注意:この文書は荒いメモなので、細かい内容に関してはご自身で元論文に当たってください。
-
論文リンク
-
公式実装:主著者による実装
概要
CNNにAttentionの仕組みを導入して、Fine-grained recognitionを実現する手法。
CNNの各段階(入力層に近い段階から、出力層に近い段階まで)の各段階でAttention機構を導入し、入力層に近い段階ではテクスチャのような情報を、出力層に近い段階では大域的な情報を抽出して、分類に役立てる。
また、各段階で得られた情報のうちどれを重視するのかも、Attention機構によって重みつけして処理している。
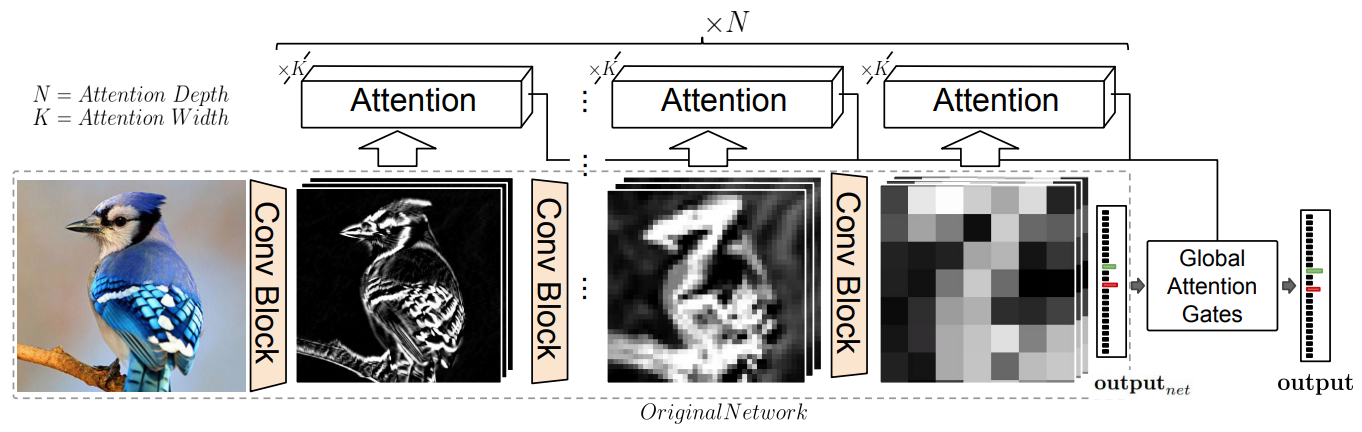
以下の4点が、本手法の利点として挙げられている。
- 全ての段階に適用する処理は同一のものであるため、モジュール化し使いまわせる
- 任意のベースアーキテクチャに適用可能
- ベースアーキテクチャに追加で必要なメモリと計算コストが少ない
- 実装が簡単
手法
本手法では、以下の3つのサブモジュールが、ローカル(CNNの段階)でも、グローバルでも使われる。
- attention head $\mathcal{H}$: 特徴量マップから複数のAttentionマップを作成する
- output head $\mathcal{O}$: 特徴量マップとAttentionマップから、仮説(分類のスコア)を計算
- confidence gates $\mathcal{G}$: 複数のAttentionマップの信頼性を計算して重み付けし、最終的な仮説とする。
いずれのサブモジュールも1層のConv層とAvgPooling、内積計算などからなる単純な計算しか含んでおらず、パラメータ数も多くは無い。
ローカルな仮説の算出
以下にCNNの各段階に対する処理のうちの、1つの段階を示す。
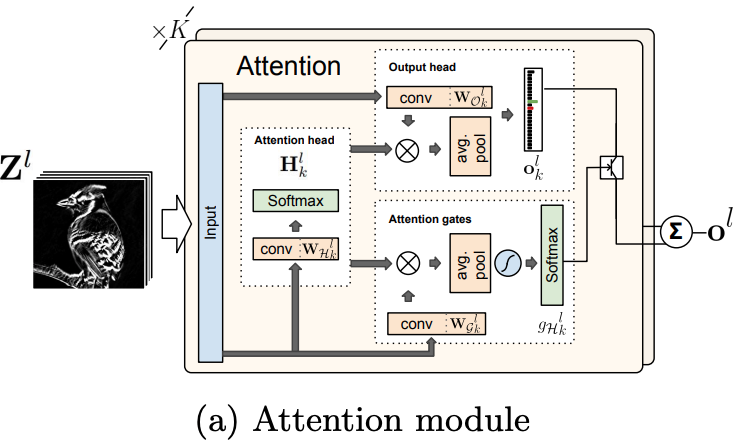
入力されている$Z^l$は、CNNの$l$段階目の特徴量マップという意味である。
- Attention head: 入力された特徴量マップを元に$K$枚のAttentionマップが作成される。
- Output head: 特徴量マップと$K$個のAttentionマップを元に、それぞれのAttentionマップに対応する$K$個の仮説を算出する。この時、AvgPoolingが行われるので、マップの大きさに依存しない出力結果となる。
- Attention gates: 特徴量マップと$K$個のAttentionマップを元に、$K$個のAttentionマップに対する信頼度($K$次元)を計算する。Output headと同様、AvgPoolingによってマップの大きさに非依存の計算となる。
- Output headで得られた $K$個の仮説に対して、Attention gatesで得られた$K$次元の信頼度をかけて足し合わせ、$l$段階目の仮説を得る。
なお、$K$をAttention Width(AW)と呼ぶ。
グローバルな仮説の算出
以下にグローバルな分類スコアの算出を示す。
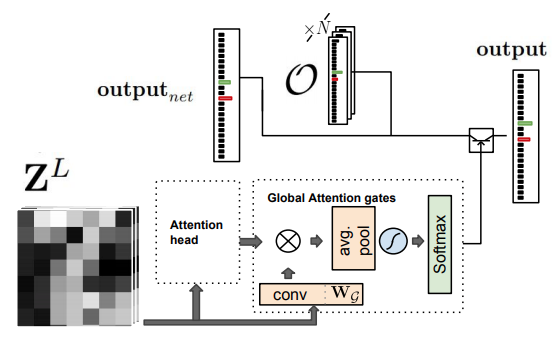
グローバルな仮説の算出も、ローカルな仮説の算出と同様のサブモジュールから成り立っている。
- 入力$Z^L$はCNNの最終層で得られる特徴量マップである。
- output headは存在しないが、代わりに、各段階の仮説とCNNの最後に得られる仮説${output}_{net}$が追加の入力として存在する。
以下に計算手順を示す。
- Attention head: ローカルでは$K$枚のAttentionマップを作成するが、グローバルでは$N+1$枚のAttentionマップを作成する。
- Global Attention gates: $N+1$個のAttentionマップから、それぞれに対応する$N+1$個の信頼度を作成する。
- N個の各段階、およびCNNの最後に得られる仮説の合計$N+1$個の仮説に対して、Global Attention gatesで得られた信頼度による重み付き合計を算出し、最終的な仮説とする。
なお、$N$をAttention Depth(AD)と呼ぶ。
実験
実験では、ベースアーキテクチャとしてWide-ResNetを使用している。
以下にCIFAR-10、CIFAR-100での既存手法との比較を示す。表中の数値はError rateである。なお、訓練はイチから行なっている。
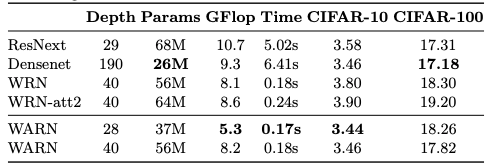
ベースラインとなっているWRN(Wide-ResNet)とほとんど実行速度に違いが無いが、精度はきっちり上がっている。
比較的浅くても(Depth=28)それなりの精度が出ている。
議論
図.6にAttention Maskの可視化が示されているが、AttentionMaskは色々なところで計算しているので、どの部分の可視化なのかが今ひとつわからない。

感想
ちょっと前に読んだものをまとめてみた。