概要
新しい画像認識用アーキテクチャ ResNeSt の論文を読んでみたので、紹介してみます。
EfficientNet を超える画像分類精度を実現し、物体検出やセグメンテーション、人のポーズ推定でも既存手法のバックボーンを置換するだけで精度向上を実現できる手法となっています。例えば、ResNet-50のバックボーンをResNeSt-50に置き換えるだけで、MS-COCOにおけるFaster-RCNNのmAPは39.3%から42.3%に、ADE20KにおけるのDeeplabV3のmIoUは42.1%から45.1%に向上しています。
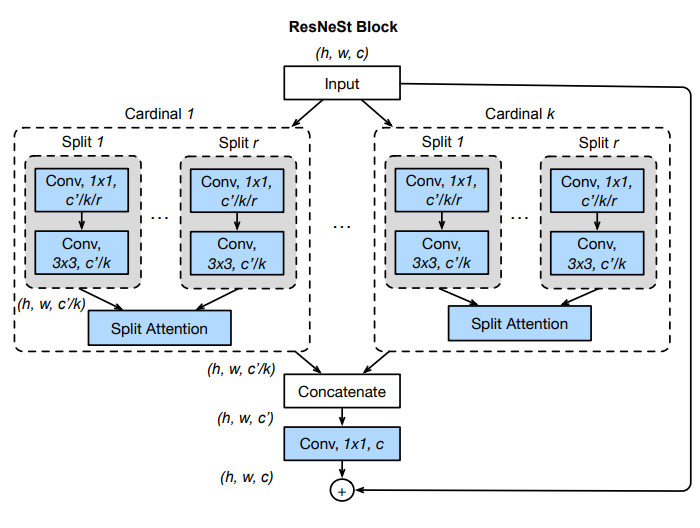
ResNeStを特徴づける構成要素(ResNeSt Block)は以下のような構造を持っています。
見通しを良くするため、本手法に至るまでの重要な手法である ResNet, SE-Net, SK-Net についても説明し、最後に ResNeSt について確認します。
書誌情報
- Zhang, Hang, et al. "ResNeSt: Split-Attention Networks." arXiv preprint arXiv:2004.08955 (2020).
-
公式実装(Gluon, PyTorch)
- 事前学習済みモデルが公開されています。
既存手法のおさらい
本手法に至るまでの重要な手法について、簡単におさらいしておきましょう。
ResNet
まずは、様々な最先端の手法の基礎構造となっている ResNet1 です。
ResNetの基本構成要素
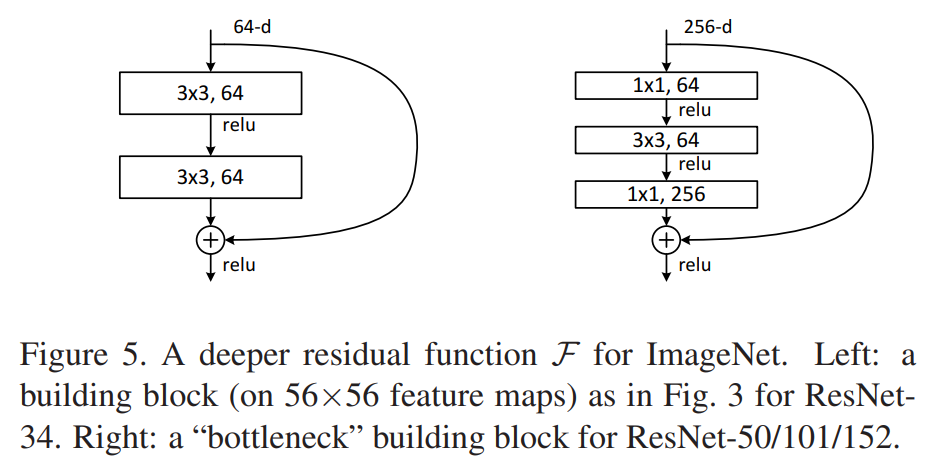
ResNet では Basic Block または Bottleneck Block が基本的な構成要素となっています。
下図の左が Basic Block、右が Bottleneck Block です。"Bottleneck"は、チャネル数が Block の内部で狭まっている、つまりボトルネック状になっていることに由来します。以降の関連手法の説明では、Bottleneckの使用を前提とした説明を行います。
いずれも共通しているのが、入力された特徴マップをスキップして複数の Conv 層から得られた処理結果と足し合わせる"Residual"構造を持っていることです。
ResNet全体の構造
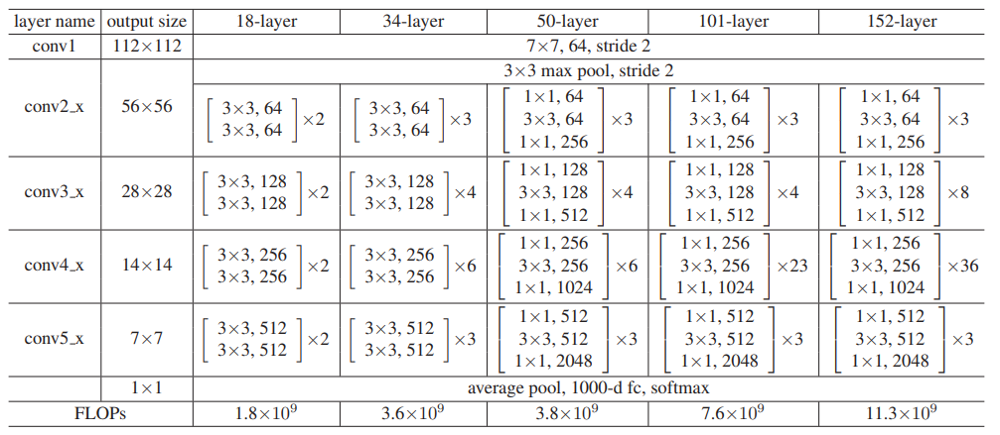
ResNet は、その深さによっていくつかのバリエーションがありますが、まとめると以下の表のような構造を持っています。18, 34-layer では Basic Block が、50-layer 以上の深い ResNet では Bottleneck Block が使われています。
ResNeXt
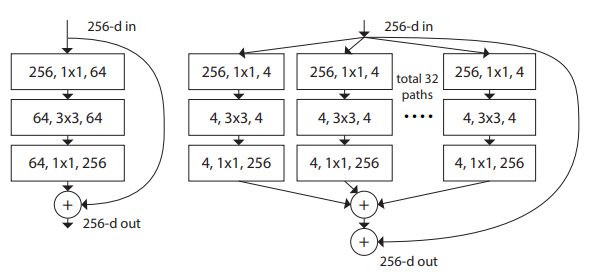
ResNeXt2 は、ResNet の Bottleneck全体を「グループ化」する方法を採用した手法です。以下は、ResNet の Bottleneck と、その ResNeXt バージョンを示しています。入力された 256 のチャネルを持っている特徴マップは 8 チャネルごとに 32 のグループに分割され、各グループで別々の Conv 層を適用された後に合計されます。一般的には、Grouped Conv はグループごとの計算結果を結合することで最終結果を得ますが、ResNeXt における Groupe化 では足し合わされるということに注意しましょう。
SE-Net
SE-Net3 は、特徴マップのどのチャネルを重視するかを重み付けるAttention機構である SE-Block を持った手法です。チャネルごとの重みは、特徴マップに対して Global Pooling を適用したのち、入力と同一のチャネル数を出力する全結合層(FC-ReLU-FC)によって得られます。
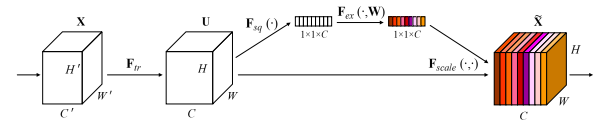
この構造は、ResNet や ResNeXt に限らず、Inception のような別のアーキテクチャにも組み込むことができます。以下は、ResNet に組み込むとどうなるかを示した図です。Residual な構造の内側に SE-Block が追加されていることがわかります。
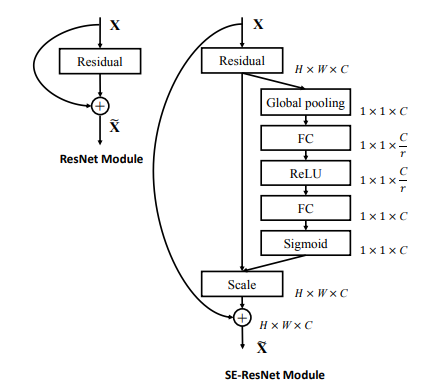
SK-Net
SK-Net4 は、Selective Kernel の名前の通り、別々のカーネル(Conv層)で加工された特徴マップのいいとこ取りをするという方法です。以下の図は、SK Conv と呼ばれる構成要素で、ResNet の Bottleneck 内の 3×3Conv を代替するものです。
入力された特徴マップに対して異なるカーネルサイズを持つ 2 つの Grouped Conv が適用され、 2 つの特徴マップ$\tilde{U}, \hat{U}$が得られています。この操作は、SplitとGrouped Convという 2 種類のグループ化操作を使用しており、ResNeXt で行ったグループ化の亜種と言えます。2 つの特徴マップは Global Pooling と全結合層によってそれぞれの特徴マップのどのチャネルを強調するかを算出され、重みづけられますが、これはSEブロックの複数入力への拡張とみなせます。重み付けられた 2 つの特徴マップは足し合わされ、出力$V$が得られます。本論文では、このようなSEブロックの複数入力への拡張を、Split Attention と読んでいます。
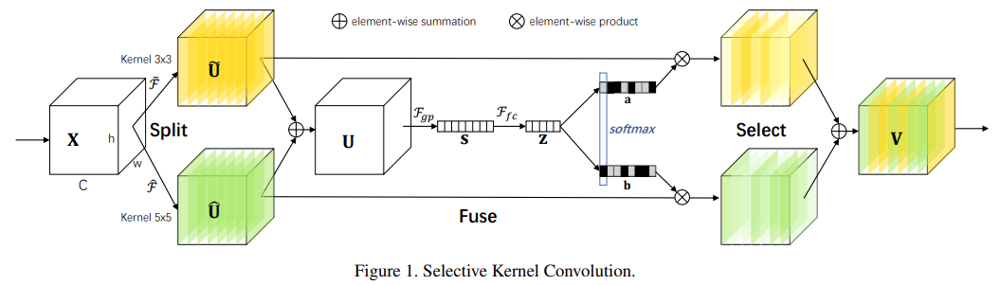
SK-Net は、ResNeXt のグループ化と SE-Net のチャネル方向のAttentionを組み合わせた構造になっていると言えます。
ResNeSt
では、以上を踏まえて、本題の ResNeSt の話に入りましょう。
既存手法との比較
SE-Net や SK-Net との比較として ResNeStの構成要素を説明するものとして、論文では以下のような図が掲載されています。
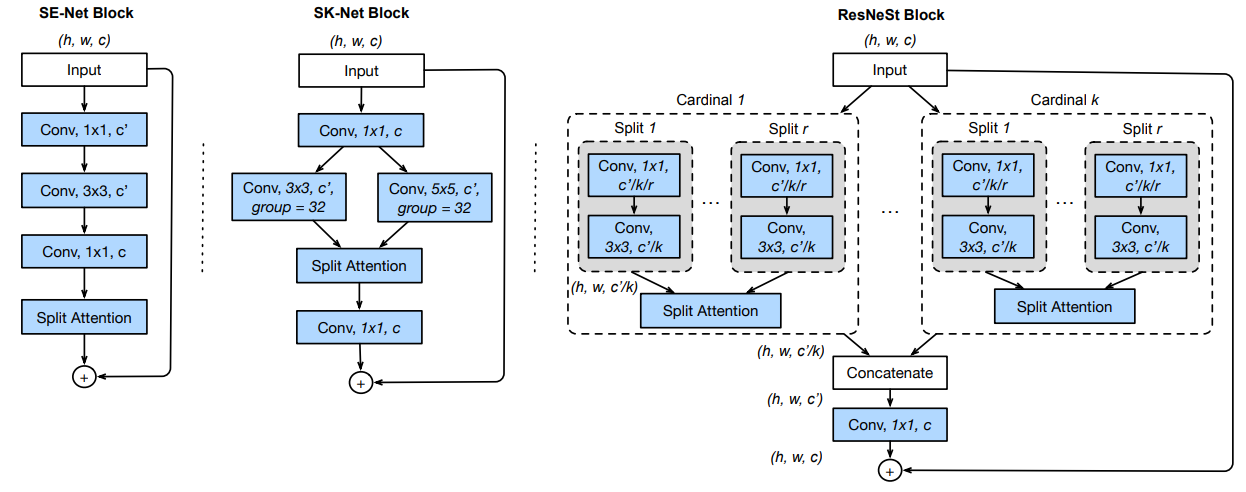
頭の整理のために、SE-Net Block と SK-Net Block の図を見てみましょう。SE-Net の図は、ResNet の Bottleneck に 1入力のSplit Attention、つまり通常の SE ブロックが続く形になっています。。また、SK-Net Block の図では ResNet の 3×3Conv 部分が ResNeXt で導入されたグループ化と、それらを入力とする Split Attention の組み合わせに置換されています。
ここから本題です。
まずは大まかな構造を捉えましょう。ResNeSt Block は、大きく言えば ResNeXt のようなチャネルのグループ化を採用しています。 ResNet における 1x1Conv, 3x3Convの部分をグループ化し、各グループの結果を結合して、最後に1×1Conv を適用しています。ここで、複数のグループで行った計算結果が足し合わされるのではなく、結合されているという点に注意しましょう。このグループは、Cardinal と呼ばれ、$K$個存在します。
各 Cardinal の中では、SK-Netのような構造が組まれています。Cardinal に入力されるのは、元の Input のチャネル$C$に対して、$K$分割された$c = C/K$チャネルの特徴マップです。これを更に$R$個のグループに分割します。これらのグループはRadixと呼ばれ、図中ではSplit 1 から Split r と記載されています。そしてこれらのグループ化された特徴マップに対して、異なる特徴抽出(1×1Conv, 3×3Conv)を施した後、Split Attention へと入力されます。カーネルサイズが Radix ごとに同一という違いはあるものの、基本的にはSK-Net Block における枝分かれとSplit Attentionによる合流という構造(SK Conv)と同じ形になっていることがわかります。
下図は、各 Cardinal 内の Split Attentin の構造を示しています。分岐が$R$個に増えているので複雑に見えますが、これは SK Conv と同じ形をしていることを確認しましょう。
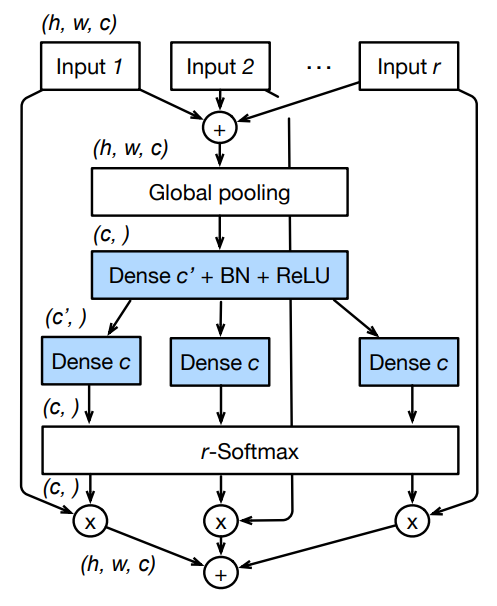
以上がResNeSt Blockの説明になります。CardinalとRadixの違いが混乱しやすいので、整理しておくと、以下のように言えます。
- Cardinal:チャネルをグループ化して別々の処理を適用し、結合する。
- Radix:チャネルをグループ化して別々の処理を適用し、Split Attentionによって足し合わせる。
ResNeSt Blockの実装
公式実装のBottleneckクラスを確認すると、先に示した図とは少々異なる実装が行われています。付録や公式のissueで説明されているとおり、計算が効率的になる実装が採用されています。
まず、先の図では、Cardinalの中にRadixがあるという階層構造になっていましたが、実際はRadixの中にCardinalがあるという Radix-major 構造が採用されています。計算上はどちらも等価です。
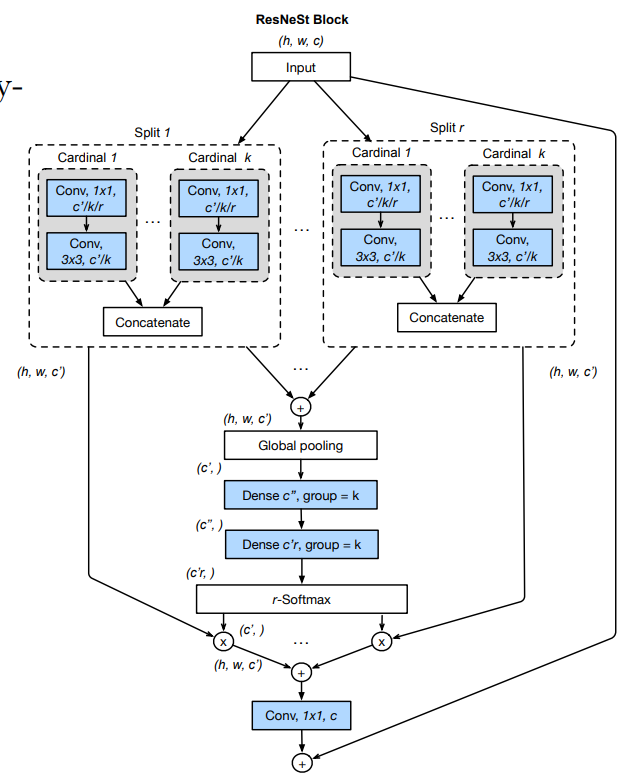
また、図を真に受けると、各 Cardinal, Radix ごとに必要な 1×1Conv, 3×3Conv はそれぞれ$KR$個用意する必要があるように見えますが、これらはまとめることができます。具体的には単純な1x1Convを 1 つと、それに続く3x3のGrouped Convによって実装されています。
まとめ
以上、ResNeSt に至るまでの流れを追ってみました。
簡単にですが、性能についても確認しておきましょう。
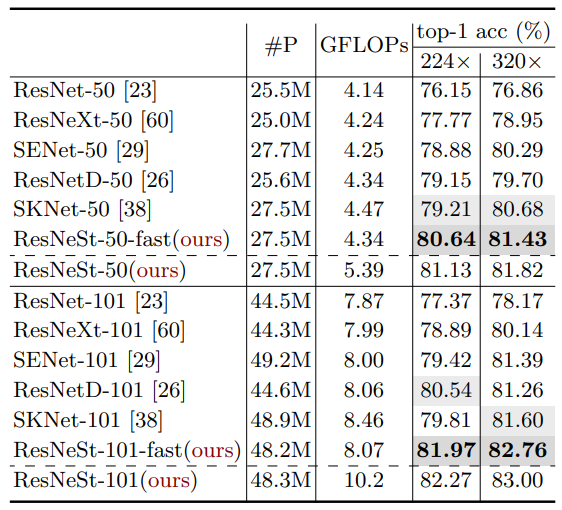
まず、同じ深さを持つ ResNet のバリエーションとの比較です。公平を期すために、入力画像サイズや前処理は揃えてあります。ResNeSt は、他の手法よりも良い結果が得られています。-fast がついているバージョンは、stride が 2 の Conv 層を、AvgPool と stride が 1 の Conv 層に置き換えることで高速化したものです。
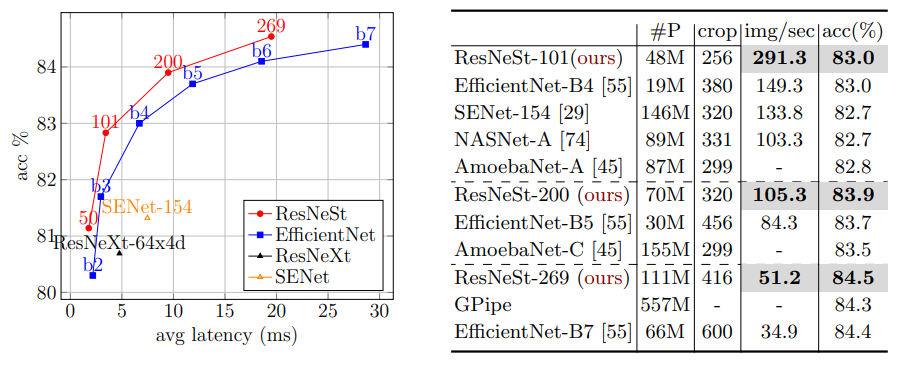
また、State-of-the-Art な手法とも比較しています。精度的には EfficientNet と同等ならば、ResNeSt はそれよりも 1.2 倍から 3 倍高速化していることが確認できます。
-
He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. ↩
-
Xie, Saining, et al. "Aggregated residual transformations for deep neural networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. ↩
-
Hu, Jie, Li Shen, and Gang Sun. "Squeeze-and-excitation networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. ↩
-
Li, X., Wang, W., Hu, X., Yang, J.: Selective kernel networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 510–519 (2019) ↩