はじめに
将棋の棋譜ファイル(csaという形式のファイルです)を入力すると、棋譜の評価値を計算、可視化してくれる簡単なアプリをGCP上で作りました。
まだまだモデルの精度が良くなかったり、何故か可視化にmatplotlibを使っていてインタラクティブなグラフになっていなかったり、という問題はあるものの、一旦形になったので、どんな感じで実装したかを話せればと思います。
この記事でわかること
- streamlitでアプリを作る方法
- vertex AIでカスタムモデルをサービングする方法
dhirookaさんの記事とgoogle cloud japanの方の記事に大変お世話になりました。
この記事でわからないこと
- 将棋について
- 殆ど将棋の話は出てこないので特に説明も入れていないです。2人で行うボードゲームということさえ理解していれば問題ないです。
- 将棋AIについて
- 盤面評価を行うDNNについて
- 学習で参考にさせていただいたコードはこちらの書籍に載っているものです。 強い将棋ソフトの創りかた|マイナビブックス
コードは以下に配置しました
https://github.com/TatsuyaSSK/shogi-ai
全体像
アプリの全体像は以下の通りです。
前提として、このアプリはGCP上に作られており、↑の動画のような見た目を作っているのがGCE(google compute engine)上に立てたstreamlitのサーバーで、評価値の予測を行うサービング環境をVertex AIで構築しています。
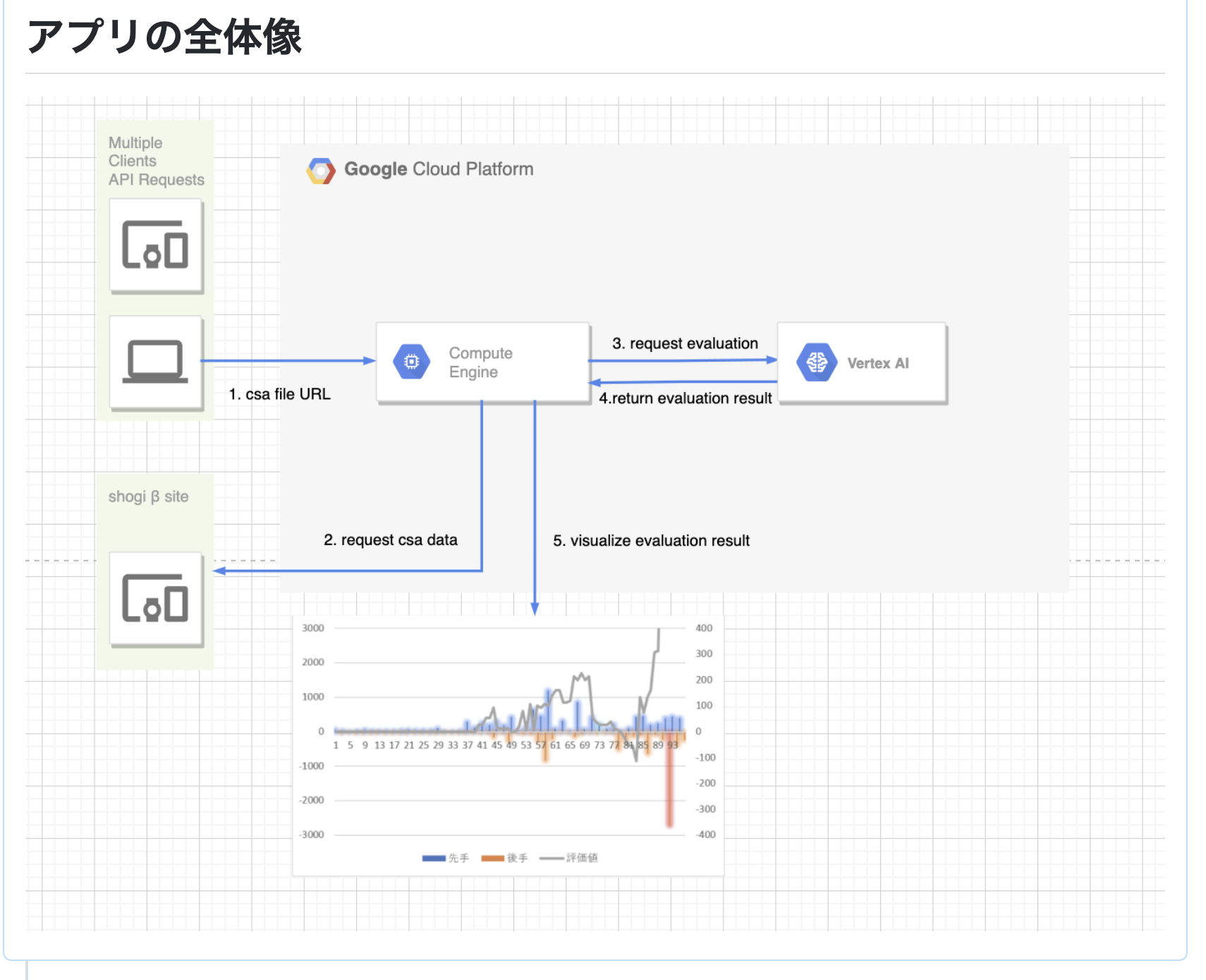
アプリの処理の流れは以下の通りです。
- csaという形式の棋譜が格納されたファイルのパスをstreamlitのテキスト入力欄に入力
- csaのファイルの中身は以下のような感じで、先手、後手ごとに、どこに何を打ったかが一行づつ格納されています。これによって局面を再現できるので、各局面ごとの評価値を出すのに使用できます
'Shogi Quest
N+tonnkotu(1713)
N-kyuubou1(1802)
P1-KY-KE-GI-KI-OU-KI-GI-KE-KY
P2 * -HI * * * * * -KA *
P3-FU-FU-FU-FU-FU-FU-FU-FU-FU
P4 * * * * * * * * *
P5 * * * * * * * * *
P6 * * * * * * * * *
P7+FU+FU+FU+FU+FU+FU+FU+FU+FU
P8 * +KA * * * * * +HI *
P9+KY+KE+GI+KI+OU+KI+GI+KE+KY
+
+2726FU
-3334FU
+3948GI
-8384FU
+7968GI
-8485FU
+6978KI
-7162GI
+5969OU
-8586FU
+8786FU
-8286HI
+0087FU
-8682HI
+9796FU
-9394FU
+4746FU
-5142OU
+4847GI
-3132GI
+3736FU
-6364FU
- 「評価値を計算する」ボタンを押すと、入力されたファイルパスにしたがって、csaファイルを取得し、GCS(google cloud storage)に保存
- 将棋の棋譜は将棋クエスト履歴検索βというサイトから取得しています。ここには将棋クエストという将棋アプリの棋譜が保存されています。
- vertex AIで用意したエンドポイントに、GCS上に格納したcsaファイルのパスを渡す
- vertex AIでは、ある棋譜の評価値をリストで返す
- 値は0 ~ 1までで、局面の数によってリストの長さが決まります(100手目まである棋譜なら、100個の値のリストを返します)
- streamlitで評価結果を可視化
streamlitとvertex AIがこのアプリで中心的な役割を果たしているので、大きくこの二つに分けて、もう少し詳細を説明していきます。
Streamlit側でやっていること
コードは上記リポジトリ内のappディレクトリのshogi.pyがメインのファイルとなります。
import streamlit as st
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import os
from utils import check_input_text, get_player_names
from get_kif_file import CsaFetcher
from vertex_ai import evaluate
st.title("将棋アプリ解析君")
text = st.text_input("csaファイルのURLを入力してください")
submit_button = st.button(label="評価値を計算する")
if submit_button:
csa_file_url = check_input_text(text)
csa_file_name = os.path.basename(csa_file_url)
bucket_name = "sasaki-sample"
csa_fetcher = CsaFetcher(bucket=bucket_name)
csa_fetcher.fetch_csa_file(url=csa_file_url, upload_dir_path="")
gcs_csa_file_path = f"gs://{bucket_name}/{csa_file_name}"
evaluate_values = evaluate(gcs_csa_file_path)
first_player_name, second_player_name = get_player_names(csa_file_url)
# 描画
fig, ax = plt.subplots(figsize=(12, 5))
x = list(range(1, len(evaluate_values) + 1))
ax.plot(x, evaluate_values)
index = np.arange(0, len(evaluate_values) + 1, step=10).tolist()
x_label = [f"{num}手目" for num in index]
ax.set_xticks(index)
ax.set_xticklabels(x_label)
ax.axhline(y=0.5, lw=0.3, color="red")
ax.set_title(f"先手:{first_player_name} 後手:{second_player_name}")
plt.tight_layout()
st.pyplot(fig)
streamlitでは、st.xxxxx と書くことで簡単に様々なwidgetを表示することができます。
今回はst.title, st.text_input, st.buttonの3つを使っています。st.title(“xxxxx“)と書くと簡単にタイトルが表示されたりして楽ですね。
st.buttonでボタンを作っておいて、ボタンが押されたらif文以下の処理が走ります。(この書き方が良いのかは自信ありません、有識者の方に教えていただきたいです)
やっていることは、
- csaファイルの取得、GCSへの格納
- vertex AIに予測を投げる
- 可視化
となります。
vertex AIに予測を投げるところはvertex_ai.pyでやっています
from google.cloud import aiplatform
import streamlit as st
PROJECT_ID = "kif-kaiseki-kun-project"
LOCATION = "asia-northeast1"
ENDPOINT_ID = "7618190613418082304"
def evaluate(csa_file_path):
client_options = {"api_endpoint": f"{LOCATION}-aiplatform.googleapis.com"}
client = aiplatform.gapic.PredictionServiceClient(client_options=client_options)
endpoint = client.endpoint_path(
project=PROJECT_ID, location=LOCATION, endpoint=ENDPOINT_ID
)
instances = [{"csa_file_path": csa_file_path}]
response = client.predict(endpoint=endpoint, instances=instances)
evaluate_values_before = response.predictions[0]["evaluate_value"]
evaluate_values = []
for index, evaluate_value in enumerate(evaluate_values_before, 1):
if index % 2 == 0: # 偶数の場合、後手の評価値を1から引いて、全て先手の評価値に直す
first_player_value = 1 - evaluate_value
evaluate_values.append(first_player_value)
else:
evaluate_values.append(evaluate_value)
return evaluate_values
必要なコードとライブラリを用意したら、以下のDockerfileを用意します。これに関しては特に言うことはなく、CMDのところでstreamlitのサーバーを起動しているくらいです。
FROM python:3.7-slim
COPY requirements.txt ./requirements.txt
RUN pip install -r requirements.txt
ENV APP_HOME /app
WORKDIR $APP_HOME
COPY . ./
CMD streamlit run app/shogi.py --server.port 80
Dockerfileが用意できたら、Dockerイメージの作成、作成したイメージのContainer Registry(GCP上のDockerイメージ管理サービス)への登録を行います。
docker build . -t shogi-ai-streamlit
docker tag shogi-ai-streamlit gcr.io/kif-kaiseki-kun-project/shogi-ai-streamlit
docker push gcr.io/kif-kaiseki-kun-project/shogi-ai-streamlit
※ container registryに登録するには、gcloudでDockerが使えるよう以下の認証手順を踏む必要がありますhttps://cloud.google.com/sdk/gcloud/reference/auth/configure-docker
$ gcloud auth login // GCP自体の認証 (Google認証)
$ gcloud auth configure-docker // gcloudでDockerが使えるよう認証
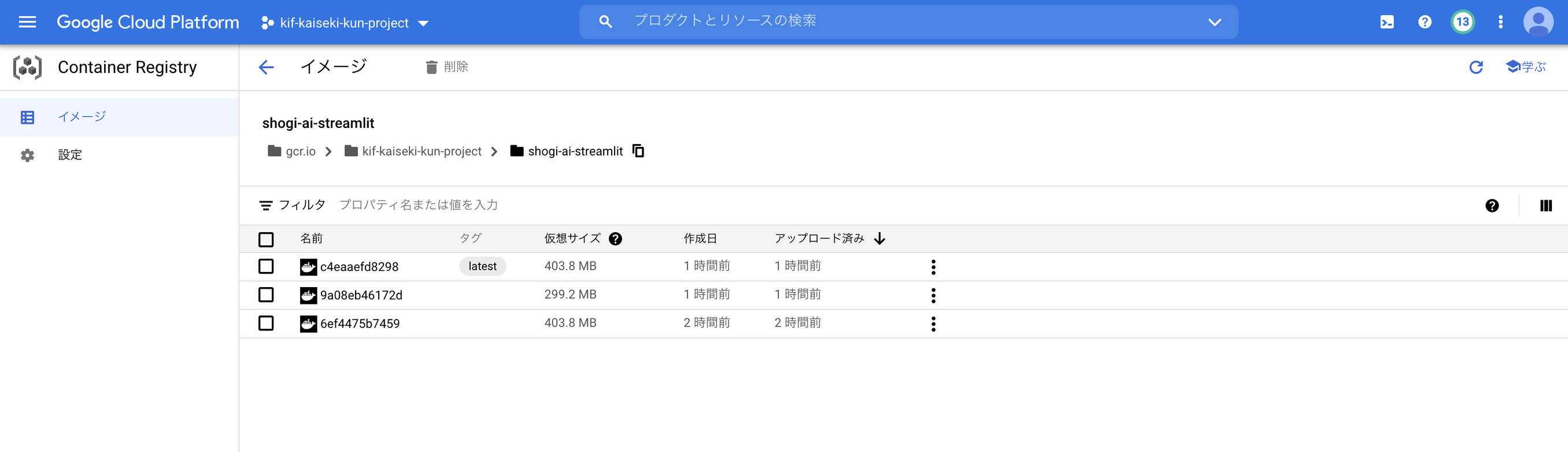
Container Registryを見ると、こんな感じでDockerイメージが登録されていることが確認できるかと思います。
確認ができたら、このコンテナを使ってGCEでインスタンスを立てます。インスタンス作成の欄に「DEPLOY CONTAINER」があるのでここをクリックして、
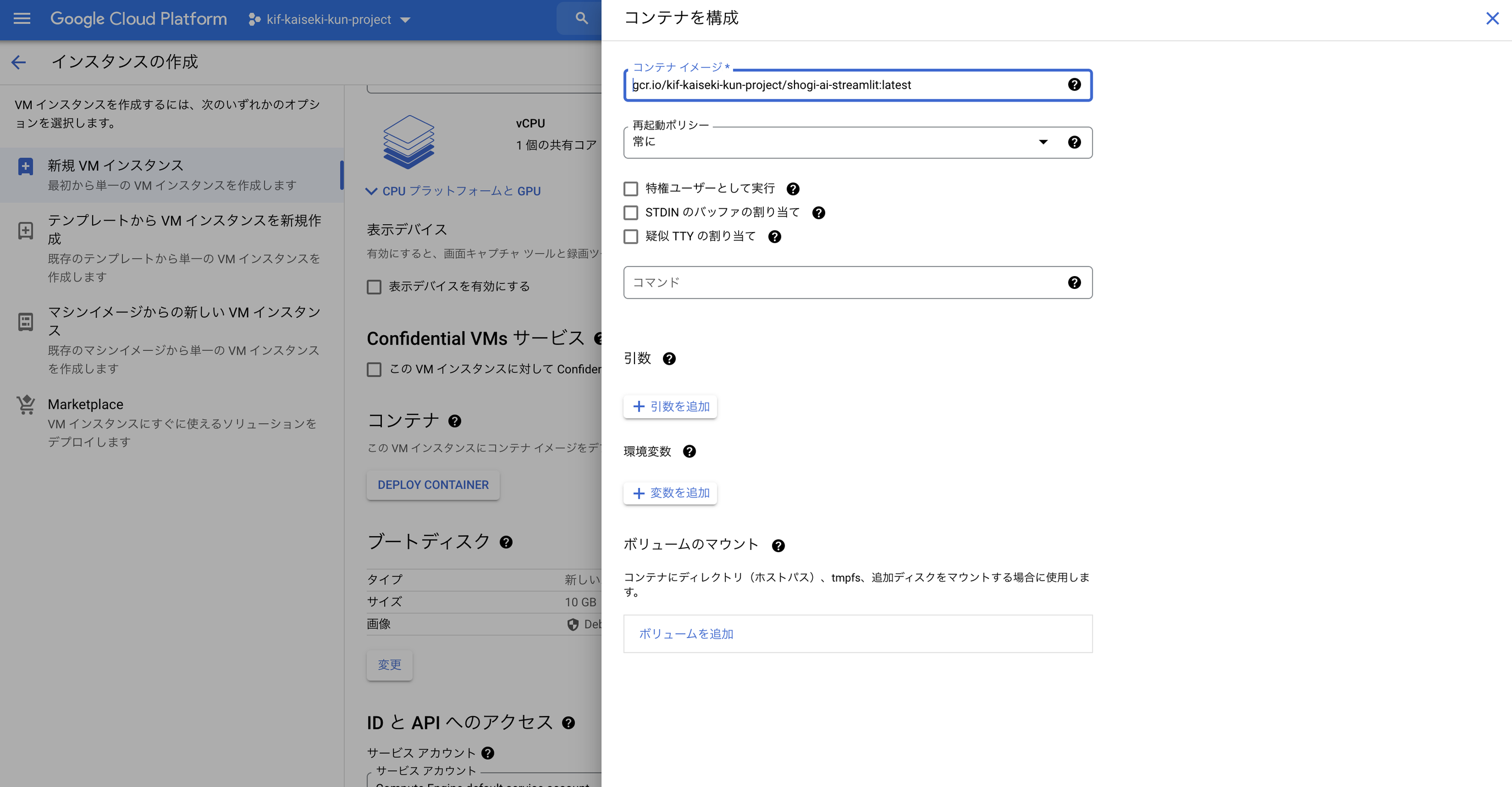
アクセス権とファイアウォールの設定を以下のように行います(アクセススコープは個別に設定してあげる方が不要な権限を付けないので望ましいです。今回はサボりました)
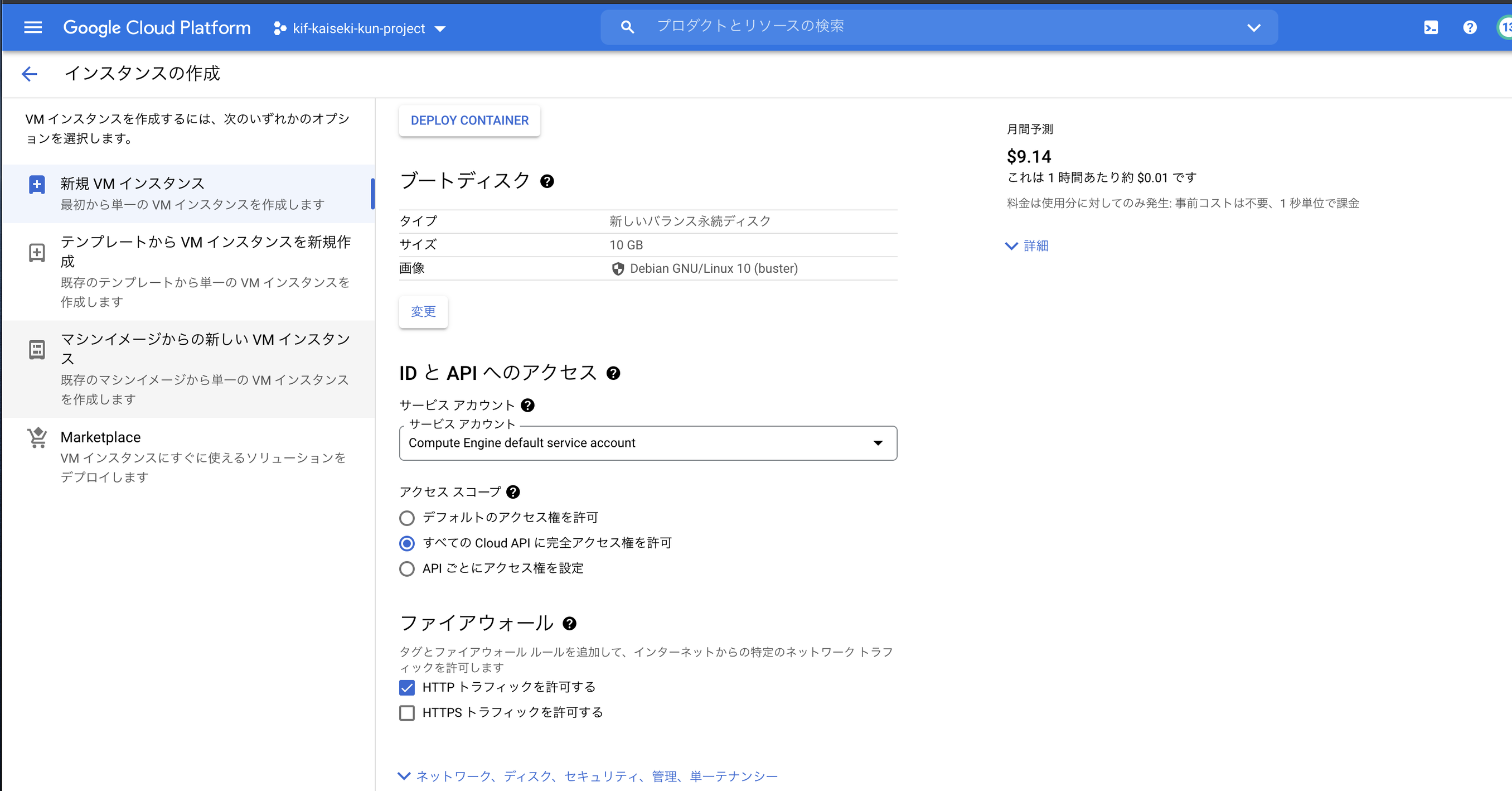
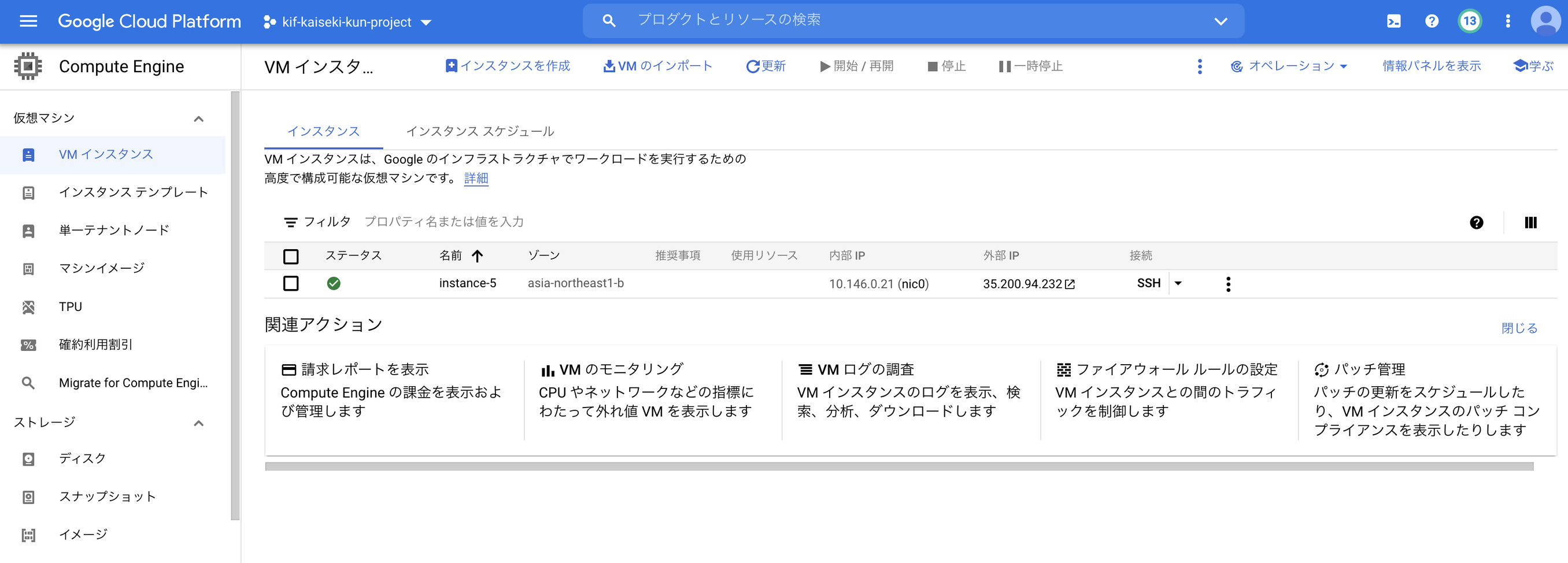
これでインスタンスを作成を押してしばらく待つとインスタンスが立ち上がっています。外部IPからアクセスすれば、streamlitが立ち上がった画面が表示されるかと思います
※ インスタンスが立ち上がってもstreamlitの画面が表示されるまでは何故か数分かかります。気長に待ちましょう(理由が分かれば知りたいです)
Vertex AI側でやっていること
コードは上記リポジトリ内のservingディレクトリのshogi.pyがメインのファイルとなります。
import json
import numpy as np
from google.cloud import storage
from cshogi import CSA, Board
import torch
from features import FEATURES_NUM, make_input_features
from policy_value_resnet import PolicyValueNetwork
from features import (
FEATURES_NUM,
make_input_features,
)
from flask import Flask, request, Response, jsonify
model = PolicyValueNetwork()
device = torch.device("cpu")
model.to(device)
model_weight = torch.load("checkpoints_checkpoint-004.pth", map_location=device)
model.load_state_dict(model_weight["model"])
model.eval()
# ここからflaskの設定
app = Flask(__name__)
# flask route for liveness checks
@app.route("/healthcheck")
def healthcheck():
status_code = Response(status=200)
return status_code
# flask route for predictions
@app.route("/predict", methods=["GET", "POST"])
def predict():
request_json = request.get_json(silent=True, force=True)
data = request_json["instances"]
csa_file_path = data[0]["csa_file_path"]
csa_file_path_splitted = csa_file_path.split(
"/"
) # bucket名とfile名の取得のためfile_pathを分割している gs://bucket_name/file_nameを仮定
bucket_name = csa_file_path_splitted[2]
file_name = csa_file_path_splitted[3]
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blob = storage.Blob(file_name, bucket)
content = blob.download_as_text()
kif = CSA.Parser.parse_str(content)[0]
board = Board()
move_num = len(kif.moves)
# 出力用の配列
torch_features = torch.empty(
(move_num + 1, FEATURES_NUM, 9, 9),
dtype=torch.float32,
device=torch.device(device),
)
# make_input_featuresがnumpyでしか動作しないのでnumpy型に変換
np_features = torch_features.numpy()
# 初期局面の特徴量を生成
make_input_features(board, np_features[0])
# 1手目から終局までの特徴量を生成
for i, move in enumerate(kif.moves):
board.push(move)
make_input_features(board, np_features[i + 1])
_, y = model(torch_features)
# Tensorをnumpyに変換
y = y.to("cpu").detach().numpy().copy()
# 次元を削減
y = np.squeeze(y)
# シグモイドで出力する
result = 1 / (np.exp(-y) + 1)
result = result.tolist() # numpy.ndarrayはjsonでシリアライズできないのでリストに変換
# jsonでdump
return json.dumps({"predictions": [{"evaluate_value": result}]})
if __name__ == "__main__":
app.run(debug=True, host="0.0.0.0", port=8080)
Vertex AIでは、HTTPサーバーを立てて、Vertex AIのREST APIの形式に合わせたリクエストを受け取れるようにする必要があります。HTTPサーバーを立てるために今回はflaskを使っています。
@app.route("/healthcheck")と@app.route("/predict", methods=["GET", "POST"])があるのですが、前者のルートを用意する理由は、Vertex AIでは、HTTPサーバーが正常に起動しているか確かめるため、/healthcheckというルートにリクエストを送ってstatus200が返ってくるか否かをチェックしてくるためです。
後者は予測のためで、streamlitから/predictルートにPOSTリクエストが飛んでくるので、その際に予測を実行します。
ごちゃごちゃ色々やっていますが、やっていることとしてはGCSに格納されたcsaファイルの中身を取ってきて、csaファイルから特徴量を作って学習済みモデルに渡しているだけです。
必要なファイルを作り終わったらこちらもDockerイメージにしてあげて、Container Registryに登録してあげましょう。
Dockerfileは、今回はモデルがpytorchなので、ベースイメージをpytorchにしています
※ pip経由でpytorchをインストールしてDockerイメージをビルドしようとすると失敗してしまっていたのでこのようなやり方を取っています… Vertex AI で AnimeGAN やってみた と全く同じ状態でも試したのですが… 原因不明のままになってしまっています。
FROM pytorch/pytorch:latest
COPY requirements.txt ./requirements.txt
RUN pip install -r requirements.txt
COPY app.py ./app.py
COPY features.py ./features.py
COPY policy_value_resnet.py ./policy_value_resnet.py
COPY checkpoints_checkpoint-004.pth ./checkpoints_checkpoint-004.pth
# Expose port 8080
EXPOSE 8080
ENTRYPOINT ["python3", "app.py"]
docker build . -t shogi-ai
docker tag shogi-ai-streamlit gcr.io/kif-kaiseki-kun-project/shogi-ai
docker push gcr.io/kif-kaiseki-kun-project/shogi-ai
こちらもContainer Registryに登録されていることを確認しておきます
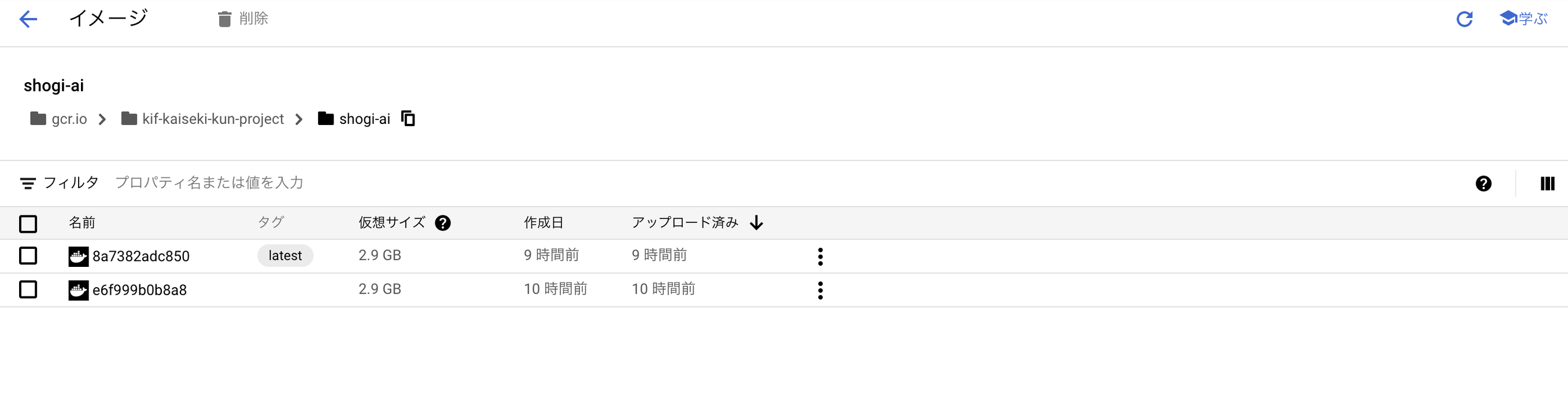
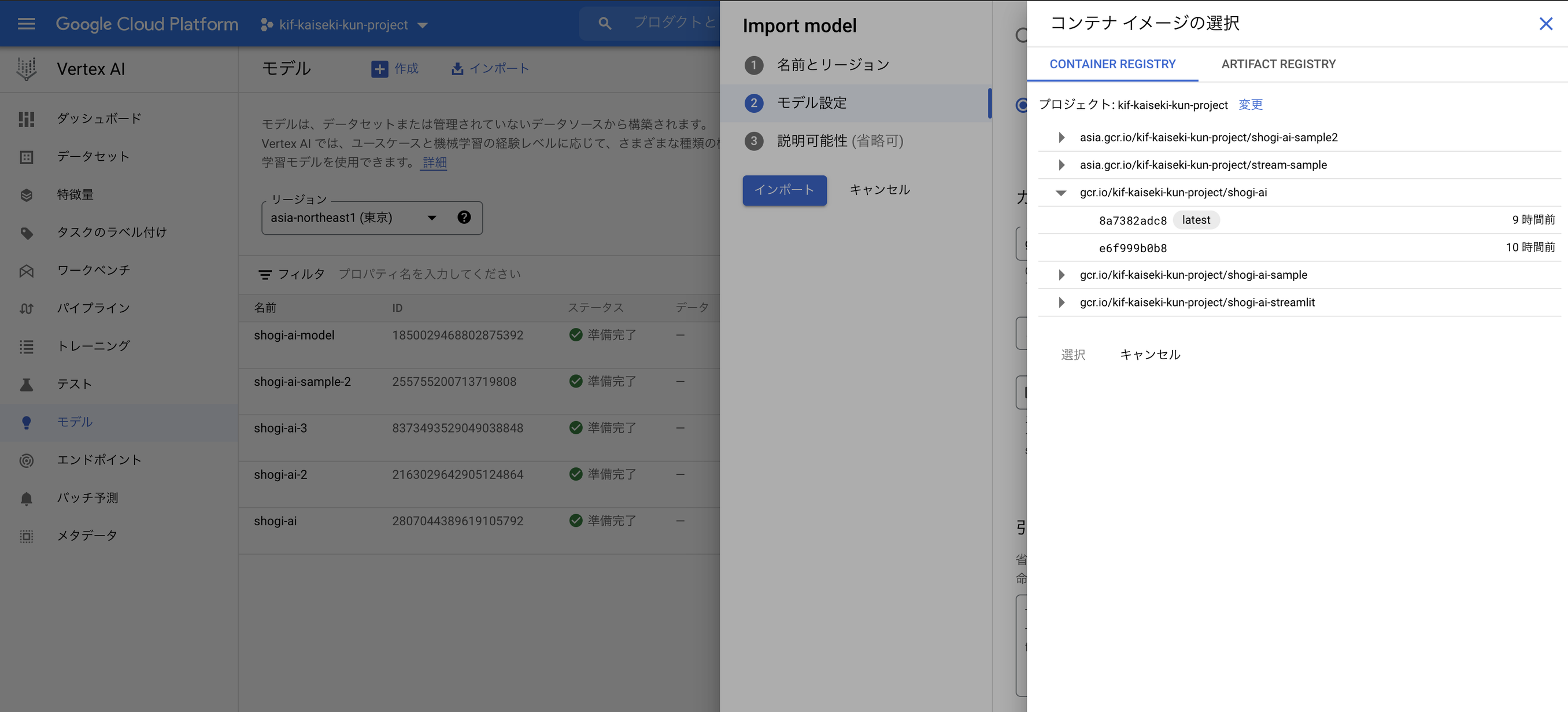
次に、このカスタムコンテナをVertex AIにモデルとして登録します。モデルのインポートから、先ほど作ったカスタムコンテナを登録してあげましょう。
モデルの登録が完了したら、最後にリクエストを送る先となるエンドポイントを用意しなければなりません。エンドポイントのモデルを追加で、先ほど作ったモデルを登録してあげます
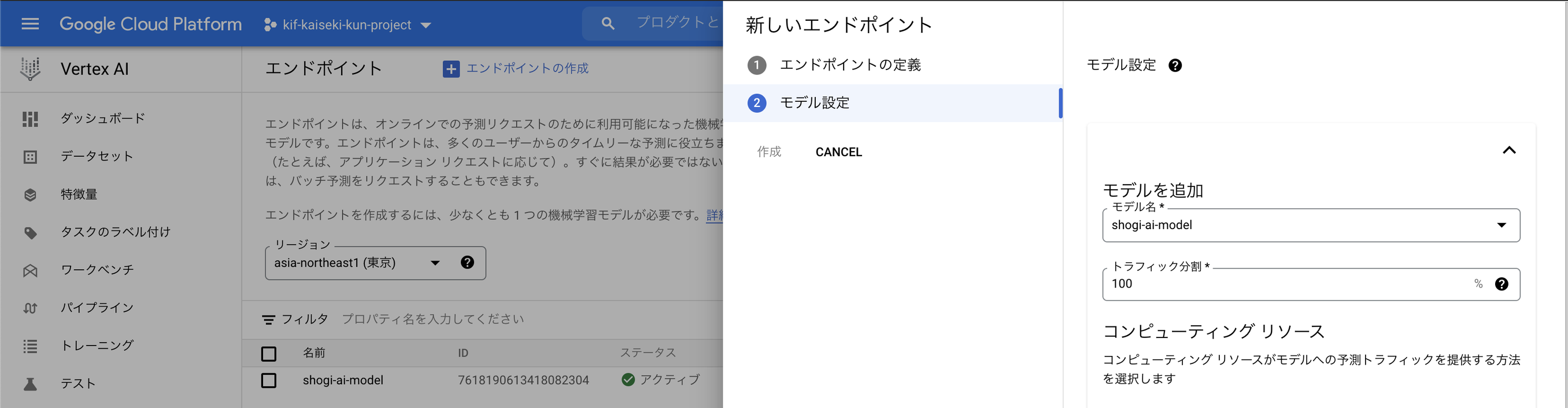
エンドポイントの作成が完了したら終わりです! streamlitからリクエストを投げてみて、うまくいくか試してみてください
おわりに
今回はstreamlitとvertex AIを活用した棋譜解析アプリの概要、作り方について説明しました。「はじめに」で書いたように、まだまだ改善できる部分はあるので、余裕があれば手をつけようかなと考えています。
心残りとしては、今回モデルの学習はvertex pipelineを使っていないので、まだそちらには慣れていないことです。もっとvertex AIの他のサービスにも慣れていきたいので、色々触っていきたいですね。