2018/11/27にarXivに投稿された論文「Deformable ConvNets v2: More Deformable, Better Results」で、スケールと形状を学習可能なConvolutionであるModulated Deformable Convolutionが提案されています。おもしろそうな手法だったのでPyTorchで実装してみました。
ソースコードはこちら
https://github.com/4uiiurz1/pytorch-deform-conv-v2
Modulated Deformable ConvolutionはDeformable Convolutional Networksで提案されているDeformable Convolutionの改良版ですので、初めにDeformable Convolutonについて簡単に説明します。
Deformable Convolution
あるニューロンの出力に影響を与える入力画像の範囲をReceptive Field(受容野)といいます。一般的にReceptive Fieldは認識したい物体の全体をカバーするように設計されます。分類タスクではそこまで問題になりませんが、一つの画像に様々なスケールと形状の物体が複数含まれるsegmentationやobject detectionのようなタスクでは、様々なスケールと形状の物体をカバーするようなReceptive Fieldを持つネットワークを設計する必要があります。
**Atrous Convolution (Dilated Convolution)**は下記のような一定間隔開けた画素に対して畳み込みを行うもので、Receptive Fieldを大幅に広げることが可能です。
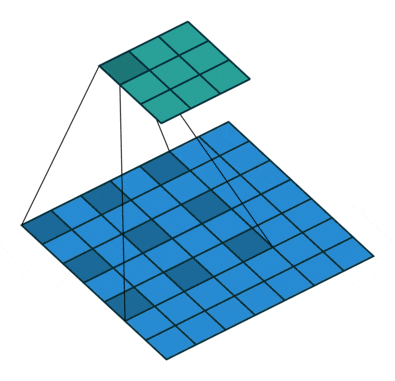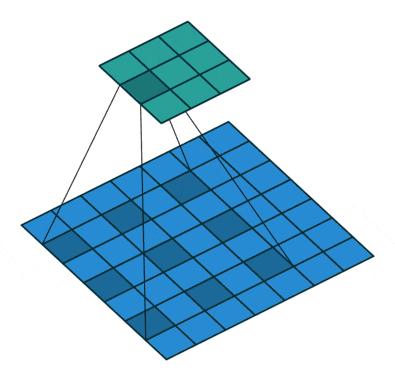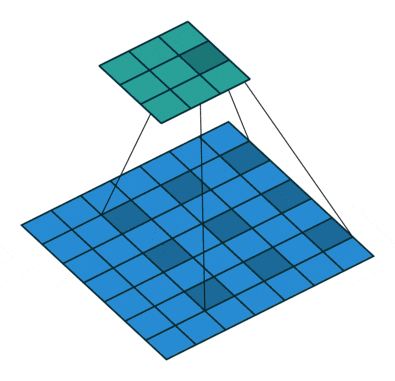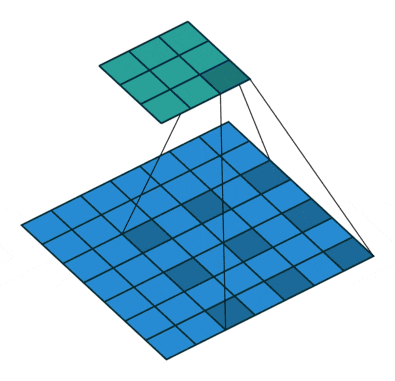
https://github.com/vdumoulin/conv_arithmetic
Atrous Convolutionではスケール・形状は固定かつ形状のバリエーションも四角形のみですが、Deformable Convolutionではスケールと形状が認識対象の物体に合わせて最適なものに変わります。具体的には、通常のConvolutionで用いる画素からの変位であるoffsetを学習します。畳み込みに用いる入力画像中の座標が離散値ではない場合は、バイリニア補間によって画素値を算出します。

下図のように異なるスケール・形状の物体に対してReceptive Fieldが動的に変化します。

ネットワーク上ではDeformable Convolutionをかける特徴マップに対して畳み込みをかけることでoffsetを求めます。
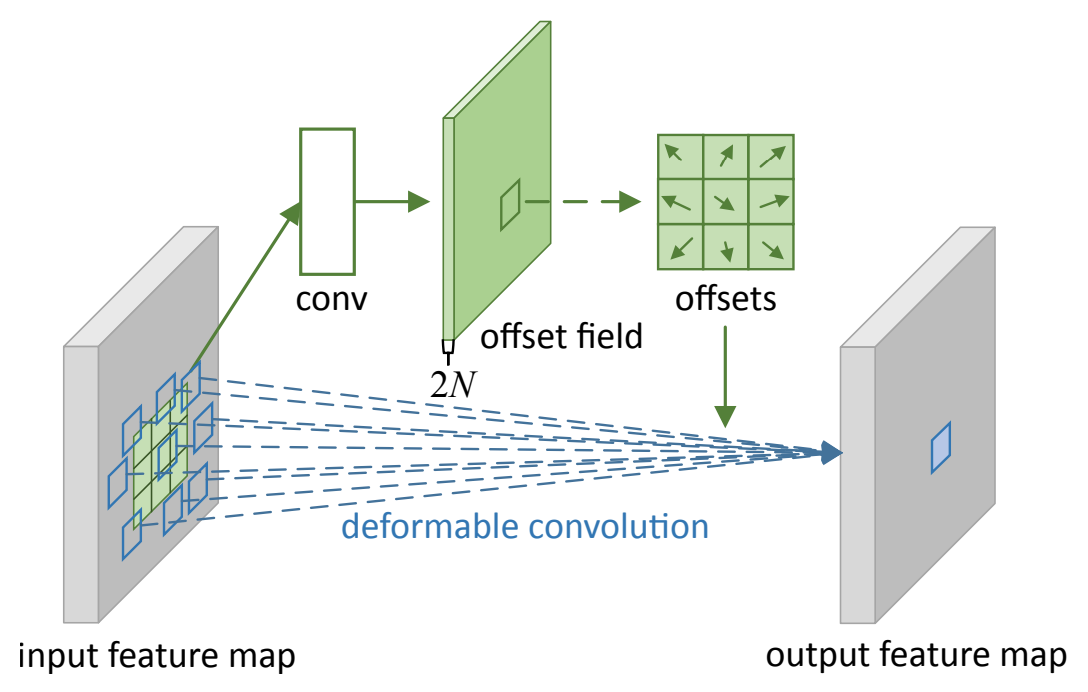
Deformable Convolutionを式で表すと以下のようになります。
y(p_0) = \sum_{p_n \in \mathcal{R}}w(p_n) \cdot x(p_0+p_n+\Delta p_n)
$p_0$: Convolutionによって求められる出力マップ上の画素
$\mathcal{R}, p_n$: 通常のConvolutionで用いられる入力マップ上の画素集合と画素
$\Delta p_n$: 変位、offset
$x()$: バイリニア補間によって算出された画素値
$w()$: 重み
Deformable Convolutionniについて、こちらのスライドを参考にしました。とても分かりやすいのでぜひご覧ください。
Active Convolution, Deformable Convolution ―形状・スケールを学習可能なConvolution―
Modulated Deformable Convolution
Deformable Convolutionにさらに入力画素ごとの学習可能な重み(0~1)であるmodulation機構を追加します。これによってDeformable Convolutionの持つ自由度が向上します。Deformable Convolutionでは適用する総数が一定以上になるとパフォーマンスがサチっていたようですが、Modulated Deformable Convolutionではそれ以上適用してもパフォーマンスは向上し、Deformable Convolution以上のパフォーマンスが得られました。
式は以下のようになります。
y(p_0) = \sum_{p_n \in \mathcal{R}}w(p_n) \cdot x(p_0+p_n+\Delta p_n) \cdot \Delta m_n
$\Delta m_n$: 重み、modulation機構
$\Delta m_n$はoffsetと同様に、Modulated Deformable Convolutionをかける特徴マップに対して畳み込みとsigmoid関数をかけることで求めます。
実装
Modulated Deformable Convolutionの実装は以下のようになります。
class DeformConv2d(nn.Module):
def __init__(self, inc, outc, kernel_size=3, padding=1, stride=1, bias=None, modulation=False):
"""
Args:
modulation (bool, optional): If True, Modulated Defomable Convolution (Deformable ConvNets v2).
"""
super(DeformConv2d, self).__init__()
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.zero_padding = nn.ZeroPad2d(padding)
self.conv = nn.Conv2d(inc, outc, kernel_size=kernel_size, stride=kernel_size, bias=bias)
self.p_conv = nn.Conv2d(inc, 2*kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
self.p_conv.register_backward_hook(self._set_lr)
self.modulation = modulation
if modulation:
self.m_conv = nn.Conv2d(inc, kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.m_conv.weight, 0.5)
self.m_conv.register_backward_hook(self._set_lr)
@staticmethod
def _set_lr(module, grad_input, grad_output):
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
def forward(self, x):
offset = self.p_conv(x)
if self.modulation:
m = torch.sigmoid(self.m_conv(x))
dtype = offset.data.type()
ks = self.kernel_size
N = offset.size(1) // 2
if self.padding:
x = self.zero_padding(x)
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = Variable(p.data, requires_grad=False).floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], -1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], -1)
# (b, h, w, N)
mask = torch.cat([p[..., :N].lt(self.padding)+p[..., :N].gt(x.size(2)-1-self.padding),
p[..., N:].lt(self.padding)+p[..., N:].gt(x.size(3)-1-self.padding)], dim=-1).type_as(p)
mask = mask.detach()
floor_p = p - (p - torch.floor(p))
p = p*(1-mask) + floor_p*mask
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# (b, c, h, w, N)
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# (b, c, h, w, N)
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
# modulation
if self.modulation:
m = m.contiguous().permute(0, 2, 3, 1)
m = m.unsqueeze(dim=1)
m = torch.cat([m for _ in range(x_offset.size(1))], dim=1)
x_offset *= m
x_offset = self._reshape_x_offset(x_offset, ks)
out = self.conv(x_offset)
return out
def _get_p_n(self, N, dtype):
p_n_x, p_n_y = torch.meshgrid(
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1),
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1))
# (2N, 1)
p_n = torch.cat([torch.flatten(p_n_x), torch.flatten(p_n_y)], 0)
p_n = p_n.view(1, 2*N, 1, 1).type(dtype)
return p_n
def _get_p_0(self, h, w, N, dtype):
p_0_x, p_0_y = torch.meshgrid(
torch.arange(1, h*self.stride+1, self.stride),
torch.arange(1, w*self.stride+1, self.stride))
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
def _get_p(self, offset, dtype):
N, h, w = offset.size(1)//2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N]*padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
@staticmethod
def _reshape_x_offset(x_offset, ks):
b, c, h, w, N = x_offset.size()
x_offset = torch.cat([x_offset[..., s:s+ks].contiguous().view(b, c, h, w*ks) for s in range(0, N, ks)], dim=-1)
x_offset = x_offset.contiguous().view(b, c, h*ks, w*ks)
return x_offset
こちらのDeformable ConvolutionのPyTorchによる実装を参考にしました。
https://github.com/ChunhuanLin/deform_conv_pytorch
実験
ランダムにスケールを変えたMNISTで性能を比較しました。
結果は以下のようになりました。
| Model | Accuracy (%) | Loss |
|---|---|---|
| w/o DCN | 97.22 | 0.113 |
| w/ DCN at conv4 | 98.85 | 0.046 |
| w/ DCN at conv3~4 | 98.93 | 0.040 |
| w/ DCNv2 at conv4 | 98.27 | 0.057 |
| w/ DCNv2 at conv3~4 | 99.09 | 0.031 |
最後に
簡単な性能評価としてランダムにスケールを変えたMNISTで試してみましたが、一応Modulated Deformable Convolutionが最も高い性能となりました。今後はobject detectionといったタスクで試してみたいと思います。
Deformable ConvolutionとModulated Deformable Convolutionの論文では畳み込みの他にも、object detectionでよく用いられるRoI PoolingをDeformableに変更したものが載っているので、興味のある方はぜひ確認してみてください。