注意:この文書は荒いメモなので、細かい内容に関してはご自身で元論文に当たってください。
- 論文リンク
- PaperWithCodeのFine-Grained Image Classificationで、いくつかのデータセットに対してSOTAとして登録されている。
概要
高精細な画像分類(Fine-Grained Visual Classification; FGVC)は、通常の画像分類のためのネットワークでは分類が難しいような、下位のカテゴリー(車の車種、鳥の種類、犬の犬種など)を分類できるようにするというタスクである。
本論文では、物体の部位(鳥の頭や羽、尻尾など)へのAttentionを利用したFGVC手法であるWS-DAN(Weakly Supervised Data Augmentation Network)を提案している。
以下の3点が本論文のポイントである。
- Weakly Supervised Attention Learning: 画像レベルのラベルのみのよって、部位レベルへのAttentionを学習する。
- Attention Guided Data Augmentation: 部位レベルのAttentionを導きとして、効率的なデータ拡張を行う。
- Look Closer(Localization & Refinement): 物体領域を特定してその部分の高解像度の画像を得るよる分類精度の向上
手法
学習の流れ
以下に学習時の処理の流れを示す。
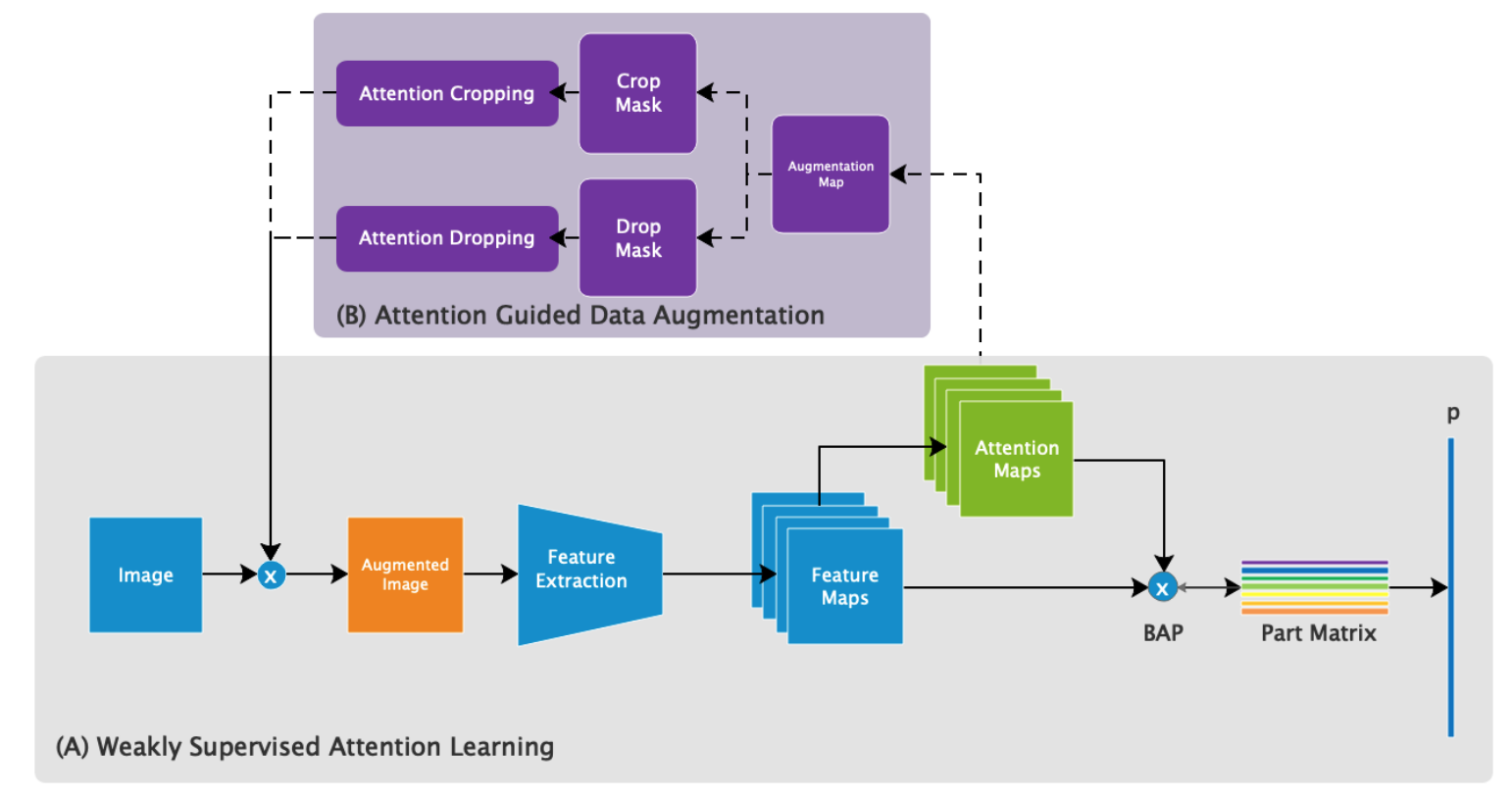
- ImageからFeatureExtractionによってFeatureMapsを得る。
- FeatureMapsからAttentionMapsを得る。
- FeatureMapsとAttentionMapsから、**BilinearAveragePooling(BAP)**によってPartMatrixを得る
- PartMatrixを元に分類の予測を行う。
- AttentionMapsを利用し、Imageに対して**(B)**で計算されるデータ拡張を行う。
- データ拡張済みのImageについて、1~4までの処理を行う。
つまり、特徴量抽出、Attentionの取得、BAP、分類、という流れは、2回行うことになる(図のみではわかりにくい)。
損失は、4と6で得られる分類に対する損失(CrossEntoropy)と、PartMatrix(の各行)に対して定義されるAttention Regularization Lossによって得られる。
BilinearAttentionPoolingとAttention Regularization Lossについては、Weekly Supervised Attention Learningで、**(B)**については、Attention Guided Data Augmentationで説明する。
Weekly Supervised Attention Learning
Bilinear Attention Pooling
FGVCの手法では、物体の部位(part)からdiscriminativeな特徴を抽出することが重要。
本手法では、画像レベルのアノテーションのみで、物体の部位を特定できるよう学習するために、BilinearAttentionPooling(BAP)を提案している。
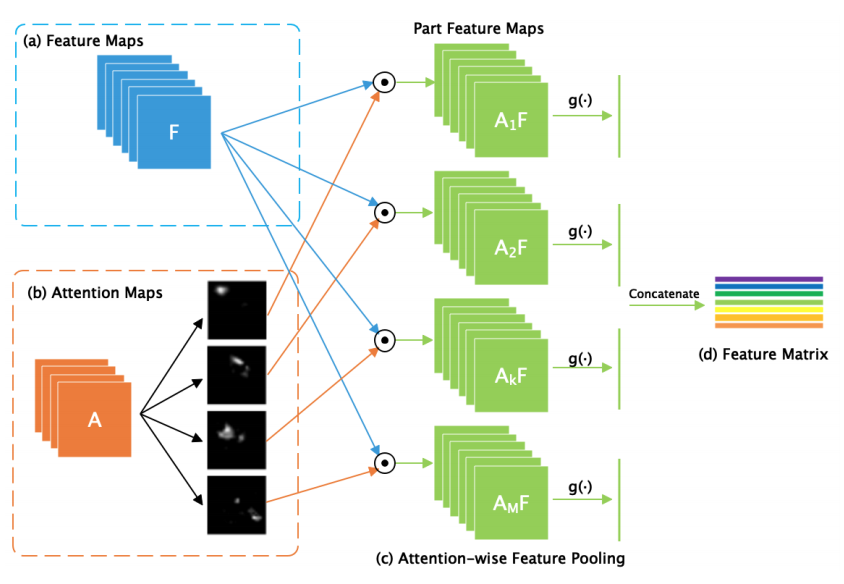
AttentionMapsは、FeatureMapsから関数$f(\cdot)$(実装上は1x1のConvolution)によって得ることができる。それぞれのサイズは、$(M,H,W), (d,H,W)$である。$M$は、AttentionMapsの数、すなわち想定される部位(part)の数に対応している。1枚1枚のAttentionMapは、$A_k (k=1...M)$と表現される。
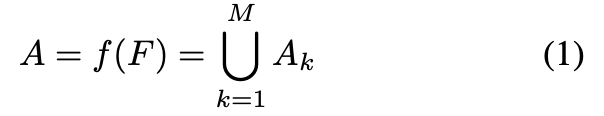
次に、各AttentionMapとFeatureMapsについて、要素積であるPartFeatureMapsを得る(図中の$A_1F$~$A_MF$、下式の$F_k$)。それぞれのサイズは$(d,H,W)$であり、それが$M$個できる。
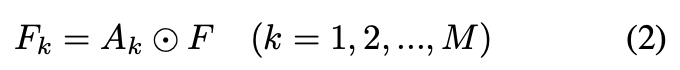
そして、関数$g( \cdot )$によるGlobalPoolingが適用される。$f_k$は$d$次元のベクトルである。

最後に、$f_k (k=1...M)$を結合して最終的なFeatureMatrixが得られる。FeatureMatrixのサイズは$(M,d)$である。
FeatureMatrixから分類を行うのかの記載は見当たらないが、普通に全結合層が繋がる感じだろう。
Attention Regularization Loss
$f_k (k=1...M)$は、同一クラスの画像間ではある程度似通っていてほしい。この正則化によって、クラス内分散を抑えることができる。
そのため、以下のようなAttention Regularization Lossを最小化することで、$f_k$の分散を抑える。
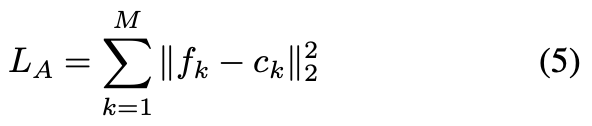
各$c_k$は各クラス、各$k$に用意されており、零ベクトルから出発し、ミニバッチを通じて、以下の式で更新される。

Attention Guided Data Augmentation
通常の画像分類モデルの構築時に適用されるデータ拡張では、ランダムなリサイズやランダムな位置で画像を切り抜く、ということが多い。しかし、この方法は、背景のノイズを多く含む画像がサンプルされてしまうために、学習が非効率になってしまう。
この非効率を回避するためには、物体が含まれている位置情報を考慮する必要がある。
Attention Guided Data Augmentationでは、物体中の各部位へのAttentionを利用し、物体の部位の位置と領域を特定することで、2種類のデータ拡張を実現する。

準備: ランダムにAttentionMapを選択
具体的なデータ拡張の話に入る前に、ランダムにAttentionMapを選択する。これを$A_k$とする。
データ拡張は、この$A_k$を正規化した$A_k^*$をベースに行う。
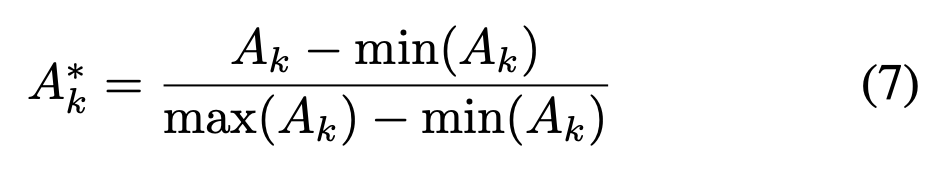
Attention Cropping
$A_k^*$が表す部位の領域にズームするように画像を切り抜き、データ拡張を行う。
具体的には、以下に定義される$C_k$を元に、それを含む矩形領域$B_k$を探してリサイズのデータ拡張とする。$B_k$について細かい記述はないが、$C_k$を含む領域であれば、ある程度ランダムに選んで良さそう。

ランダムなCroppingとAttention Croppingの比較を以下に示す。ランダムなCroppingではあらぬところを切り抜くことも多いが、Attention Croppingでは物体の領域が切り抜かれていることがわかる。

Attention Dropping
$A_k^*$が表す部位の領域をDroppingすることで、特定の部位のみに依存したモデルにならないようにデータ拡張できる。具体的には、以下で定義される$D_k$を定め、0の領域をDroppingする。このデータ拡張によって、AttentionMapが担当する部位を分離することを狙っている。

ランダムなDroppingとAttention Droppingの比較を以下に示す。ランダムなDroppingは物体と無関係な部分を削除したり、逆に物体のほとんどの部分が削除されてしまうケースが見られるが、AttentionDroppingは、物体の一部のみを削除することに成功している。

推論時の流れ
以下に推論時の処理の流れを示す。

- ImageからFeatureExtractionによってFeatureMapsを得る。
- FeatureMapsからAttentionMapsを得る。
- FeatureMapsとAttentionMapsから、BilinearAveragePooling(BAP)によってPartMatrixを得る
- PartMatrixを元に分類の予測を行う。
- AttentionMapsを利用し、Imageに対して(C)で計算されるLocalizationを行う。
- Localization済みのImageについて、1~4までの処理を行う。
- 4と6で得られる分類結果(softmax済み)の平均をとり、最終的な予測結果とする。
5~7までの処理はオプションである。7まで行う場合は、学習時と同様に2回分類までの処理を行うことになる。
(C)で行われる処理を以下で説明する。
Look Closer(Localization & Refinement)
AttentionMaskは物体の各部位へのAttentionだが、統合すれば、物体のLocalizationに使える。物体のLocalizationが行えれば、元画像からその領域を切り抜けば、高解像度の画像を対象とした分類が行える。

実験
以下の4つのデータセットでいくつかの実験を行なっている。
全ての実験結果については紹介せず、提案事項の有効性を示す上で明快な表を示す。
以下はCUB-200-2011について、精度を評価する際に、本論文で提案した、Weekly Supervised Attention Learning(AttentionLearning)、AttentionCropping、AttentionDropping、Look Closer(Loc.&Refinement)を使用する/使用しない場合の精度の比較である(一番上は、Inception-V3をファインチューニングした結果)。

提案している手法で見事に精度が向上していることがわかる。
議論
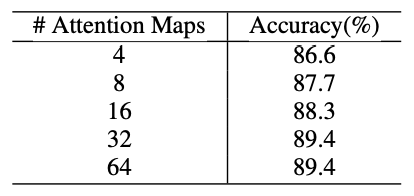
論文中の実験の範囲内だと、AttentionMapsの数($M$)は増やせば増やすほど良い精度が得られる、ということになっている。
感想
似たような手法は色々ありそうな気もするが、とりあえず一つ精読してみた。
- AttentionDroppingは、画像の側でDropさせるのではなく、$f_k$の方でDropさせるのではいけないのだろうか、と素朴に思った。
- AttentionMapsの個数$M$は増やせば増やすほど良いという結論になっているが、増えすぎるとAttentionDroppingによるデータ拡張が台無しになる気がするが、どうなのだろうか。
- AttentionMapsの局所性に関する制約が無いが、TVノルムなどの制約を加えることで、収束が早まったりしないだろうか。
4.2節の末尾に、実装を近日中に公開予定と記載されているので期待している。