をある固定長で分解したセル毎にそれぞれどのカテゴリの物体なのかもしくはただの背景なのか、のそれぞれの確率が出力される。
』
→
回答例:
(a)
【考察】
(a) YOLOというネットワークは、検出速度は高速だが、シンプルなネットワークになった分、画像内のオブジェクト同士が複数重なりあっている場合に、検出出来ない。という特徴がある。つまりこれは正しい。
(b) YOLOでは画像をある固定長で分割したセル毎に、必ず定義された2つの候補領域は生成される。そのため、「最大2つの候補領域」というところが間違っている。
(c) Single Shot Multi Box Detectorと呼ばれるネットワークモデルの誤差は、オブジェクト領域の位置特定誤差と各クラスの確信度に対する2つの誤差の重みづけまで表現されている。そのため「2つの誤差の単純和」というところが間違っている。
(d) YOLOではオブジェクトの検出とクラス分類を行う。カテゴリの物体なのかと、背景なのかについては、それぞれの確率が出力されるわけではない。よってこれは間違い。
『
VGG-GoogLeNet-ResNetの特徴を
それぞれ簡潔に述べよ。
(3分)
』
→
回答例:
VGG:この中で最も古くて、2014年のモデル。特徴としては、conv->conv->max poolingというような単純なネットワークの積み重ねによって出来ている。ネットワークの構成はすごくシンプルなものになっている。
一方、パラメータ数は、他のGoogLeNetやResNetに比べて多いというのが特徴。
GoogLeNet:inception moduleを使っているのが特徴。中でも1x1の畳み込みを使った次元削減や、様々なフィルタサイズを使う事によるスパースなものというのが特徴になっている。
ResNet: スキップコネクションIndentity moduleを使う事によって、残差接続を行い、それによって深い学習が行えるという事が特徴。
【考察】
VGG:通常のCNNと同じ構成で、conv->pooling->..->affineという構造、VGG16だと全部で16層。VGG19だと全部で19層ある。
GoogLeNet:Inception moduleと呼ばれる複数のフィルタ群により構成されたブロックがある。ネットワークを途中で分岐させて、途中でもクラス分類を行っている。最後でもクラス分類は行う。
ResNet:層数が152層と圧倒的に多いNN。IndentityMapping(スキップコネクション)により、深い層でも勾配消失問題に対応出来ている。
Section2:強化学習
『
強化学習に応用出来そうな事例を考え
環境・エージェント・行動・報酬を具体的に挙げよ。
』
→
回答例:
ファミコンゲーム(点数が付くアクションゲーム)
環境:現在のゲーム画面
エージェント:上下左右、ABボタンを押す事が出来るソフト
行動:タイミングをみて、何らかのボタンを押す。
報酬:ゲームのスコア
【考察】
何らかの行動をとる事で、結果(短期的だけではなく、長期的にでも)、報酬が分かるものであれば、色々なものが考えられそう。迷路の脱出タスクなども強化学習で考える事も出来る。
行動をとる事は出来るが、その結果、報酬が分からなければ、学習が出来ない。
『
問:以下に当てはまるものを記号で答えよ。
強化学習の基本的なアルゴリズムのうちの1つとして、ベルマン方程式に従って行動価値関数Q(s, a)をモデル化する価値反復に基づく方法が挙げられる。しかしこの方法では行動aが連続的な値を取るような場合を自然に扱えないといった欠点がある。
そうした問題に対する対応方法として、方策自体をパラメータθを用いてπθ(a|s)のようにモデル化した方策勾配に基づくアルゴリズムが挙げられる。方策勾配に基づくアルゴリズムにおいては、方策勾配の定理により目的関数J(θ)=V(s0)のθに関する勾配∇θJ(θ)を以下のように計算出来る。
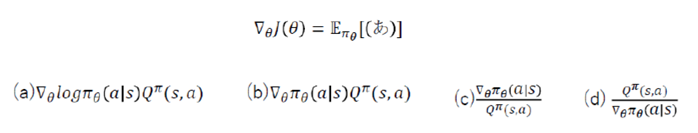
こうして計算された勾配を用いて勾配法により、方策πθ(a|s)をアップデートするのが、方策勾配に基づくアルゴリズムである。
』
→
回答例:
(a)
【考察】
方策勾配定理は、基本的には下記の2式から導出される:
状態価値関数 v(s) = sum_a ( π( a|s)Q(s,a))
ベルマン方程式 Q(s,a) = sum_s’(P(s’|s,a)[r(s,a,s’) + γ V(s’)]
勾配を求める際は、対数微分法を用いて、勾配を求める。
対数微分法:式の両辺にlogを取ってから微分を行う方法。