Elasticsearch について調べてみました。
Elasticsearch とは
Elasticsearch は、オープンソースの分散型 RESTful 検索および分析エンジンです。Apache Lucene を基盤としており、大規模なデータセットに対してリアルタイムの検索を提供します。構造化データと非構造化データの両方を扱うことができます。
主な特徴
- 高速な全文検索: Apache Lucene をベースにした強力な検索機能
- 分散アーキテクチャ: データをシャーディング(分割)して複数のノードに分散させることで、高い可用性とスケーラビリティを実現
- RESTful API: JSON 形式でデータをインデックスし、API を介して操作
- 柔軟なデータモデル: 構造化・非構造化データを JSON 形式で取り扱い
Elasticsearch の基本的な構成要素
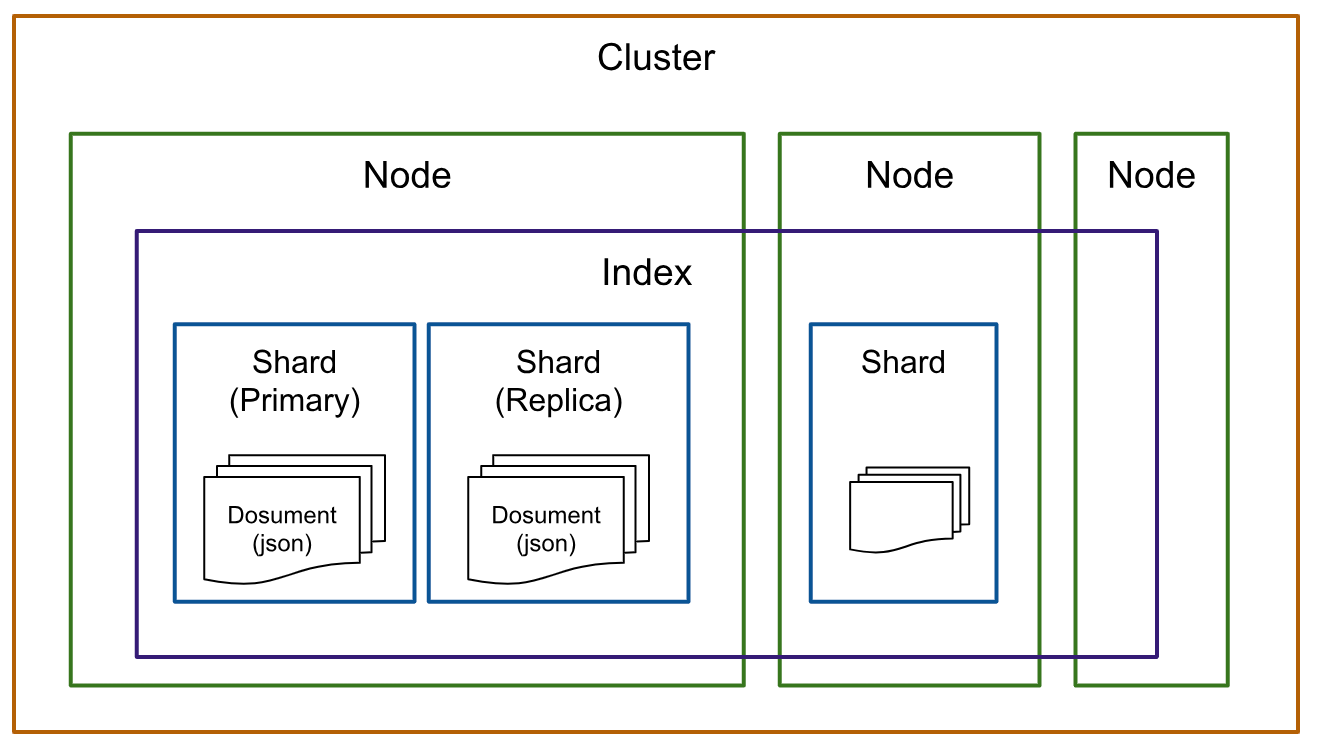
| 用語 | RDBに例えると |
|---|---|
| クラスター (Cluster) | データベースサーバー群 |
| ノード (Node) | 個々のデータベースサーバー |
| シャード (Shard) | パーティションまたはシャーディング |
| インデックス (Index) | データベースまたはテーブル |
| ドキュメント (Document) | レコード (行) |
| フィールド (Field) | カラム (列) |
| エイリアス (Alias) | ビューまたはシンボリックリンク |
主なデータ型
| データ型 | 説明・用途 |
|---|---|
| Keyword | 検索で完全一致を行うためのデータ型です。通常、短い文字列やタグのように、正確に一致させたいデータに使用されます。インデックス時に解析されません。 用途例: メールアドレス、郵便番号、カテゴリー、タグ、IDなど、一意の値を検索する場合に適しています。 |
| Text | フルテキスト検索に使用されるデータ型で、インデックス時に解析されます。形態素解析やストップワードの処理を行い、部分一致や全文検索に適しています。 用途例: 店舗の説明文、メニューの詳細、レビューの内容など、検索に対応させたい自由形式のテキストデータに使用します。 |
| Numeric | さまざまな数値データに使用されます。 |
| Flattened | 動的でネストされたキーと値のペアを持つオブジェクトを格納するためのデータ型です。nestedよりもシンプルで、正確な関連付けは必要ないが、動的フィールドの扱いが必要な場合に使用します。 用途例: メニューアイテムのような多様で構造が固定されていないデータを格納する際に使用されます。 |
| Nested | ネストされたオブジェクトを格納するためのデータ型で、各オブジェクトを独立したドキュメントとして扱います。関連するデータの正確な関連付けが必要な場合に適しています。 用途例: レストランの営業時間やメニューアイテムなど、複数のフィールドを持つオブジェクトを関連付けて格納する際に使用されます。 nested フィールドの利点 - 正確な関連付けが可能 - 高度なクエリが可能 nested フィールドの欠点 - パフォーマンスの低下 - クエリの複雑化、インデックスサイズ増大 nested 使用推奨の例 - データの関連性が非常に重要な場合 - 限定的に使うことでパフォーマンス最適化 nested 回避が有効な例 - パフォーマンスが重要な場合は flattened や object を検討 |
| Object | object型は、ネストされたデータを表現するための基本的なデータ型です。サブフィールド間の関連性は保持されず、構造がシンプルなデータに適しています。 例: json<br>{<br> "name": "Restaurant A",<br> "opening_hours": {<br> "day": ["Monday", "Tuesday"],<br> "open": ["10:00", "12:00"],<br> "close": ["18:00", "20:00"]<br> }<br>}この構造では曜日と時間が正しく対応せず、関連付けが困難になります。 |
| Date | 日付と時刻を表すためのデータ型です。様々なフォーマット(ISO 8601など)をサポートし、日付フィルタリングや範囲検索に使用されます。 用途例: イベントの日付やレストランの営業開始時間・終了時間などの時間データに使用されます。 |
| Geopoint | 緯度と経度の座標を格納するためのデータ型で、地理的な位置情報を扱います。距離検索や地図検索に対応しています。 用途例: レストランや店舗の位置情報を保存し、現在地からの距離で店舗を検索する場合に使用されます。 |
Object、Flattened、Nested の違い
| 特性 | object型 | flattened型 | nested型 |
|---|---|---|---|
| フィールドの関連性 | 関連性を保持しない | 関連性を保持しない | 各サブフィールド間の正確な関連性を保持 |
| 内部構造 | フラットにインデックス化される | フラットにインデックス化される | 各サブフィールドが別個のサブドキュメントとしてインデックス化される |
| 用途 | 定義済みの階層構造データを扱うのに適している | 動的で予測不能なキー・値ペアを扱うデータに適している | ネストされたデータの正確な関連性が必要な場合に適している |
| パフォーマンス | フラットに処理されるため、通常は高速 | フラットに処理されるため、通常は高速 | クエリ時に結合処理が発生するため、データ量によってはパフォーマンスに影響が出ることがある |
| ストレージ効率 | 比較的効率的 | 多数の動的フィールドを効率的に保存可能 | object型よりストレージ消費が大きい |
| クエリの複雑さ | 通常のクエリで使用可能 | 部分一致やフィルタリングのみ可能 | nestedクエリが必要。結合クエリが必要なためやや複雑 |
| 関連性が必要なクエリ | 関連性を考慮せずに検索される | 関連性を考慮せずに検索される | 関連性を保持し、ネストされたデータ内での正確な検索が可能 |
| 動的フィールド対応 | フィールドは静的に定義される | 動的なフィールドの追加に対応 | ネストされたデータは動的に追加できるが、パフォーマンスの考慮が必要 |
| 主な利用シーン | 住所やプロフィールなどの固定階層データ | 商品の属性データや動的に変わる設定情報 | 複数の属性が相互に関連するデータ(例: 商品の異なるバリエーションや、曜日ごとの営業時間) |
マッピングパラメータ
| パラメータ名 | 説明 |
|---|---|
| analyzer |
text フィールドに対して、どのアナライザーを使ってテキストを解析するかを指定します。アナライザーは、テキストをトークン化(単語の区切り)し、正規化(小文字化など)を行います。デフォルトの standard アナライザーのほか、カスタムアナライザーを設定することもできます。 |
| doc_values |
doc_values はディスク上にデータを格納する形式で、主にフィルタリングやソート、集計のパフォーマンス向上に役立ちます。keyword や numeric フィールドではデフォルトで有効ですが、text フィールドでは無効です。無効にすることで、メモリ消費量を削減できます。 |
| index | フィールドがインデックスされるかどうかを制御します。true の場合は検索可能になります。false の場合は検索できませんが、ソースには格納されます。 |
| null_value |
null_value パラメータを使用すると、ドキュメントで null 値を持つフィールドに対して、代替値をインデックスに保存することができます。null 値に対する検索処理が必要な場合に便利です。 |
| fields(マルチフィールド) | マルチフィールドを使用すると、同じフィールドを異なる方法でインデックスできます。例として、1つのフィールドを text として全文検索に使いながら、同時に keyword として正確な検索や集計にも利用できます。 |
| ignore_above |
keyword フィールドにおいて、指定された文字数を超える値はインデックスされません。非常に長い文字列を無視したい場合に便利です。 |
インデックス切り替えの仕組み
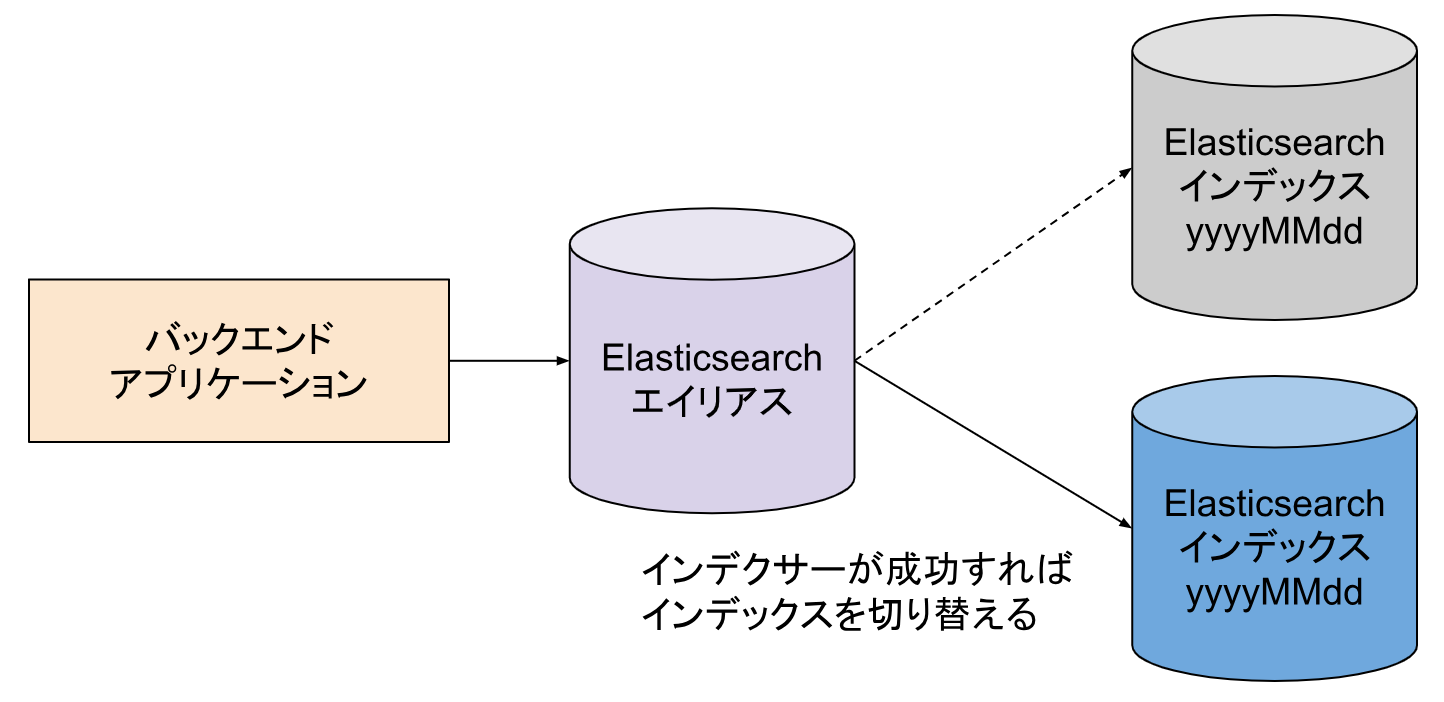
Elasticsearch はデータ更新中に RDB のようにトランザクションがありません。そのため、インデックスを切り替えることで、データの整合性を保ちながら更新を行います。