アンカーを使用しない物体検出手法の1つであるRepPointsについて、最近論文を読んだので解説してみます。
概要
RepPointsは、物体検出の手法です。入力された画像に対して、事前に定められたカテゴリに属する物体の矩形領域を出力します。特徴として、この手法ではYoloやFaster-RCNNといった代表的な物体検出手法で使用されるようなアンカーは使用せず、物体の領域を表現できる「点」を求めてそこから矩形領域を得るという、ポイントベースの手法です。
ポイントベースの手法には、例えばCornerNetのように矩形領域の角を推定するような手法もありますが、本手法では、物体領域の代表的な点の集合(Point Set Representation; RepPoints)を求めて、そこから矩形領域に変換するという手法になります。
下図は、画像中の物体に特徴的なポイントから推定領域(pseudo box)を得られるところと、各ポイントから得られる特徴量を集約してクラス分類を行っていることが示されています。
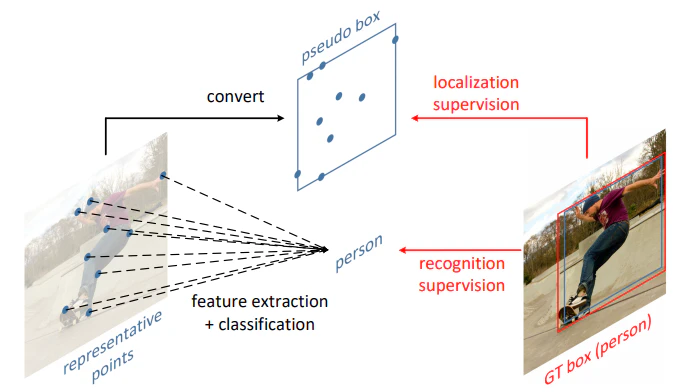
説明の流れとしては、まずはネットワークのアーキテクチャについて説明し、その後損失がどのように計算されるのかを確認していきます。
ネットワークアーキテクチャ
まずはネットワークアーキテクチャを概観してみましょう。
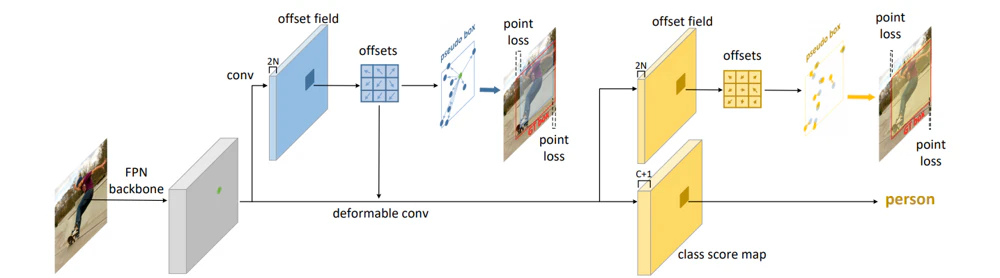
- 入力画像は、Feature Pyramid Networkを通して、5段階のスケールの特徴量マップに変換されます。図中では、その1スケール分の特徴量マップが描かれています(灰色)。以降の処理は、各スケールごとに行われます。
- 特徴量マップから、物体領域を代表する$N$個の点を得ます。本論文では、点の数は$N=9$で統一されています。特徴量マップからいくつかのConv層を通じて$2N$チャネルのマップ(青いoffset field)が得られており、各セルごと$N$個の2次元ベクトルを値を保持しています(青いoffset)。直感的には、これらの2次元ベクトルは、「あっちの方に重要な点があるよ」ということを推測していると考えれば良いでしょう。このようにして得られた$N$この点から矩形領域を作成し、損失を計算します(point loss)。
- メインの流れに戻りましょう。先程得られたoffsetを使い、FPNから得られた特徴量に(いくつかのconv層を適用した後に)DeformableConvを適用します。DeformableConvについては詳細には説明しませんが、直感的には、身近な領域から特徴を集約する通常のConv層に対して、入力によって動的に変化するoffsetによって調整された、少し離れた領域から特徴を集約するConv層であると理解すれば良いでしょう。
その後、ネットワークは2つに枝分かれします。1つはクラスを推定する分類ブランチで、$C+1$チャネルのマップを出力します(class score map)。もう1つは前段で得られていた$N$個の点を補正するブランチで、$2N$チャネルのマップを出力します(黄色のoffset field)。分類ブランチでは分類の損失が、補正ブランチでは前段と同様のpoint lossが適用されます。
上の図はざっくりとした構造を理解するのには十分ですが、少々ミスリーディングで、実際には、以下のような構造を持っています。
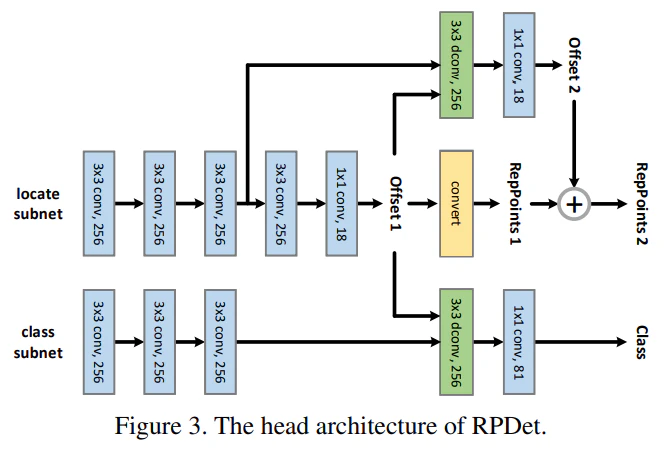
ポイントの位置を推定するlocate subnetと分類を行うclass subnetは、DeformableConvで使用するoffsetのみを共有しており、conv層自体のパラメータは共有していないことに注意しましょう。
※DeformableConvの詳細はQiita内の解説記事等を御覧ください。
- https://qiita.com/keisuke-nakata/items/90f7020f04476b01d07d
- https://qiita.com/4Ui_iUrz1/items/38eca224f0aecb312979
損失関数
ネットワークアーキテクチャの説明の部分でいくつか出てきた損失について説明します。
RepPointの位置を訓練するための位置損失と分類を訓練するための分類損失について説明しますが、その前に、$N$個のPointからどのようにして疑似矩形領域が領域が作れられるのかを確認します。また、推論結果の目標を真の矩形領域からどのように作成するのかも確認します。
疑似矩形領域の作成
本論文では、以下に示す3つの方法を検討していますが、精度的には3つ目のモーメントベースの方法が良かったと実験的に示しています。3つ目の方法では、まず$N$個の点の平均を中心点とし、x方向y方向の標準偏差を求め、それに対して訓練対象のパラメータ$\lambda_x, \lambda_y$によってスケーリングすることで矩形領域を得ています。

推論の目標の作成
疑似矩形領域は、Feature Pyramidのスケールごとに、offset fieldのセルごとに出力されますので、その目標となる、真の矩形領域の情報は、何らかの形でoffset fieldのセルに対応付ける必要があります。本手法では非常に単純な方法を採用しており、真の矩形領域をただ1つのスケールとセルに対応づけます。
まず真の矩形領域の大きさに応じて、Feature Pyramidのどのスケールに対応させるのかを決めます。具体的には、下式で決定されます。
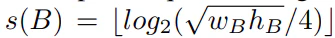
次に、真の物体領域の中心が位置するセルに、クラスと矩形領域の目標を設定します。
このような対応づけは、異なるスケールの複数の物体が同じ位置にあるようなとき(例えば、大人が子供を抱っこしているような状況)でも、概ね対応できているそうです。
位置損失(point loss)
このようにして得られた疑似矩形領域と真の矩形領域の差異を、左上の点や右下の点のSmooth L1距離によって評価し、これを損失とします。ただし、1段階目の推定矩形領域が大幅に外れてしまっている場合は、2段階目の補正項の訓練に悪影響が生じてしまうため、1段階目のRepPointsから作られた推定矩形領域と真の矩形領域のIoUが0.5以上のときのみ訓練対象とします。
分類損失
分類損失も、1段階目のRepPointsから作られた推定矩形領域が大幅に外れている場合は適用されません。推定矩形領域と真の矩形領域とのIoUが0.5以上のときのみ適用されます。損失関数はFocalLossを使用しています。
実験
以下に、近年のSoTAの物体検出手法との比較を示します。データセットとして、MS-COCOのDetectionベンチマークを使用しています。
RPDetと書かれているのが本手法で、BackboneがResNet-101のとき、アンカーベースの手法やアンカーフリーのCornerNetなどの手法と、ほぼ同程度の精度が得られていることがわかります。
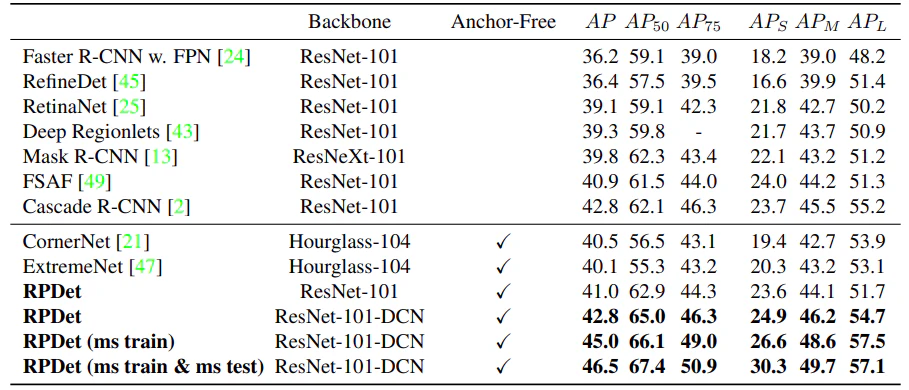
気になるのがBackbone-101-DCNですが、これはResNet内のConv層をすべてDeformableConvに置き換えたものとのことです。
また、ms train, ms testのmsとは、multi scaleの略で、訓練時や推論時に入力画像に対してランダムな拡大縮小を適用するか否かを表しています。
全体としては、本手法は既存の手法の代替として使える有力な手法であると言えるでしょう。
まとめ
アンカーフリーの物体検出手法RepPointsについて解説しました。
アンカーにまつわるいくつかのハイパーパラメータなしに、SoTAの手法と同程度の精度まで迫っていることを確認しました。
書誌情報
- Yang, Ze, et al. "RepPoints: Point Set Representation for Object Detection." arXiv preprint arXiv:1904.11490 (2019).
- ICCV2019のページ
- arxiv
- 公式実装