背景
個人的には以前より自然言語処理の中でも、文章の "要約" が一番難しく一番重要な機能なのではないかと考えています。
"要約" の中でも大きく分けると、要約文章を新たに生成する『抽象型要約』と、文章内に存在する文や単語を抽出して要約文章を再構成する『抽出型要約』があり、まぁ新たに文章を生成するような『抽出型要約』は、まだまだ実現することは不可能で、実用的には『抽出型要約』しか実現できないであろうと個人的には考えていました。
そして、 BertSUMなどの『抽出型要約』を試してみたりしていましたが、長文の場合は抽出型でも十分効果はあるのですが、2・3行の文章を要約するにはあまり適してはいないと感じています。
しかし、GPT-2やGPT-3の壮絶な結果を目の当たりにすると… あながち『抽象型要約』が不可能な時代でも無いのだと、認識せざるを得ない状況となっています。
っが… GPT系はちゃちゃっとファインチューニングするにはデカすぎるし、完全なオープンソースでもなく、手軽に試して感触を得るような代物ではなく(できなくは無いのでしょうが…)、なかなか個人的にちょっと試してみる! ということもできません。
そんな時にフワッと… 以下のサイトで『抽象型要約』を試している記事を見つけたのでした…
事前学習モデルBARTを使って日本語文書要約をやってみた
なんと、BERTレベルのサイズ感で『抽象型要約』ができ、さらには京大で日本語のpretrainingモデルを公開してくれているということではないですか!!
(以前の経験から、京大といえばJuman++を使い、そのインストールにちょいと難儀するという懸念点は感じながらも…)まずは自分のMacで試せないかと、Webを彷徨い始めたのでしたぁ。
その後、T5のモデルを利用した『抽象型要約』もあるみたいなことが分かったので、今後こちらも試してみようと思います。
そして、この結果を部内で共有したところ「自分でもやってみたいんだけど… 上手く動かない!」という声がありましたので、私が理解しているポイントを記しておこうと思ったわけです。
BARTとは
難しいことは、ちゃんと論文などを理解して解説してくれている、以下のサイトなどを拝見しましたが…
【論文解説】BARTを理解する
『BARTはBERTをSequence-to-Sequence(Seq2Seq)の形にしたもの』
という事らしいです。
Seq2Seqといえば、翻訳とか… チャットボットとかにも利用される、入力された文章に対する文章を学習されたモデルに従って新しい文章を生成する仕組みです。日本語を入力するとそれに対する英語を出力したり、質問を入力するとその回答を出力したりするような振る舞いが得意なアルゴリズムです。なので、同様に正しく学習されていれば、長い文章を短な要約された文章として出力することも可能なはずなのです。
では、どの様にこのBARTを実装するのでしょう…
調べていくと以下のサイトで、 fairseq というモジュールを利用する方法で実現しているようです。
(レトリバーさんにも、よくお世話になります…)
事前学習モデルBARTを使って日本語文書要約をやってみた
この中では、 fairseq の利用も含めBARTで要約する際の注意ポイントが説明されています。
- pretraining 時に学習した語彙しか利用できない。
- 語彙に含まれないトークンの、要約結果では未知語
<unk>として扱われる。 - 未知語
<unk>を減らすために、Sentencepieceでサブワード化する。 - fairseq は、そのままでは上手く利用できず、推論時に少し工夫する必要がある。
…と、いうことは分かりましたが…
じゃぁ、どう実装したら良いのか?? さっぱり分かりません。 困ったぁ。
BARTの実装
見つけたのです! Hakky(https://www.about.st-hakky.com/company)さん… ありがとう。

実装する環境は Google Colab です。fairseq は CUDA を前提としているらしく、Mac上では無理そうです。
そして後述しますが、Hakkyさんのコードをそのままコピペしても、一部で動かない部分があります。ここは他のサンプルやコードを読み込んで修正する必要があります。
また、ファインチューニングするデータも準備する必要があります。
こちらもHakkyさんが「livedoorデータセットの使い方」で公開してくれていますので参考にします。
※以前にBertSUMでも同じ様にLivedoor Newsのデータを扱いましたが、その時の実装よりシンプルで扱いやすいです。しかしいつもではありますが、Livedoor Newsさんに迷惑がかからない様に、のんびりと間隔を空け時間をかけて取得しますので数日かかります。こちらはLocalのMacで実行しました。
【ファインチューニング実行】
ファインチューニングは、10,000程度の訓練データの5epochで4hくらいかかります。Google Colab での実行であることを考慮し10,000と少し控えました。訓練自体はデータ量が多い方が良いと思うので、環境が許せばもっと大量のデータでファインチューニングしたいですね。
また、まだ細かなパラメータを変更した結果の差異などのチェックはできていないのです。これを変えることで結果も変わるのかと思います。まぁでもファインチューニング自体にも時間はかかりますので今後の課題とします。
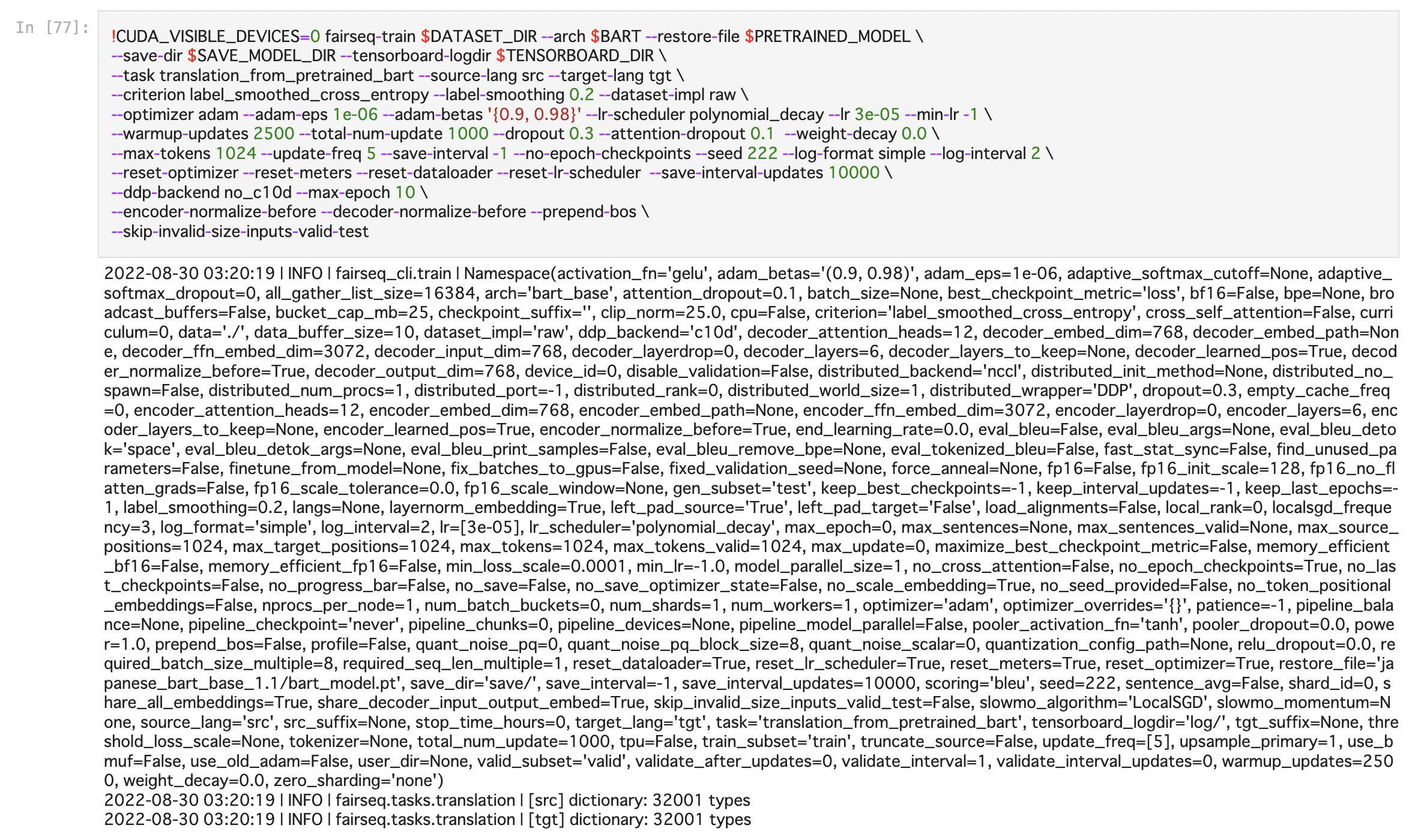
【要約用スクリプトの実行】
こんな感じで、推論を実行されます。
推論で印象的だったのが… 推論が意外と遅い感じです。なにか、形態素解析+sentencepieceの処理が結構重い感じがしていますが… もしリアルタイムで要約を得る様な仕組みに組み込む場合は、もう少し工夫する必要があるかもしれません。

【要約結果】
要約のテストとして使ったデータは、YahooニュースなどのLivedoor Newsと同じくらいの長さの文章を使いました。要約の結果は… まぁ、悪くはないです。でも、文章単位で抜き出すBertSUMの様な結果になっている気がします。
これは、ファインチューニングに利用したデータが、Livedoor Newsの3行見出しを利用しているからなのか、前半部分の文が丸ごと複数行が抜き出されている様な結果になっています。Livedoor Newsのデータがだいたいそんな感じの構造が多いのだと思いますので、個人的な期待とは少し違っていましたが、訓練された構造を再現しているのであれば、BARTの効果と考えて良いのかと思います。

Hakkyさんのコードの修正点
1. fairseqのインストール
fairseq は2つの形態でインストールしないといけないようです。
ファインチューニングでは、--editableなパラメータでインストールしないとファインチューニング実行時にエラーとなります。また記載のまま !pip 〜 ./文章要約 では動きません。!pip 〜 ./のようにカレントディレクトリを指定します。
しかもなぜか、要約実行時には通常の(--editableでない)方法でインストールされていないと実行できないのです。なので fairseq は2度インストールします。
そして更に Google Colab の場合は、ここでランタイムの再起動が必要です。
## Hakkyさんのサンプル
!pip install --editable ./文章要約
こんなふうに↓↓↓↓修正↓↓↓↓
!pip install --editable ./
!pip install ./
##そしてこのインストール後に Google Clab のランタイムの再起動!!
2. juman++のインストール
juman++は文字数の上限が4,096バイトまでに限定されているようで、長めの文章を要約するためには4,096では短いため、これを10倍ほどに拡張します。このために、juman++のソースファイルの2カ所を修正する必要があります。
しかし、Google Colab だけではファイルの修正はできません。かといって毎度 Google Drive から取得するのも面倒ですし… なので、sedで行を修正します。まぁ、juman++のバージョンが変わったりするとさらに修正が必要になるかもしれませんが、まずは"今"を楽することにします。
## Hakkyさんのサンプル
16,17行目
size_t pageSize = 48 * 1024 * 1024;
size_t maxInputBytes = 48 * 1024;
27,28行目
u64 maxInputLength_ = 48 * 1024;
u64 maxCommentLength_ = 48 * 1024;
こんなふうに↓↓↓↓修正↓↓↓↓
%%bash
sed -i -e "16c size_t pageSize = 48 * 1024 * 1024;" jumanpp-2.0.0-rc3/src/core/analysis/analyzer.h
sed -i -e "17c size_t maxInputBytes = 48 * 1024;" jumanpp-2.0.0-rc3/src/core/analysis/analyzer.h
head -17 jumanpp-2.0.0-rc3/src/core/analysis/analyzer.h | tail -2 ## 修正結果の確認
sed -i -e "27c u64 maxInputLength_ = 48 * 1024;" jumanpp-2.0.0-rc3/src/core/input/stream_reader.h
sed -i -e "28c u64 maxCommentLength_ = 48 * 1024;" jumanpp-2.0.0-rc3/src/core/input/stream_reader.h
head -28 jumanpp-2.0.0-rc3/src/core/input/stream_reader.h | tail -2 ## 修正結果の確認
3. 要約用スクリプト(1)
コピペミスかと思います。っが… args.pa。は[args.path]に変更しました。
checkpoint_utils.load_model_ensemble()を見ると、第1パラメータはlist型になっているので、list型に変更したら動きました。
## Hakkyさんのサンプル
# Load ensemble
logger.info('loading model(s) from {}'.format(args.path))
models, _model_args = checkpoint_utils.load_model_ensemble(
args.pa。rrides=eval(args.model_overrides),
task=task,
suffix=getattr(args, "checkpoint_suffix", ""),
)
こんなふうに↓↓↓↓修正↓↓↓↓
# Load ensemble
models, _model_args = checkpoint_utils.load_model_ensemble(
###### args.pa。rrides=eval(args.model_overrides),
[args.path],
arg_overrides=eval(args.model_overrides),
task=task,
suffix=getattr(args, "checkpoint_suffix", ""),
)
3. 要約用スクリプト(2)
こちらもコピペミスなんだと思います。最初はどんなふうに変更したら良いかさっぱりイメージできませんでしたが、ファインチューニングの前処理と同じような処理を実行している部分と想像し、fairseq/jaBART_preprocess.pyを参考に探ってみたら、まさしくココでした!
## Hakkyさんのサンプル
spm.Load(args.bpe_model)
return ' '.join([mrph.midasi for mrph in result.mrph_list()])
こんなふうに↓↓↓↓修正↓↓↓↓
spm.Load(args.bpe_model)
# return ' '.join([mrph.midasi for mrph in result.mrph_list()])
def juman_split(line, jumanpp):
result = jumanpp.analysis(line)
return ' '.join([mrph.midasi for mrph in result.mrph_list()])
応用
さて、ちゃんと動いてくれたので… 欲は膨らみます。
弊社はアンケートを取っている会社ですのでフリーアンサー(FA)の回答もあります。このFAを要約できたら、なんだか上手く利用できるような気がしますよね?!
なので社内で社員に対して複数の採ったアンケートのFAを、一人黙々と"要約"しました。1,200文章くらいを"要約"しました。個人の主観で… こんなふうに要約されていたら良いなぁというふうに。でも、短い文は要約も同じ文にしました。
ちょっとした時間や寝る前の時間を利用して… たかだか1,200の文章の"要約"に1週間ほどかかりました。
しかし自分で要約しないと、自身のやりたい"要約"のファインチューニング用の訓練データが得られません。しかもあまり世の中には"要約"に適したデータが無いんです。そして、自分の求めているような訓練データは更に見つかりません…
そして、1,200の文章でファインチューニングしてみましたが… 全然学習されていると思われる結果にはなりません…
epochを10に変更したりして訓練数を増やしてみましたが、全然ダメでしたぁ。 足りていないのです!
Livedoor Newsのデータを2,000行追加して3,200行程度にしたり… もしましたが、結果としてはLivedoor Newsの構造に引っ張られているようで、目的の短な文章では同じ文が2度繰り返す結果が返ってきたり… と期待するような要約は得られませんでした。
とほほ…
最後に
今回のトライを通して、BARTやBertSUMのような手法の選択も大事ではあるが、教師アリ系の機械学習(特にNLP関連)では、訓練データが重要なんだということを実感しました。手法はどんどん進化していて、やりたいことの実現が近づいてきているような気はしますが、しかし正しく訓練(ファインチューニング)をしなければ、本当のやりたいことには近づけられません。
訓練データ、重要です。
そして、サンプルのコードを提供してくださったHakkyさんをはじめ、BARTについて解説をしてくれたり、はたまたpretrainingモデルを公開してくださった皆さん。皆さんが知識と経験値を提供してくださったおかけで、なんとかここまで辿り着けました。
ありがとうございました…
今後、独自の訓練データを拡充でき、目的の要約に近い結果が得られたりしたら、またその結果についても公開したいと思います… いつになったら目的の訓練データを10,000に増やせるのか想像すらできませんが。
一旦はこの辺でひと区切りとしたいと思います。
以上