概要
Efficientな物体検出モデル、EfficientDetの論文を読んだので、ざっくり紹介します。
本論文の新規性は以下の2点です。
- 複数の解像度の特徴マップをうまく混合してFeaturePyramidを得るための方法であるBiFPNを提案。
- Efficientの名を冠している通り、分類モデルのEfficientNetの影響を受けている。特徴抽出のバックボーンとしてEfficientNetを使用するだけでなく、EfficientNetのようにネットワークの容量をスケールさせるパラメータを導入し、FLOPsと精度のバランスを図っていまる。一番大きなEfficientDet-D7は、MS COCOデータセットで51.0mAPを達成し、論文発表時点でのSotAを主張している。
書誌情報
- Tan, Mingxing, Ruoming Pang, and Quoc V. Le. "Efficientdet: Scalable and efficient object detection." arXiv preprint arXiv:1911.09070 (2019).
- Google Research, Brain Team
- https://arxiv.org/pdf/1911.09070.pdf
BiFPNによるFeaturePyramidの混合
物体検出では、FeaturePyramidと呼ばれる複数の解像度からなる特徴マップをよく利用します。各特徴マップの1マスごとに(様々なスケールの)アンカーを定義するので、解像度が高く網目が小さい特徴マップでは小さい物体を、解像度が低く網目の大きい特徴マップでは大きい物体を検出できることを期待しています。
FeaturePyramidは、同じチャネル数の異なる解像度の特徴マップから構成されます。各種のバックボーンネットワーク(VGG、ResNetなど)の処理途中の特徴マップに簡単な調整を施してチャネル数を揃えた後、これらを混合して最終的なFeaturePyramidを得ます。問題となるのは、どのように混合して物体検出に適した複数の特徴マップを得るのか、ということになります。この混合の方法は非常に自由度が高く、いろいろな方法が提案されています。
混合のためのアーキテクチャ
以下の図はFeaturePyramidの混合のバリエーションです。$P_3, P_4, P_5, P_6, P_7$はバックボーンネットワークから得られた、チャネル数を揃えた特徴マップです。
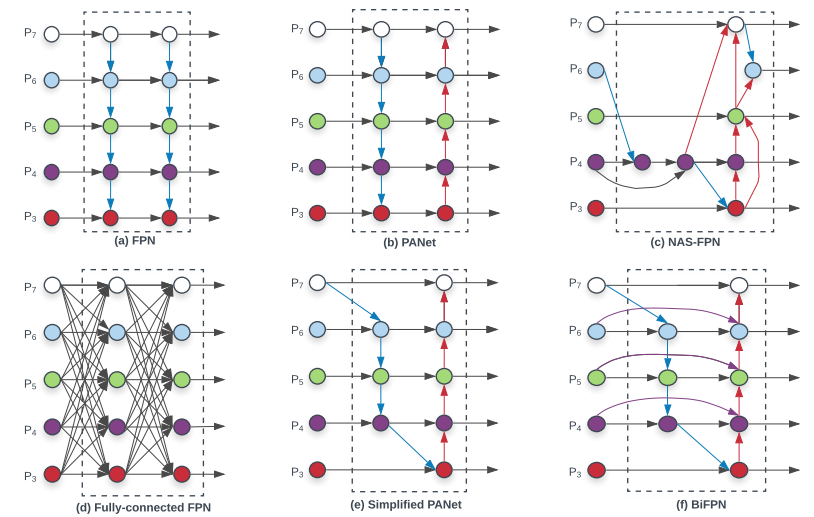
(a)FPNでは、解像度が低く大域的な特徴を表した特徴($P_7$側)を高解像度の特徴側に加算するという構造になっています(青矢印)。これは、物体の検出を行う際に、局所的な情報だけではなく、大域的な情報も含めて総合的に判断するというトップダウンな情報の混合と言えます。
(b)PANetは、FPNだけだと情報の流れが1方向だけになってしまうので、2段目の処理をボトムアップの方向の加算(赤矢印)へと変更したものです。
(c)NAS-FPNは、混合の方法をNeural Architecture Searchによって探索したものです(NAS-FPNについては、前に紹介記事も書いたので、興味があったら御覧ください)。また、(d)はとりあえず全部つないどこう、というケースです。
(e)Simplified PANetは、(b)PANetのうち1入力になっている箇所を除去し、効率化したバージョンです。そして、本論文で提案している(f)BiFPNは(e)にスキップコネクションを導入し、訓練効率の向上を実現しています。
また、実際にBiFPNを使うときは、BiFPNを1つだけでなく、複数回適用します。こうすることで、トップダウンとボトムアップの混合を何度か繰り返しならがFeaturePyramidを洗練させていくという処理が実現できます。
複数の特徴マップの加算方法
上図のように特徴マップを混合する際に、いくつか気になる点があります。
- 異なる解像度の特徴マップ同士をどのように混合するか
- 特徴マップが合流する点では具体的にどのような処理を行うか
前者については、ごく普通のリサイズ処理によって実現します。問題となるのは後者のほうで、本論文では3通りのやり方を考えています。
- Unbounded fusion:複数の入力特徴マップを重み付けして足し合わせます。$O=\sum_{i} w_{i} \cdot I_{i}$と表され、$w_i$は訓練対象のパラメータです。この方法は、$w_i$のスケールに制限が無いため、学習が不安定になりがちです。
- Softmax-based fusion:上記の不安定さを回避するために、重みをsoftmaxによって算出します。$O=\sum_{i} \frac{e^{w_{i}}}{\sum_{j} e^{w_{j}}} \cdot I_{i}$と表され、$w_i$は訓練対象のパラメータです。この方法によって、混合時のスケールを安定させます。しかし、ここでsoftmax処理を採り入れると、GPUでの処理速度が遅くなるという問題が実験的に明らかになったそうです。
- Fast normalized fusion:上記の計算速度を改善するために、もう少し直接的な重み付けを行います。$O=\sum_{i} \frac{w_{i}}{\epsilon+\sum_{j} w_{j}} \cdot I_{i}$と表されます。$w_i$は訓練対象のパラメータですが、より正確には、正の値になるようにReLUを適用された値を使用します。こうすることで、Softmaxのような重い処理を避けつつ、適切に重み付けした特徴マップの混合処理を実現しています。
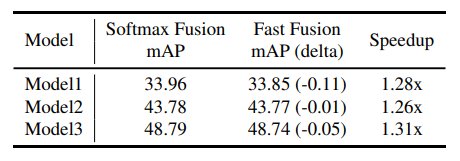
Softmax-basedとFast normalizedの比較が以下の表です。若干Fast normalizedでは精度が劣化しますが、1.3倍程度のスピードアップが得られています。
Fast normalizedを使うと、例えば、2入力、3入力の混合処理は以下のように実現されます。
- $P_{6}^{t d} = \operatorname{Conv}\left(\frac{w_{1} \cdot P_{6}^{i n}+w_{2} \cdot \operatorname{Resize}\left(P_{7}^{i n}\right)}{w_{1}+w_{2}+\epsilon}\right)$
- $P_{6}^{o u t} =\operatorname{Conv}\left(\frac{w_{1}^{\prime} \cdot P_{6}^{i n}+w_{2}^{\prime} \cdot P_{6}^{t d}+w_{3}^{\prime} \cdot \operatorname{Resize}\left(P_{5}^{o u t}\right)}{w_{1}^{\prime}+w_{2}^{\prime}+w_{3}^{\prime}+\epsilon}\right)$
EfficientDetのアーキテクチャとCompaound Scaling
EfficientDetは、バックボーンのネットワークとしてEfficientNetを使用し、そこから得られた複数解像度の特徴マップをBiFPNによって混合し、それぞれの解像度で分類・矩形予測のヘッドがついている、という構造になっています。BiFPNは、同じ構造が複数層(下図では3層)積まれています。
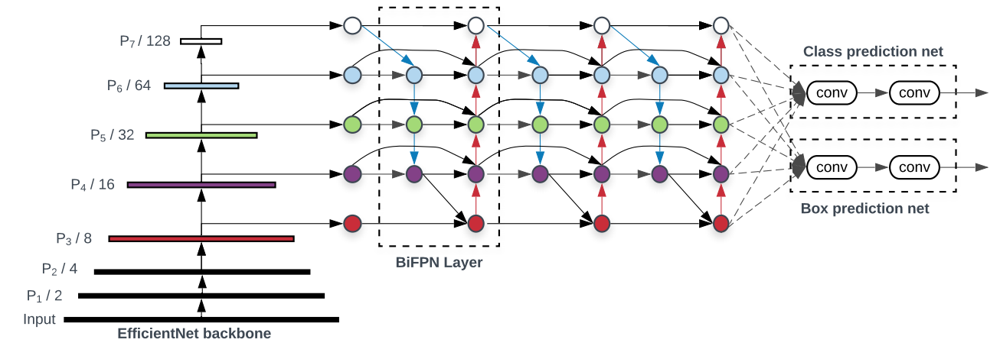
ここで、EfficientNetにどの容量のものを使用するのか、BiFPNは何層重ねるか、ヘッド部分の次元数はどうするか、といった容量に関するいろいろなパラメータが存在します。
本手法では、詳細なグリッドサーチはせずに、一つのパラメータ$\phi$によってネットワークの容量の調整を代表させています。$\phi$によって、各種パラメータは以下のように決定されます。
- 入力画像の大きさ:$R_{\text {input}}=512+\phi \cdot 128$
- EfficientNet:$\phi$
- 特徴マップのチャネル数:$W_{b i f p n}=64 \cdot\left(1.35^{\phi}\right)$
- BiFPNの層数:$D_{b i f p n}=2+\phi$
- 分類・矩形ヘッドの層数:$D_{b o x}=D_{c l a s s}=3+\lfloor\phi / 3\rfloor$
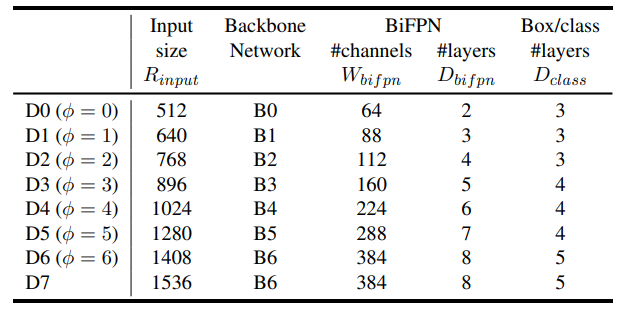
ネットワークの容量に関するハイパーパラメータを混ぜてひとつのパラメータで代表させるので、Compaund Scalingと呼んでいます。
まとめ
以上、簡単にですが、EfficientDetについて紹介しました。
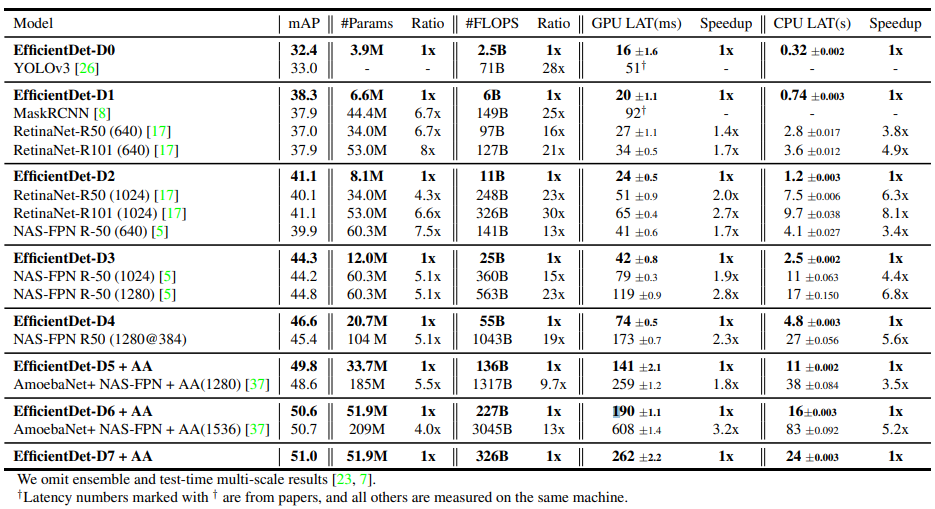
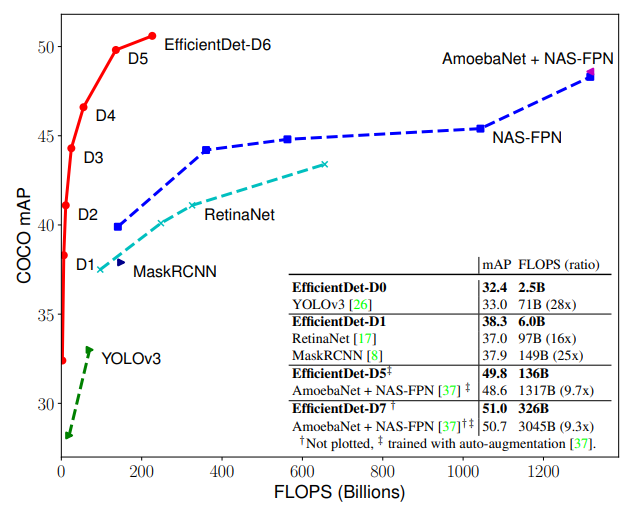
最後に、複数のモデルと本手法の比較を行った表を見ておきましょう。
同程度の精度が得られている既存のモデルに比べると、EfficientDetでは、パラメータ数がかなり減少しているということが見て取れます。