概要
cGAN の軽量化手法を提案している論文1を読んでいたところ、"once-for-all network"という手法に遭遇しました。あまりにもサラッと記載されていたので、軽量化の分野では結構メジャーな手法なのかもと思い、元の論文に当たってみることにしました。
実装が GitHub にて公開されています。GitHub のトップページに以下のような図が掲載されています。
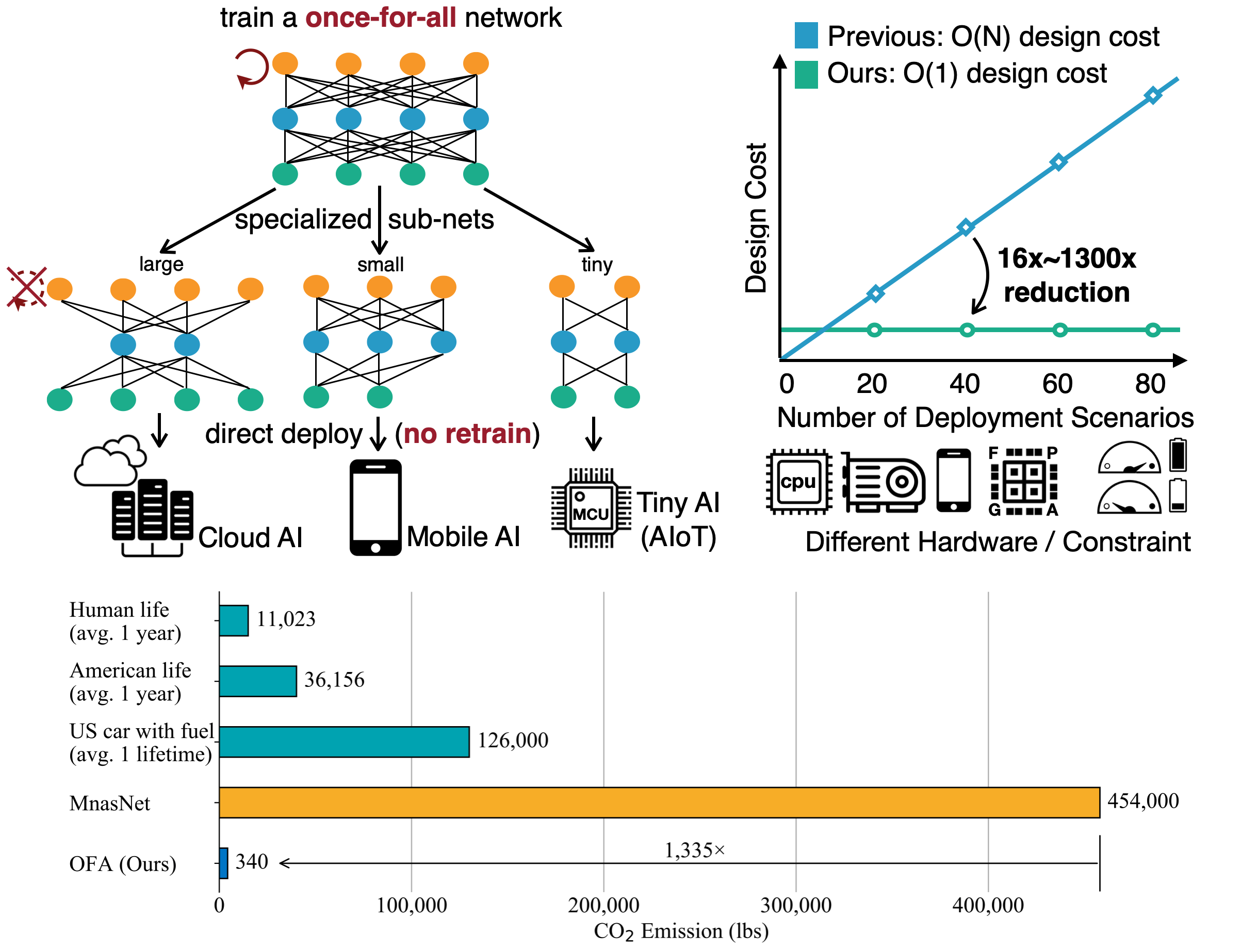
- 左上の図では、once-for-all network を訓練すると、各デバイスに特化したサブネットワークを「追加訓練なしで」つくることができるということを示したものです。
- 右上のグラフは、各デバイスに合わせたネットワーク構造の設計が不要になるため、デザインコストが$\mathcal{O}(N)$から$\mathcal{O}(1)$になるということを示しています。
- 一番下の棒グラフは、本手法によって CO2 排出量がどれだけ減らせるかを示しています。
本手法は、低消費電力のモデル構築を競うLPCVというコンペで、複数回・複数部門でトップを勝ち取っています。
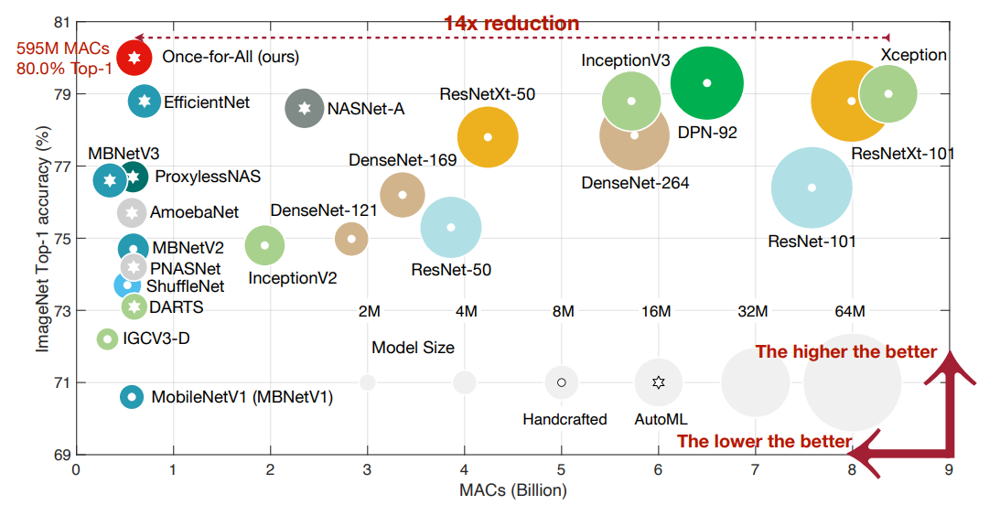
また、モバイル設定では世界で初めて ImageNet の Top-1 Accuracy が 80%を超えた、と主張しています。
書誌情報
- Cai, Han, Chuang Gan, and Song Han. "Once for all: Train one network and specialize it for efficient deployment." arXiv preprint arXiv:1908.09791 (2019).
- 公式実装(PyTorch)
- 発表スライド(Progressive Shrinkingの手順がわかりやすいです)
once-for-allの仕組み
通常、様々な構造を持つニューラルネットワークを訓練するためには、その都度個々のネットワークを個別に訓練する必要があります。
本手法ではこの問題を解決しています。1 つの巨大なネットワーク(onece-for-all network;以下、OFA)の訓練さえすれば、そのなかの一部分を流用して構築されたサブネットワークを追加訓練なしで得ることができます。なお、追加訓練がなくてもそれなりの精度が出ますが、更にファインチューニングを行うこともできます。また、特定のデバイスで動かすために、期待する精度やレイテンシ(処理時間)を指定して適切なサブネットワークを探索する方法も提案されています。
一体どのようにして1 つの巨大なネットワークの中に多くのサブネットワークを含むことが可能になるのか、というのが本手法の肝となるところです。
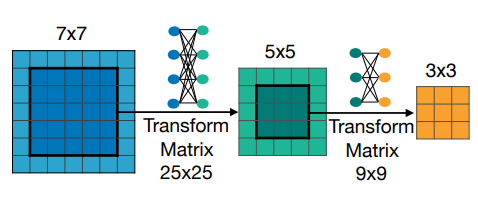
一例として、Conv 層のカーネルサイズについて考えます。一般に、畳み込み層のカーネルは、その中央に近い領域ほど重要な情報を持っていることが期待されます。そのため、7×7 のカーネルの中央 5×5 を元に少し調整してあげれば、7×7Conv 層と似たような計算結果になる 5×5Conv 層を構成できるのではないかということが考えられます。同様に、 5×5Conv 層を近似できる 3×3 Conv 層も作れそうです。ここで重要なのは、7×7 のカーネルと 5×5 のカーネル、そして 3×3 のカーネルはいずれも訓練対象のパラメータの大部分を共有しているということです。訓練対象のパラメータは、大もとの 7×7Conv のパラメータに加えて、分布調整のためのパラメータ$(5 \times 5) \times (5 \times 5) + (3 \times 3) \times (3 \times 3)$が必要になります。大もとの 7×7Conv のパラメータが支配的で、追加で必要なパラメータは微々たるものです。このような Conv 層は、気分によってカーネルサイズを変更できる、Elastic な(弾性的な) Conv 層とでも呼ぶべきものになっています。
以上のような Elastic な Conv 層が 5 つ連なっているネットワークを考えます。このネットワークの各 Conv 層のカーネルサイズは、${7, 5, 3}$という 3 通りの中から選ぶことができるので、ネットワーク全体では$3^5$通りのサブネットワークの可能性を持っています。これが、1 つの巨大なネットワークの中に多くのサブネットワークを含む、ということの意味です。
ベースとなるネットワーク
本手法では、MobileNetV32をベースのネットワーク構造としています。MobileNetV3 では以下のような (Inverse)BottleNeck 構造を基本の構成要素としています。
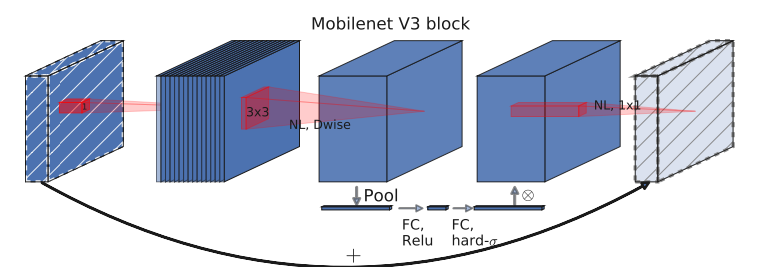
詳細な説明は省きますが、1 つ BottleNeck に対して 1 つの 3×3 Depth-wise Conv 層を含んでいることが確認できます。それ以外の Conv 層は 1×1 のカーネルサイズを持つ Point-wise Conv 層から構成されています。SE(Squeeze-and-Excitation)ブロックも使っていることが確認できます。
このような BottleNeck と普通の Conv 層を組み合わせて、例えば MobileNetV3-Small という小さめのネットワークは、以下のような構成要素から成り立っています。
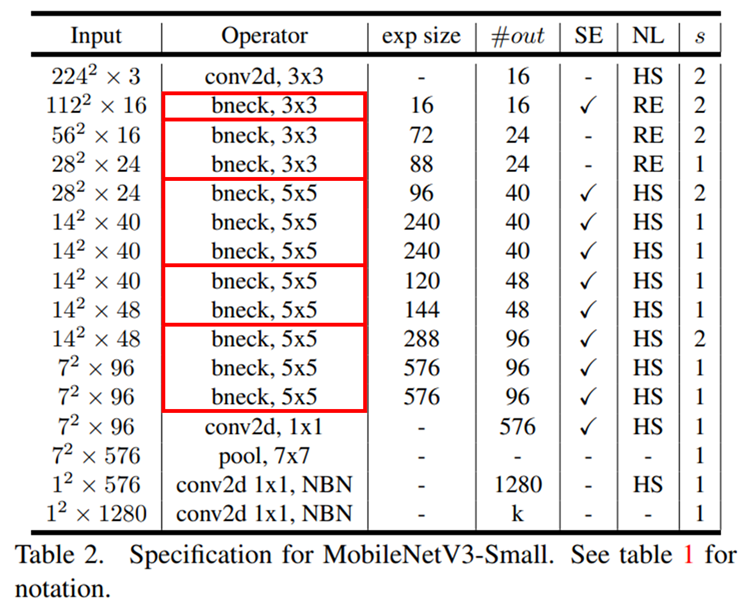
本手法に関係のあるところである、Operator 列と exp size 列に注目しましょう。まず、Operator 列には通常の Conv 層に加えて、bneck と表記された BottleNeck が並んでいます。BottleNeck は、大きく 5 つのブロックに区分けされており、各ブロックを赤枠で囲っています。MobileNetV3 には 5 つのブロックが含まれていますが、ブロック内で何個 BottleNeck を使用するのか、という点については自由度があります。また、exp size 列には、BottleNeck の中間層のチャネル数が示されています。このチャネル数も自由度があります。
探索空間
本手法では、上に挙げた MobileNetV3 の基本構造を踏襲しながら、いくつかの要素をパラメータ化して選択可能にしています。
- Resolution: 入力画像サイズ。128 から 224 まで 4 飛ばしで 25 通り。
- Kernel: BottleNeck 内の Depthwise-Conv 層のカーネルサイズ。3, 5, 7 の 3 通り。
- Width: BottleNeck 内のチャネル数(を制御する拡大率)。2, 3, 4 の 3 通り。
- Depth: ブロック内の BottleNeck の数。2, 3, 4 の 3 通り。ブロックは全部で 5 つある。
Width や Depth がどのようにして Elastic な形にできるのかは、後述します。
入力画像のサイズ以外のネットワーク構造に関する探索空間の広さを概算してみると、$((3 \times 3)^2 + (3 \times 3)^3 + (3 \times 3)^4)^5 \simeq 2 \times 10^{19}$通りとなります。つまり、OFA は単一のネットワークに見えながら、$10^{19}$通りのサブネットワークを含んでいる、ということになります。
ElasticなWidthとDepth
Width や Depth をどのようにして Elastic にできるのかを確認していきましょう。
Width
Width は BottleNeck 内のチャネル数を制御する拡大率です。各チャネルに対して重要度を算出してソートし、あまり重要でないチャネルに関する計算を省略するようにすれば、異なる拡大率のサブネットワークとして扱うことができます。チャネルの重要度は、BottleNeck の最初に行う Pixel-wise の 1×1Conv 層の重みを元に、各チャネルの L1 ノルムを元に算出します。
Depth
Depth は、ブロック内で BottleNeck を何回繰り返すかを制御する値です。ブロックの後方に位置する BottleNeck の計算を省略することで、異なるサブネットワークを構成できます。BottleNeck は Residual な構造を持っているので、ブロック前方の BottleNeck が大まかな処理を、後方の BottleNeck が細かい処理を担当していると考えられます。そのため前方の BottleNeck は残したまま、後方の BottleNeck を削除することで、もともとのネットワークを近似する小さいサブネットワークを構成できます。
Progressive Shrinking
OFA の訓練方法である Progressive Shrinking について説明していきます。
最も単純に考えられる方法として、OFA に含まれる$10^{19}$通りのサブネットワークを、ランダムにサンプルしながら訓練するという方法が考えられます。しかし、この方法はうまく行かないそうです。そこで、最初に最大規模のネットワークを訓練し、その後徐々に小さいサブネットワークに対応できるようにファインチューニングしていくという Progressive Shrinking を提案しています。
Progressive Shrinkingの手順
Progressive Shrinking は以下のような手順で行われます。
- ランダムな Resolution で、最大規模のネットワークを訓練します。最大規模のネットワークは、$Kernel=7, Depth=4, Width=4$がすべての Elastic なモジュールに対して適用されたサブネットワークです。
- 上記がある程度完了したところで、Kernel を${7, 5}$の中からランダムにサンプルして訓練を進めます。$Depth=4, Width=4$はそのままです。通常のラベルを使用した損失以外に、最大規模のネットワークを用いた知識蒸留の損失も使って訓練します。Resolution はランダムなままです。
- 上記がある程度完了したところで、Kernel を${7, 5, 3}$の中からランダムにサンプルして訓練を進めます。その他の条件はそのままです。
- 上記がある程度完了したところで、次は Depth を${4, 3}$の中からランダムにサンプルして訓練を進めます。その後、Depth のサンプル空間を${4, 3, 2}$にまで拡張します。この間、Resolution と Kernel はランダムにサンプルされます。
- 上記がある程度完了したところで、最後に Width を${4, 3}$の中からサンプルするようにして訓練を進め、その後${4, 3, 2}$までサンプル空間を広げます。この間、Resolution, Kernel, Depth はランダムです。
以上のように、徐々にパラメータのサンプル空間を拡張し、対応するサブネットワークを増やしていくことで、安定した訓練が進められるようになったとのことです。
Progressive Shrinking の手順をまとめると、以下のようになります。
- Resolution, Kernel, Depth, Width の順にサンプル空間を増やしながら訓練する
- Kernel, Depth, Width のそれぞれの段階では、徐々に小さいサイズのサブネットワークに対応するサンプル空間を増やしながら訓練する
以下の 3 つの図は、それぞれ Kernel, Depth, Width の Shrinking の過程を表しています。各 Shrinking の間には、ファインチューニングが含まれているということに注意しましょう。
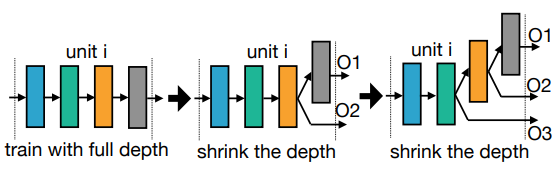
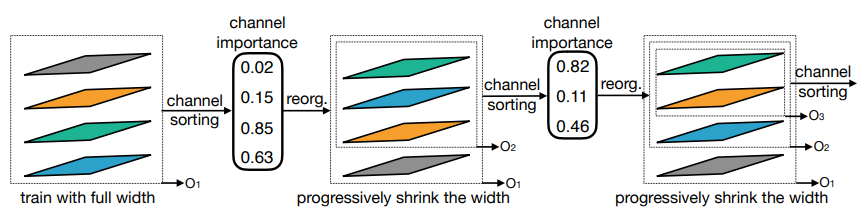
このような OFA の訓練は、32 個の V100 GPU を使って 2048 バッチサイズで行い、1,200 GPU hours で行われるそうです。なかなかのコストですが、この訓練さえ完了すれば様々なデバイスに向けたサブネットワークが追加の訓練無しで得られる、と考えると安いものです。
Progressive Shrinkingの有効性
以下に示すのは、最初から全サンプル空間で訓練した場合と、Progressive Shringkin によって徐々にサンプル空間を広げて訓練した場合の精度比較をした図です。比較の簡略化のために、Depth, Width, Kernel を全モジュールで一致させています。
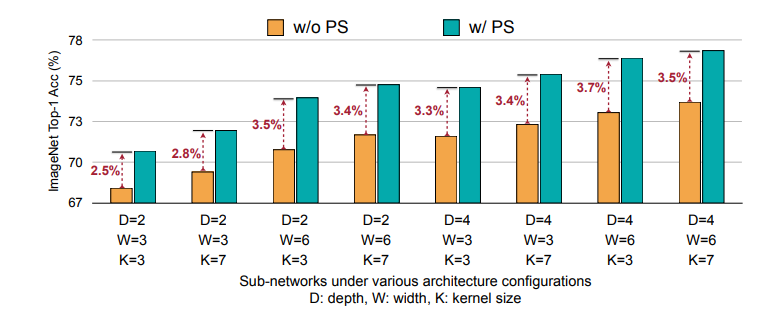
Progressive Shrinking を用いることで、より良い精度のサブネットワークが得られるということが確認できます。
最適なサブネットワークの探索
以上のように訓練した OFA から、各デバイスに向けたサブネットワークを得るための方法について説明します。
精度とレイテンシの推定
各デバイスに特化したサブネットワークの選択をするにあたって、何らかの基準が必要になります。多くの場合、その基準は精度やレイテンシ(ネットワークの処理時間)となります。
精度に関しては、サブネットワークそのものの性質なので、GPU 環境で測定できます。しかし、サブネットワークの組み合わせは$10^{19}$通りもあるので、実際にすべての組み合わせを動かしてみて精度を測定するというのは無理のある話です。そこで、精度を推定する予測モデルを構築します。このモデルは、サブネットワークのパラメータを入力すると予測精度を出力するモデルです。このようなモデルを作るに当たり、教師データが必要になります。本手法では、40GPU hours 程度かけて 16k ものサブネットワークで実際に精度を測定し、(サブネットワークのパラメータ, 精度)がセットとなった教師データを得ています。
一方、レイテンシについては各デバイスごとに実際のサブネットワークを動かしてみて速度を計測するしかありません。ここで、進化的探索を行うことで、できるだけ賢く探索していきます。この進化的探索のコストは 40GPU hours と比べると、無視できる大きさだそうです。
このようにして、必要な精度、必要なレイテンシを満たしたサブネットワークが選択されます。このサブネットワークは、そのままでもそれなりの精度が得られますが、さらにファインチューニングを行うことでより良い精度が得られるようになります。
コストの比較
以下は、様々な手法で、1 つのデバイス(Google Pixel 1)に特化したモデルを作ると、どのような精度・レイテンシ・コストとなるのかをまとめた表です。Mobile latency は Google Pixel 上で測定したものが掲載されています。また、デプロイシナリオ数$N$に対してコストがどのように増加するのかを示しています。
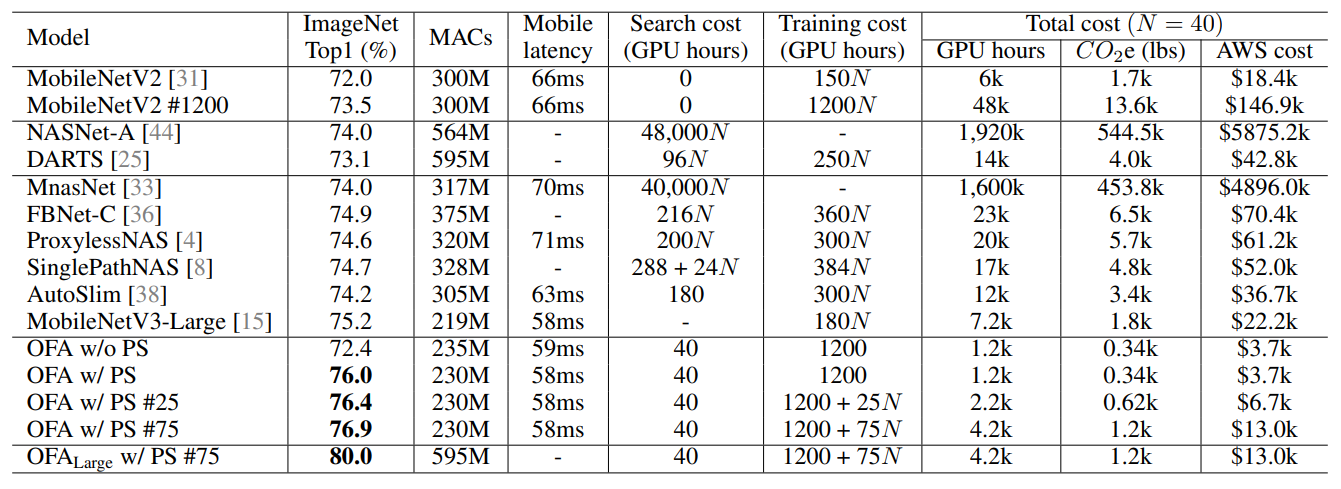
本手法(OFA)は下の方の行に示されています。PS は Progressive Shrinking を示しており、# はファインチューニングを行った場合のエポック数を示しています。
まず、精度(ImageNet Top1)を見ていくと、Progressive Shrinking によって大幅な精度改善が得られていることが確認できます。また、MobileNetV3-Large と同程度のレイテンシで、より良い精度のサブネットワークが探索できていることを確認できます。加えて、ファインチューニングを行うことで、精度の向上が確認できます。最後の行では、少し大きめのサブネットワークについて、80.0%の精度が得られている記載されています。表では省略されていますが、このときのPixel 1におけるレイテンシは 143ms です。
次に、Search cost を確認すると、精度を予測するモデルの教師データを作成するのに必要な 40GPU hours で、探索そのもののコストは無視できる大きさです。一方、その他多くの探索を必要とするネットワークでは、デプロイシナリオ数$N$に対して線形にコストが増加しています。
Training cost は、ファインチューニングを行わない場合は OFA を訓練する 1200GPU hours のみで固定です。ファインチューニングは各デプロイシナリオことに行うので、デプロイシナリオ数に比例してコストが増加します。
40 程度のデプロイシナリオがある場合は、本手法を用いた一連のバリエーションは、他の手法よりも様々な面で低コストを実現しています。
まとめ
巨大な単一のネットワークを訓練することで、様々なデバイス向けのデプロイシナリオを低コストで実現できる Once for all を紹介してみました。
1 つのネットワークに効率的に複数のサブネットワークをが含まれるようにする、という発想が最初はよくわからず、頭に「?」を浮かべながら読みました。しかし一度理解してしまうと、多種多様なデバイスで展開するアプリに深層学習モデルを組み込みたい場合は真っ先に検討すべき方針なのかも、と思ってしまうぐらいに納得感がありました。
なお、もともと読もうと思っていた論文である GAN の軽量化手法1では、cGAN の Generator にで使用するConv層のチャネル数を本手法の枠組みで最適化しています。各タスクごとに本手法のような考え方を適用するという方向性は、実用上非常に重要なトレンドになるのでは、と思いました。
-
Li, Muyang, et al. "Gan compression: Efficient architectures for interactive conditional gans." arXiv preprint arXiv:2003.08936 (2020). ↩ ↩2
-
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, et al. Searching for mobilenetv3. In ICCV 2019, 2019. ↩