①導入
今回データサイエンティストとしての学習をしてきました。
そのためそれらを活用して、自分で考察したテーマからデータ分析を実施し、その結果をもとに記事として作成することにしました。
②解決したい社会課題
今回はカフェの売上についてフォーカスしました。
カフェでは様々なコーヒー等の飲み物が販売されていますが、その過去の販売数から将来の予測を立てて、傾向を確認し、それの考察をするものです。
③実行環境
PC:MacBook Pro(M2 Pro)
開発環境:Visual Studio Code、Jupyter Notebook
言語:Python3.11.9
生成AI:Gemini(2.5Flash)
ライブラリ:pandas seaborn prophet matplotlib
④分析方法
課題実施に際し、適切なデータセットがインターネット上から見受けられませんでした。
そのため生成AI(Gemini)を活用して、データセットを生成します。
また今回は商品名称(name)の、Drip Coffee(商品種別(type)はhot)を抽出し、売上予測を立てていきます。
データセット
以下はGitHubからダウンロードが可能です。
また一部をプロンプト以降に画像で掲載します。
Coffee_Sales.csv
プロンプト(命令文・質問文)
データサイエンティストとしてPythonにてグラフによる可視化と、予測モデルの構築を実施するため、それらのためのサンプルデータ(CSV形式)の作成をお願いします。
以下に要望を記載します。・テーマ
とある仮想のカフェにて、今後のコーヒーの販売予測を行っていきます。
温かいコーヒーと冷たいコーヒーの月別販売数のサンプルデータを作成してください。・サンプルデータ名称
Coffee_Sales.csv・サンプルデータ要件(カラム)
①データ期間(date):2020年〜2024年の5年間で、1月〜12月の月別
表示形式は、"YYYY-MM"形式でお願いします。②商品名称(name):温かいコーヒー(Drip Coffee、Espresso等)と冷たいコーヒー(Iced Coffee、Cold Brew等)といった商品名称を作成してください。
数はそれぞれ5種類でお願いします。
なお、HotやColdといった温冷の区分を加える必要はありませんが、Iced CoffeeやCold Brewのように、商品名として一般的に記載されている場合は、これに限りません。③商品種別(type):温かいコーヒーはhot、冷たいコーヒーはcoldと分けてください。
④商品単価(price):各商品名称に単価を設定してください。
設定方法は、あなたにお任せします。⑤販売数(quantity):販売した数量を設定してください。
休日や祝日が多い月は、販売数が多くなることが予想されるため、日本の祝日も考慮をお願いします。
その際は特定の大型連休(GW、お盆、年末年始など)の考慮もお願いします。⑥売上額(total):以下に計算方法を記述しますので、それを元に記載してください。
total = price * quantity⑦CSVファイルとして、ダウンロードできるようにお願いします。
データの内容も確認したいので、CSVファイルの表示もお願いします。他、予測モデルを構築する上で必要な情報があれば、提案をお願いします。
プロンプト概要
カフェでは様々な種類のコーヒーが販売されているため、商品名称の種類や温冷の区分、単価や販売数による売上額等を指示し、CSVファイル上のカラム(列)の区分けを明示しました。
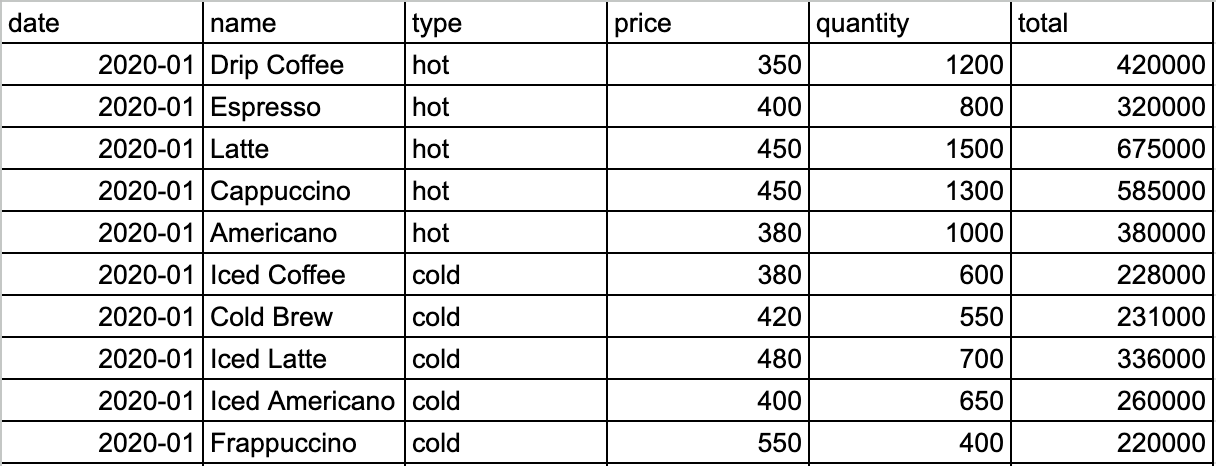
データセット内容を以下に記載
(表示が大きいため、一部掲載)
カラムは左から、
・date:日付(年月 yyyy-mm形式)
・name:商品名称(今回はhotの商品5種、coldの商品5種)
・type:商品種別(その商品がhotかclodかを表示)
・price:商品単価
・quantity:商品ごとの月別の販売数
・total:商品ごとの月別の売上額
分析内容
モデル:時系列予測
説明変数:商品ごとの過去の販売数
目的変数:将来の商品ごとの販売数
予測モデル学習:Prophet:Meta社が開発した時系列分析に便利なライブラリ
訓練・テストデータ範囲 : 2020~2024年までの5年間
(交差検証で 1 年分を予測し、訓練データとしてどの程度の期間最低限必要かを見極める)
予測対象範囲 : 2025年
予測モデル評価:rmse・mape
データの確認
準備のため、インストールと必要なライブラリのインポート、上記のデータのCSVファイルを読み込みます。
実行したコード
以下、ライブラリのインストールとインポート、データフレームの格納を実施します。
pip install pandas seaborn prophet matplotlib
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv('[任意で指定したパス]/Coffee_Sales.csv')
df # 格納したデータフレームを確認
データの抽出
格納したデータフレームはCSVファイルそのものなので、商品名称(name)のカラムから、Drip Coffeeのみを抽出します。
実行したコード
# 'name' カラムから 'Drip Coffee' を抽出
drip_coffee_df = df[df['name'] == 'Drip Coffee'].copy()
# 結果のデータフレームを表示(確認用)
drip_coffee_df
nameからDrip Coffeeのみを抽出し、実行した結果を一部抜粋します。
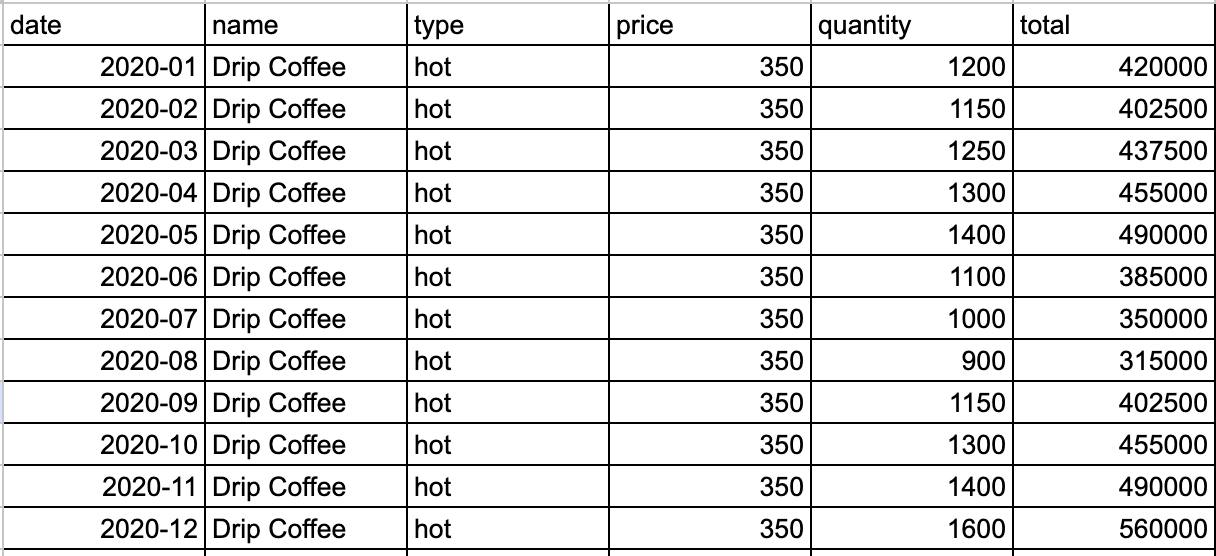
販売数のグラフ化
上記でデータフレームからDrip Coffeeのみを抽出したデータフレーム(drip_coffee_df)を作成できました。
そこから販売数の実績を表示させます。
実行したコード
# seabornのlineplot関数で折れ線グラフを描画
# 'date'カラムをdatetime型に変換
time = pd.to_datetime(drip_coffee_df['date'])
# グラフのフィギュアサイズを設定
# figsize=(幅, 高さ) のタプルでインチ単位で指定します。
# 例: 幅10インチ、高さ6インチ
plt.figure(figsize=(10, 6))
# lineplotを表示(線グラフ)
sns.lineplot(x=time, y=drip_coffee_df['quantity'])
# 以下はオプション: グラフにタイトルや軸ラベルを追加
plt.title('Drip Coffee Quantity Over Time')
plt.xlabel('Date')
plt.ylabel('Quantity')
# グリッド線を表示
plt.grid(True)
# グラフを表示
plt.show()
データの可視化
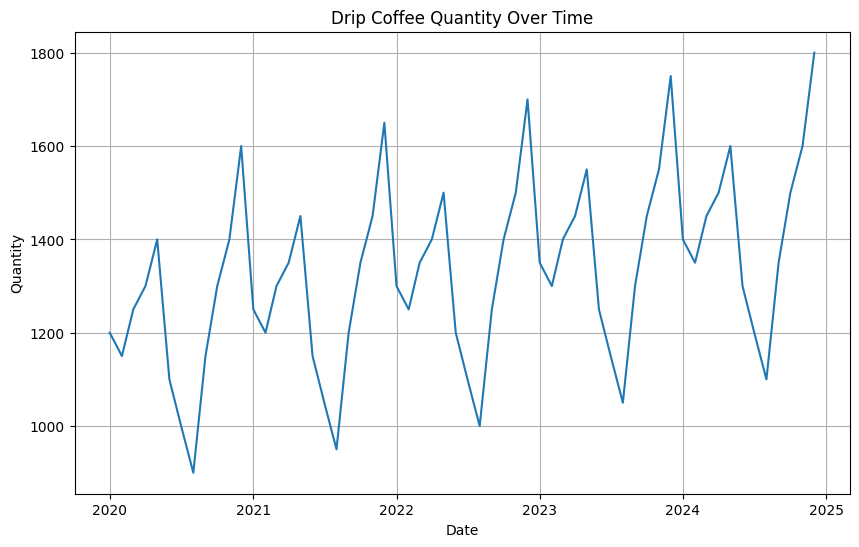
可視化の結果
緩やかですが、販売数が向上している傾向であることがわかりました。
またHotとColdを区分するようGeminiへ指示した結果なのか、夏頃(8月頃)は販売数が落ち込んでいる様子です。
またどの年も1〜2月付近は落ち込んでいることがわかりました。
データ欠損値を確認
Geminiで出力させたものですが、欠損値が発生していないか確認が必要です。
実行したコード
# データ欠損を確認
drip_coffee_df.info()
# 実行結果
<class 'pandas.core.frame.DataFrame'>
Index: 60 entries, 0 to 590
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 60 non-null object
1 name 60 non-null object
2 type 60 non-null object
3 price 60 non-null int64
4 quantity 60 non-null int64
5 total 60 non-null int64
dtypes: int64(3), object(3)
memory usage: 3.3+ KB
上記のNon-Null列にて、全てのカラムで「non-null」と表示されました。
これで欠損値が無いと表示されていることがわかりました。
予測モデルの学習
ここから予測モデルを構築していきます。
実行したコード
まずは必要なインポートとインスタンス化を実施します。
from prophet import Prophet
model = Prophet()
※実行したメッセージが表示されます。
続いて、Prophetはdsとyでしか認識できないため、'date'カラムを'ds'(datastamps)に、'quantity'カラムを'y'(目的変数を意味する記号)にリネームする
drip_coffee_df = drip_coffee_df.rename(columns={'date': 'ds', 'quantity': 'y'})
※結果は表示されません。
# fitメソッドでデータフレームを引数に指定して学習
model.fit(drip_coffee_df)
※学習結果のメッセージが表示されます。
予測の評価
続いては予測した結果を評価していきます。
方法は以下の通り
・過去のデータから学習データとテストデータを取得し、学習データで予測モデルを学習
・テストパターンは、cutoffsとhorizonの2つのパターンで実施
cutoffs:いつまでのデータを学習データとするかという期限の日付
horizon:cutoffsで定めた日付の翌日以降のテスト期間
・学習データは、2020年、2021年、2022年、2023年
(2024年を設定すると、テストデータの期間がないため対象外)
・テスト期間は1年間(365日)とする
実行したコード(期間の指定と交差検証)
まずは学習期間の末を指定
cutoffs = pd.to_datetime(['2020-12-01', '2021-12-01', '2022-12-01', '2023-12-01'])
続いてテストパターンを作成するcross_validation関数をインポートします。
インポートなので実行結果はありません。
from prophet.diagnostics import cross_validation
続いてテストデータ期間を指定
今回は1年なので、365日で設定
df_cv = cross_validation(model, horizon = '365 days', cutoffs=cutoffs)
これで学習期間とテストデータを指定できたので、改めてpredictメソッドの中身を確認するには、以下のコードで確認が可能です。
df_cv
実行結果
以下、実行した結果を抜粋します。
実行したコード(performance_metrics関数)
続いて評価指数を算出するperformance_metrics関数をインポートします。
インポートなので結果は表示されません。
from prophet.diagnostics import performance_metrics
次はdf_cvに格納したデータから上記の関数で実行します。
df_p = performance_metrics(df_cv)
df_p
実行結果
一部抜粋します。
これで評価指数を算出しました。
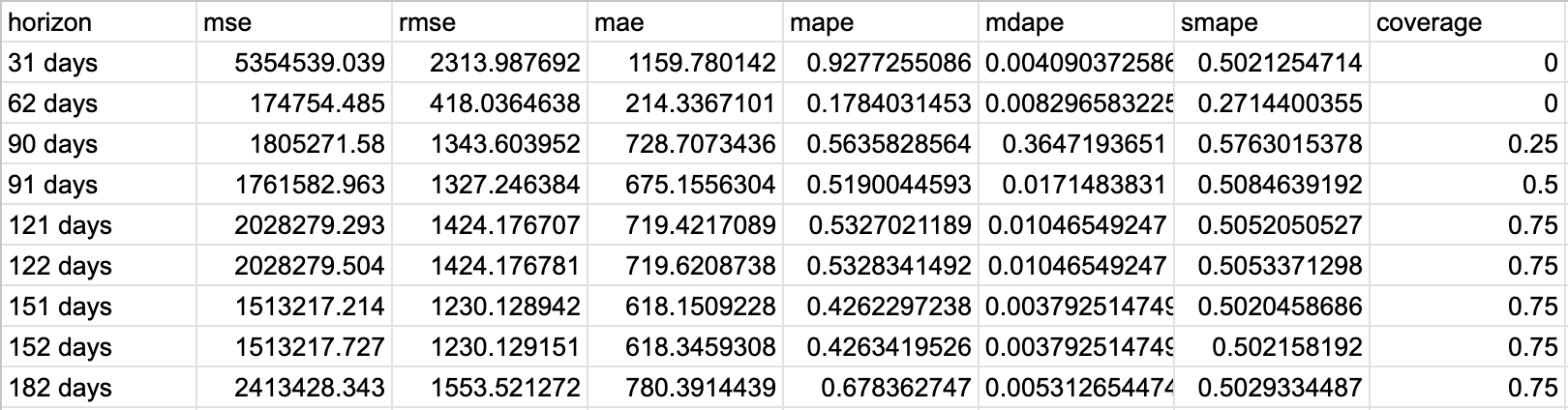
実行したコード(評価指数の決定)
今回利用する評価指数は以下2点で実施します。
・rmse(二乗平均平方根誤差)
予測値と実績値の差を評価する指標
値が小さいほど予測精度が高い
・mape(平均絶対パーセント誤差)
予測値と実績値の間のパーセント誤差の平均を示す指標
同じく値が小さいほど予測精度が高い
またhorizon列が## days(経過日数)となっているので、monthlyパラメータにTrueを指定して月単位で表示させます。
df_p = performance_metrics(df_cv, monthly=True)
df_p
実行結果
一部抜粋します。
これでhorizon列が月単位に変わりました。
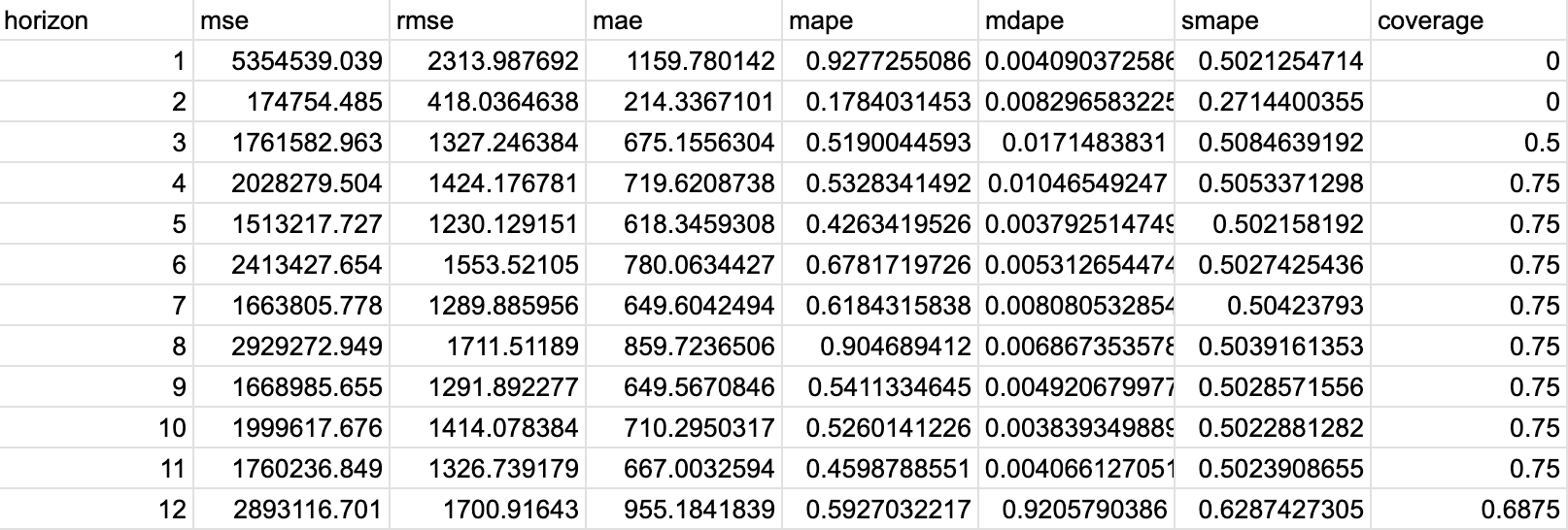
実行したコード(評価指数:rmse)
これで準備が整いましたので、rmseとmapeで評価を実行していきます。
まずはrmseを実施します。
sns.lineplot(x='horizon', y='rmse', data=df_p)
実行結果
rmseの値がとても大きい(特にhorizonが1月の時)ため、誤差が大きく、良い値でないことがわかりました。
後ほど検証するため、一旦次のmapeを実行します。
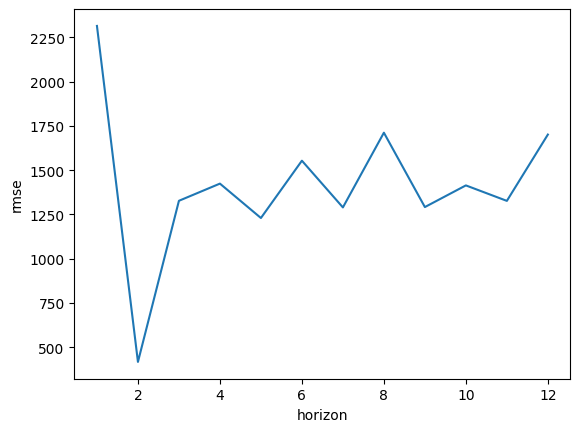
実行したコード(評価指数:mape)
mapeにて評価を実施します。
cutoffs = pd.to_datetime(['2020-12-01', '2021-12-01', '2022-12-01', '2023-12-01'])
実行結果
こちらもやはり誤差とバラツキが大きく、評価としてはあまり良いものではない様子です。
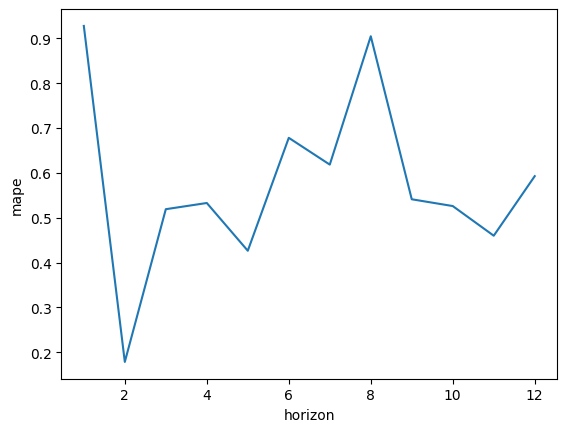
⑤考察
誤差が大きいことからデータを確認したところ、テストデータとして作成した2021年が、yhat(予測値)とy(実際の値)の誤差に乖離が生じていました。
これは今回2020年〜2023年の各年から学習データを作成しましたが、2020年の学習データが不足していたため、2021年の予測に乖離が発生したものと考えました。
⑥予測の再評価
考察から確認できたところ、2021年のテストデータのみでは誤差が大きく発生してしまいました。
また予め2021年からの予測をしたところ、2023年3月もyhatとyに誤差が大きく発生していたため、次の通りに調整しました。
実行したコード(評価指数:rmse)
まずは元々のコードは以下の通りです。
cutoffs = pd.to_datetime(['2020-12-01', '2021-12-01', '2022-12-01', '2023-12-01'])
続いて、変更したコードは以下の通りです。
cutoffs = pd.to_datetime(['2022-12-01', '2023-12-01'])
学習期間の末月を、2022-12-01と2023-12-01に変更しました。
上記のコードから、再度以下のコードを実行します。
まずはrmseを確認します。
sns.lineplot(x='horizon', y='rmse', data=df_p)
実行結果
当初のrmse値の最大は2000ほどでしたが、0〜2.75で変異するようになり、誤差が軽減されました。
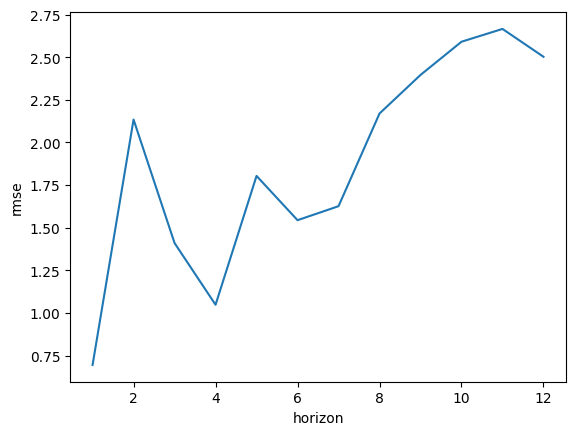
実行したコード(評価指数:mape)
続いてはmapeを確認します。
sns.lineplot(x='horizon', y='mape', data=df_p)
実行結果
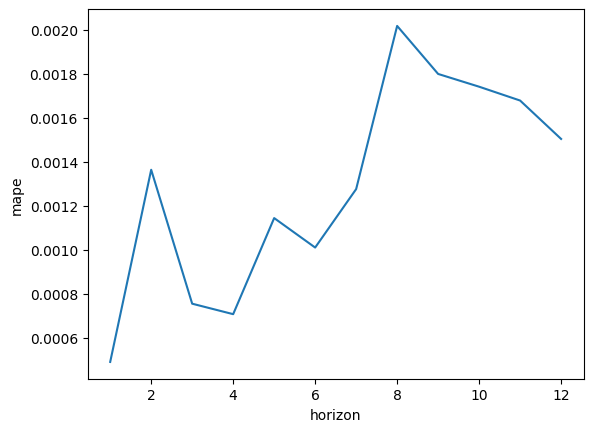
こちらも元のmape値は0.2〜0.9の範囲でしたが、調整することで0〜0.0020までと値が小さくなりました。
以上のrmseとmapeの差が軽減されたことで、予測モデルの評価としては良好な状態になったと考えられます。
以上から、最低3年の学習データの期間が必要とわかりました。
予測
それでは予測を行います。
データは2020〜2024年の5年間となっていますので、1年後の2025年の予測を立てます。
実行したコード(予測期間を指定)
# 1年後を予測してみるため、12ヶ月で設定
# 1ヶ月(追加される日時データは、月の初月)としてMSで設定
future = model.make_future_dataframe(periods=12, freq='MS')
future # 実行結果を表示
実行結果
実績(2020〜2024年)と予測(2025年)の年月が作成されました。
以下、一部を抜粋します。
実行したコード(predictメソッド)
続いては※predictメソッドで予測する準備をします。
※データや根拠に基づいて未来の出来事を推測
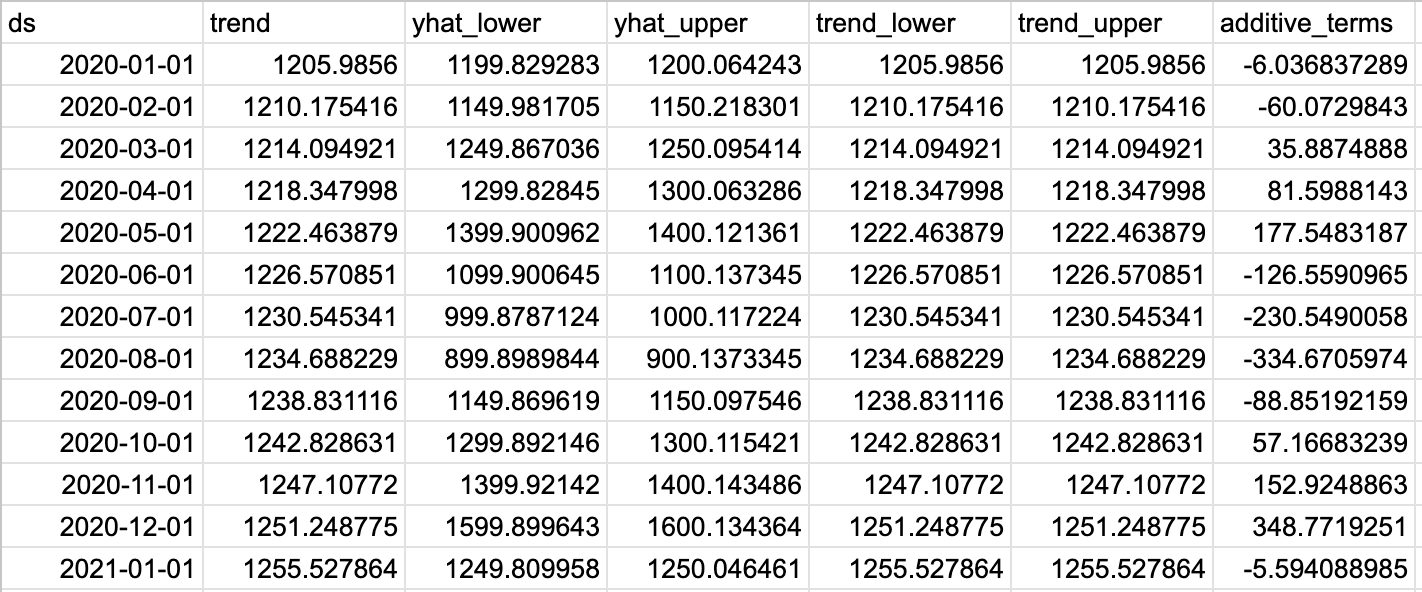
forecast = model.predict(future)
forecast
実行結果
表が大きいため、一部抜粋します。
期間は2020年1月から2025年12月までです。
(中略)
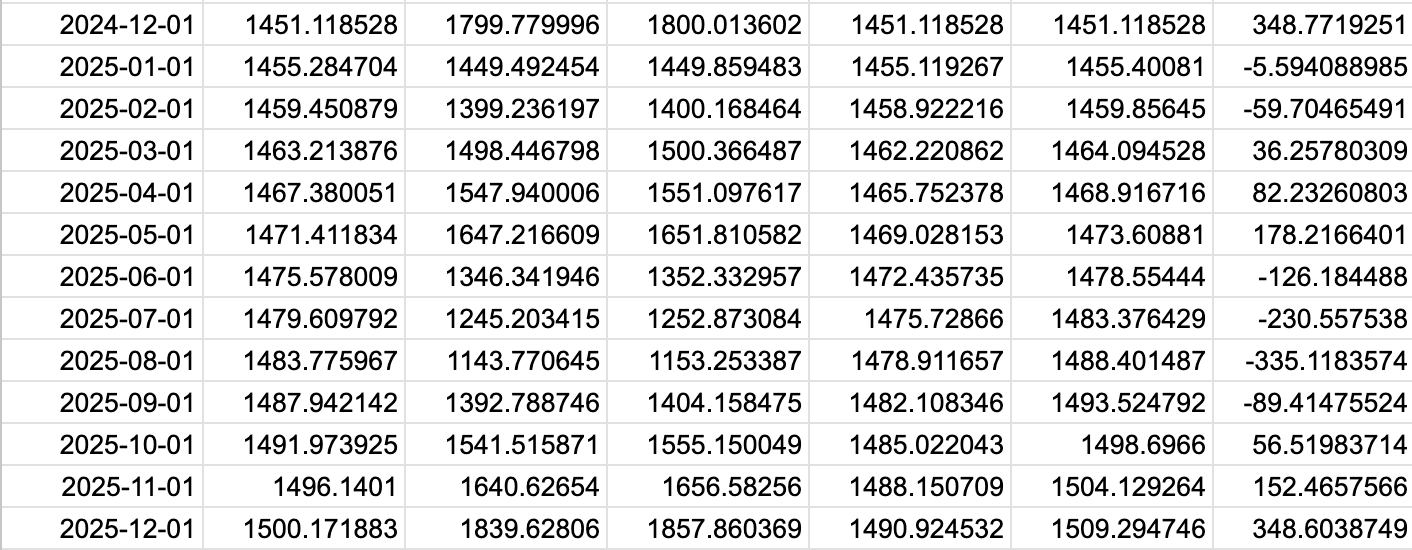
実行したコード(項目を抽出)
続いては上記のpredictメソッドで予測した内容から、予測に必要な項目を抽出します。
抽出する項目は以下の通り。
・ds(datastamp):日付
・yhat:販売数(quantity)の予測値
・yhat_lower:予測値の不確実性区間の下限
・yhat_upper:予測値の不確実性区間の上限
※yhatとは…
y:目的変数を表す記号
hat:推定値や予測値を表す記号「^」(ハット)の意味
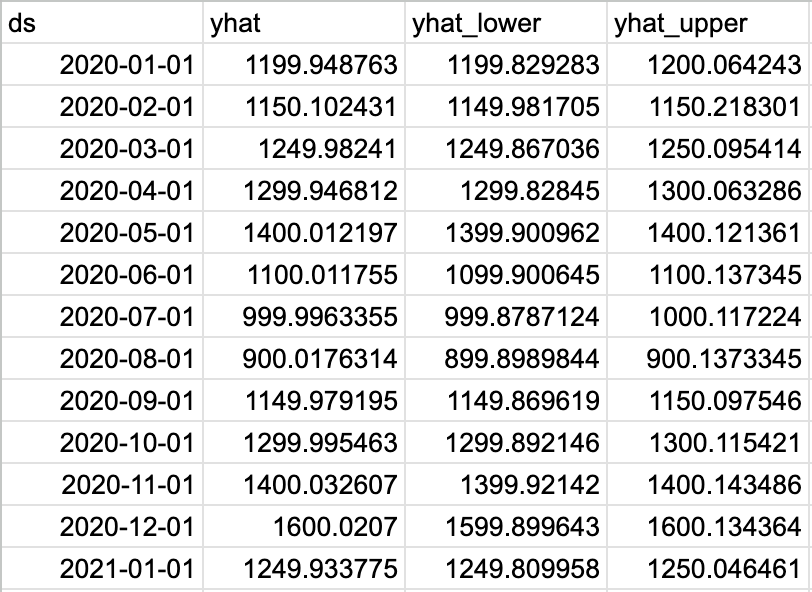
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']]
実行結果
表が大きいため、一部抜粋します。
期間は2020年〜2025年
実行したコード(グラフ可視化)
上記で日付、販売数の予測値、不確実性区間が表示されました。
次の項目で予測値をグラフ化します。
fig_forecast = model.plot(forecast)
実行結果
これで実績から予測までのグラフが表示されました。
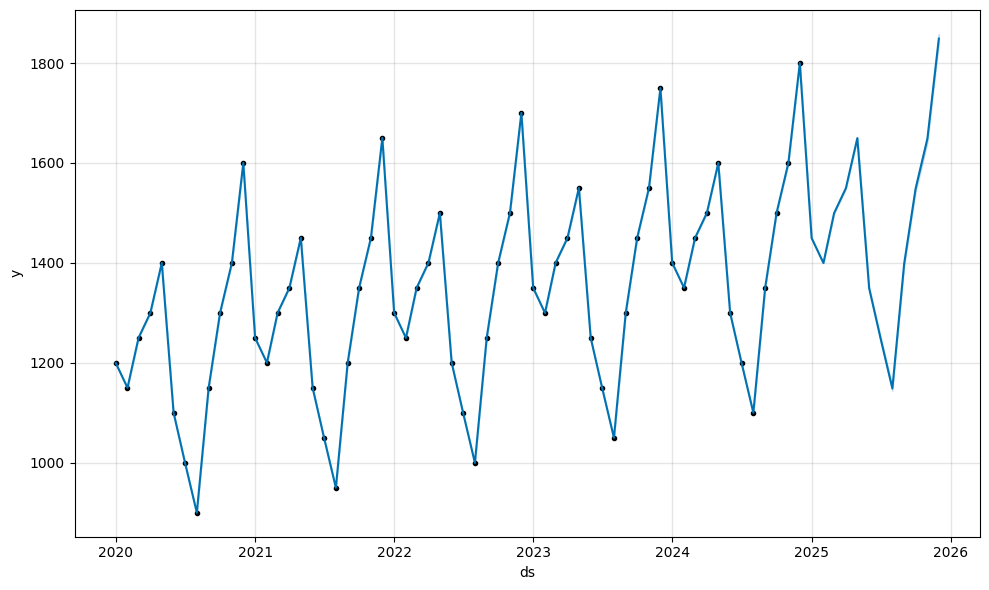
⑦再考察
2020〜2024年の販売数から予測した結果、2025年も過去に準じた傾向になったことがわかりました。
各年の中では12月が一番販売数の多い月でしたが、2020年は1600ほどが2025年では1800〜1900の間で推移していました。
予測の再評価では、販売数に対して
・rmse:最大2.75程度
・mape:最大0.0020%程度
との結果となり、各月の販売数が1000を超える値に対して3(0.0020%)以下の誤差であることから、予測モデルとしては誤差の少ない良いモデルになったと言えます。
⑧結論
今回データサイエンティストとして学習してきたことを、Geminiで生成したデータセットにて実践しました。
改めて今回データ分析の手順を、概要としておさらいします。
・分析するデータを抽出
今回はhotのDrip Coffee
・予測モデルの学習
ライブラリ:Prophet
・予測モデルの評価
期間の指定と交差検証、performance_metrics関数で評価指数を決定
・考察
評価指数で誤差が大きかったため、検証
学習データの期間が短いことによるためだった。
・予測モデルの再評価
学習データの期間を、3年以上へ変更
・予測を実施
以上のデータ分析を通じて、時系列分析では最低でも3年のデータが必要なことがわかりました。
このモデルを応用することで、実際のリアルなデータに対して利用することができると思われます。